
앤트로픽 내부에서 진짜로 일어나고 있는 일인데요.
비즈니스 분석 질문의 95%를 사람이 아니라 클로드가 답하고 있어요. 그것도 정확도 99%에 육박하면서요.
"우리 회사 데이터, AI한테 그냥 물어보면 알아서 분석해주는 거 아냐?" 한 번쯤 막연히 상상해보셨을 거예요. 근데 막상 시켜보면 그럴듯한 헛소리만 뱉어내죠. 숫자는 틀리고, 엉뚱한 테이블을 보고, 어제 맞던 답이 오늘 틀려요.
놀라운 건, 앤트로픽도 처음엔 정확도가 21%였다는 거예요. 다섯 번 물어보면 한 번 맞히는 수준이요. 그런데 이걸 95% 이상으로, 어떤 영역은 99%까지 끌어올렸어요. 모델을 더 키워서가 아니에요. 우리가 다 따라 할 수 있는 방법들로요.
오늘은 그 21%를 99%로 만든 과정을 처음부터 끝까지 뜯어볼게요. 좀 길어요. 근데 끝까지 보시면 "아, 우리 회사도 이거 그대로 하면 되겠다" 싶을 거예요.
잠깐, 이게 왜 그렇게 어려운 일인가요?
먼저 이 질문부터 짚고 갈게요. 정답이 데이터 안에 분명히 들어있는데도, 왜 AI는 못 찾을까요?
앤트로픽은 자기들이 겪은 문제를 딱 세 가지로 정리했어요. 들어보시면 "어, 우리도 저런데?" 하실 거예요.

앤트로픽은 "데이터는 소프트웨어가 아니다"라고 말해요. 코딩은 정답이 비교적 명확한데, 데이터 분석은 같은 질문에도 해석이 수십 갈래로 갈리거든요.
문제 1. "그 단어가 정확히 뭔데?"
"활성 유저 수 알려줘." 이 한마디가 그렇게 어려워요.
생각해보세요. 활성을 며칠 기준으로 볼 건가요? 7일? 30일? 어뷰징 계정은 빼야 하나요? 어떤 테이블을 봐야 진짜 숫자가 나오죠? 회사 안에 비슷비슷한 필드가 수백 개예요. 사람도 헷갈리는데 AI라고 별수 있나요. 그럴듯한 걸 하나 집는데, 그게 틀린 거죠.
앤트로픽은 이걸 '개념과 실체 사이의 모호함(Concept-to-Entity Ambiguity)'이라고 불러요. 머릿속 개념("활성 유저")을 실제 데이터의 어느 칸과 연결할지가 진짜 어렵다는 거예요.
문제 2. 데이터가 계속 늙어요
회사는 살아있는 생물이에요. 비즈니스 정의가 바뀌고, 스키마가 바뀌고, 데이터 출처가 바뀌어요.
그러면 AI가 지난주에 배운 지식이 이번 주엔 틀린 게 돼요. 사람은 "아 그거 바뀌었어요" 하고 알아채는데, AI는 옛날 정보를 그대로 붙들고 자신만만하게 틀린 답을 내놔요. 이걸 '데이터 노후화(Data Staleness)'라고 해요.
문제 3. 있는데 못 찾아요
제일 억울한 경우예요. 정답이 분명히 데이터 모델 어딘가에 있어요. 근데 그 거대한 바다 속에서 AI가 그걸 못 건져요. '검색 실패(Retrieval Failure)'죠.
정리하면 이래요. 단어를 잘못 해석하고(문제 1), 옛날 정보를 붙들고(문제 2), 있는 것도 못 찾아요(문제 3). 이 세 개가 겹치니까 정확도가 21%였던 거예요.
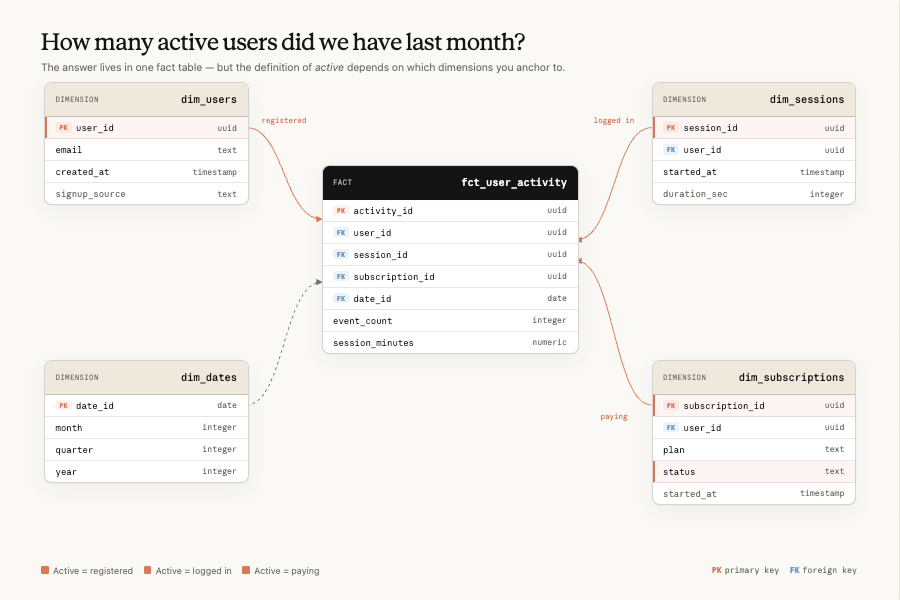
그래서 앤트로픽은 결심해요. "AI 똑똑하니까 알아서 하겠지"라는 환상을 버리자. 대신 4층짜리 시스템을 차곡차곡 쌓자.

앤트로픽이 쌓은 4층 구조예요. 아래부터 데이터 기반 → 소스 오브 트루스 → 스킬 → 검증.
1층 — 재료부터 깨끗하게 (데이터 기반)
요리 잘하려면 좋은 재료부터죠. AI 분석도 똑같아요.
앤트로픽이 1층에서 한 일은 의외로 평범해요. 비슷비슷한 테이블 여러 개를 없애고, 딱 하나의 정답 데이터셋만 남긴 거예요. "매출 데이터가 여기도 있고 저기도 있고 좀 다르네?" 이런 상황을 다 정리한 거죠. 단일 출처(single source of truth)를 만든 거예요.
그리고 더 중요한 게 있어요. 메타데이터를 '제품'처럼 다뤘다는 거예요.
메타데이터가 뭐냐면, 데이터에 대한 데이터예요. 이 컬럼이 무슨 뜻인지, 이 지표는 어떻게 계산하는지, 데이터가 어디서 왔는지, 담당자가 누군지. 보통 회사들은 이걸 대충 적거나 아예 안 적어요. 근데 앤트로픽은 이걸 정성껏 문서화했어요.
왜냐? AI는 결국 이 설명을 읽고 판단하거든요. 컬럼 설명이 부실하면 AI도 부실하게 답해요. 재료에 라벨을 제대로 안 붙여놓으면 요리사가 소금 대신 설탕 집는 거랑 똑같아요.
차원 모델링(dimensional modeling) 같은 정석 데이터 엔지니어링을 그대로 적용했어요. 화려한 신기술이 아니라 기본기예요.
여기에 한 가지 더. 데이터 관련 코드(모델링, 정의, 참고 문서)를 전부 한 저장소(repository)에 모아뒀어요. 흩어져 있으면 관리가 안 되니까요. 그리고 이 표준을 지키도록 자동화 도구와 CI 프로세스로 강제했어요. "지키면 좋고"가 아니라 "안 지키면 통과 안 됨"으로요.
2층 — 믿을 수 있는 출처 4개 (소스 오브 트루스)
1층이 재료라면, 2층은 AI가 판단할 때 펼쳐보는 '공식 참고서'예요. 앤트로픽은 네 종류를 준비했어요.
1. 시맨틱 레이어 (Semantic Layer)지표와 차원의 정의가 정리된 곳이에요. "매출은 이렇게 계산한다", "활성 유저는 이렇게 센다"가 컴파일되어 있어요. AI가 가장 먼저, 가장 믿고 보는 1순위 출처예요.
2. 계보 그래프 (Lineage Graph)이 데이터가 어디서 흘러왔는지 보여줘요. 어떤 테이블이 어떤 테이블에서 파생됐는지, 어느 게 더 신뢰도 높은지 순위까지요.
3. 쿼리 corpus (과거 쿼리 모음)예전에 사람들이 짠 SQL 패턴들이에요. 단, 그냥 쌓아둔 게 아니라 구조화된 참고 문서로 정제해서 넣었어요.
4. 비즈니스 맥락 (Business Context)조직도, 로드맵, 의사결정 기록 같은 회사 지식이에요. "이 팀이 뭐 하는 팀인지" 같은 맥락을 AI가 알아야 제대로 답하니까요.
자, 여기서 앤트로픽이 실험하다 발견한 충격적인 결과 하나 공유할게요.
과거에 사람들이 짠 쿼리 수천 개를, AI한테 그냥 통째로 다 던져줬어요. "이거 다 참고해서 답해." 그랬더니 정확도가... 1점도 안 올랐어요.
이게 무슨 뜻이냐면요. 우리가 흔히 "AI한테 데이터 많이 주면 똑똑해지겠지"라고 생각하잖아요. 틀렸어요. 양이 아니라 '얼마나 잘 정리됐느냐'가 전부예요. 쿼리 수천 개의 무더기보다, 잘 정제된 참고 문서 한 장이 훨씬 강력했던 거죠.
이 교훈, 기억해두세요. 뒤에서 또 나와요.
3층 — 스킬, 여기가 진짜 핵심이에요
자 이제 진짜 주인공이 나와요. 스킬(Skills)이에요.
스킬이 뭐냐면, AI가 필요할 때 꺼내 보는 업무 매뉴얼 폴더예요. 마크다운 파일로 적혀 있고요. 평소엔 안 보다가, 관련된 질문이 오면 그제서야 펼쳐봐요.
클로드 코드 써보신 분이라면 "어 그 스킬?" 하실 거예요. 맞아요. 그 개념을 회사 데이터 분석에 그대로 가져온 거예요.
이게 얼마나 효과 있었는지 숫자로 보여드릴게요.
핵심: 스킬 없을 때 21% → 스킬 넣으니 95% 이상, 어떤 영역은 99%
네 자릿수 투자 없이, 모델 안 바꾸고, 매뉴얼 폴더 하나로 정확도가 4배 넘게 뛴 거예요.
스킬은 두 종류예요
길잡이 스킬 (Knowledge Skills)"이 질문은 이 파일들 보면 돼" 하고 길을 안내하는 라우터예요. 특정 분야에 대해 잘 정리된 참고 파일 20~30개로 AI를 안내해요. AI가 망망대해에서 헤매지 않게 "여기 보면 답 있어" 하고 콕 집어주는 거죠.
워크플로우 스킬 (Unbook Skills)이건 더 고급이에요. 시니어 분석가가 일하는 순서를 통째로 담았어요. 질문이 모호하면 먼저 되묻고 → 참고 자료를 찾고 → 쿼리를 실행하고 → 결과를 스스로 검증하는, 그 전 과정을요. 리텐션 곡선 그리기, 퍼널 분석, 비율 분해 같은 재사용 가능한 분석 패턴 12개 이상도 같이 들어있어요.
근데 함정이 있었어요
스킬 깔고 "오 95% 됐다!" 하고 한 달 놔뒀어요. 그랬더니...
정확도가 95%에서 65%로 곤두박질쳤어요.
왜냐? 아까 말한 문제 2, 데이터가 계속 늙는다는 거 기억나시죠. 데이터는 매일 바뀌는데 매뉴얼은 그대로니까, 매뉴얼이 거짓말쟁이가 된 거예요.
앤트로픽의 해결책이 똑똑해요. "데이터 바꾸는 PR에 매뉴얼 수정도 무조건 같이 넣어라." 데이터 코드랑 스킬 마크다운을 같은 곳에 두고, 하나 바꾸면 다른 것도 같이 바꾸게 규칙으로 묶은 거예요.
결과요? 지금은 데이터 관련 PR의 90%가 스킬 수정을 함께 담고 있어요. 매뉴얼이 데이터랑 같이 늙고 같이 갱신되니까, 다시는 65%로 안 떨어지는 거죠.
4층 — 검증, 못 믿으면 아무도 안 써요
아무리 정확해도, 사람들이 "이거 믿어도 돼?" 싶으면 안 써요. 그래서 4층은 신뢰를 만드는 층이에요.
시험 문제를 AI가 직접 만들어요
앤트로픽은 평가용 문제를 끊임없이 만들어요. 방법이 재밌어요.
- 대시보드 기반 평가: 클로드가 스스로 문제를 뽑고, 사람이 검수해요.
- 롱테일 평가: 비즈니스 맥락을 활용해, 클로드가 여러 분야에서 나올 법한 질문들을 상상해서 만들어요. 잘 안 나오는 희귀한 질문까지 대비하는 거죠.
- 실시간 수확: 실무자들이 "이거 틀렸어요" 하고 고쳐준 걸 모아서 새 시험 문제로 써요.
목표는 오프라인 정확도 거의 100%예요. 시험 범위만 제대로 짜면 가능하다는 거죠.
"안 되는 것"도 기록으로 남겨요
여기 또 중요한 교훈이 있어요. 앤트로픽은 대시보드, 변환, 노트북 SQL 파일 수천 개에 AI가 직접 grep(검색)으로 접근하게 해봤어요. 결과는?
정확도 1점 미만 변화.
또 나왔죠? "정보를 많이 주는 게 답이 아니다"라는 교훈이요. 병목은 정보의 양이 아니라 구조였던 거예요.
그래서 앤트로픽은 "이건 해봤는데 안 되더라"를 문서로 남겨요. 다음 사람이 같은 삽질 반복 안 하게요.
답할 때마다 출처를 꼬리표로 달아요
이게 신뢰의 핵심이에요. 클로드가 답을 줄 때마다 '출처 꼬리표(Provenance Footer)'를 붙여요.
"이 답은 시맨틱 레이어에서 나왔고(1순위 출처), 데이터는 며칠 자 신선한 거고, 이 영역 담당자는 누구입니다." 이렇게요.
어디서 나온 답인지 추적이 되니까, 사람이 "아 이건 믿을 만하네" 혹은 "어 이건 raw 테이블에서 나온 거니까 한 번 검토해보자" 하고 판단할 수 있어요. 신뢰는 투명함에서 나오는 거죠.
순찰 도는 AI까지 있어요
압권은 이거예요. 사내 채널을 자동으로 순찰하는 AI가 있어요. 사람들이 "이거 틀렸어요" "이 숫자 이상한데요" 하고 정정하는 패턴을 발견하면, 알아서 한 줄짜리 수정안을 만들어서 담당자한테 PR로 올려요.
사람이 일일이 "어디 틀렸나" 찾아다니지 않아도, 시스템이 스스로 상처를 찾아 꿰매는 거예요.
근데 정확도 더 올리는 건 공짜가 아니에요
앤트로픽이 정말 솔직하게 공개한 트레이드오프 숫자가 있어요. 이게 이 글에서 제일 현실적인 부분이에요.
반박 전담 AI(Adversarial Review)를 붙여봤어요. 메인 AI가 답을 내면, 다른 AI가 "그 가정 진짜 맞아? 그렇게 단정해도 돼?" 하고 깐깐하게 물고 늘어지는 거예요. 결과는?
| 항목 | 변화 |
|---|---|
| 정확도 | +6% 올라감 |
| 응답 속도 | +72% 느려짐 |
| 토큰 사용량 | +32% 증가 |
정확도 6% 더 얻으려고, 속도는 거의 두 배 느려지고 비용은 3분의 1 더 들어요.
그래서 앤트로픽이 하는 말이, "무작정 켜지 마라"예요. "우리한테 6% 정확도가 이 비용을 치를 값어치가 있나?"를 따져보라는 거죠. 빠른 답이 중요한 상황도 있고, 느려도 정확한 게 생명인 상황도 있으니까요. 정답은 회사마다 달라요.
그래서 우리는 뭐부터 하면 되나요?
여기까지 읽고 "와 좋은데 우리 회사는 저렇게 못 해..." 싶으실 수 있어요. 걱정 마세요. 앤트로픽이 맨땅에서 시작하는 팀을 위한 가이드도 줬어요.
딱 세 개만 하래요.
- 정답 데이터셋 몇 개부터 깔끔하게 만들기 (1층의 축소판)
- 평가 문제 수십 개
- 얇은 길잡이 스킬
화려할 필요 없어요. 작게 시작해서, 다음 질문들에 답하면서 키워가면 돼요.
- 정답이 빨리 나오는 게 중요한가, 아니면 모델 좋아질 때까지 기다려도 되나?
- 우리 비즈니스 복잡도가 앞으로 어떻게 변할까?
- 이걸 쓸 사람들의 기술 수준은 어느 정도인가?
- 정확도 끌어올리는 데 (반박 AI 같은) 비용을 얼마나 쓸 수 있나?
- 데이터 접근 권한과 프라이버시는 어디까지 열어도 되나?
이 질문들에 답이 쌓일수록, 시스템도 같이 커져요.
마무리 — 진짜 메시지는 이거예요
긴 글 끝까지 와주셨어요. 이 글이 진짜로 하고 싶은 말, 딱 한 줄로 정리할게요.
AI를 똑똑하게 만드는 건 더 큰 모델이 아니라, 잘 정리된 매뉴얼과 깨끗한 데이터예요.
생각해보세요. 쿼리 수천 개를 던져도 1점이 안 올랐어요. 파일 수천 개를 검색하게 해도 1점이 안 올랐고요. 그런데 잘 쓴 매뉴얼(스킬) 하나가 21%를 95%로 만들었잖아요.
이건 비단 데이터 분석만의 얘기가 아니에요. 우리가 AI를 쓰는 거의 모든 일에 똑같이 적용돼요. "AI가 멍청해서 안 돼"가 아니라, "AI한테 줄 재료와 설명서를 우리가 제대로 안 만들어서 안 되는 것"일 때가 많거든요.
클로드 코드의 그 '스킬', 회사 데이터에도, 여러분 업무에도 똑같이 통한다는 게 오늘의 핵심이에요.
자, 그래서 오늘 당장 할 일 하나 드릴게요.
우리 팀에서 사람마다 다르게 세는 지표 하나만 골라보세요. "활성 유저", "매출", "전환율"... 뭐든 좋아요. 그리고 그 정의를 딱 한 줄로 적어보세요. "활성 유저 = 최근 7일 내 로그인한 어뷰징 제외 계정" 이렇게요.
그 한 줄이, 여러분 회사의 첫 번째 시맨틱 레이어예요. 거기서부터 시작이에요.
다음 레터에서 또 만나요. 👋
검증된 AI 전문가 에반의 강의를 듣고 싶으시면 아래 멤버쉽으로 와주세요
https://www.vrl.co.kr/ai-insider-club
AI 도입 관련 문의는 아래 페이지를 참고해주세요
더 많은 정보를 얻으시려면 아래 커뮤니티로 와주세요
ai 인사이더 클럽
https://open.kakao.com/o/pNsaddci
스킬샵
https://open.kakao.com/o/pUigcTsi
의견을 남겨주세요