
Introduction
매일 수백만 건의 메시지가 오가는 현대의 분산 시스템에서, 안정적인 메시지 처리는 선택이 아닌 필수가 되었습니다. Netflix는 하루 평균 1조 건 이상의 이벤트를 처리하고, LinkedIn은 매일 7조 건의 메시지를 다룬다고 하는데요. 이런 엄청난 규모의 데이터를 어떻게 안정적으로 처리할 수 있을까요?
바로 이때 등장하는 것이 Apache Kafka입니다. 처음 LinkedIn에서 내부 시스템으로 시작된 Kafka는 이제 PayPal, Uber, Netflix 등 수많은 글로벌 기업들의 백엔드를 지탱하는 핵심 인프라가 되었죠. 그런데 많은 개발자들이 Kafka를 어렵게만 생각합니다. "브로커? 파티션? 컨슈머 그룹?" 생소한 용어들 때문일까요?
이 글에서는 복잡해 보이는 Kafka의 핵심 개념들을 실제 사례와 함께 쉽게 설명해드리려고 합니다. 대규모 시스템 설계에서 Kafka가 왜 필수적인지, 그리고 어떻게 하면 효과적으로 활용할 수 있는지, 자세히 풀어보겠습니다. <Apache Kafka: A Basic Intro>를 번역해 가져왔습니다.
이 글을 읽고 나면, 여러분도 Kafka를 자신 있게 다룰 수 있게 될 거예요.
Apache Kafka: 쉽게 배우는 기초 가이드

이 글에서는 Apache Kafka의 기본 개념과 시작하는 데 필요한 핵심 용어들을 알기 쉽게 설명해드리겠습니다.
Kafka란?
Kafka는 큐 기반 아키텍처를 통해 여러 서비스 간의 통신을 가능하게 하는 분산 시스템입니다. 이제 Kafka를 이해하는 데 필요한 핵심 용어들을 하나씩 살펴보겠습니다.
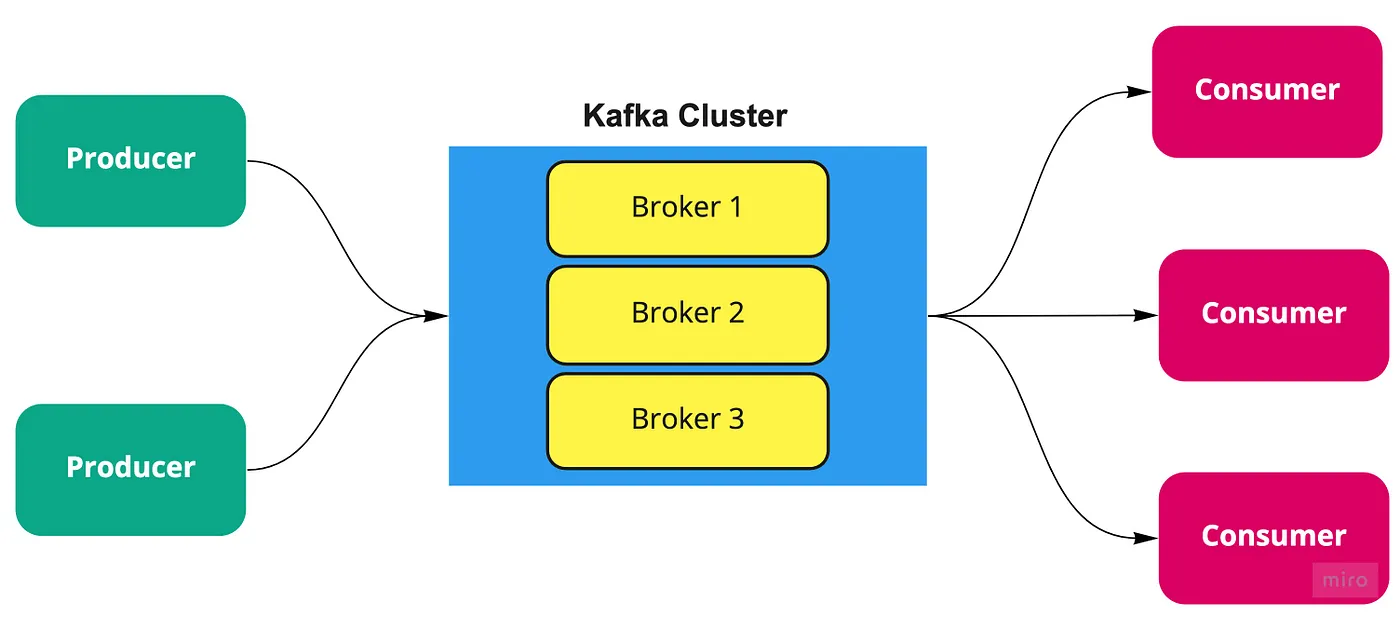
핵심 용어
브로커(Broker) Kafka가 실행되는 서버를 브로커라고 합니다. 브로커는 서비스 간 통신을 담당하며, 여러 브로커가 모여 Kafka 클러스터를 구성합니다.
이벤트(Event) Kafka 브로커에서 주고받는 메시지를 이벤트라고 부릅니다. 이러한 이벤트는 브로커의 디스크에 바이트 형태로 저장됩니다.
프로듀서와 컨슈머(Producer and Consumer) 이벤트를 생성하여 Kafka 브로커로 보내는 서비스를 프로듀서, 이벤트를 수신하는 서비스를 컨슈머라고 합니다. 한 서비스가 프로듀서와 컨슈머 역할을 동시에 수행할 수도 있습니다.
토픽(Topic) 토픽은 Kafka에서 이벤트를 분류하는 단위입니다. 파일 시스템의 폴더처럼, 특정 유형의 이벤트들을 하나의 토픽에 저장합니다. 예를 들어 "payment-details"나 "user-details" 같은 형태로 사용됩니다.
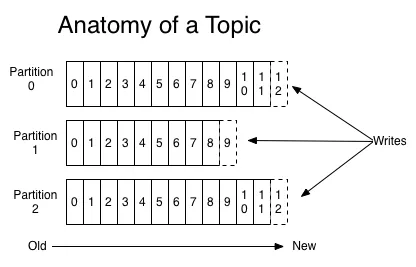
파티션(Partition) 처리량을 높이기 위해 토픽을 여러 파티션으로 나눌 수 있습니다. 파티션은 토픽 데이터의 일부를 저장하는 가장 작은 단위입니다.
복제 팩터(Replication Factor) 파티션의 복제본을 몇 개 유지할지 결정하는 값입니다. 예를 들어, 파티션이 1개이고 복제 팩터가 2인 토픽은 동일한 데이터를 가진 파티션 사본이 Kafka 클러스터에 2개 저장된다는 의미입니다.
오프셋(Offset) 컨슈머가 어디까지 메시지를 읽었는지 추적하기 위한 인덱스입니다. 컨슈머가 장애로 중단되었다가 다시 시작할 때, 이 오프셋을 통해 마지막으로 읽은 위치부터 다시 메시지를 처리할 수 있습니다.
주키퍼(Zookeeper) 주키퍼는 Kafka 클러스터의 관리를 돕는 보조 서비스입니다. 클러스터의 접근 제어 목록(ACL) 관리, 각 토픽의 파티션 오프셋 저장, Kafka 브로커 노드의 상태 모니터링, 클라이언트의 데이터 처리량 제한(할당량) 관리 등을 담당합니다.
컨슈머 그룹(Consumer Group) 여러 컨슈머를 하나의 그룹으로 묶어 토픽의 메시지를 분산 처리할 수 있습니다. 같은 컨슈머 그룹에 속한 컨슈머들은 서로 다른 파티션을 할당받아 메시지를 처리하므로, 중복 처리 없이 효율적으로 메시지를 소비할 수 있습니다. 이를 통해 메시지 처리 속도를 높일 수 있습니다.
이벤트의 생산과 소비 과정
실제 동작 방식을 이해하기 위해 두 가지 시나리오를 살펴보겠습니다.
시나리오 1:
단일 파티션 가장 단순한 구성으로, 하나의 Kafka 브로커에 다음 요소들이 있다고 가정해봅시다:
- 하나의 토픽(Topic-A)
- 파티션 1개, 복제 팩터 1
- 프로듀서 1개
- 컨슈머 1개
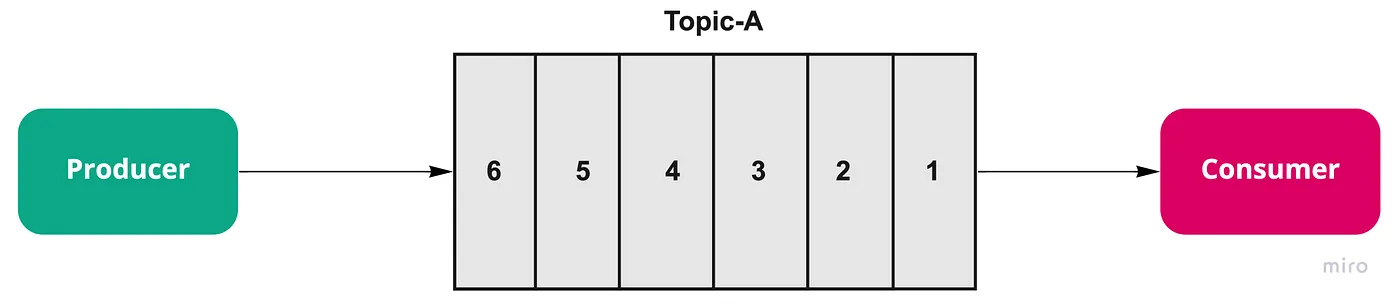
이 경우, 프로듀서가 Topic-A로 전송한 모든 메시지는 단일 파티션에 순차적으로 저장됩니다. 컨슈머는 이 파티션을 구독하여 메시지가 저장된 순서 그대로 처리합니다.
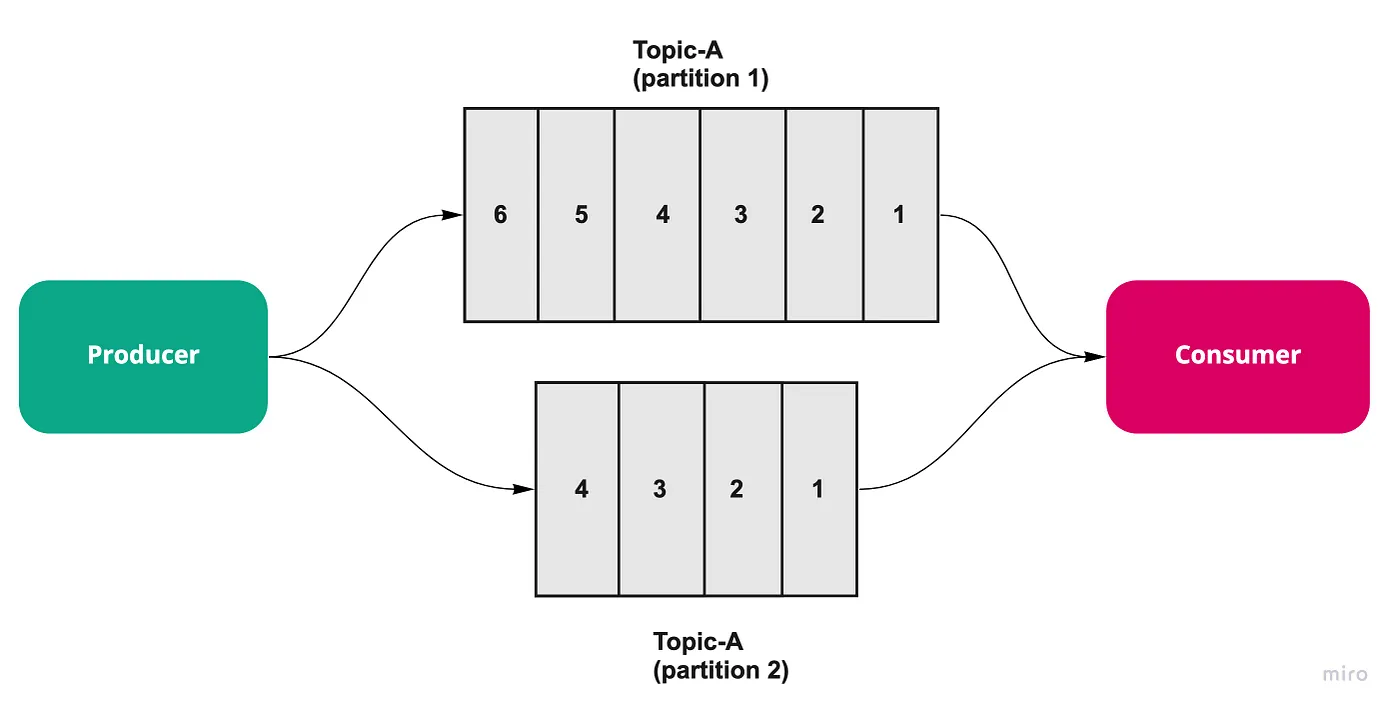
시나리오 2:
다중 파티션 이번에는 Topic-A가 2개의 파티션을 가지고 있는 경우입니다. 프로듀서가 보내는 메시지는 두 파티션에 분산되어 저장되며, 각 메시지는 반드시 하나의 파티션에만 저장됩니다. 컨슈머는 자신에게 할당된 파티션의 메시지만 처리합니다.
자주 묻는 질문
Q. Kafka는 메시지를 컨슈머에게 직접 전달(push)하나요?
A. 아니요, Kafka는 풀(pull) 방식을 사용합니다. 컨슈머가 직접 Kafka 브로커에 요청을 보내 메시지를 가져가는 방식으로 동작합니다.
Q. 메시지는 소비되면 바로 삭제되나요?
A. 아니요, 메시지는 소비 여부와 관계없이 다음 두 가지 조건 중 하나에 해당할 때까지 보존됩니다:
- 설정된 보존 기간이 지났을 때
- 파티션의 크기가 지정된 최대값에 도달했을 때
Q. 같은 메시지가 여러 파티션에 저장될 수 있나요?
A. 아니요, 하나의 메시지는 항상 하나의 파티션에만 저장됩니다.
Q. 여러 파티션의 메시지가 생산된 순서 그대로 처리되나요?
A. 개별 파티션 내에서는 메시지 순서가 보장되지만, 여러 파티션에 걸쳐서는 원래의 생산 순서가 보장되지 않습니다.
Kafka 파티션과 컨슈머 그룹에 대해 더 자세히 알고 싶다면 후속 글 "6분 만에 이해하는 Kafka 파티션과 컨슈머 그룹"을 참고하시기 바랍니다.
👥 더 나은 데브필을 만드는 데 의견을 보태주세요
Top 1% 개발자로 거듭나기 위한 처방전, DevPill 구독자 여러분 안녕하세요 :)
저는 여러분들이 너무 궁금합니다.
어떤 마음으로 뉴스레터를 구독해주시는지,
어떤 환경에서 최고의 개발자가 되기 위해 고군분투하고 계신지,
제가 드릴 수 있는 도움은 어떤 게 있을지.
아래 설문조사에 참여해주시면 더 나은 콘텐츠를 제작할 수 있도록 힘쓰겠습니다. 설문에 참여해주시는 분들 전원 1개월 유료 멤버십 구독권을 선물드립니다. 유료 멤버십에서는 아래와 같은 혜택이 제공됩니다.
- DevPill과의 1:1 온라인 커피챗
- 멤버십 전용 슬랙 채널 참여권
- 채용 정보 공유 / 스터디 그룹 형성 / 실시간 기술 질의응답
- 이력서/포트폴리오 템플릿

의견을 남겨주세요