

지난 레터에서 데이터가 생성되어 저장되기 까지 일련의 과정을 데이터 파이프라인이라고 했습니다. 데이터 파이프라인은 크게 아래 4단계로 분류할 수 있습니다.
1. 데이터 생성
2. 데이터 수집
3. 데이터 가공 후 저장(ETL)
4. 데이터 시각화(BI)
이번 글에서는 데이터 생성에 대해 다뤄보겠습니다. 앞으로는 데이터 파이프라인의 과정과 함께 데이터 직군(데이터 엔지니어, 데이터 분석가 등)이 하는 일도 다룰 계획입니다 (찡긋)
서비스 데이터와 로그 데이터
IT 회사에서 관리하는 데이터를 크게 나눠보면 서비스 운영에 필요한 데이터와 서비스에서 발생한 로그 데이터로 구성됩니다.
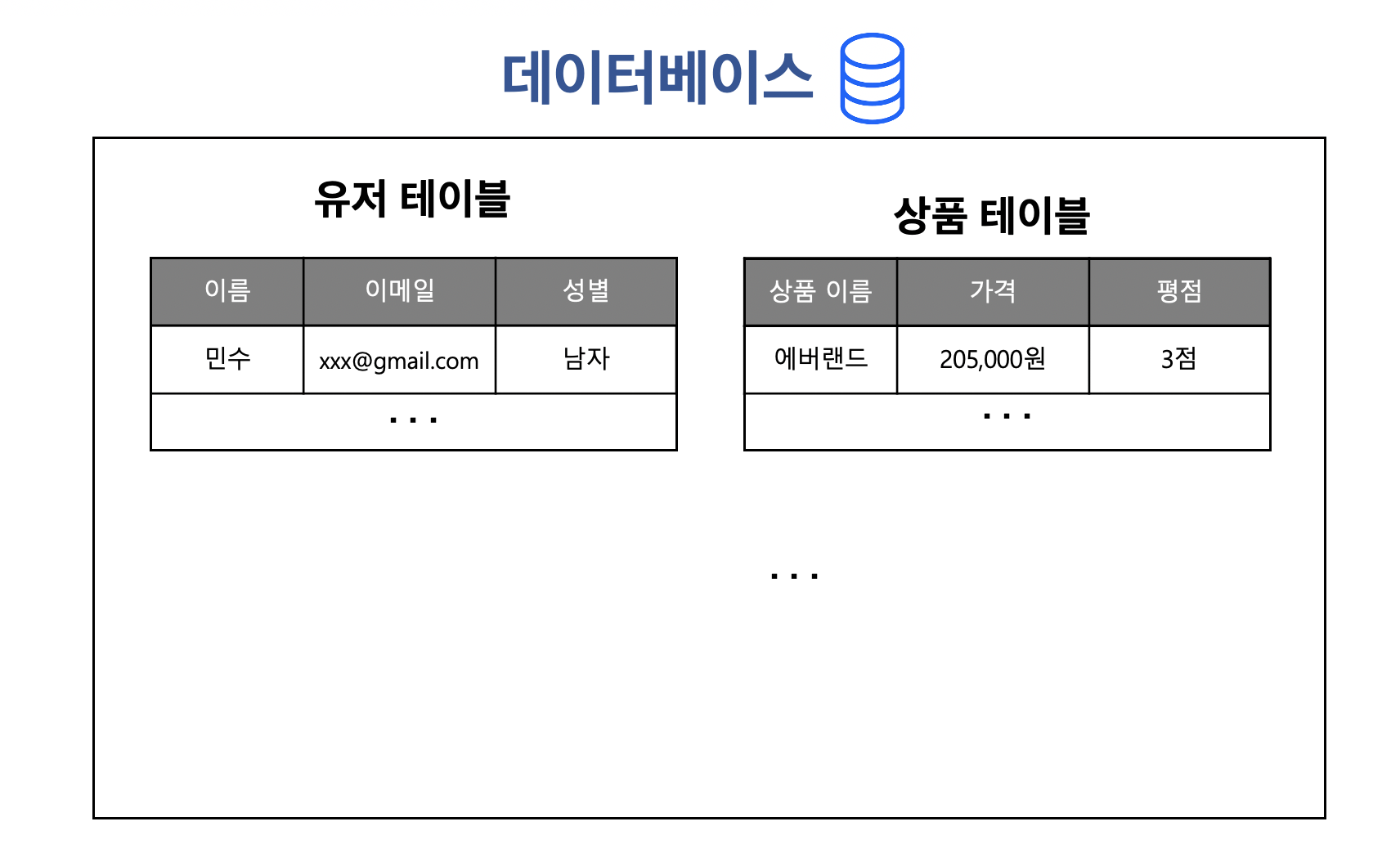
서비스 데이터는 쿠팡을 예로 들면 상품 정보, 고객 정보, 결제 정보 등을 생각하면 됩니다. 이들은 서비스 운영에 꼭 필요한 친구들이고 철저한 보안 관리를 받는 데이터베이스에 저장됩니다. 만일 이 데이터베이스가 해킹 당한다는 건 IT 회사의 생명이 끝나는 것과 다름이 없죠.
일반적으로 서비스 데이터는 따로 데이터 파이프라인을 거치지 않습니다. 해당 데이터의 생성 속도가 빠르지 않으며 오히려 데이터의 관리(보안, 성능)에 더 신경을 써야 하기 때문입니다. 그래서 서비스 데이터를 따로 관리하는 직군으로 DBA가 있으며 여러 클라우드 사에서 보안, 성능을 최적화한 데이터베이스 상품을 앞다투어 판매하고 있죠.
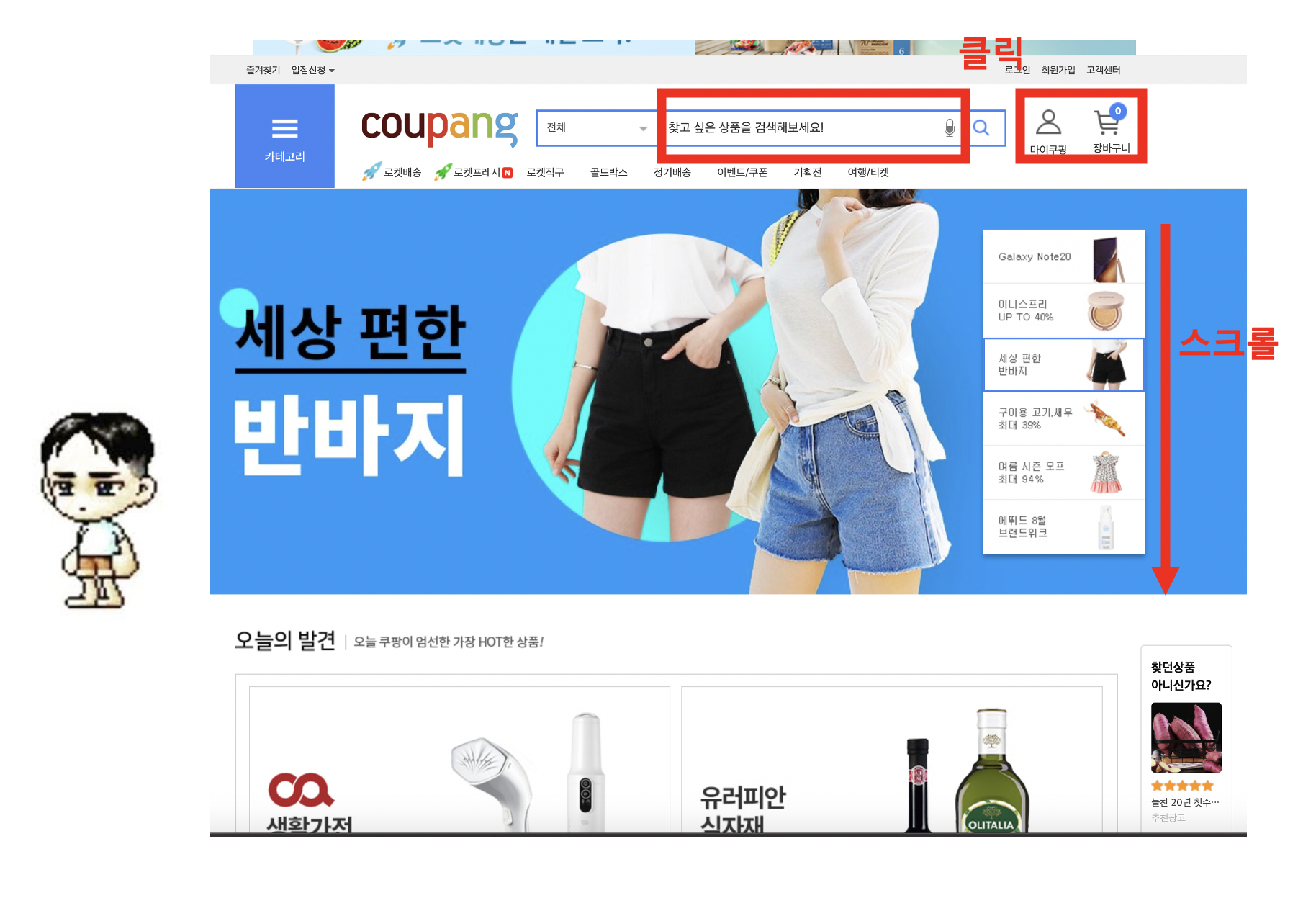
로그 데이터는 서비스를 운영하면서 생기는 모든 행위를 기록(로그)으로 남긴 데이터예요. 유저가 서비스(웹, 앱 등)를 이용하면서 클릭, 스크롤, 머무르기 같은 이벤트가 발생하게 됩니다. 이때 이런 이벤트를 기록한 결과들은 전부 로그 데이터라고 볼 수 있습니다.
로그 데이터는 크게 유저들이 서비스(웹, 앱)를 사용하면서 생성되는 클라이언트 로그와 백엔드 서버에서 발생하는 서버 로그로 나눌 수 있어요. 서버 로그는 보통 백엔드 개발자들이 서버에 발생한 이상 징후나 패턴을 찾을 때 사용합니다. 반면 클라이언트 로그는 고객들의 행동을 분석하는 데 사용되기 때문에 다양한 직군이 클라이언트 로그를 활용하게 되죠.
업종마다 다르겠지만 IT 회사에서 다루는 데이터 양의 대부분은 로그 데이터가 차지합니다. 한 명의 유저가 웹 사이트나 앱에 잠깐 접속하더라도 적게는 10개 많게는 100개 이상의 로그 데이터가 생성되는데 수천, 수만 명의 유저가 방문한다면 정말 많은 트래픽의 데이터를 견뎌야겠죠?
[참고]
우리가 앞으로 다룰 데이터는 로그 데이터라고 보셔도 무방합니다.
데이터 생성
데이터를 생성한다는 것은 각 도메인을 맡는 개발자가 데이터를 생성해서 서버로 전송하는 코드를 짠다는 것을 의미합니다. 예를 들어 웹 서비스에서 결제 버튼 클릭을 표현하는 클라이언트 로그를 추가하고 싶다면 프론트엔드 개발자가 코드를 추가합니다. 만일 API 서버에서 회원가입 요청이 얼마나 왔는지 확인하고 싶다면 백엔드 개발자가 코드를 추가해야겠죠.
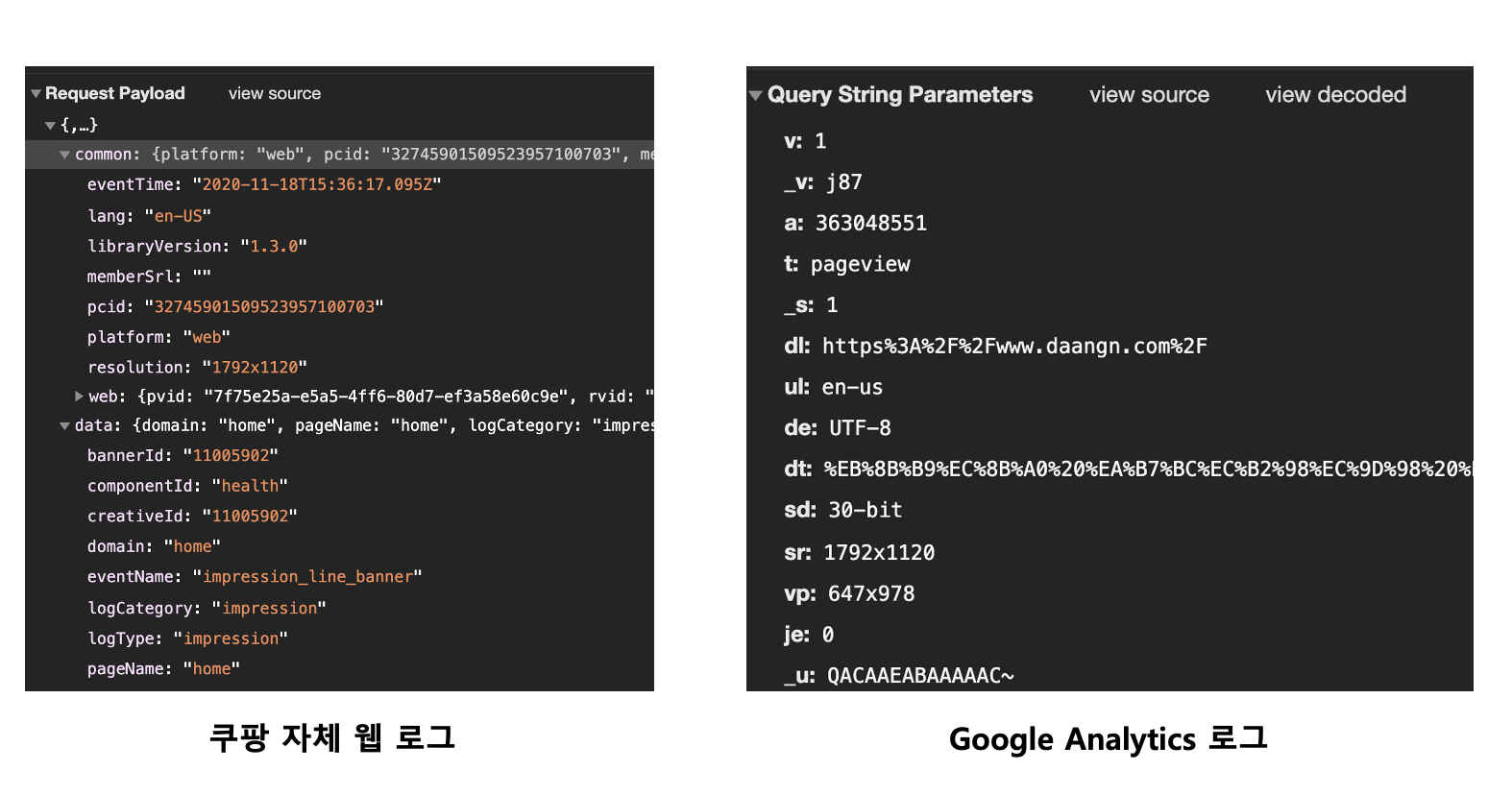
참고로 데이터가 저장되는 서비스에 따라 데이터의 형식이 달라집니다. Google Analytics나 Amplitude 같이 SAAS 형태로 제공되는 분석 툴의 경우 그곳에서 요구하는 데이터 형식에 맞게 코드를 새롭게 짜는 과정이 필요합니다. 만일 서드 파티 툴과 함께 자체적으로 데이터를 관리한다면? 데이터를 관리하기가 더욱 복잡해지겠죠. 그래서 데이터를 생성할 때도 아키텍처를 잘 설계해서 관리하는 게 중요합니다💪🏼
[참고]
요새 데이터 관리를 손쉽게 도와주는 CDP(Customer Data Platform)가 급부상하고 있습니다. CDP를 이용하면 한 번의 데이터 생성만으로 다양한 데이터 저장소에 맞는 형식으로 저장을 합니다
(참고 : Segment)
의견을 남겨주세요