

안녕하세요 구독자 여러분!
벌써 내일이면 한 해를 마무리하는 12월이 다가옵니다. 저는 오늘로 해서 회사를 퇴사한 지 1년이 됩니다. 퇴사할 때는 외주나 받아서 1년 정도 디지털 노마딩이나 하자는 가벼운 생각을 하고 있었는데, 지금 제 행보를 보고 있자니 사람 인생은 정말 예측할 수 없나 봅니다 ㅎㅎ
여러분들의 관심 덕분에 (IT 관종) 그랩의 뉴스레터가 곧 구독자가 1000명이 됩니다! 그래서 여러분들과 함께 할 수 있는 소소한 이벤트를 준비해봤습니다.
이벤트 상품으로 55,000원 상당의 [IT 회사에서 살아남기 위한 모든 개발 지식 A to Z] 강의 수강권을 드립니다(소리 질러!)

참여 방법은 간단해요. 뉴스레터 하단에 초대 링크가 있습니다. 하단 링크를 복사해서 친구들에게 소개해주세요!😊 (그랩의 IT 뉴스레터를 떡상시켜 주세..)
친구를 초대해주신 분들 중 아래 조건에 해당하시는 모든 분들에게 아래 상품을 드립니다 :)
15명 초대 : 개발지식 강의 수강권
10명 초대 : 강의 50% 할인 쿠폰( 27,500원 할인)
이번 뉴스레터에서는 데이터 파이프라인의 3번째 과정인 데이터 가공에 대해서 다루도록 하겠습니다.
1. 데이터 생성
2. 데이터 수집
3. 데이터 가공
4. 데이터 분석 & 시각화
데이터 가공
시간이 지날수록 데이터를 저장하는 디스크(SSD)의 성능이 점점 좋아지고 있으며 클라우드에서도 더 값싸게 데이터를 저장해주는 공간을 제공해줍니다. 그래서 이제 개인도 충분히 원하는 데이터를 저렴한 가격에 저장할 수 있게 됐습니다.
IT 회사에서는 정말 많은 데이터들을 저장하고 관리해야 합니다. 회사 내에서는 ERP 같이 사내 데이터를 관리하는 데이터베이스가 필요합니다. 그리고 서비스를 제공하기 위해서 서비스 데이터베이스가 꼭 있어야 하며 사용자들이 서비스를 이용하면서 남기는 클라이언트 로그도 저장해야 하죠. 이 뿐만 아니라 각 서버들의 로그도 남겨야 하고, 3rd party 서비스에서 발생하는 데이터들까지...
현재는 데이터 춘추 전국 시대입니다. 데이터 저장을 제공해주는 서비스마다 장단점이 있어 자연스럽게 여러 서비스를 사용할 수밖에 없는 거죠.
이렇게 다양한 데이터 소스로부터 데이터를 분석해야 한다면 어떨까요? 예를 들어 '페이스북 광고를 타고 들어와 A 상품을 구매한 고객들이 관심 있어하는 상품들' 을 추출하고 싶다면 어떨까요? 기본적으로 아래와 데이터 소스로부터 데이터를 가져와서 가공하는 작업까지... 저는 벌써부터 머리가 아파옵니다.
1. 페이스북 광고 픽셀 데이터
2. 서비스 데이터베이스(유저, 상품, 결제 데이터)
3. GA 데이터(유저 행동 분석 데이터)
이 글을 쓰는 와중에 데이터와 홀연히 싸우고 계시는 데이터 분석가 분들에게 심심한 위로를 보냅니다. 실제로 데이터 분석가는 핸썸하게 SQL로 데이터를 분석하는 일만 하지 않습니다. 정상적으로 데이터를 추출하고 데이터 형식을 통일시키기 위해 수많은 노가다 작업이 포함되어 있죠 흑흑
그래서 데이터가 많은 IT 회사에서는 다양한 데이터 소스의 데이터를 한 곳에 취합하는 작업을 합니다. 그렇게 되면 데이터를 관리하고 분석하는 데에 맨먼스(manmonth)가 확연히 줄어들 겁니다.
ETL
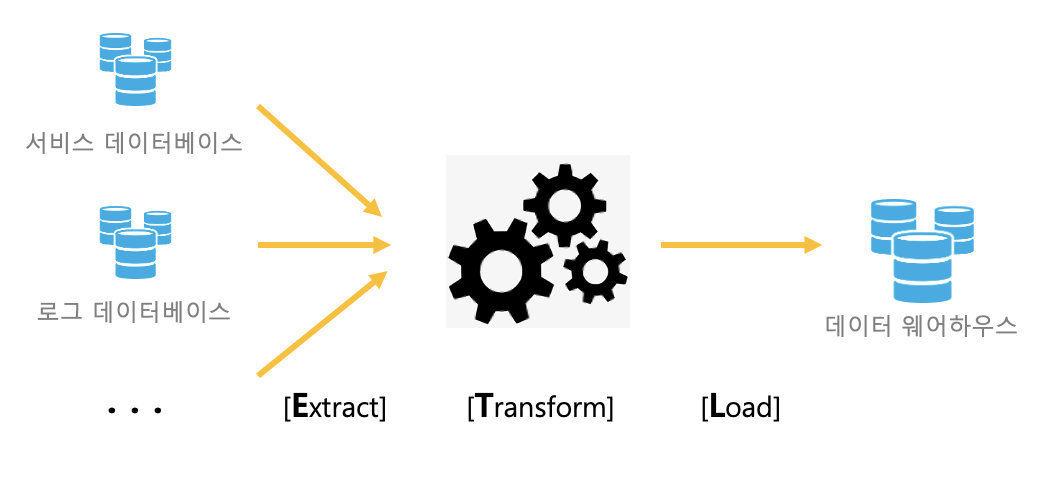
다양한 데이터 소스들을 관리하기 쉽게 한 군데로 취합하는 대표적인 프로세스로 ETL가 있습니다. ETL은 Extract, Transform, Load의 약자로 데이터를 가공하는 과정이라고 보시면 됩니다.
[참고]
요새는 ETL 프로세스를 자동화하도록 도와주는 SAAS 제품도 늘어나고 있습니다. 대표적으로 FiveTran, Panoply 등이 있으며 더 로우 레벨로 개발하는 대신 확장성이 높은 Airflow도 업계에서 점점 표준이 되고 있습니다.
Extract
산발적으로 흩어져 있는 데이터 소스로부터 데이터들을 가져오기 위해선 추출하는 과정이 필요합니다. 이를 Extract라고 합니다. 보통 클라우드 서비스에서 손쉽게 데이터를 추출하도록 많이 자동화가 되어있는 편입니다.
Transform
Transform은 데이터를 가공하는 작업입니다. 여러 데이터베이스에 저장된 데이터는 형식이 각기 다릅니다. 이들을 한 군데로 이쁘게 정렬시키기 위해선 데이터 형식에 맞게 데이터를 변형해주는 작업이 꼭 필요합니다. 또한 회사에서 지향하는 데이터 목적성에 맞게 필터링을 하는 과정도 필요하겠네요.
이때 가공되기 전의 데이터, 즉 데이터 소스에 저장된 데이터를 비정형 데이터라고 한다면 가공된 데이터를 정형 데이터라고 합니다. 보통 빅데이터라는 키워드의 핵심 중 하나로 비정형 데이터들을 정형 데이터로 가공하는 작업이 있답니다.
Load
최종적으로 데이터 변형이 완료됐다면 데이터 웨어하우스에 적재(Load)하는 과정이 남아있습니다. 데이터 웨어하우스는 규칙적(Relational)으로 데이터를 저장하도록 돕는 일종의 데이터베이스로 대용량의 데이터를 관리하기에 최적화된 데이터베이스라고 보시면 됩니다.
최종적으로 데이터 분석가, 사이언티스트, 머신러닝 엔지니어 등이 데이터 웨어하우스에 저장된 데이터를 사용한다고 보시면 됩니다. 그리고 데이터 웨어하우스에 데이터를 안전하게 적재하는 작업은 데이터 엔지니어가 맡게 되죠.
ELT?
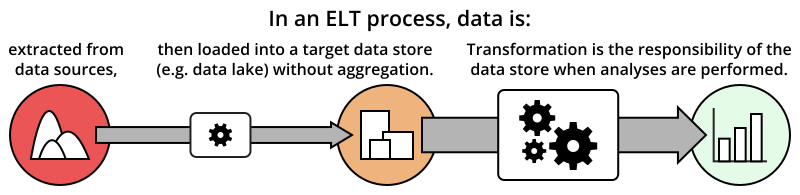
최근에는 ELT 프로세스가 화두가 되고 있어요. 기존에 ETL 프로세스에서 Transform 과정은 생각보다 많은 컴퓨팅 파워(=비용)를 필요로 하며 생각보다 손을 많이 타는 작업이에요. 그래서 데이터를 우선 한 곳에 먼저 적재(Load)한 후 필요에 따라 Transform을 하는 ELT 과정이 인기를 끌고 있습니다. 이때 데이터들을 한 곳에 빠르게 저장하는 공간을 데이터 레이크라고 부릅니다(데이터 웨어하우스에서 비슷한 역할을 제공해주기도 합니다)
여기까지 해서 데이터 가공 프로세스에 대해 알아봤습니다. 다음 편에서는 데이터 웨어하우스에 저장된 데이터를 시각화 & 분석하는 과정에 대해 알아봐요! 안녕!!
의견을 남겨주세요