
안녕하세요 구독자 여러분. 그랩입니다😗 날씨가 많이 쌀쌀해졌는데 여러분은 감기 조심하시길 바랍니다 (저는 독감이 심하게 와서 고생 중입니다 😂)

이번 시리즈는 'IT 회사에서 데이터가 흐른다는 것'을 주제로 선정했습니다.
요즘 같은 시대에 데이터의 중요성은 날이 갈수록 부각되고 있어요. 수많은 데이터를 저장할 수 있는 하드웨어가 받쳐주다 보니 컴퓨터 안에서 발생하는 대부분의 이벤트를 데이터로 저장시키고 있죠. 실제로 유저가 브라우저, 모바일 앱에서 일으키는 이벤트(클릭, 스크롤 등)뿐만 아니라 회사의 서버 컴퓨터에서 남기는 로그 데이터도 정말 어마어마합니다.
[참고]
우리가 브라우저에서 스크롤하고 페이지를 이동하는 것이 전부 녹화될 수 있다는 사실 알고 계셨나요?
정성 데이터 분석 툴 Hotjar의 Screen Recording 기능
요즘 같은 시대엔 클라우드(AWS, Azure 등)에서 손쉽게 데이터를 저장할 수 있도록 데이터 공간을 제공해줍니다. 그래서 코드 몇 줄만 짜면 손쉽게 데이터를 전송할 수 있으며 정형화된 분석 템플릿을 이용해서 쉽게 데이터를 분석할 수 있습니다.
그래서 요새 IT 회사에서는 '데이터 기반 의사결정(Data Driven)'이 대세입니다. 예전에 데이터가 부족했을 때는 리더의 경험과 감에 의존해서 의사결정을 했었다면 데이터 드리븐은 데이터를 기반으로 핵심 의사결정을 하게 됩니다. 이제는 손쉽게 데이터를 쌓고 분석할 수 있기 때문이죠.
요새 IT 서비스가 성장할 때 꼭 언급이 되는 '그로스 해킹'도 데이터를 통한 지표에 100% 가까이 의존합니다.
🔗토스팀에 데이터가 흐르게 하는 데이터 플랫폼 팀을 만나다
🔗데이터가 흐르는 조직 만들기 - 마이리얼트립
[참고]
Google Analytics, Amplitude 같은 분석 툴을 활용하면 개발자가 없더라도 데이터를 손쉽게 분석할 수 있습니다.
데이터 파이프라인 개요
IT 서비스를 사용하는 입장에서는 전혀 눈치채지 못하지만 뒤에서는 생성된 데이터를 무사히 저장소에 저장하기 위해 여러 서버 컴퓨터들이 분주하게 일을 하고 있습니다. 데이터를 생성해서 무사히 저장하기까지 일련의 과정을 데이터 파이프라인이라고 합니다.
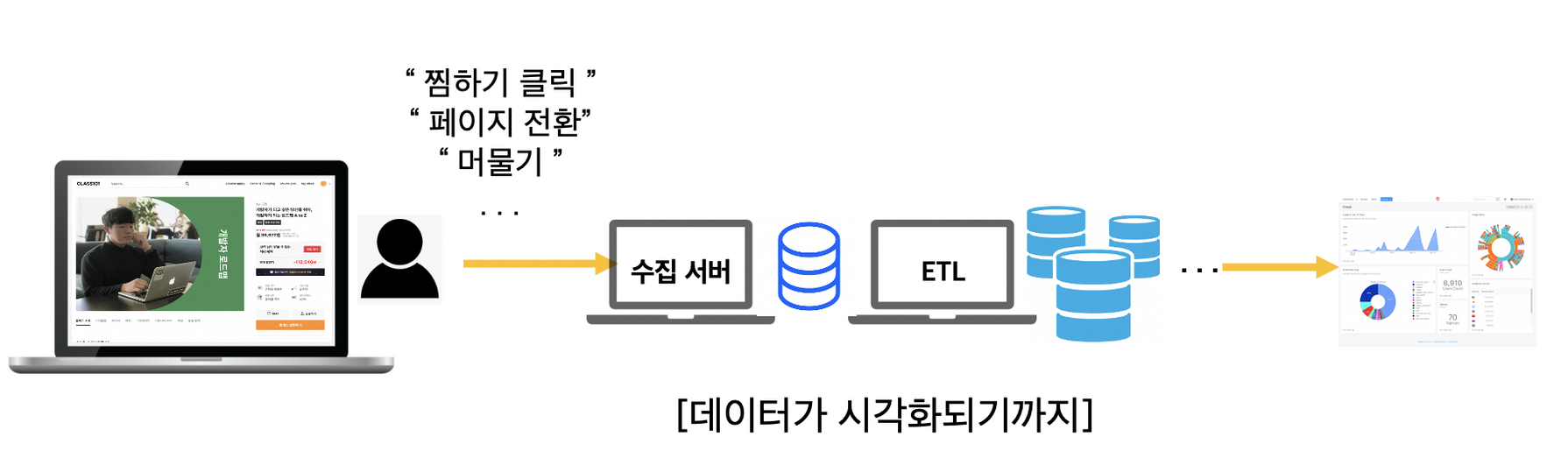
데이터 파이프라인을 큼지막하게 본다면 아래와 같이 나눌 수 있어요.
1. 데이터 생성
2. 데이터 수집
3. 데이터 가공 후 저장(ETL)
4. 데이터 시각화(BI)
데이터를 저장하는 과정이 복잡한 이유는 데이터가 누수되지 않고 안전하게 저장되게 하기 위해서죠. 실제로 수많은 사용자들을 둔 서비스의 경우 매 초마다 수천, 수만의 데이터가 생성됩니다. 이들이 모두 데이터 저장소(데이터 웨어하우스, 데이터 레이크 등)에 저장되기 위해선 각자의 역할을 가진 컴퓨터들이 협동해야 합니다.
데이터 파이프라인을 구축하기 위해 IT 회사에서는 데이터 엔지니어를 필요로 합니다. 역할 별로 데이터를 처리하는 서버 컴퓨터들을 관리하고 분석할 수 있는 형태로 데이터를 가공하고 시각화하는 작업을 하죠.
소규모의 서비스에는 SAAS 형태의 분석 툴(GA, Amplitude 등)로 충분하지만, 규모가 커지면 데이터 엔지니어가 직접 데이터 환경을 구축하는 게 낫습니다(경제성, 데이터 정합성 측면 등)
다음 챕터부터는 데이터 파이프라인의 구성 요소에 대해서 알아보도록 하겠습니다😊
의견을 남겨주세요
Saasduckwho
이번에도 좋은 꿀팁 잘 읽고 갑니다! 데이터 엔지니어 정말 필요한 소중한 롤입니다!
그랩의 IT 뉴스레터
공감합니다. 요즘 같은 시대에 꼭 필요합니다 ㅠㅠ
의견을 남겨주세요