
서비스를 운영하기 위해서는 DB는 당연히 사용해야 합니다. 그렇지 않으면 모든 데이터가 휘발되기 때문에 일시적인 서비스 밖에 만들 수 있는 것이 없죠.
우리는 좋은 서비스를 운영하기 위해서 DB를 공부해야 합니다. 그래야 비지니스 로직에 알맞은 자료구조를 선택해서 사용하는 것처럼, DB도 필요에 맞게 사용할 수 있기 때문이죠.
하지만 DB의 세계는 너무 거대합니다. RDB와 NoSQL 차이부터 시작해서 깊게 들어가면 들어갈 수록 머리가 아파지죠.

그러면 대체 어디까지 공부해야할까요? 저는 개인적으로 비지니스 로직에 맞는 DB를 선택할 수 있을 정도까지라고 생각합니다.
각 DB의 특성을 비교할 수 있고, 어떤 유즈케이스에 사용되는 지 정도를 알고 있으면 개발자에게는 충분합니다. 그 외 나머지의 영역은 서비스를 운영하면서 배워가는 게 맞지 않을까요?
그렇다면 주니어 개발자가 알아 두면 좋은 DB 지식은 무엇일까요?
각 회사마다 요구하는 능력치가 다르지만, 저는 DB 전체적으로 통용되는 개념들을 알고 있으면 된다고 생각합니다. 이런 걸 알고 있으면 다른 DB를 이해할 때 도움이 많이 되기 때문이죠.
그래서 이 글에서는 주니어 개발자가 DB에 대해 알았으면 하는 것을 준비했습니다.
DB도 서버야! 서버!
그렇습니다. DB도 서버입니다.
다르게 말하면, DB도 컴퓨터라고 말하는 것이 좋겠네요. DB도 CPU가 있고 메모리가 있고 Disk가 있는 컴퓨터입니다. 그래서 여러분이 배운 네트워크, 운영체제의 지식들이 DB에서도 사용되고 있습니다.
어플리케이션에서 DB에 데이터를 넣고 뺄 때, 사실은 다른 서버에 API를 쏘고 있는 것과 똑같다는 말이죠.
그러면 이들은 어떻게 통신하는 걸까요? 정답부터 말하자면, TCP/IP 를 통해 통신을 하고 있습니다.
이들은 요청을 제대로 전달하기 위해서 TCP를 이용하고 있습니다. 만약 연결이 불안정해서 지속적으로 몇몇 요청을 분실해 버린다면, 서비스를 신뢰하지 못하겠죠. 그래서 DB는 다른 서비스와 연결할 때, 비교적 안정적인 TCP를 이용합니다.
근데 이 TCP는 위에서도 보았다 싶이 신뢰성을 보장하기 위해서 여러 절차를 수행합니다. 이 작업이 굉장히 코스트하죠. DB에 요청을 보낼 때마다 이 연결을 계속 만들었다가 끊었다가를 반복하면 그만큼 비효율적인 일이 없습니다.
그래서 성능저하를 피하기 위해서 미리 그 연결점들을 맺어 놓습니다. 그리고 그 연결점들을 커넥션 풀(Connection Pool)이라고 부릅니다.
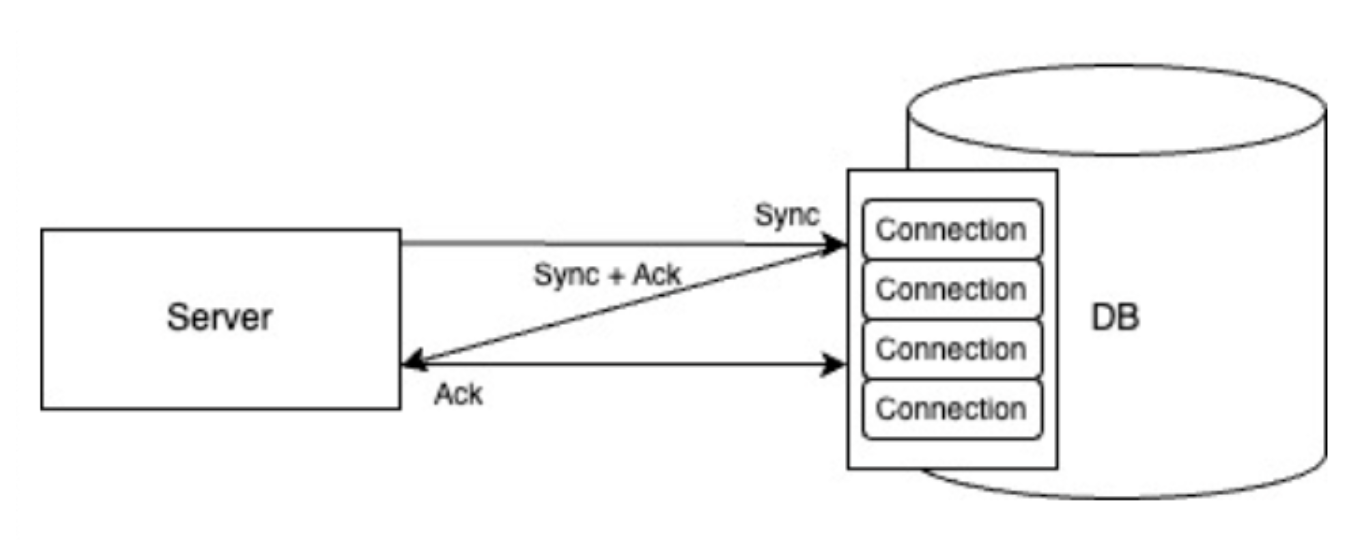
커넥션 풀은 미리 연결시킨 통로들을 모아 놓은 것이라고 이해하면 좋습니다. 요청이 동시에 여러 개 들어올 수 있으니 일정량의 통로를 미리 준비한 것입니다.
실제로 어플리케이션 서버가 켜지면 미리 DB와의 연결을 만들어 놓습니다. 그 이후의 요청들은 모두 그 연결을 통해서 진행되는 것이죠. 미리 다 연결되어 있으니 요청들이 빠르게 수행될 수 있고요.
참고로 이 커넥션 풀에서 미리 준비한 Connection 개수 이상으로 요청이 들어오게 되면, 앞선 요청들이 처리될 때까지 요청이 대기하게 됩니다. 그래서 이 커넥션 풀의 개수를 어떻게 조절하는 지가 서비스의 성능을 좌우하게 됩니다.
??? : 내가 속도의 한계를 보여줄게
혹시 DB로 보내진 데이터들은 어디로 갈까 생각해보셨나요? 그들은 일반적으로 Disk 에 적재가 됩니다. 디스크로 들어가고 다시 디스크에서 꺼내는 것이죠. 따라서 Disk 에 대해서 조금은 이해를 하고 있어야 합니다.

디스크는 CD 나 LP판 처럼 생겨 빙글빙글 돌아가고 있습니다. 대충 1분에 1만번 정도 돌아간다고 생각하면 되겠네요. (제 행복회로만큼 돌아가는 군요.)
디스크를 읽고 쓰기 위해서는 특정 지점에 헤드(Head)라고 불리는 침을 가져가야합니다. 그 특정지점에 도달하는 것을 탐색(Seek)이라고 부릅니다. 디스크에서 원하는 정보가 있는 위치가 회전해서 다가올 때까지 기다리다가 도달하면 데이터를 읽고 쓰게 되는 것이죠.
1분에 1만번 정도면 사실 굉장히 빠르지만 컴퓨터랑 비교하자면 굉장히 느립니다. 간단히 비교해서, 전기신호와 기계동작이랄까?
메모리에서 I/O하는 것은 nano-second이지만, Disk에서 I/O는 milli-second 이거든요. 이런 Seek Time 때문에 메모리보다 디스크가 느리다고 하는 겁니다.
디스크가 데이터에 접근하는 방법은 크게 두 가지(Sequential Access, Random Access)로 나뉩니다.
Sequential Access은 순차적으로 모든 데이터에 접근하는 방식입니다. 처음부터 끝까지 순서대로 다 읽는 동작이라고 볼 수 있습니다. 흔히 말하는 풀스캔(Full Scan)이 Sequential Access로 이루어집니다.
Random Access은 필요한 부분만 쏙 가져오는 것이죠. 위에서 말한 것처럼 특정 위치에 도달하기 위해서 Seek Time이 소요됩니다.
두 접근 방식을 비교하자면 당연히 Sequential Access가 압도적으로 빠릅니다.
정리하자면, 제가 여기서 이야기하고 싶은 것은 메모리와 디스크의 차이, 그리고 디스크의 접근방법입니다. 이 두 개가 왜 중요할까요?
바로 다른 데이터 저장소에 대해 이해하는 데 도움을 주기 때문입니다. 예를 들어서 설명하자면 다음과 같습니다.
여러분 혹시 Redis에 대해서 아시나요?
The open source, in-memory data store used by millions of developers as a database, cache, streaming engine, and message broker.
Redis
Redis는 다른 DB들보다 빠르다는 평가를 받고 있습니다. 그 이유는 바로 in-memory data store를 이용하기 때문입니다. 당연히 메모리가 디스크 저장방식보다 빠르기 때문에 속도면에서 이점이 있는 것이죠.
혹은 Kafka에 대해 아시나요?
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Apache Kafka
Kafka는 디스크를 이용하는 저장소입니다. 하지만 다른 Disk 저장소보다 빠르죠. 그 이유는 무엇일까요? 바로 내부적으로 Sequential I/O를 하고 있기 때문이죠.
당연히 이것만이 두 저장소들이 빠른 이유의 전부는 아닙니다. 하지만 이해를 하는데 도움을 주는 것은 당연하죠.
요약하자면,
- Connection Pool: DB 는 요청 처리할 수 있는 커넥션 풀(Connection Pool)을 미리 준비해두며, 이 관리법에 따라 성능 차이가 존재한다.
- Disk vs Memory: DB 응답은 디스크 또는 메모리에 적재된다. 디스크는 Seek Time 이 소요되기 때문에 Memory 보다 일반적으로 느리다.
- Sequential vs Random Access: 랜덤 탐색은 필요한 위치에 접근하는 동안 탐색 시간이 길고, 순차 탐색은 순서대로 탐색하기 때문에 랜덤보다 빠르다.
의견을 남겨주세요