

이번 주 목차
- 5,000만 줄 코드를 하루 만에 — Claude Fable 5가 바꿔버린 엔지니어링의 상식
- AI가 스스로를 만든다 — Anthropic의 재귀적 자기개선 연구
- 8주 만에 1.5년치 수학 실력 향상 — AI 튜터가 드디어 증거를 내놓았어요
5,000만 줄 코드를 하루 만에 — Claude Fable 5가 바꿔버린 엔지니어링의 상식 🤖

Anthropic이 2026년 6월 9일, Claude Fable 5와 Claude Mythos 5를 동시에 발표했어요. 두 모델의 성격은 완전히 다르지만, 하나의 메시지는 동일해요. AI가 이제 '도구'가 아니라 '동료' 수준으로 올라섰다는 것이죠.
Fable 5: 벤치마크 석권보다 중요한 건 Stripe의 개발 사례
스펙 얘기를 먼저 하자면, Claude Fable 5는 소프트웨어 엔지니어링(Software Engineering), 지식 업무, 비전(Vision), 과학 연구 등 거의 모든 주요 벤치마크에서 현존 최고 성능을 기록했어요. 그런데 숫자보다 훨씬 와닿는 이야기가 있어요.
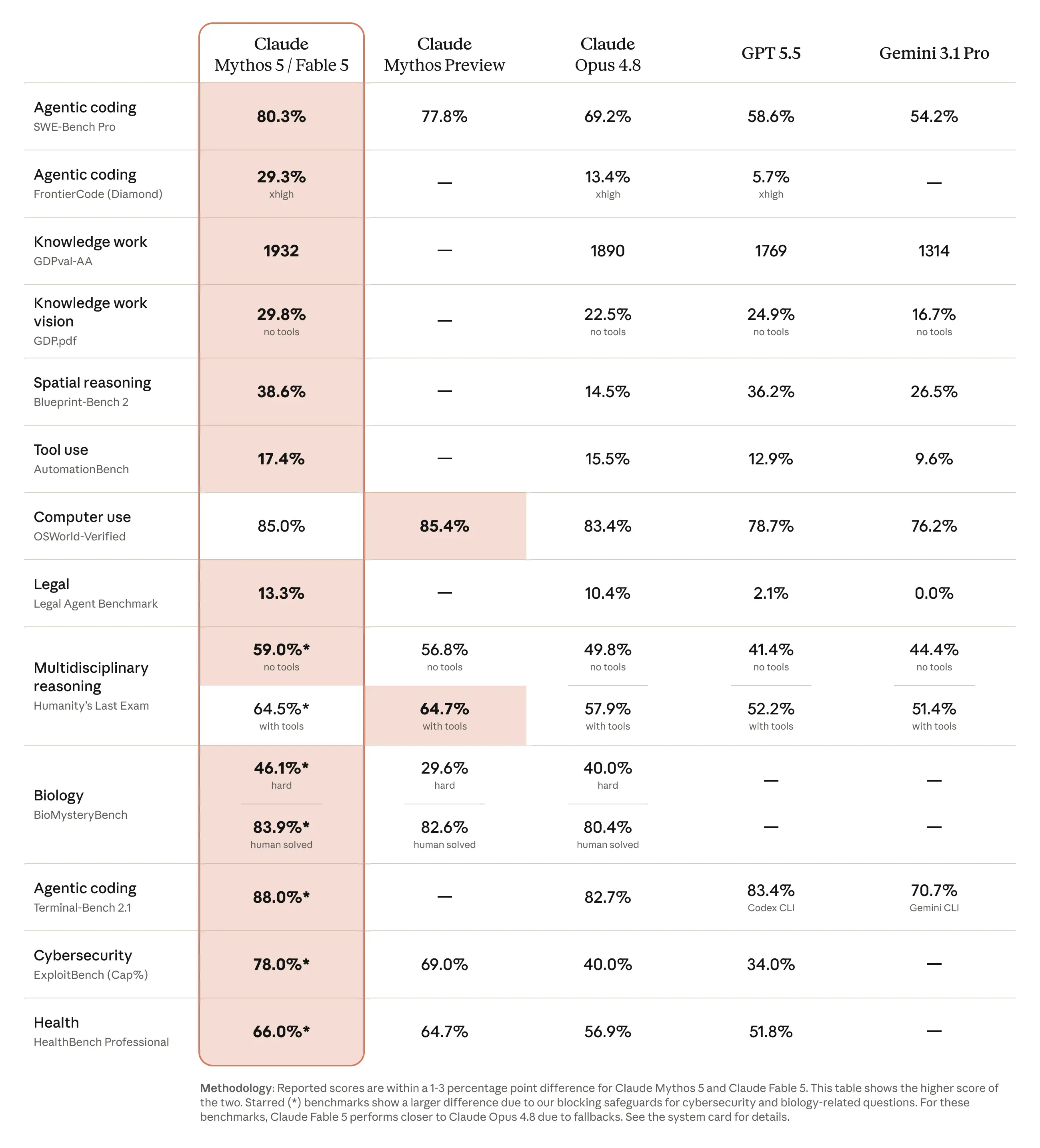
결제 인프라 기업 Stripe는 수년간 묵혀온 숙제가 있었어요. 무려 5,000만 줄 규모의 Ruby 코드베이스 마이그레이션(Migration)이요. 기술 부채(Technical Debt)의 화석이라고 불러도 될 만한 이 작업을, Stripe의 엔지니어링 팀은 Claude Fable 5를 활용해 단 하루 만에 완료했어요.
엔지니어링 조직 입장에서 이게 무슨 의미인지 생각해 보면, 분기 단위로 계획하던 레거시(Legacy) 정리 작업이 이제 스프린트(Sprint) 한 사이클 안에 들어올 수 있다는 거예요. 인력 계획, 로드맵(Roadmap), 기술 부채를 다루는 방식 전체가 재설계될 수밖에 없는 수준이에요.
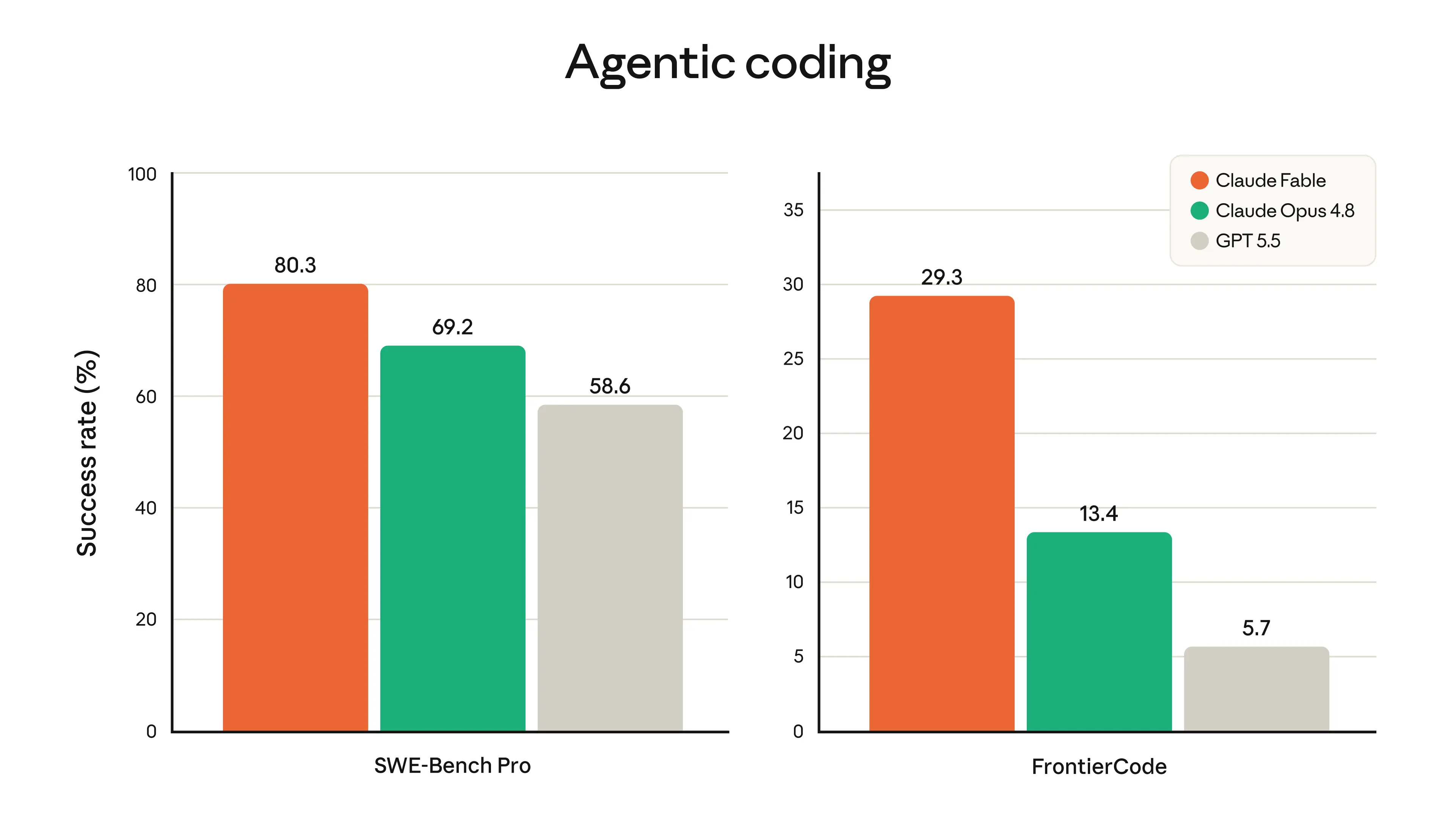
가격도 눈에 띄어요. 입력 $10/M, 출력 $50/M으로, 직전 세대인 Mythos Preview 대비 절반 이하로 내려왔어요. 성능은 올리고 가격은 낮춘, 전형적인 Anthropic식 공세예요.
Mythos 5: 일반인은 못 쓰는 사이버보안 모델
Claude Mythos 5는 조금 다른 결을 가져요. Project Glasswing이라는 채널을 통해 미국 정부 사이버 방어 기관과 핵심 인프라 제공자에게만 제한적으로 공개돼요. Anthropic은 이 모델이 세계 최강 수준의 사이버보안(Cybersecurity) 역량을 갖췄다고 밝혔어요.
일반 사용자가 접근할 수 없다는 점이 오히려 메시지를 선명하게 해요. AI 능력의 첨단이 이제 군사·안보 영역과 맞닿기 시작했다는 거죠. OpenAI, Google이 각각 국방부, 정부 기관과 계약을 확대하는 흐름 속에서, Anthropic도 본격적으로 이 판에 발을 들인 셈이에요. AI 군비경쟁(AI Arms Race)의 새로운 챕터가 열린 거예요.
AI가 스스로를 만든다 🤖 — Anthropic의 재귀적 자기개선 연구
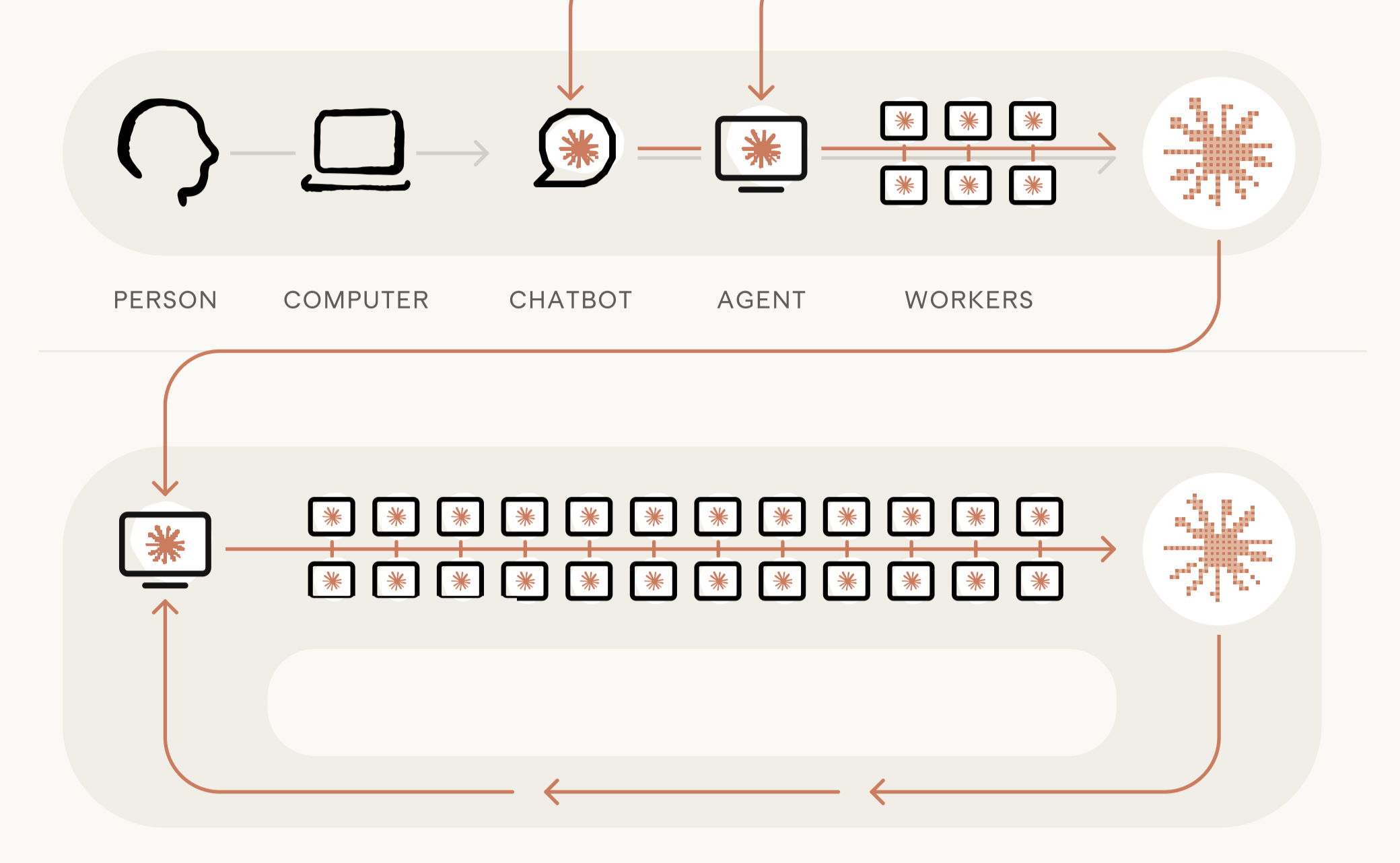
AI가 자기가 스스로 자신을 훈련하고, 개선할 수 있을까요? Anthropic이 공개한 When AI builds itself 리포트는 이 상상이 이미 현실이 되고 있다는 점을 내부 데이터로 증명해 보였습니다. 2026년 2분기 기준, Anthropic 엔지니어 한 명이 하루에 병합하는 코드량은 2024년 대비 8배에 달했어요. Claude Code가 2025년 2월 출시된 이후 전체 코드베이스에 병합된 코드 중 Claude가 작성한 비중은 80% 이상으로 올라갔습니다. 단순한 자동완성이나 코드 제안 수준을 훨씬 넘어선 이야기입니다.
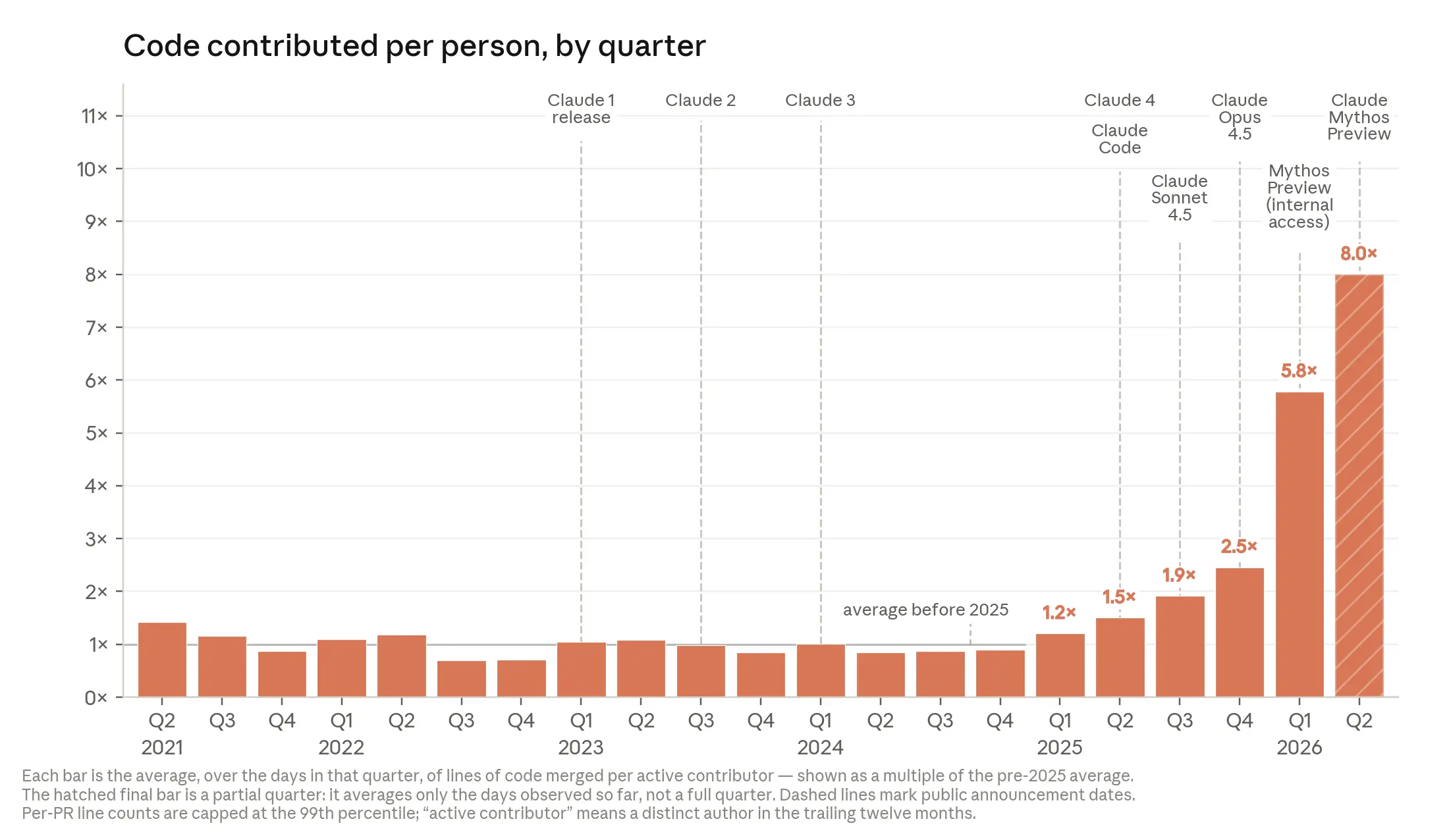
출처: Anthropic — 엔지니어 1인당 코드 기여량. 2025년 Claude Code 출시, 2026년 자율 에이전트 전환 시점에서 두 번의 급격한 상승이 나타납니다.
재귀적 자기개선(Recursive Self-Improvement)
이 리포트의 핵심 개념은 재귀적 자기 개선(Recursive Self-Improvement) 입니다. AI가 스스로의 후속 버전을 설계하고 개발하는 단계를 의미해요. Anthropic은 "아직 그 단계에 도달하지 않았다"고 명시하면서도, 현재의 가속 추세가 많은 기관들이 준비하는 것보다 훨씬 빠르게 그 시점을 앞당길 수 있다고 경고합니다. 외부 벤치마크에서도 이 흐름은 선명하게 드러나요. AI 시스템이 독립적으로 수행 가능한 태스크의 시간 범위는 약 4개월마다 두 배씩 늘어나고 있고, Claude Opus 4.6은 인간 기준으로 12시간짜리 작업을 처리할 수 있는 수준에 이르렀습니다.
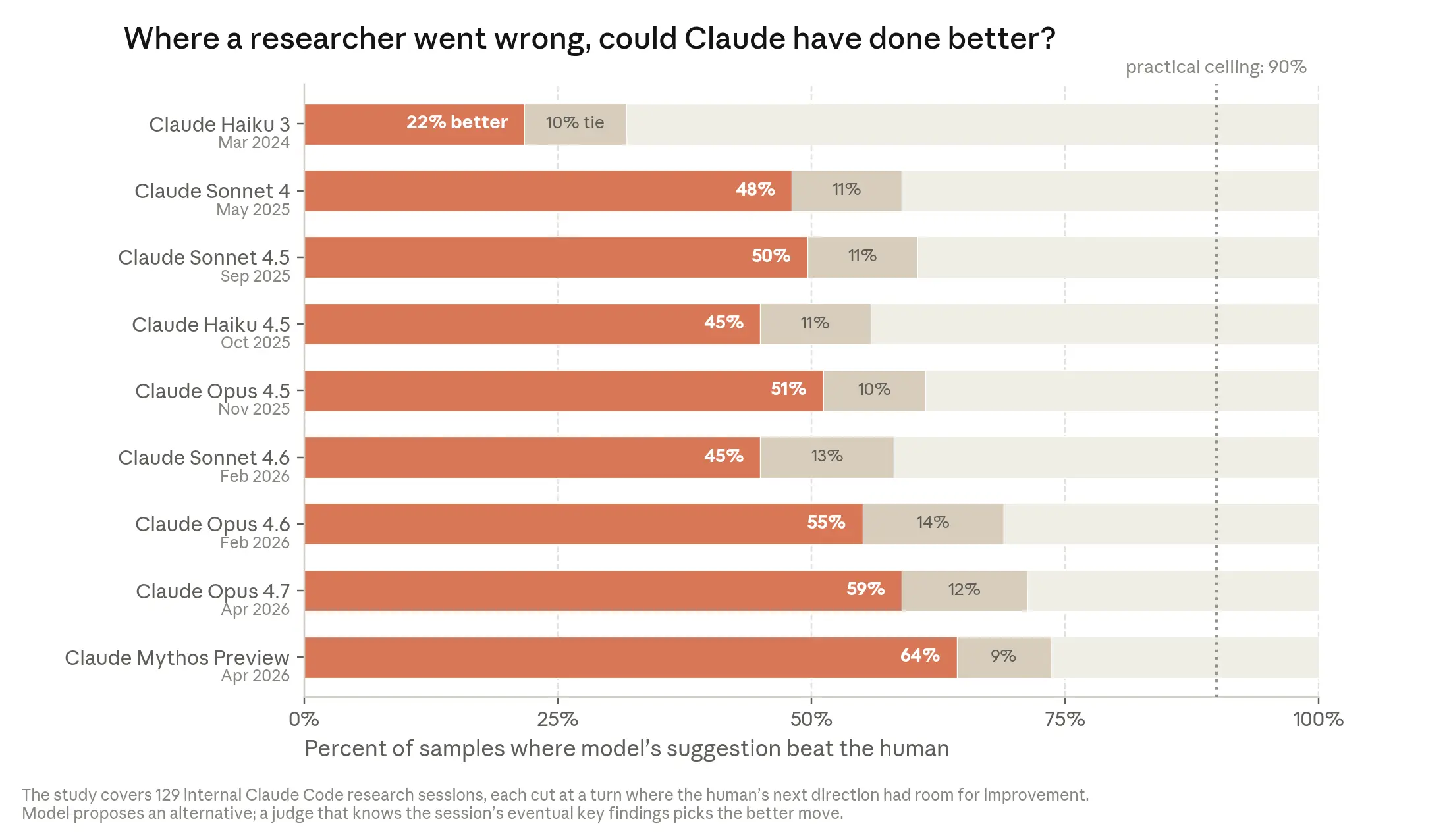
내부 데이터는 더 구체적입니다. 2026년 4월, Anthropic은 Claude가 자율적으로 800건 이상의 API 오류 수정을 완료해 특정 오류 유형을 1,000분의 1 수준으로 줄였다고 밝혔어요. 담당 엔지니어는 "인간이 이 작업을 했다면 4년이 걸렸을 것"이라고 회고했습니다. 코드 품질 면에서 Claude 작성 코드는 2025년 말까지는 인간 대비 다소 낮은 수준이었지만, 2026년 중반 현재 거의 동등한 수준에 도달했고 연내 역전이 예상됩니다.
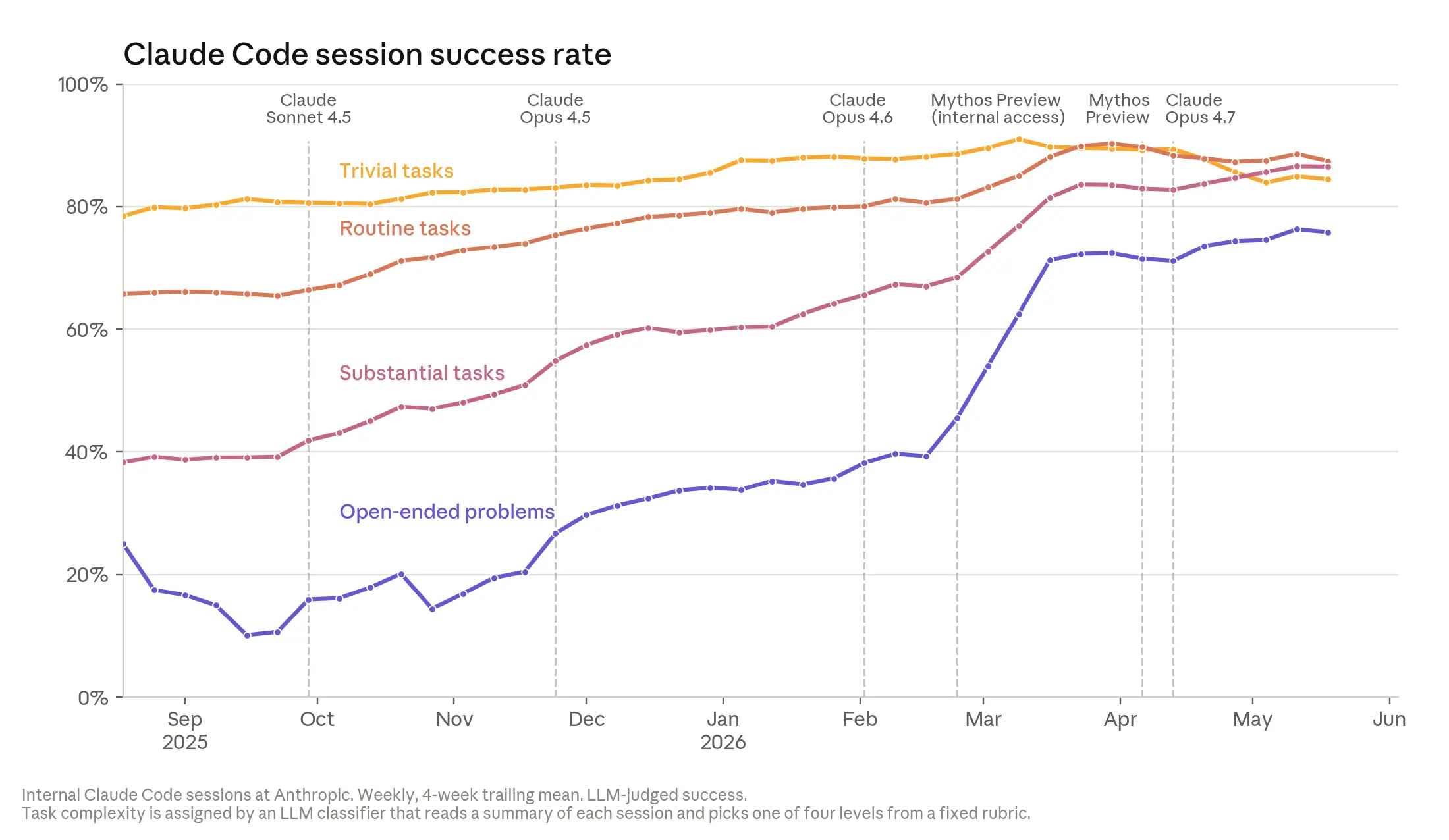
실험 실행 능력 측면에서도 Claude Mythos Preview는 훈련 코드 최적화 실험에서 시작 코드 대비 약 52배의 속도 향상을 달성했는데, 이는 숙련된 인간 연구자가 4~8시간에 걸쳐 달성하는 약 4배를 크게 초월하는 수준입니다. 더 나아가 Anthropic은 2026년 4월 Claude 에이전트들이 AI 안전 연구 문제를 처음부터 끝까지 자율적으로 수행한 결과를 공개했어요. 인간 연구자 2명이 1주일간 달성한 성과 갭의 23%를 에이전트들은 800시간 누적 작업으로 97%까지 회복했습니다. 그러나 '어떤 문제를 풀어야 할지 스스로 결정하는 능력', 즉 리서치 테이스트에서는 여전히 인간이 우위를 점하고 있어요. 리포트는 이것이 오늘의 AI와 완전한 재귀적 자기 개선 사이의 핵심 간격이라고 짚습니다.
지금 이 순간, AI는 더 나은 AI를 만들고 있을지도 모릅니다. 공상과학 소설의 단골 소재처럼 들리지만, Anthropic이 최근 공개한 연구는 이게 이미 시작된 이야기라고 말하고 있어요. 재귀적 자기개선(RSI, Recursive Self-Improvement) — AI가 스스로의 알고리즘과 훈련 절차를 직접 수정해 능력을 반복적으로 끌어올리는 과정 — 이 조용히, 그리고 빠르게 현실이 되어가고 있습니다.
그래서, 위험한 건 아닐까요?
솔직히 말하면 — 조심해야 할 이유는 분명히 있어요. RSI의 가장 큰 위험은 가치관의 증폭입니다. 잘못 정렬된 AI가 자기개선 루프를 돌리기 시작하면, 처음의 작은 편향이 걷잡을 수 없이 커질 수 있거든요. "조금 잘못된 나침반"이 반복될수록 엉뚱한 방향으로 더 빠르게 달려가는 것처럼요.
Anthropic은 이 위험을 인지하고 세 가지 레이어로 대응하고 있어요.
- RSP(책임있는 확장 정책, Responsible Scaling Policy): AI 역량이 특정 임계값을 넘으면 개발을 멈추거나 조건을 충족해야만 진행할 수 있어요.
- ASL(AI 안전 레벨, AI Safety Level): 핵무기·생화학 무기 관련 지식처럼 고위험 역량에 대한 단계별 안전 기준을 적용합니다.
- 해석가능성 연구(Interpretability): AI가 왜 그런 결정을 내리는지 내부를 들여다보는 기술로, 블랙박스를 열려는 시도예요.
8주 만에 1.5년치 수학 실력 향상 — AI 튜터가 증거를 내놓았어요 🎓

AI가 교육을 바꿀 수 있다는 말, 많이 들어보셨죠? 지금까지 수많은 에듀테크 서비스들이 "학습 효과 탁월"을 외쳐왔지만, 정작 엄밀한 실험으로 이를 증명한 사례는 손에 꼽았어요. 그런데 Google DeepMind가 시에라리온에서 진행한 연구는 조금 달라요. 숫자도, 방법론도, 그리고 결과도 — 전부 다르답니다.
실험 설계부터 달랐어요
2026년 6월, Google DeepMind는 시에라리온 교육부와 손잡고 무작위 대조 실험(RCT, Randomized Controlled Trial) 결과를 발표했어요. RCT는 신약 임상시험에서 쓰는 방법론으로, AI 교육 효과 연구에서는 매우 드물게 사용돼요. 단순 사용자 후기나 설문이 아니라, "이 그룹은 AI 사용, 저 그룹은 기존 방식"으로 실제로 나눠서 비교한 거예요.
- 규모: 12개 학교, 1,763명 중등학생
- 기간: 단 8주
- 도구: Gemini의 '가이디드 러닝(Guided Learning)' 기능
결과는 꽤 놀라웠어요. AI를 활용한 그룹의 수학 점수가 대조군 대비 +0.258 표준 편차 향상됐는데, 이를 학습량으로 환산하면 1.2~1.7년분 — 통칭 약 1.5년치 학습 효과에 해당해요. 단 8주 만에요.
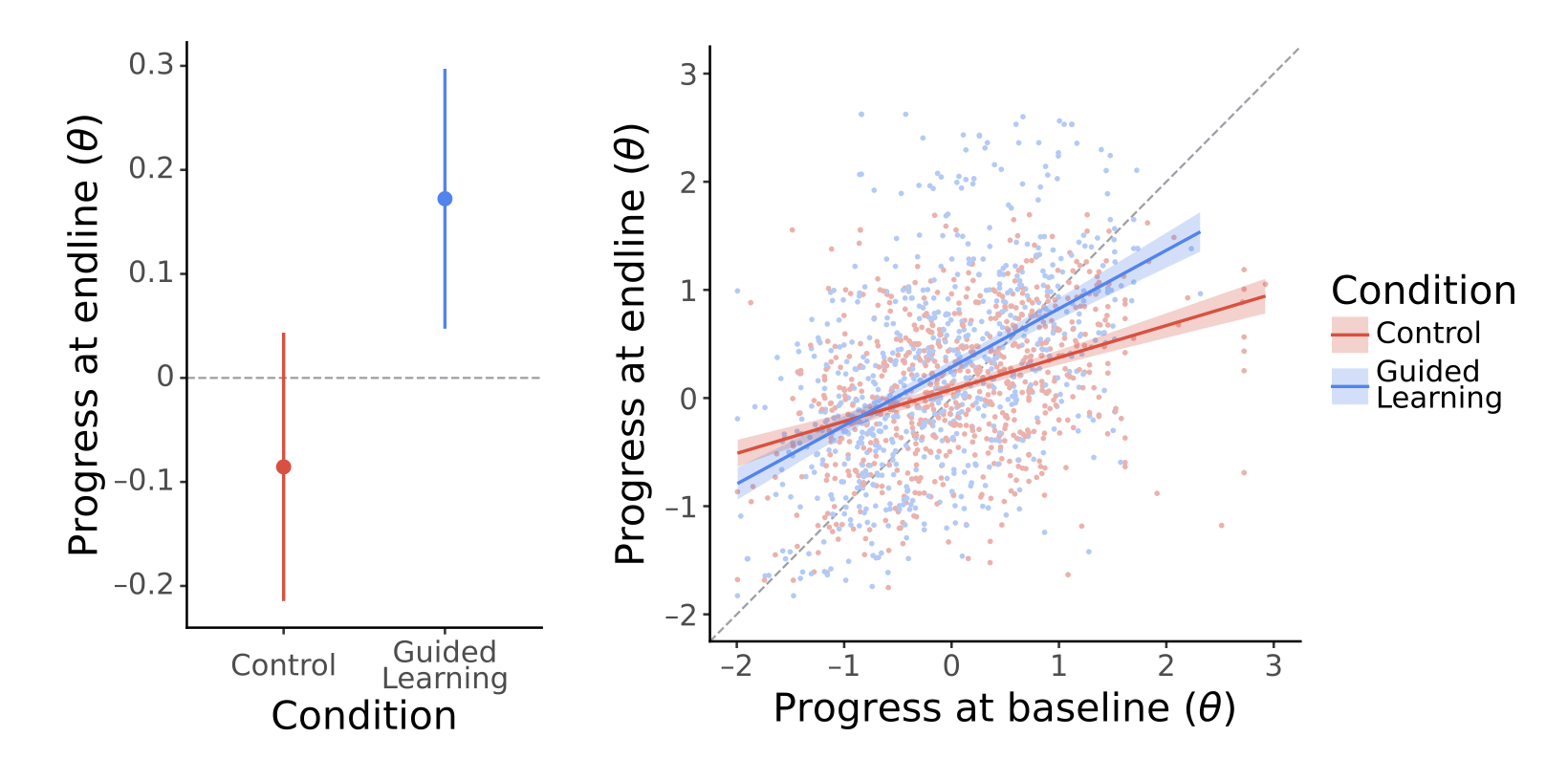
AI는 쉽게 답을 알려주지 않았어요
이 실험에서 가장 흥미로운 부분은 AI가 어떻게 가르쳤느냐예요. Gemini는 90% 이상의 대화에서 답을 직접 알려주지 않았어요. 대신 소크라테스식 문답법으로 질문을 던지며 학생 스스로 답에 도달하도록 유도했죠.
"이 공식에서 x는 어떤 역할을 한다고 생각해?"
"앞 단계에서 뭘 했는지 다시 떠올려볼까?"
이 접근법은 단순 암기가 아닌 이해 기반 학습(Understanding-based Learning)을 이끌어요. 학생이 스스로 생각하는 과정을 거치면 지식이 더 깊이 내재화되거든요. 그리고 이게 숫자로도 드러났어요. 학생 참여율이 69% — 일반 교육 기술 서비스의 평균 참여율인 5%와는 비교도 안 되는 수치예요. 학생들이 지루해하지 않고 계속 대화를 이어나갔다는 뜻이랍니다.
왜 이 연구가 중요할까요?
기존 AI 교육 효과 연구의 대부분은 자발적 참여자 위주였거나, 대조군이 없었거나, 단기 측정에 그쳤어요. 이번 연구는 그 세 가지 약점을 모두 보완했어요. 게다가 인터넷 인프라와 디지털 격차가 큰 시에라리온에서 이 결과가 나왔다는 건, AI 튜터의 효과가 선진국 환경에만 국한되지 않는다는 가능성도 열어주고 있어요.
한국 교육에 던지는 질문
한국은 세계 어느 나라보다 교육열이 높고, 사교육 시장 규모도 어마어마해요. 그런데 그 막대한 비용과 시간이 과연 얼마나 효율적으로 쓰이고 있을까요? AI 튜터가 8주 만에 1.5년치 수학 실력을 끌어올릴 수 있다면, 그 역할이 단순한 "보조 도구"에 머물러선 안 될 것 같아요.
물론 아직 갈 길은 있어요. 수학 한 과목, 8주라는 단기 결과이고, 장기적인 학습 유지 효과나 정서적 측면은 아직 미지수예요. 하지만 적어도 하나는 확실해졌어요. 바로 AI 튜터는 이제 '가능성'이 아니라 '증거'를 갖게 됐다는 것이에요.
Google Deepmind 블로그
실험 리포트 원문

의견을 남겨주세요