
안녕하세요! BDA 뉴스레터입니다 :)
경영정보시각회(필기)부터 컴활2급 그리고 오늘 ADsp까지! 벌써 3개의 자격증을 다루고 있는데요, 저희 뉴스레터가 자격증 시험 준비하는데 큰 도움이 되어서 취준에 꼭 도움이 됐으면 하는 바람입니다😊
그렇다면 ADsp에 대한 소개부터 공부기간, 공부법 그리고 꿀팁까지!! 지금 바로 알아보러 가볼까요?🍀
데이터 직무를 꿈꾼다면 무조건 따야하는 자격증, ADsP
ADsP(데이터분석 준전문가) 자격은 데이터 기반 의사결정을 지원할 수 있는 실무형 분석 인재를 양성하기 위한 자격증이에요. 데이터 분석을 통한 생산성 향상과 사회적 가치 창출을 목표로 하며, 산업 현장의 수요에 부응하는 인재 확보를 위해 마련되었습니다
🖥 ADsP 시험 정보 정리
✅ 시험 개요
한국데이터산업진흥원이 주관하며, 공공 및 민간 분야에서 데이터 활용 능력을 객관적으로 검증해요. 빅데이터 및 통계 분석에 대한 기본 이해와 실무 적용 역량을 평가하며, 과학적 데이터 해석과 전략 수립 능력을 갖춘 인재 양성을 목적으로 한답니다.
✅ 시험 일정
| 회별 | 원서 접수 | 시험일 | 사전점수 공개 | 합격자 발표 |
|---|---|---|---|---|
| 44회 | 1.20~24 | 2.22(토) | 3.14~18 | 3.21 |
| 45회 | 4.14~4.18 | 5.17(토) | 6.5~10 | 6.13 |
| 46회 | 7.7~11 | 8.9(토) | 8.29~9.2 | 9.5 |
| 47회 | 9.22~26 | 11.2(일) | 11.21~25 | 11.28 |
✅ 응시 자격 및 합격 기준
- 응시 자격은 따로 없어요! 연령, 학력, 경력 제한 없이 누구나 응시할 수 있어서 중고등학생, 대학생, 직장인 누구든 도전 가능해요.
- 합격 기준은 총점 60점 이상으로 과목별 40%미만 취득은 과락이니 이점 유의해주세요!
🗓️ 공부기간
저는 비전공자에다가 방학 때 이것저것 하는 게 많아서, 무리하지 않고 약 2주 정도 공부 기간을 잡았습니다! 정확히 말하면 총 10일 정도 진짜로 집중해서 공부했고, 그 외엔 그냥 틈틈이 자료를 훑거나 영상 정도 보는 수준이었어요.
하루에 2~3시간 정도 공부했고 특히 주말엔 5시간 이상 했어요. 마지막 3일 정도는 기출문제만 계속 반복했고, 시험 전날은 오답 노트랑 헷갈렸던 개념만 복습했어요. 공부 기간을 너무 길게 잡으면 오히려 늘어지기 쉬워서, ‘짧고 강하게 몰입하는 전략’이 오히려 더 좋았던 것 같아요. 지금 다시 해도 저는 10일~2주면 충분히 붙을 수 있을 것 같다는 생각이 들어요.
📘 공부법
공부는 세 단계로 나눴어요: 개념 잡기 → 요약 정리 → 기출문제 반복.
첫 3~4일은 개념 위주로 공부했는데, 유튜브에 무료 강의가 많아서 민트책이랑 병행해서 강의 보면서 개념을 익혔어요. 처음 보는 용어들(통계량, 회귀분석, 데이터 마이닝 등)이 많아서 머리가 복잡했지만, 완벽히 이해하려고 하지 않았어요. 그냥 문제에서 어떻게 쓰이는지만 캐치하자! 이런 마인드로 공부했습니다😊
민기술사 요약노트 같은 PDF 자료도 병행해서 봤고, 이게 개념정리하는 데에 많은 도움이 됐어요 5일 차부터는 바로 기출문제를 풀기 시작했어요. 처음엔 점수가 잘 안 나왔지만, 틀린 문제 중심으로 오답노트를 만들면서 반복하니까 눈에 익더라고요.
특히 3과목(데이터 분석)이 어려워서 그쪽은 문제 유형을 외우다시피 했습니다..ㅎㅎ 1·2과목은 거의 암기과목이라서, 하루 이틀이면 충분히 정리 가능했어요. 암기할 땐 제가 직접 말로 반복하거나, 간단히 써보는 식으로 정리했어요. 본인이 지금까지 공부하면서 가장 효율이 좋았던 방법을 그대로 적용하는 게 좋을 것 같아요! 저는 무조건 반복파라 계속계속 반복했습니다✏️
💡 공부팁
제가 실제로 공부해보니까 ADsP는 “완벽하게 공부하려다 망한다”는 말이 정말 맞더라고요.(모든 자격증 시험이 그렇지만..🥲) 특히 비전공자는 이해보다 문제풀이 중심으로 빠르게 넘어가야 붙어요.
기출문제를 무조건 반복하세요. 저는 5년 치 정도를 3번은 돌린 것 같아요. 틀린 문제는 따로 모아서 오답노트를 만들었고, 시험 전날엔 그 노트만 봤어요. 기출을 많이 풀다 보면, 문제 스타일이 거의 비슷해서 어떤 개념이 자주 나오는지 감이 와요.
3과목(데이터 분석)은 별도로 더 투자하세요. 여기가 제일 어렵고 점수 차이도 많이 나는 부분이라, 저는 공부 시간의 절반 이상을 여기에 썼어요. R 문법은 그냥 아예 보지도 않았고, 통계 및 데이터 마이닝 개념은 강의와 예시 문제로 감만 익히고, 실제 문제를 풀면서 익숙해지는 게 훨씬 나아요.
셋째, 1·2과목은 암기과목이니 요약 정리를 반복해서 보세요. 시간이 부족하면 3과목만이라도 제대로 하고, 1·2과목은 단답형 문제 위주로 감 잡는 것도 괜찮아요.
마지막으로 민트책으로 공부를 하신다면 민트책 전용 어플로 공부하는 걸 추천해요! 저는 시간날 때마다 어플을 통해서 기출 문제 및 개념 확인 문제 등을 풀었는데 이렇게 자투리 시간에 공부하니까 휘발되는 개념이나 내용 없이 시험 때까지 쭉 기억할 수 있더라고요 어플로 공부하는 거 완전 강추👍합니다
이런 식으로 공부한 결과 78점으로 꽤나 넉넉하게 합격했습니다 -!
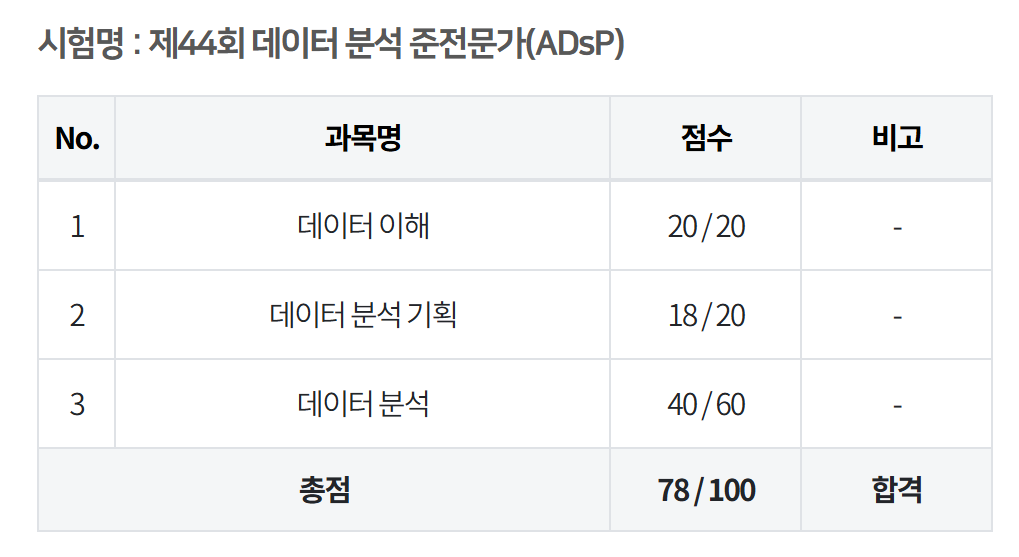
모두 좋은 결과 있으시길 진심으로 응원합니다!🤎‼️
7월 2주차 DATA 트렌드 인사이트 🧐
- “Attention Is All You Need”는 2017년에 Vaswani et al.가 발표한 논문으로, Transformer 구조를 소개한 매우 중요한 연구입니다. 이 모델은 자연어 처리(NLP) 분야에서 혁신을 일으켰고, 현재 GPT, BERT, T5 등 최신 LLM(Large Language Model)의 근간이 되는 구조입니다.
🔍핵심 개념 정리
1️⃣ Transformer의 구조
Transformer는 전통적인 RNN이나 LSTM 없이 Self-Attention Mechanism을 통해 입력 시퀀스의 중요한 정보를 추출합니다.
- Encoder-Decoder 구조
- Encoder: 입력 시퀀스(X1, X2, X3...)를 처리하고 컨텍스트 벡터를 생성
- Decoder: 생성된 컨텍스트 벡터를 바탕으로 다음 시퀀스를 예측
- Encoder는 입력 문장을 이해하고, Decoder는 그것을 바탕으로 다음 단어를 생성합니다.
2️⃣ Self-Attention Mechanism
Transformer의 핵심 기술인 Self-Attention은 입력 문장 내 모든 단어가 서로 얼마나 중요한지를 계산합니다.
- 각 단어는 다른 모든 단어와의 관계를 Attention Score로 계산
- 문장의 길이와 관계없이 병렬 처리가 가능하기 때문에 학습 속도가 매우 빠름
- 예를 들어:
- 문장: “The cat sat on the mat”
- “cat”은 “sat”와 강하게 연결되고, “mat”와도 어느 정도 관련이 있습니다.
- Self-Attention이 이런 관계를 학습합니다.
3️⃣ Multi-Head Attention
하나의 Attention만 사용하는 것이 아니라, 여러 개의 Attention Head를 사용합니다.
- 각 Head는 다른 시각에서 문장을 이해하려고 시도합니다.
- 예를 들어, 하나의 Head는 문법적 구조, 다른 Head는 의미적 유사성을 찾습니다.
- 병렬적으로 처리되기 때문에 속도가 빠르고, 정보 추출력이 뛰어납니다.
4️⃣ Positional Encoding
Transformer는 RNN처럼 순서 정보를 내재하지 않기 때문에, Positional Encoding을 통해 단어의 순서를 학습합니다.
- Sine, Cosine 함수를 이용해 각 위치를 표현합니다.
- 모델이 문장 내 위치 정보를 이해할 수 있도록 도와줍니다.
5️⃣ Feed-Forward Neural Network
각 Attention Layer 다음에는 Feed-Forward Neural Network가 연결됩니다.
- 이 신경망은 각 Attention의 출력을 변환하여 다음 단계에 전달합니다.
- Layer Normalization과 Residual Connection을 사용하여 학습 안정성을 높입니다.
6️⃣ Optimization Techniques
- Residual Connection: 기울기 소실(Vanishing Gradient) 문제를 방지
- Layer Normalization: 학습 속도 향상
- Dropout: 과적합(Overfitting) 방지
✅Transformer의 주요 장점
- 병렬 처리가 가능하여 학습 속도가 RNN/LSTM보다 훨씬 빠름
- Long-term Dependency를 효과적으로 학습함
- Multi-Head Attention을 통해 다양한 시각으로 문맥을 파악
- Positional Encoding으로 시퀀스 정보도 학습 가능
🏷️Transformer 이후의 발전
- BERT (2018): Bidirectional Encoder Representation, 양방향으로 문맥을 이해
- GPT (2018-2023): Decoder 중심, 생성 능력 강화
- T5 (2019): Text-to-Text Transfer Transformer
- ViT (2021): Vision Transformer, 이미지 처리에 Transformer 도입
“Attention Is All You Need”는 2017년 Google Brain 연구진이 발표한 논문으로, 자연어 처리(NLP) 분야에서 혁신적인 Transformer 아키텍처를 소개하였습니다. 이 아키텍처는 기존의 순환 신경망(RNN)이나 합성곱 신경망(CNN)을 사용하지 않고, 오직 어텐션 메커니즘만을 활용하여 시퀀스 데이터를 처리합니다. 이를 통해 병렬 처리가 가능해졌으며, 학습 시간과 성능 면에서 큰 향상을 이루었습니다 .
📄 논문 정보
- 제목: Attention Is All You Need
- 저자: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin
- 발표 연도: 2017
- 학회: Neural Information Processing Systems (NeurIPS)
- 원문 링크: arXiv:1706.03762
- PDF 다운로드: 논문 PDF
🔑 주요 기여 및 특징
- Transformer 아키텍처 도입: 순환 구조 없이도 시퀀스 간의 의존성을 효과적으로 학습할 수 있는 모델을 제안하였습니다.
- Self-Attention 메커니즘: 입력 시퀀스 내에서 각 단어가 다른 단어들과의 관계를 학습하여, 문맥을 효과적으로 파악합니다.
- Multi-Head Attention: 여러 개의 어텐션 헤드를 통해 다양한 표현 공간에서 정보를 추출하고 통합합니다.
- Positional Encoding: 단어의 순서 정보를 인코딩하여, 순차적인 정보 손실 없이 모델이 위치 정보를 학습할 수 있도록 합니다.
📚 추가 학습 자료
Transformer와 해당 논문에 대한 자세한 설명과 리뷰를 원하신다면 아래의 자료들을 참고하실 수 있습니다:
이러한 자료들은 논문의 핵심 개념을 시각적으로 설명하고, 주요 수식과 구조를 쉽게 이해할 수 있도록 도와줍니다.
필요하신 경우, 논문 내용을 한글로 요약하거나 주요 개념에 대한 추가 설명을 제공해드릴 수 있습니다. 언제든지 말씀해주세요!
의견을 남겨주세요