
Introduction
메시징 시스템은 현대 소프트웨어 아키텍처에서 없어서는 안 될 중요한 구성 요소입니다. 특히 실시간 데이터 처리와 스트리밍 분야에서는 그 역할이 더욱 크죠. 하지만 메시징 시스템에도 종류가 있습니다. 바로 큐(Queue) 기반과 로그(Log) 기반인데요.
둘 다 비동기 방식으로 데이터를 처리한다는 공통점이 있지만, 동작 방식과 특성에는 큰 차이가 있습니다. 이 차이를 이해하는 것은 여러분의 시스템에 가장 적합한 메시징 시스템을 선택하는 데 있어 매우 중요한 첫걸음이 될 거예요.
오늘은 현업에서 널리 사용되는 RabbitMQ, Kafka 등의 사례를 통해 큐 기반과 로그 기반 메시징 시스템의 차이를 쉽게 이해할 수 있도록 Messaging Systems: Queue Based vs Log Based를 번역해 정리해봤습니다. 어떤 상황에서 어떤 시스템을 선택해야 할지, 그리고 각 시스템의 장단점은 무엇인지 알아볼 거예요. 이 글을 통해 여러분이 실시간 데이터 처리를 위한 최적의 메시징 시스템을 선택하는 데 도움이 되길 바랍니다. 그럼 시작해 볼까요?
오늘은 실시간 및 스트리밍 세계에서 널리 사용되는 기술을 다루는 또 다른 기사를 공유하려 합니다. 우리는 두 가지 대중적인 메시징 시스템을 보다 광범위한 관점에서 살펴보고, 차이점, 주요 측면 및 속성을 다룰 것이며, 여러분에게 다음에 어디로 가야 할지 명확한 그림을 제시할 것입니다.
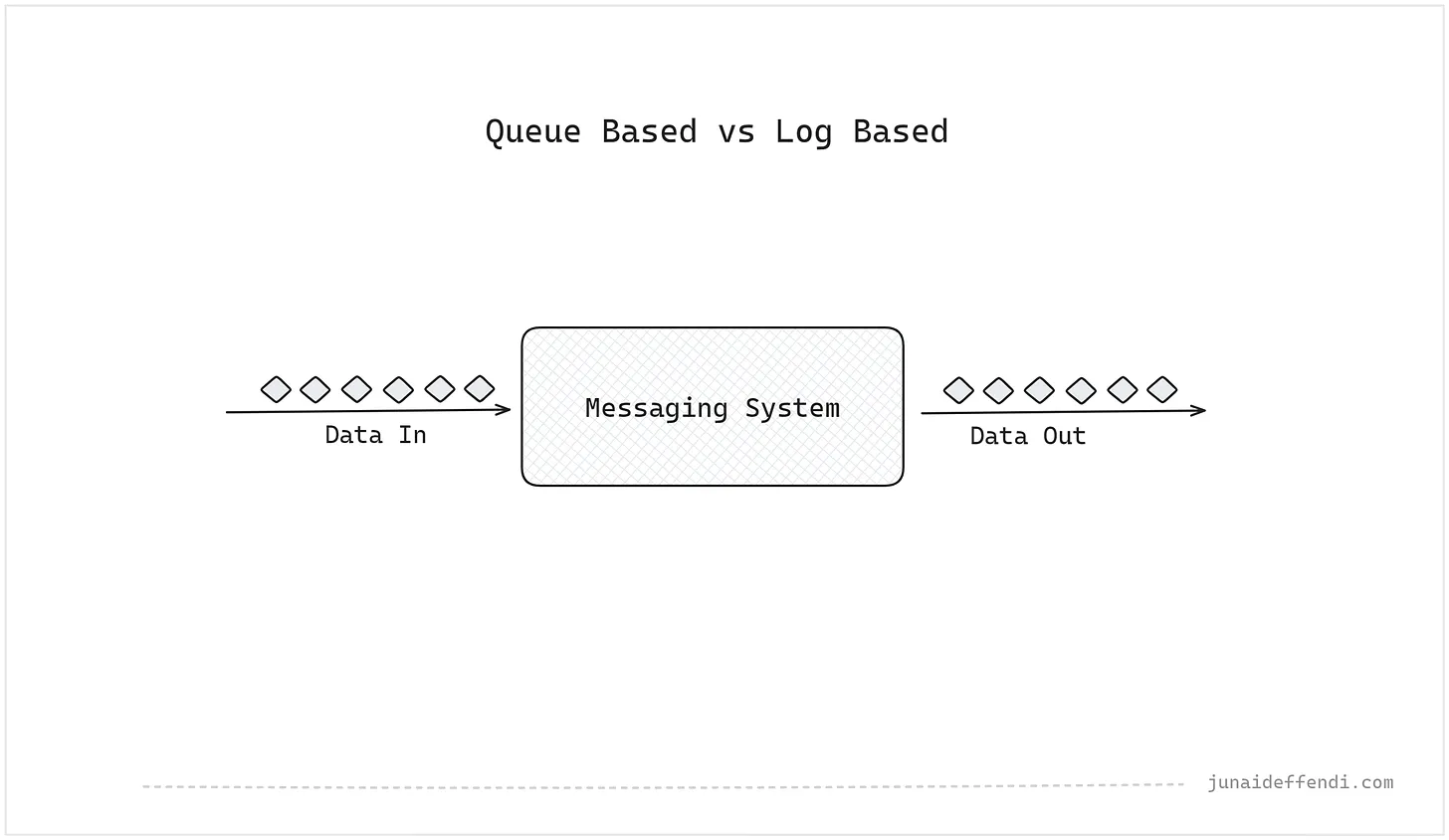
큐 기반이든 로그 기반이든, 최종 목표는 실시간 데이터의 높은 볼륨을 비동기식으로 처리하기 위해 시스템에서 메시지를 버퍼링하는 것으로 간단합니다. 이때, 생산자와 소비자는 분리되어 있습니다.
그러면 큐 기반과 로그 기반 시스템에 대해 각각 알아봅시다.
큐 기반 메시징 시스템
큐 기반 메시지 시스템은 JMS 또는 AMQP 접근 방식을 활용하여 선입선출(FIFO) 방식으로 데이터를 처리합니다.
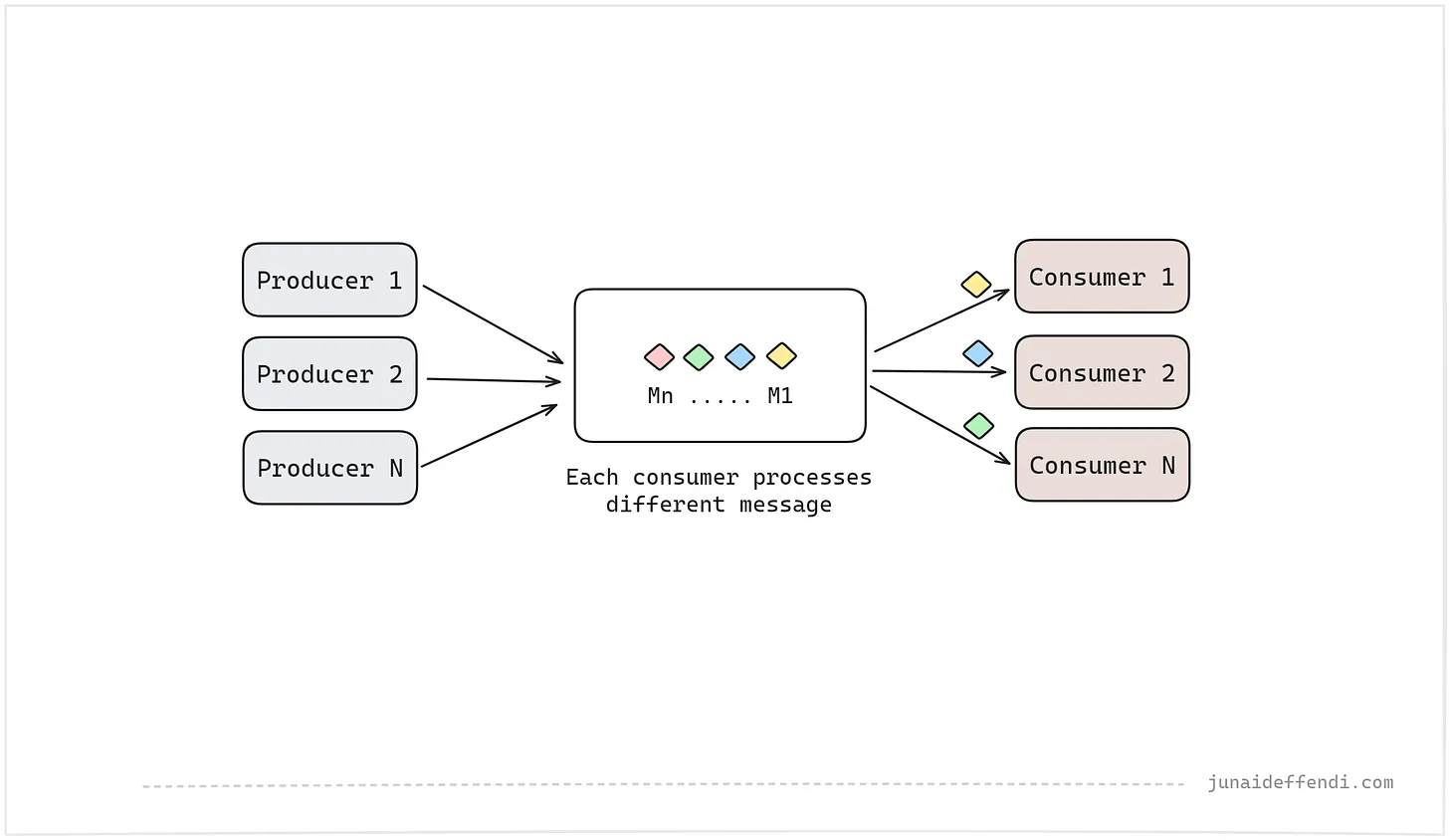
아래 그림에서 간단한 큐 기반 예제를 살펴보시죠. 여기서 N개의 생산자가 큐에 데이터를 푸시하면 N개의 소비자가 비동기 방식으로 큐에서 데이터를 읽을 수 있습니다.
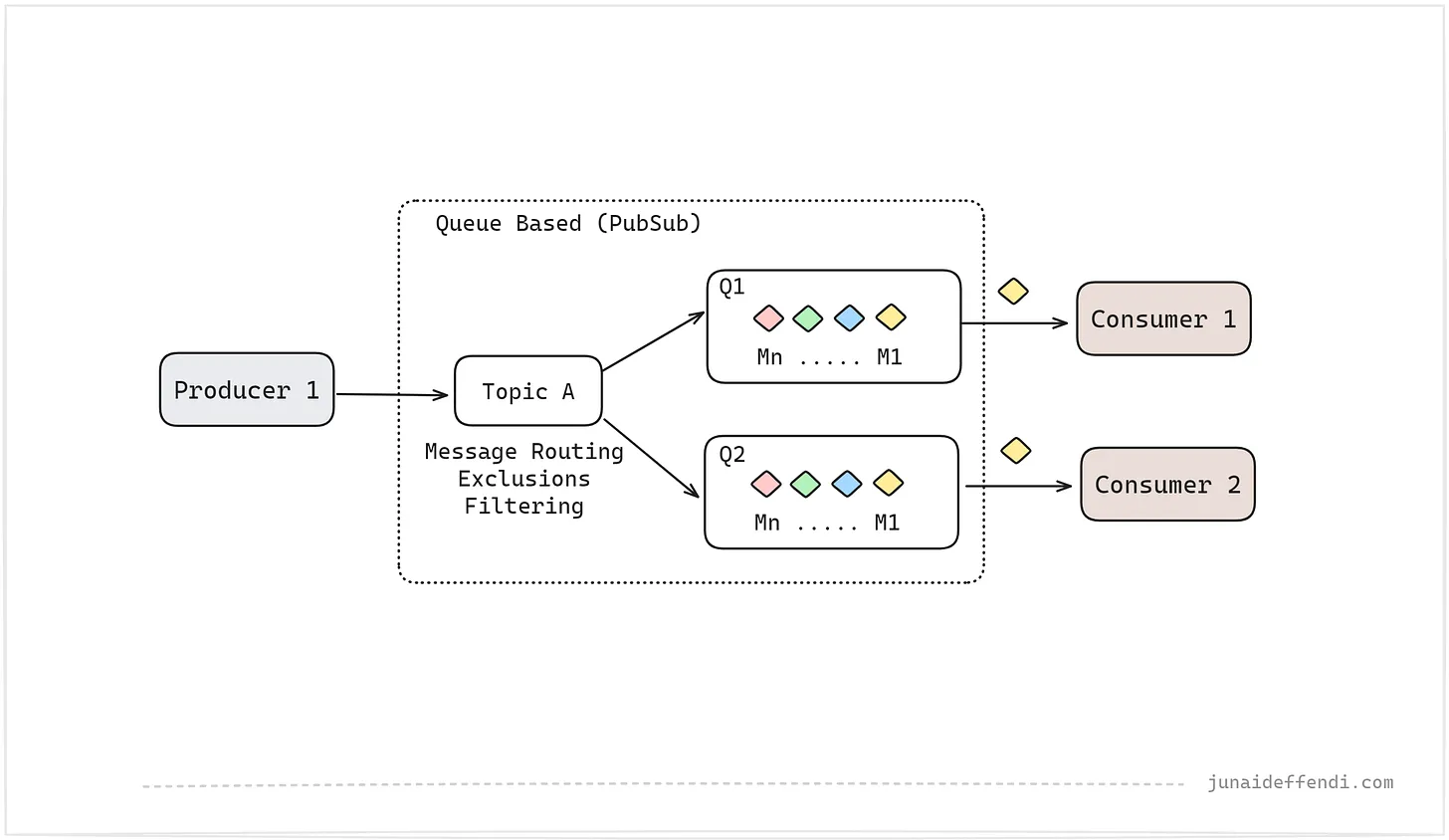
큐를 더 높은 레벨의 스케일로 확장하려면 PubSub 접근 방식을 고려해볼 수 있습니다. 여기에는 소비자가 각각의 큐에서 동일한 메시지를 읽을 수 있도록 하는 토픽과 구독이 있습니다.
여기서 몇 가지 중요한 측면을 살펴보겠습니다.
- 예: RabbitMQ, ActiveMQ, AWS SQS, GCP PubSub. 이들은 모두 몇 가지 특정 기능과 함께 동일한 기본 사항을 공유합니다.
- 여러 생산자가 동일한 주제 또는 큐에 푸시할 수 있습니다. 여러 소비자가 동일한 큐에서 읽을 수 있습니다.
- 하나의 큐는 여러 주제를 구독할 수 있습니다.
- 소비자는 간격에 따라 큐에서 데이터를 가져옵니다. 대부분의 큐는 오늘날 long polling도 지원합니다.
- 각 메시지가 소비자에 의해 정확히 한 번 처리되도록 하여 중복을 처리합니다.
- 위 이미지에 표시된 것처럼 여러 소비자가 동일한 큐에서 동일한 메시지를 읽을 수 없습니다. 해당 사용 사례를 지원하려면 두번째 이미지에 표시된 것처럼 PubSub 솔루션으로 이어지는 여러 큐가 필요합니다.
- 메시지가 소비자에 의해 성공적으로 처리되면 삭제되므로 재처리가 지원되지 않습니다.
- 실패한 메시지를 처리하려면 DLQ(Dead Letter Queue)가 필요합니다. DLQ는 일반 큐이지만 실패한 메시지를 쉽게 재처리할 수 있도록 소스 큐에 연결됩니다.
- 큐 기반 시스템은 메시지 우선순위 지정을 지원합니다.
- 순서는 생산자가 제출한 순서와 동일한 순서로 소비자가 읽는 것으로 정의되는 큐당 순서를 보장합니다.
- PubSub 접근 방식에서는 주제를 통해 고급 메시지 라우팅, 필터링 및 제외를 수행할 수 있습니다.
- 큐는 여러 가지 이유로 데이터를 디스크에 유지/저장할 수 있습니다(예: 메모리 압력 또는 RabbitMQ의 delivery 모드와 같은 구성).
- 메시지는 소비될 때까지 메모리나 디스크에 남아 있어 저장 측면에서 훨씬 가벼워집니다.
- back pressure가 있는 경우, 즉 소비자가 생산자가 큐/주제에 푸시하는 것과 같은 속도로 읽지 않는 경우 메모리나 디스크 문제가 발생합니다.
로그 기반 메시징 시스템
로그 기반 메시징 시스템은 디스크에 추가 전용 로그를 유지 관리하여 내결함성을 제공하고 영구 스토리지를 제공합니다.
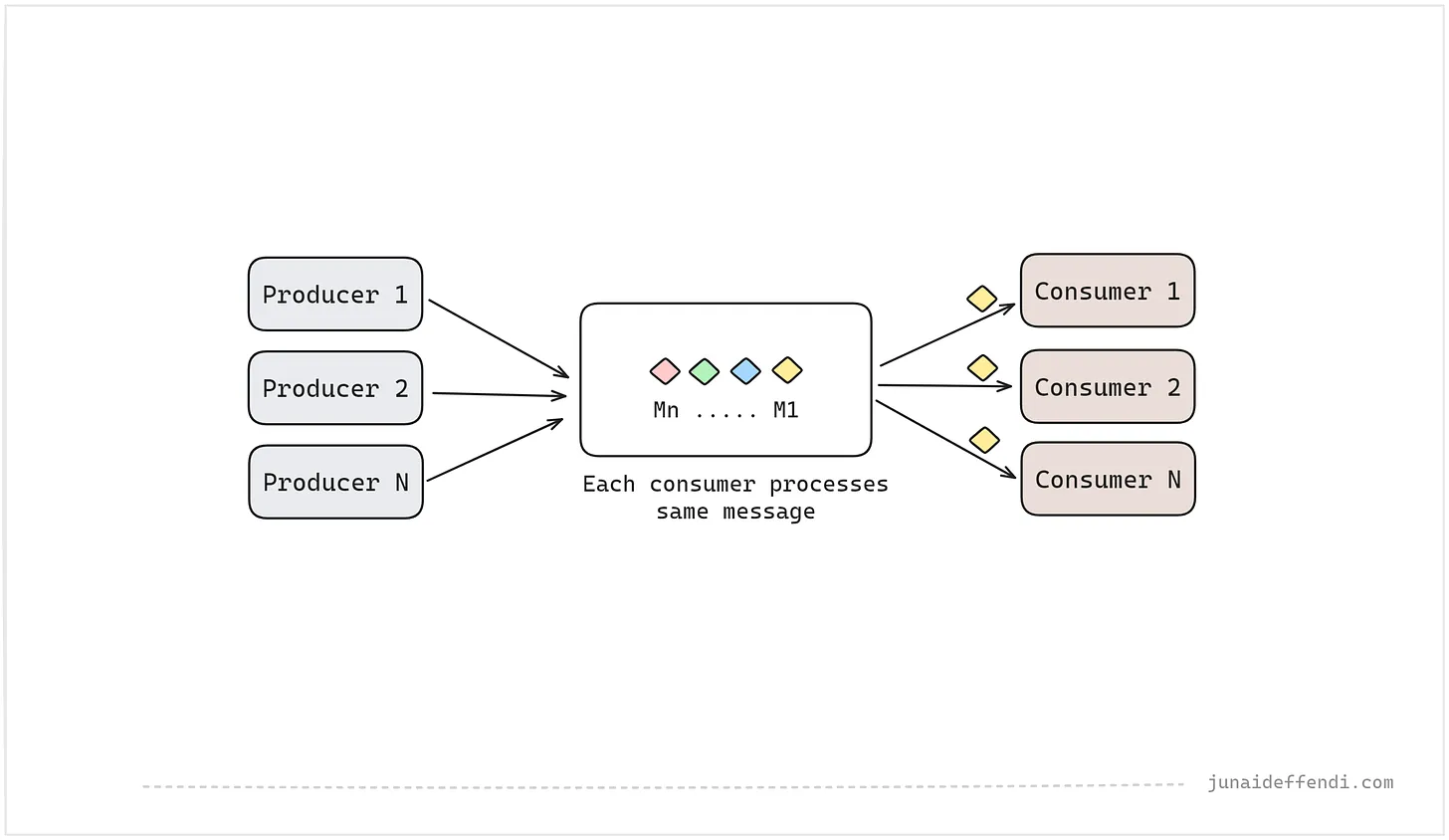
간단한 엔드 투 엔드 아키텍처는 다음과 같습니다.
이를 더 확장하려면 소비자를 다음과 같은 방식으로 그룹화하여 파티션 수준에서 병렬로 동일한 주제에서 처리할 수 있습니다.
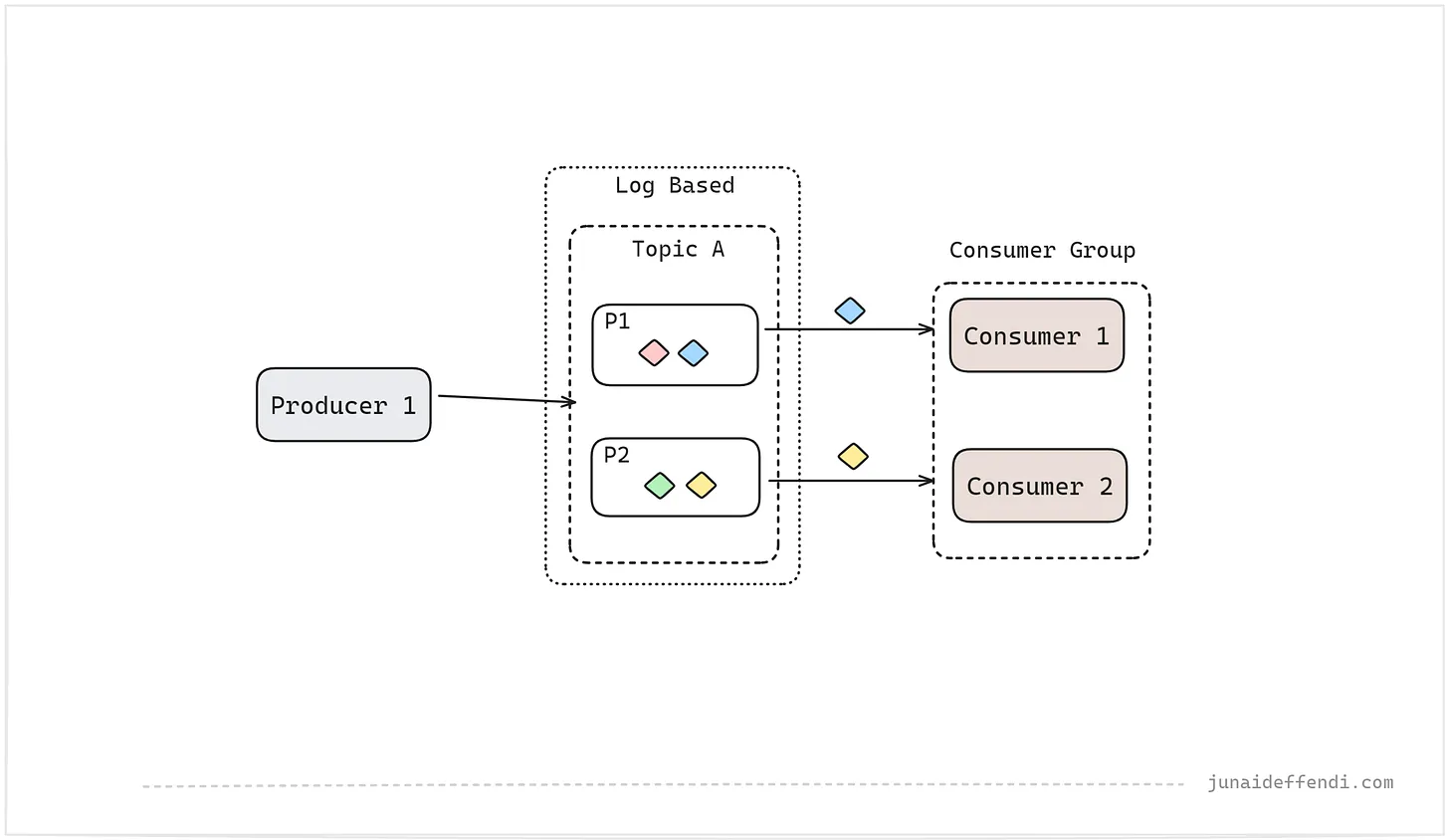
몇 가지 중요한 측면을 살펴보겠습니다:
- 예: Apache Kafka, AWS Kinesis. 이들은 모두 몇 가지 특정 기능과 함께 동일한 기본 사항을 공유합니다.
- 여러 생산자가 동일한 주제에 푸시할 수 있습니다. 여러 소비자 또는 소비자 그룹이 동일한 주제에서 읽을 수 있습니다.
- 파티션은 Kafka에 적용되는 소비자 그룹 내의 하나의 소비자가 읽을 수 있습니다.
- 소비자는 오프셋 및 시퀀스 번호와 같은 사양에 따라 메시지를 가져옵니다.
- 이미지 2a에 표시된 것처럼 여러 소비자가 동일한 메시지를 읽을 수 있습니다. 이는 큐 기반 모델과 비교할 때 하나의 중앙 집중식 시스템을 갖출 수 있게 해주는 큰 차별점 중 하나입니다.
- 이미지 2b에 표시된 것처럼 소비자를 그룹화하여 하나의 큰 소비자처럼 작동하도록 할 수 있습니다. 그룹의 각 소비자는 다른 메시지를 읽습니다.
- 로그 기반 시스템을 사용하면 로그 보존 정책에 따라 오프셋을 특정 시점으로 이동하여 메시지를 재처리할 수 있습니다.
- 파티션별 순서를 보장합니다. 즉, 파티셔닝 키를 신중하게 결정해야 합니다.
- 파티션별로 내장 복제를 지원합니다.
- 더 많은 브로커, 주제 및 파티션과 함께 소비자 그룹을 추가하여 하나의 중앙 집중식 시스템 내에서 수평적으로 확장하기가 더 쉽습니다.
- 주제/파티션을 통한 메시지 라우팅으로 파티션을 신중하게 결정해야 합니다.
- 로그 기반 시스템은 먼저 페이지 캐시를 활용한 다음 디스크에 추가하여 내결함성을 제공합니다.
- 로그 기반은 보존 정책을 통해 구성된 지정된 시간 동안 데이터를 영구적으로 저장하여 임시 단기 스토리지 솔루션 역할을 합니다. 데이터베이스로 간주해서는 안 됩니다.
- 메시지 크기와 수가 증가함에 따라 디스크 공간 문제가 발생합니다. 향후 필요한 디스크 공간을 추정하는 것이 중요합니다.
사용 사례
높은 수준에서 두 가지 모두 기능적으로 동일한 목표를 달성합니다. 어떤 것을 선택할지 결정하려면 다음 항목에 대한 심층 분석이 필요합니다:
- 소유권: 누가 소유할 것인가요?
- 인프라: 설정하기 쉬운가요?
- 규모: 가까운 미래의 예상 데이터 규모는 어떻게 되나요?
- 소비자 요구 사항: 필요한 기능은 무엇인가요?
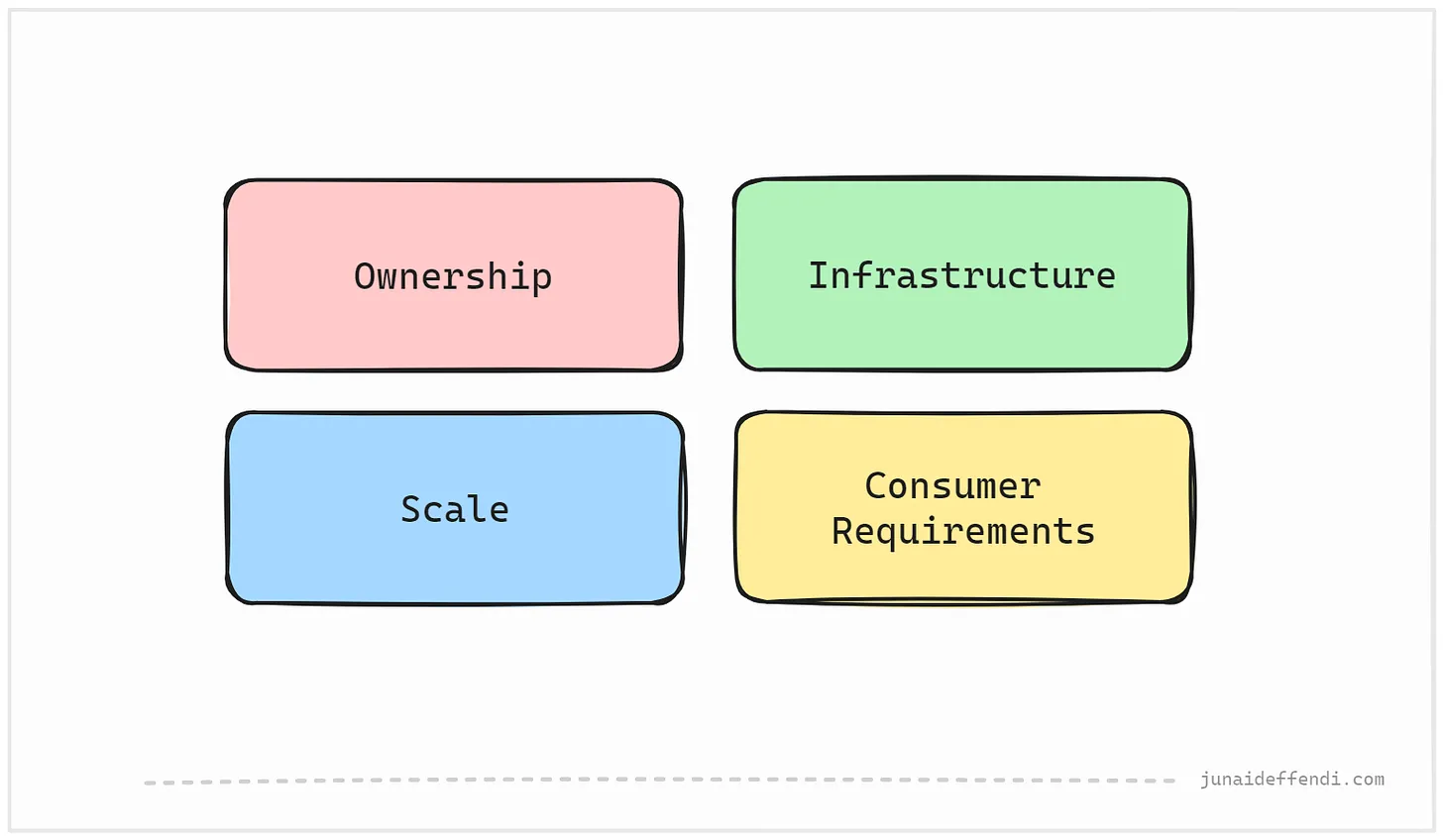
큐 기반과 로그 기반 중에서 결정할 때 고려해야 할 네 가지 영역입니다. 큐 기반과 로그 기반 중에서 결정할 때 고려해야 할 네 가지 영역입니다. 💬 댓글 섹션에서 두 가지 중에서 결정할 때 어떤 사항을 더 고려할 지 알려주세요.
지금까지 큐 기반과 로그 기반 메시징 시스템의 주요 차이점과 특성에 대해 살펴보았습니다. 둘 다 실시간 데이터 처리라는 같은 목표를 가지고 있지만, 동작 방식과 적합한 사용 사례에는 분명한 차이가 있었죠.
큐 기반은 메시지의 순서 보장과 개별 메시지 처리에 중점을 두는 반면, 로그 기반은 데이터의 영속성과 확장성, 그리고 메시지의 재처리 기능을 제공합니다.
어떤 것이 더 좋다고 단정 짓기는 어렵습니다. 중요한 것은 여러분의 시스템이 어떤 특성을 필요로 하는지 파악하고, 그에 맞는 최적의 메시징 시스템을 선택하는 것입니다.
메시지의 크기와 처리량, 확장 계획, 장애 대응 방안 등 다양한 요소를 고려해야 할 거예요. 운영 환경과 팀의 역량 또한 간과할 수 없는 부분이죠.
단순히 최신 트렌드를 쫓기보다는, 여러분의 상황에 가장 적합한 방향으로 나아가는 것이 현명한 선택이 될 거라 믿습니다.
혹시 이 글을 읽고 나서 어떤 메시징 시스템을 선택해야 할지 고민이 되시나요? 아니면 추가로 궁금한 점이 있으신가요? 댓글로 여러분의 의견을 듣고 싶습니다.
실시간 데이터 처리의 세계에 오신 여러분을 응원하며, 흥미로운 주제로 다시 찾아 뵙겠습니다.
Top 1% 개발자로 거듭나는 확실한 처방전, 데브필입니다.

PS: 구독자 100명 돌파! 👏
뉴스레터 데브필이 구독자 100명을 돌파했습니다 :) 항상 구독자님들께 감사의 말씀을 전해드리고 싶습니다.
여러분의 관심과 성원 덕분에 매주 열심히 글을 쓰고, 좋은 콘텐츠를 전달하려 노력할 수 있었습니다. 앞으로도 소프트웨어 개발과 아키텍처, 커리어에 관한 실용적인 정보를 전하는 데브필이 되겠습니다.
개발자로서의 성장과 행복한 커리어 쌓기에 작은 도움이 될 수 있기를 바라며, 구독자 여러분과 함께 성장하는 뉴스레터가 되고 싶습니다.
데브필과 함께해 주셔서 다시 한번 깊이 감사드립니다. 언제나 여러분의 피드백을 기다리고 있겠습니다.
계속해서 200명, 300명을 향해 달려가 볼게요! 우리 함께 성장합시다 :)
의견을 남겨주세요