
모델 선택에 대한 간단한 퀴즈를 내볼게요. 정답을 모두 알 것 같으면 이 글을 읽지 않으셔도 되지만, 헷갈리는 문제가 있으시다면 글을 끝까지 읽으시고 다시 도전해 보세요!
모델 선택의 정의
모델 선택은 성능 지표를 기준으로 다양한 후보 모델 중에서 가장 좋은 모델을 선택하는 일이다.
위키피디아(Wikipedia)
모델 선택의 정의는 영문 위키피디아의 내용을 인용하여 의역했습니다.
같이 차근차근 살펴보시죠.
1) 성능 지표
• 성능 지표는 어떤 모델이 더 나은지 평가하는 기준입니다. 머신 러닝에서 성능 지표는 크게 2가지로 나뉘며, 이들을 종합적으로 고려하여 더 나은 모델을 선택합니다.
• 오차(Error)는 모델이 예측한 값과 실제 값의 차이를 의미합니다. 따라서 오차가 작을수록 좋은 모델로 평가됩니다. 이러한 오차는 데이터가 숫자일 경우 사용되며, 평균제곱오차(MSE), 평균절대오차(MAE) 등이 자주 사용됩니다.
• 통계 지표(Statistical Metrics)는 모델이 얼마나 정확하고 신뢰할 수 있는지를 나타냅니다. 이러한 통계 지표는 데이터가 범주일 경우 사용되며, 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1 점수 등이 자주 사용됩니다. 이에 대한 자세한 설명은 아래에서 살펴보겠습니다.
2) 다양한 후보 모델
• 모델 선택 과정에서는 보통 여러 후보 모델을 준비합니다. 후보 모델은 크게 2가지 기준으로 나눌 수 있습니다.
• 첫째로, 완전히 다른 종류의 모델을 비교할 수 있습니다.
예: 의사결정 나무(Decision Tree) 모델 vs 신경망(Neural Network) 모델
• 둘째로, 동일한 모델이라도 서로 다른 파라미터(튜닝) 값을 부여하여 비교할 수 있습니다.
예: 레이어(Layer)마다 뉴런(Neuron)이 5개인 신경망 모델 vs 뉴런이 10개인 신경망 모델
3) 가장 좋은 모델
• 가장 좋은 모델은 절대적인 것이 아닙니다. 문제의 성격, 데이터의 특성, 평가하고자 하는 목표에 따라 좋은 모델은 달라질 수 있습니다. 이에 대한 자세한 예시는 아래에서 살펴보겠습니다.
위 내용들을 요약해 보면 모델 선택은 주어진 상황에 가장 알맞은 성능을 가진 모델을 고르는 것이라고 말할 수 있습니다.
모델 선택의 예시
암 환자를 분류하기 위해 4개의 모델을 준비했다고 가정해 보겠습니다. 이 모델들의 성능을 비교하여 가장 좋은 모델을 고르려고 합니다. 모델들의 성능은 아래와 같습니다.
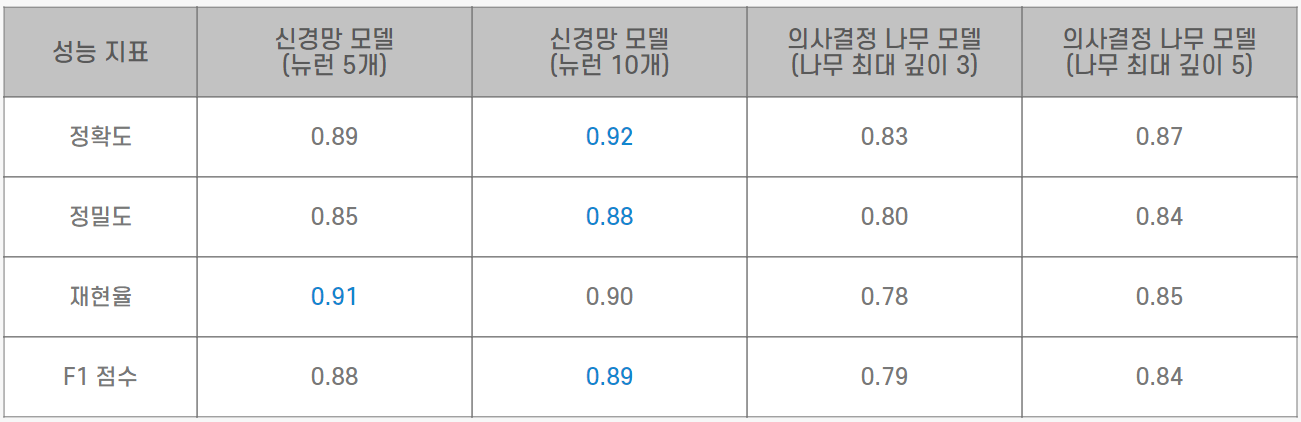
1) 정확도
• 정확도는 모델의 전체 예측 중 맞춘 예측의 비율입니다.
• 위 모델들에서 정확도는 암에 걸린 사람을 암이라고 맞춘 비율과 암에 걸리지 않은 사람을 암이라고 맞추지 않은 비율을 의미합니다. 정확도가 가장 좋은 모델은 레이어마다 뉴런이 10개인 신경망 모델입니다.
2) 정밀도
• 정밀도는 모델이 참이라고 예측한 사례 중에서 실제로 참인 비율입니다.
• 위 모델들에서 정밀도는 암이라고 예측한 사람 중에서 실제로 암인 사람의 비율을 의미합니다. 정밀도가 가장 좋은 모델은 뉴런이 10개인 신경망 모델입니다.
3) 재현율
• 재현율은 실제로 참인 사례 중에서 모델이 참이라고 맞추는 비율입니다.
• 위 모델들에서 재현율은 실제로 암인 사람 중에서 암이라고 맞춘 비율을 의미합니다. 재현율이 가장 좋은 모델은 레이어마다 뉴런이 5개인 신경망 모델입니다.
4) F1 점수
• 정밀도와 재현율의 조화평균으로, 두 지표를 균형 있게 고려한 단일 지표입니다.
• F1 점수가 가장 좋은 모델은 레이어마다 뉴런이 10개인 신경망 모델입니다.
암을 분류하고 진단하는 상황에서 위 모델 중 가장 좋은 모델은 재현율이 높은 모델이어야 합니다. 그 이유는 일부 암 환자를 놓치게 된다면 큰 문제가 되기 때문입니다. 재현율이 낮다면 더 많은 환자를 진단에서 놓칠 수 있습니다. 이처럼 의료, 제조와 같이 재현율이 중요한 업계가 있습니다.
의견을 남겨주세요