
구독자님, 안녕하세요! 데이터 전처리에 대한 간단한 퀴즈를 내볼게요. 정답을 모두 알 것 같으면 이 글을 읽지 않으셔도 되지만, 헷갈리는 문제가 있으시다면 글을 끝까지 읽으시고 다시 도전해 보세요!
데이터 전처리의 정의
데이터 전처리는 데이터를 분석하거나 패턴을 발견하기 이전에 데이터를 처리, 필터링, 또는 증강하는 것을 의미한다.
위키피디아(Wikipedia)
데이터 전처리의 정의는 영문 위키피디아의 내용을 인용하여 의역했습니다.
같이 차근차근 살펴보시죠.
1) 데이터를 분석하거나 패턴을 발견하기 이전에
• 데이터 전처리는 데이터를 모델에 적합한 상태로 만드는 사전 작업입니다.
• 데이터 수집 과정에서 발생하는 값 누락이나 범위를 벗어난 값 등의 문제를 해결하는 데 필수적입니다.
2) 데이터 처리(Data Manipulation)
• 데이터 처리는 데이터를 원하는 형태로 변환하거나 처리하는 과정입니다.
• 예를 들어, 데이터의 모양이 네모인데, 모델에서 세모 모양의 데이터를 요구한다면 데이터를 세모로 바꿔줘야 합니다. 이러한 작업 없이 아래 영상처럼 데이터를 모델에 억지로 집어넣으면 오류가 발생합니다.

• 결측값 대체, 이상치 제거, 표준화, 정규화, 더미 인코딩, 원-핫 인코딩, 토큰화 등 다양한 작업이 있습니다. 자세한 설명과 예시는 아래 파트에서 진행하겠습니다.
3) 데이터 필터링(Data Filtration)
• 데이터 필터링은 데이터를 원하는 조건에 따라 추출하는 작업입니다.
• 데이터 범위를 설정하여 특정 값들만 확인하거나 전체 데이터에서 일부 샘플을 뽑아낼 수 있습니다. 엑셀에서도 자주 사용되는 필터 옵션과 유사합니다.
4) 데이터 증강(Data Augmentation)
• 데이터 증강은 데이터 부족 문제를 해결하기 위해 기존 데이터를 변형하여 새로운 데이터를 생성하는 작업입니다.
• 데이터 증강은 이미지나 텍스트 데이터에서 자주 사용됩니다. 이미지의 밝기를 조정하거나 회전, 반전 등을 통해 새로운 학습 데이터를 생성합니다. 텍스트의 경우, 문장의 순서를 바꾸거나 단어들을 동의어로 대체하기도 합니다.

위 내용들을 요약해 보면 데이터 전처리는 수집한 데이터의 품질을 개선하고 정확한 분석과 모델링을 위해 진행하는 작업들이라고 말할 수 있습니다.
데이터 전처리의 예시
성별, 손목, 복부, 발목 둘레를 이용하여 몸무게를 예측하는 모델을 만든다고 가정해 보겠습니다. 이때, 아래 주어진 데이터셋은 모델링에 적합한 형태가 아니므로 일련의 전처리 과정을 진행해 보겠습니다.
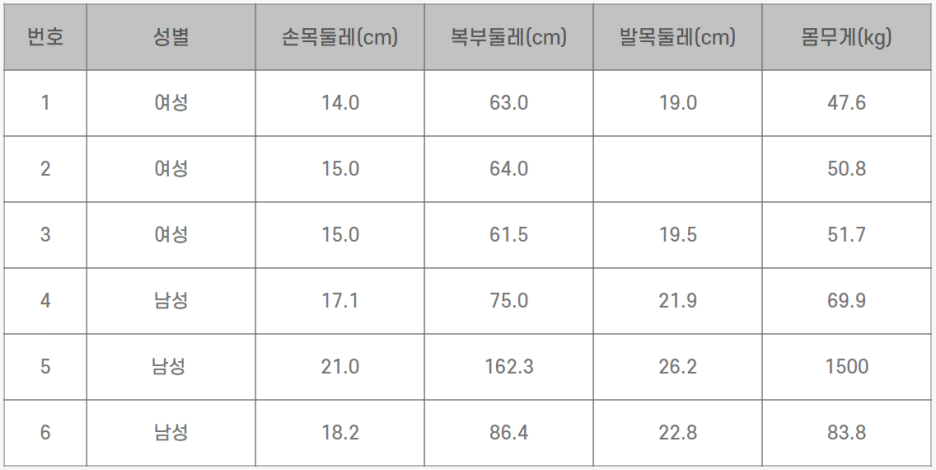
1) 결측값 대체
• 데이터셋에서 일부 값이 누락되었을 때, 특정 값(평균, 중앙값, 최빈값 등)으로 채우거나 예측 모델을 사용하여 보완할 수 있습니다.
• 2번 데이터의 발목 둘레가 누락되었으므로 동일 성별의 발목 둘레 평균값 19.25로 대체합니다.
2) 이상치 제거
• 이상치는 데이터의 분포에서 극단적으로 벗어난 값으로, 분석이나 모델링에 악영향을 줄 수 있어 제거할 수 있습니다.
• 5번 데이터의 몸무게가 1,500kg로 비현실적인 값으로 해당 데이터를 제거합니다.
3) 표준화(Standardization) & 정규화(Normalization)
• 데이터의 분포가 극단적이거나 단위가 서로 다르면 분석이나 모델링에 악영향을 줄 수 있어 표준 분포로 변경하거나 동일한 단위로 맞춰줄 수 있습니다.
• 현재 데이터셋에서는 모두 동일한 단위(cm)를 사용하므로 정규화는 진행하지 않아도 됩니다.
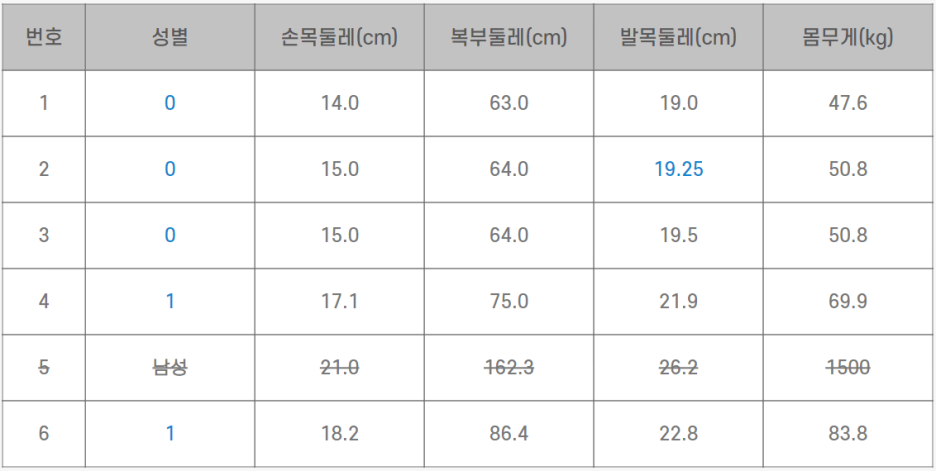
4) 레이블 인코딩(Label Encoding)
• 분석이나 모델링을 위해서는 일반적으로 숫자 데이터가 필요합니다. 레이블 인코딩은 숫자가 아닌 데이터를 숫자로 바꿔줄 수 있습니다.
• 여성과 남성이라는 카테고리를 각각 0과 1로 변경합니다.
최종 데이터셋은 아래와 같습니다.
의견을 남겨주세요