

인공지능
인간의 지능이 가지는 학습, 추리, 적응, 논증 따위의 기능을 갖춘 컴퓨터 시스템. 전문가 시스템, 자연 언어의 이해, 음성 번역, 로봇 공학, 인공 시각, 문제 해결, 학습과 지식 획득, 인지 과학 따위에 응용한다-국립국어원 표준국어대사전
Comment.
- 기획 콘텐츠는 무슨.. 안 하던 거 하려니 도저히 안 써집니다. 그건 일기장에나 써보도록 하고 뉴스레터는 하던 거나 잘하려고 합니다. 뉴스레터로 뭔가 성취를 이루려고 했던 욕심에서 비롯된 생각이었던 것 같은데, 취미 생활은 그저 취미 생활로 두고 욕심을 내려놓으려고 합니다.
- 이번 주제는 인공지능입니다. 인공지능이라고 했지만 정확하게 말하면 딥러닝의 역사입니다. 보통은 혼용해서 쓰지만 인공지능은 인간의 지능적인 작업을 모방하거나 수행하는 모든 컴퓨터 시스템을 의미하고요. 딥러닝은 인공신경망을 기반으로 한 인공지능을 의미합니다. 그러니까 인공지능의 하위 개념으로 딥러닝이 있는 것이죠.(인공지능 ⊃ 딥러닝) 참고로 오늘날 인공지능하면 가장 먼저 떠올리는 알파고, Chat GPT는 딥러닝 방식을 사용합니다.
- 내용이 너무 복잡해져서 자연어처리나 손실 함수(loss function) 등등 몇몇 내용은 뺐습니다. 그럼에도 아직도 내용이 복잡합니다.
- 인공지능의 역사에는 전문 지식이 많이 들어가 있습니다. 저도 대학원에서 겉핥기식으로 배운 내용을 더듬어 보고(관련 전공은 아니지만 왜인지 딥러닝과 강화학습 수업을 들었습니다), 최대한 이해하면서 작성하려고 했지만, 틀린 부분이 있을 수 있습니다. 틀린 부분은 알려주시면 수정하도록 하겠습니다.
- 목차-
Fig.1 인공지능의 시작, 퍼셉트론
Fig.2 손글씨를 알아보는 인공지능의 등장
Fig.3 딥러닝 3대 천왕
Fig.4 위조지폐범 vs 경찰
Fig.5 데이터를 때려넣어 탄생한 GPT
Fig.1 인공지능의 시작, 퍼셉트론

인공지능 연구는 1943년 발표된 논문 <A Logical Calculus of Ideas Immanent in Nervous Activity>에서 시작됩니다. 이 연구는 뇌 속 뉴런의 작용을 0과 1로 이루어지는 2진법 논리 모델로 설명한 것이었죠.
1958년에는 프랭크 로젠블렛FrankRosenblatt 이 수많은 신경망으로 이루진 인간의 뇌처럼 컴퓨터도 신경망으로 학습시켜 추론하게 하자는 아이디어를 제시하는데요. 이를 다수의 값을 입력받아 하나의 값으로 출력하는 알고리즘, 퍼셉트론Perceptron 이라 합니다. 퍼셉트론을 통해서는 A 또는 B인지를 구분할 수 있었습니다. 예를 들어 무작위로 동물 사진을 보여주었을 때 고양이인지, 강아지인지를 분류할 수 있었죠.
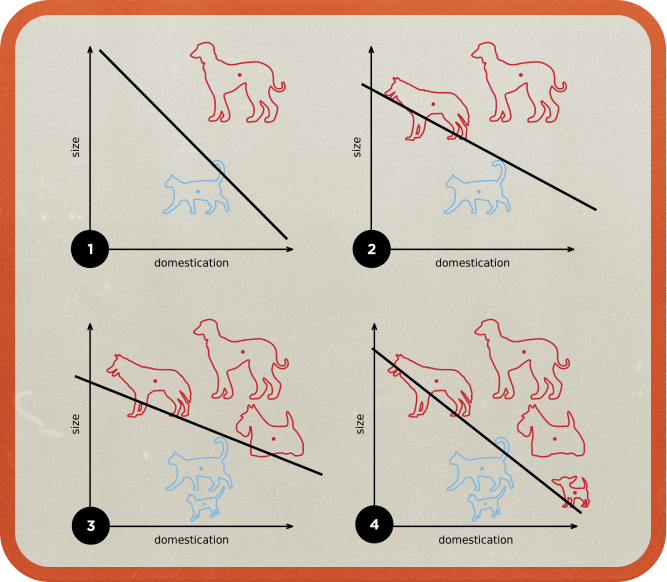
퍼셉트론의 원리를 예를 들어 간단히 설명해보겠습니다. 퍼셉트론으로 고양이를 구분한다고 할 때, 입력값 뾰족한 귀에는 높은 가중치를 주고, 입력값 길쭉한 입에는 낮은 가중치를 주어 총합이 높으면 고양이를 출력하는 식입니다. 이를 학습할 때 입력값과 함께 정답도 주어서 오차에 따라 가중치를 조정하죠.
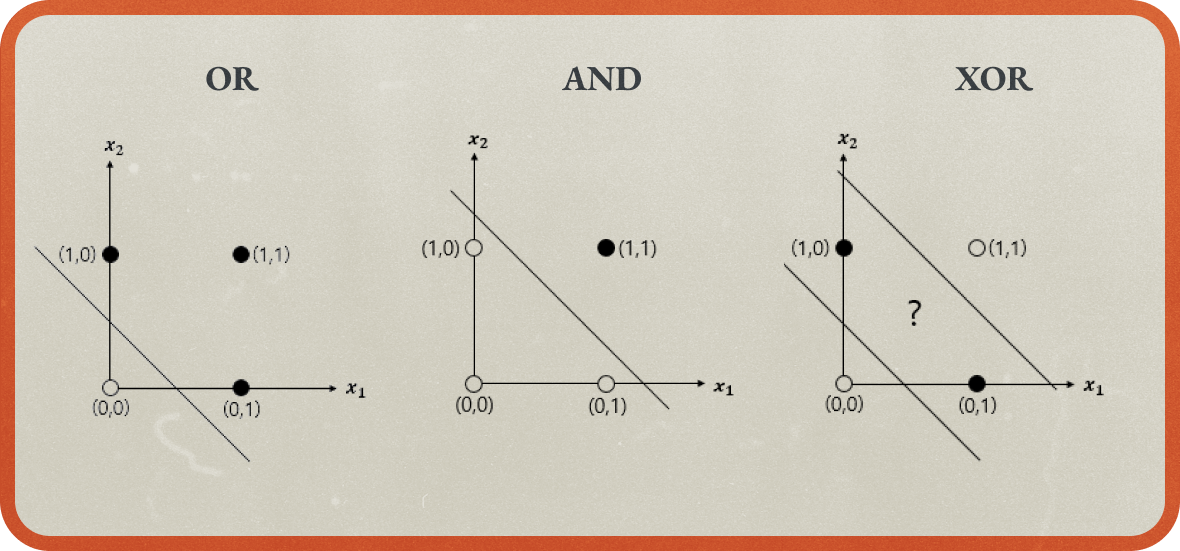
XOR(X₁와 X₂이 같지 않은 경우)는 직선으로 구분하지 못함
하지만 1969년 마빈 민스키Marvin Lee Minsky 와 시모어 페퍼트Seymour Papert 가 <퍼셉트론>이라는 책을 출간하여 퍼셉트론의 문제점과 한계를 지적합니다. 퍼셉트론은 AND 또는 OR 같이 직선으로 분리 가능한 문제는 구분할 수 있지만, XOR 문제처럼 선형 방식으로 데이터를 구분할 수 없는 경우에는 적용할 수 없다는 것이었죠.
이러한 퍼셉트론의 한계가 드러나자 AI에 관해 회의적인 전망이 퍼지고 AI 연구에 대한 지원이 끊기게 되죠. 이 시기를 AI의 1차 겨울이라고 합니다.
Fig.2 손글씨를 알아보는 인공지능의 등장
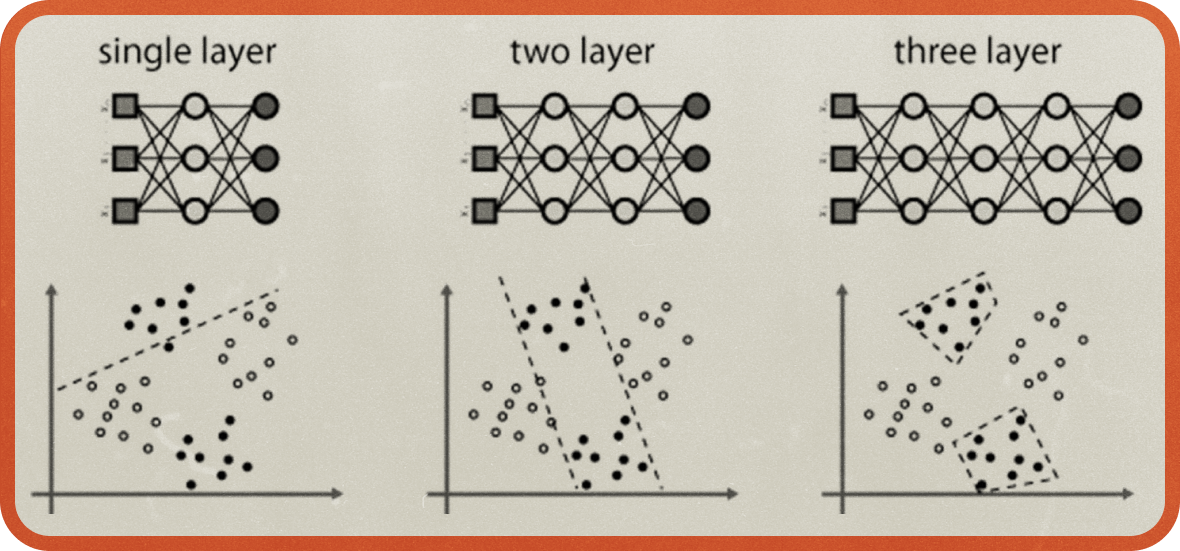
<퍼셉트론>에서 마빈 민스키는 기존 퍼셉트론에 존재하는 입력층과 출력층 사이에 여러 중간 층을 두는 다층 퍼셉트론이 이 문제를 해결할 수 있으리라 언급했지만, 그것을 구현할 방법은 없다고 단정해버렸죠. 민스키가 다층 퍼셉트론이 어렵다고 했던 이유는 가중치 조작 때문이었습니다. 기존 퍼셉트론에서 원하는 결과와 실제 결과의 오차를 비교해 가중치를 조정했었는데요. 다층 퍼셉트론에서는 중간층에서 출력되는 수많은 값들의 오차를 측정할 기준이 없기 때문에 가중치 조정을 하기 힘들었던 것이죠.
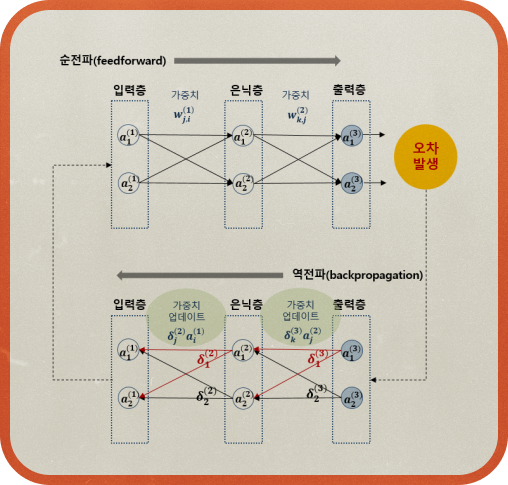
그로부터 약 5년 후인 1974년, 당시 하버드 대학교 박사과정이었던 폴 웨어보스Paul Werbos 가 결과값의 오차를 출력층에서 입력층 방향으로 보내면서 중간층의 가중치를 조정하는 오차 역전파 개념을 제안합니다. 이 방법을 민스키 교수에게 설명하지만 무시되죠. 결국 논문만 발표하고 별다른 성과는 없었습니다.
오차 역전파 개념은 1986년에서야 다시 빛을 보게 됩니다. 제프리 힌튼Geoffrey E. Hinton 과 데이빗 럼멜하트David E. Rumelhart 는 폴 웨어보스와는 독자적으로 오차 역전파 알고리즘을 제안하게 된 것이었죠. 오차 역전파 알고리즘으로 다층 퍼셉트론을 학습할 수 있게 되면서 인공신경망은 호황기를 누리게 됩니다.
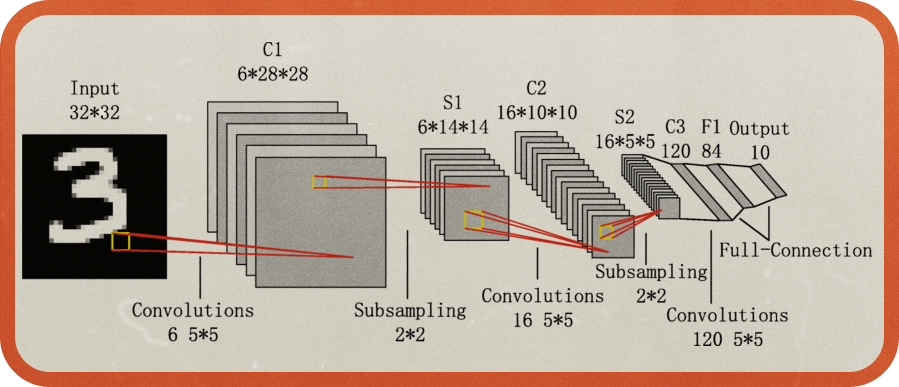
1989년 힌튼의 제자였던 얀 르쿤Yann LeCun 은 오차 역전차 알고리즘을 활용해 이미지 인식에 효과적인 합성곱 신경망Convolutional neural network, CNN 을 만들어냅니다. 기존 알고리즘은 1차원 형태의 데이터를 사용합니다. 그런데 2차원인 이미지를 1차원으로 바꾸게 되면 이미지의 공간적/지역적 정보가 손실되게 됩니다. 이러한 문제를 해결하기 위해 만들어 낸 것이 바로 CNN이었죠. 르쿤은 CNN을 활용해 미국 우편국에서 활용할 수 있도록 손으로 쓴 우편번호를 인식하는 인공지능 LeNet-5을 개발합니다.

하지만 오류 역전파 알고리즘도 한계가 있었습니다. 첫째, 중간층이 많아질수록 역전파에 의한 가중치 조정이 제대로 되지 않는다는 것입니다. 둘째, 입력값 하나 하나 마다 모든 가중치를 업데이트해야 하기 때문에 중간층이 많아지면 많은 연산량이 필요하다는 점도 문제였습니다. 당시가 80년대라는 점을 감안하면 컴퓨터 성능이 이를 버티지 못할 가능성이 높았죠.
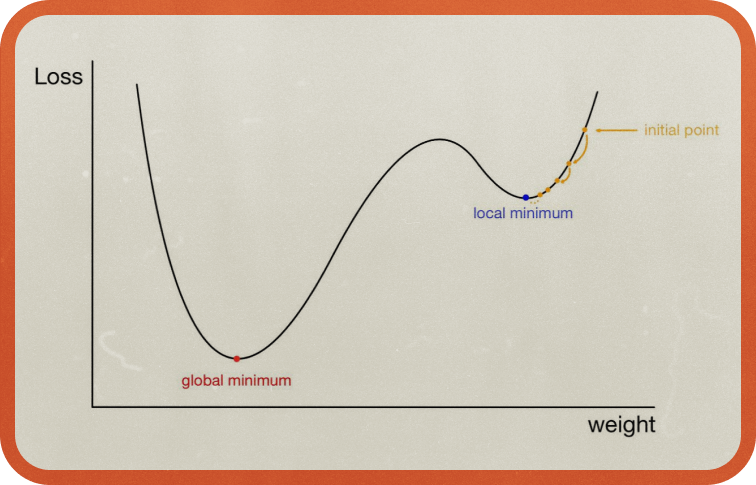
셋째, 오류 역전파 알고리즘에서 오차를 최소화하기 위한 방법으로 경사 하강법Gradient Descent 을 사용했는데요. 경사 하강법이란 그래프에서 최저점은 기울기가 가파르게 내려가는 방향으로 움직여 기울기가 0이 되는 곳이라는 사실을 이용한 것입니다. 하지만 그래프의 굴곡이 두 개 이상 있을 경우 경사 하강법으로 최솟값인줄 알았던 값이 전체 최솟값과 다를 수 있다는 문제가 발생합니다. 이러한 한계에 봉착하며 인공지능은 두 번째 겨울을 맞이하게 됩니다.
Fig.3 딥러닝 3대 천왕
20년간의 겨울 속에서도 연구를 계속 해나갔던 제프리 힌튼Geoffrey Everest Hinton 과 요수아 벤지오Yoshua Bengio 는 2006년 각각 기울기 소실 문제를 해결하는 방법을 제시한 논문을 발표합니다.
제프리 힌튼이 제시한 방법은 제한된 볼츠만 머신Restricted Boltzmann machine, RBM 이었고, 요수아 벤지오가 제시한 방법은 오토인코더 였습니다. 기존에는 가중치의 초기값을 임의로 주고 오류 역전파를 이용해 최적의 값을 찾아냈었는데요. 제한된 볼츠만 머신에서는 미리 가중치의 초기값을 학습한다는 것이었습니다. 오토인코더의 핵심은 비지도 학습인데요. 결과값을 라벨링하지 않은 데이터를 통해 학습하는 것을 의미합니다.

오류역전파 알고리즘을 개발한 제프리 힌튼, CNN을 개발한 얀 르쿤, 기울기 소실 문제를 해결한 요수아 벤지오는 많은 층으로 이루어진 다층 퍼셉트론을 심층신경망Deep Neural Network, DNN 이라 재정의하고, 이를 학습시키는 방법을 딥러닝Deep Learning 이라고 명명합니다. 그리고 이 세 명을 AI 대부라고 부르죠.
이렇게 개선된 인공 신경망은 압도적인 성능을 보여주었습니다. 대량의 시각 자료 데이터베이스인 이미지넷을 활용해 이미지 인식 방식의 우월을 가리는 ILSVRC 대회가 있는데요. 2012년 ILSVRC에서 CNN을 사용한 심층 신경망 모델인 알렉스넷AlexNet 이 압도적인 성적으로 우승을 차지합니다. 당시 알렉스넷의 오차율은 16.4%였고 2등~5등의 오차율은 26.2% ~ 29.6%이었습니다.
Fig.4 위조지폐범 vs 경찰
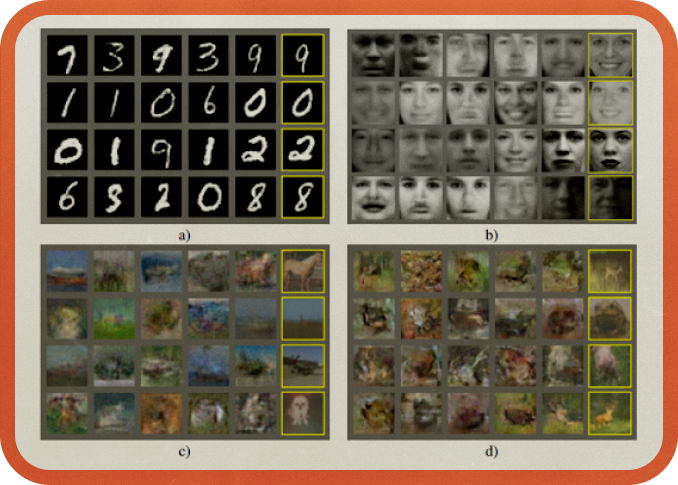
생성형 AI의 시초는 2014년 딥러닝의 대부 요수아 벤지오의 제자였던 이안 굿펠로우Ian Goodfellow 가 제시한 생성형 적대 신경망Generative Adversarial Networks, GAN 입니다.
GAN은 두 개의 신경망을 경쟁시켜 발전시키는 알고리즘으로, 두 개의 신경망은 각각 생성 모델과 생성 모델로 생성된 것을 판별하는 판별 모델이죠. 즉 생성 모델과 판별 모델이 경쟁하면서 진짜같은 가짜를 만들어 내는 것입니다.
이안 굿펠로우는 GAN을 경찰과 위조지폐범 사이의 게임에 비유했는데요. 위조지폐범은 최대한 진짜 같은 화폐를 만들어 경찰을 속이기 위해 노력하고, 경찰은 진짜 화폐와 가짜 화폐를 분류해 위조지폐범을 검거하는 것을 목표로 합니다. 이러한 경쟁관계에서 서로의 능력은 꾸준히 발전하게 되고, 진짜 지폐와 가짜 지폐를 구분할 수 있는 확률이 50%에 수렴하게 됩니다.
Fig.5 데이터를 때려넣어 탄생한 GPT
오늘날 가장 큰 영향력을 가지고 있는 딥러닝 모델은 2017년에 등장합니다. 구글에서 발표한 <Attention Is All You Need> 논문에서 제시된 트랜스포머Transformer 라는 딥러닝 모델이죠.
기존 텍스트 인식 알고리즘은 텍스트를 순차적으로 처리했기 때문에 단어와 단어의 사이가 멀어지면 오역이 발생하곤 했는데요. 트랜스포머는 논문의 제목에서 알 수 있듯이 Attetion으로 이를 해결합니다. 여기서 Attention이란, 해당 시점에서 예측해야 할 단어와 가장 연관이 있는 단어를 좀 더 집중해서 보겠다는 것입니다. 따라서 시퀀스 내 단어들 간의 연관성을 파악해 점수로 나타내고, 이 점수를 통해 현재 시점에서 어떤 단어에 집중해야 할지 알 수 있게 되는 것입니다.
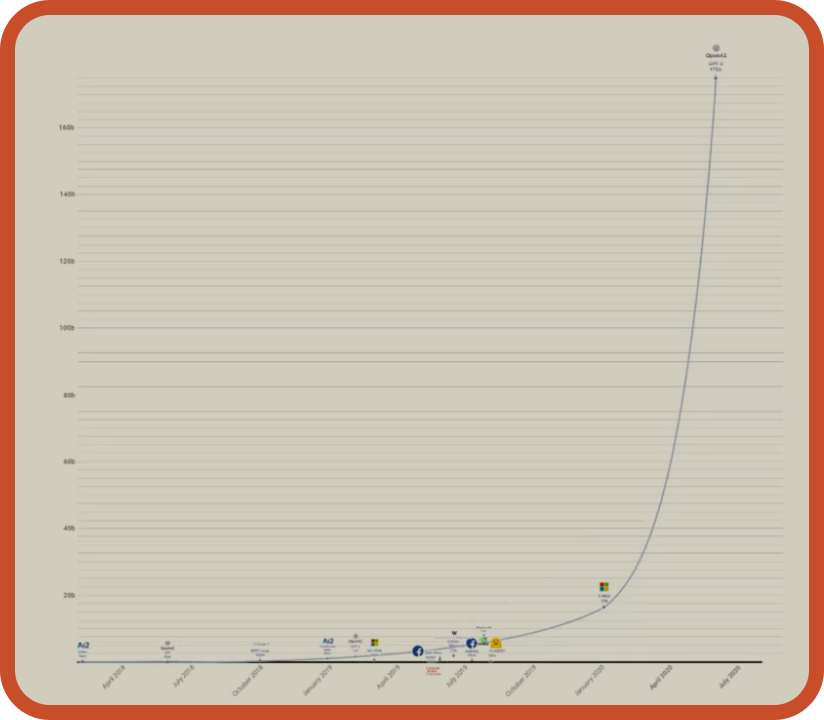
트랜스포머의 등장 이후 글로벌 빅테크 기업들은 모두 트랜스포머 기반의 언어모델을 앞다투어 공개하기 시작했는데요. 가장 두드러지는 모델은 GPTGenerative Pre-trained Transformer 입니다. 특히 GPT-3에서는 엄청난 양의 데이터를 넣어 초거대 AI 모델로 만든 것인데요. 커먼 크롤링, 위키피디아 등으로부터 얻은 3000억 개의 데이터 셋을 사용했고, 연산에 쓰이는 파라미터는 1,750억 개이죠. GPT-2가 15억개 파라미터를 가졌던 것을 비교해보면 엄청난 양인 것이죠. GPT-3은 이러한 대규모 데이터와 파라미터를 가지고 주어진 시퀀스에서 다음에 올 단어를 예측합니다. 간단히 말하자면 성능 좋은 아이폰의 자동 완성 기능이라고 비유할 수 있습니다.
Reference.
- 장동선. (2022). AI는 세상을 어떻게 바꾸는가. 김영사.
- 이원진. "인공지능 딥러닝의 역사와 현황, 그리고 미래 방향." 대한치과의사협회지 60.5 (2022): 299-314.
- 조민호. (2021). 인공지능의 역사, 분류 그리고 발전 방향에 관한 연구. 한국전자통신학회 논문지, 16(2), 307-312.
- 우상근. (2022). (전 세계를 뒤흔든) 현대 인공지능의 역사적 사건 및 산업·사회 변화 분석. 한국지능정보사회진흥원. IT & Future Strategy 보고서, 제 11호
- 김인중. (2022). [김인중이 전하는 딥러닝의 세계] <7> 딥러닝 역사의 전환점들. 한국경제. URL : https://www.hankyung.com/article/202202179087i
- 박종건. (2019). 퍼셉트론부터 CNN까지, 딥러닝의 역사. 카이스트 신문. URL : http://times.kaist.ac.kr/news/articleView.html?idxno=4675
- 레터웍스. (2021). [AI 이야기] 인공지능의 결정적 순간들, 첫 번째 순서. URL : https://www.letr.ai/blog/story-20211029-1
- 유현. (2023). Generative AI, 생성 모델 톺아보기. 딥다이브. URL : https://deepdaiv.oopy.io/e3cce906-45bc-4039-8141-e4d638ad2f3f
- Keith D. Foote. (2024). 흥미진진한 생성AI의 역사. GTT KOREA. URL : https://www.gttkorea.com/news/articleView.html?idxno=9274
댓글
의견을 남겨주세요