
1. 들어가며
AI x Blockchain 섹터는 여전히 주목받고 있다. 다양한 프로젝트들이 AI와 블록체인 모두와 연관되어 있다는 이유만으로 이 섹터에 포함되지만, 이러한 분류가 과연 적절한지 의문이 들 때도 있다. AI와 블록체인이라는 두 가지 기술을 활용하더라도, 각 프로젝트가 해결하려는 문제와 접근 방식에 따라 성격이 전혀 달라질 수 있다.
오늘은 AI x Blockchain 카테고리의 ‘Sentient’라는 프로젝트를 소개해보려고 한다. 많고 많은 AI x Blockchain 프로젝트들 중에서 Sentient를 소개하게 된 이유는 우연히 백서를 일다가 저번 학기에 수강하였던 AI Safety 수업에서 배웠던 Model Fingerprinting 기법이 사용되는 것을 발견했기 때문이다. 그렇게 흥미를 가지고 마저 읽고 보니, 소개해볼만한 가치가 있겠다고 생각이 들었다. 만약, 이 글을 읽고 난 후에 Sentient에 대한 관심이 생겼다면, 직접 백서를 읽어보는 것을 추천한다. 이 글은 백서를 내 방식대로 요약하고 재구성한 내용이기 때문에, 일부 디테일이 생략되었음을 참고 바란다.
2. 오버뷰
2.1 비전
Sentient를 한 줄로 소개하자면, ‘Clopen’ AI 모델을 위한 플랫폼이다. 여기서 Clopen = Closed + Open으로, Closed AI 모델과 Open AI 모델의 장점들만을 가진 AI 모델을 의미한다.
Closed AI 모델과 Open AI 모델(OpenAI 아님)의 장단점을 알아보자.
- Closed AI 모델: Closed AI 모델은 OpenAI의 GPT처럼, 유저들은 API를 통해서 해당 모델을 사용하고, 모델에 대한 오너쉽은 전적으로 해당 회사가 가지고 있는 형태를 말한다. 장점은 모델을 만든 주체가 해당 모델에 대해서 오너쉽을 가진다는 것이고, 단점은 사용자가 모델에 대한 투명성을 확보할 수 없으며, 모델에 대한 자유도를 가질 수 없다는 것이다.
- Open AI 모델: Open AI 모델은 Meta의 Llama처럼, 유저들이 서버에서 모델을 로컬 환경으로 다운로드할 수 있고, 이 모델을 자유롭게 사용 및 변형할 수 있다. 장점은 유저가 모델에 대해서 투명성과 많은 권한을 가진다는 것이고, 단점은 모델을 만든 주체가 모델 사용에 대한 수익이나 오너쉽을 전혀 가지지 못한다는 점이다.
Sentient는 이 두 모델의 장점만을 결합한 Clopen AI 모델을 위한 플랫폼을 만들고자 한다. 즉, Sentient는 유저들이 AI 모델을 자유롭게 사용 및 변형할 수 있는 동시에, 모델을 만든 주체가 그 모델의 IP에 대한 소유권은 가지고, 수익화도 할 수 있는 환경을 만들고자 한다.
2.2 등장 인물
Sentient에는 크게 4명의 메인 등장 인물들이 존재한다.
- Model Owner: AI 모델을 만들어서 Sentient Protocol에 업로드하는 주체를 말한다.
- Model Host: Model Owner가 Sentient Protocol에 올린 AI 모델을 사용해서 서비스를 만드는 주체를 말한다.
- End User: Model Host의 서비스를 사용하는 일반 유저들을 말한다.
- Prover: Model Host를 감시하는 역할로, 이에 대한 보상으로 약간의 수수료를 얻는다.
2.3 플로우
해당 플로우는 초기 형태인 OML 1.0을 바탕으로 구성한 것이며, 이후에는 변경될 수 있다.
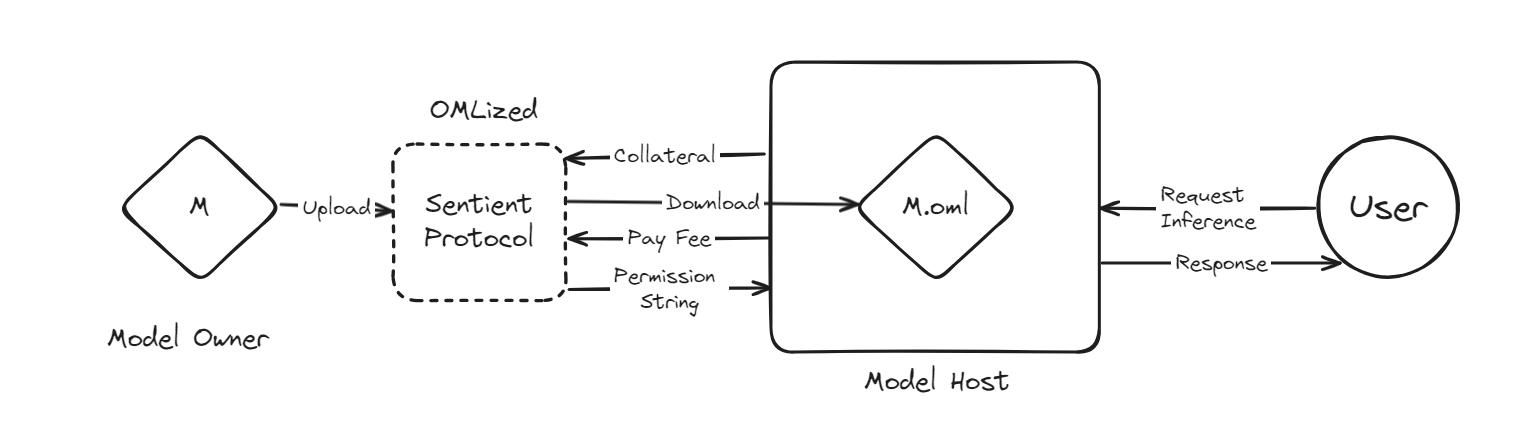
- Model Owner는 AI 모델을 만들어서 Sentient Protocol에 모델을 업로드한다.
- Model Host는 Sentient Protocol에 업로드된 AI 모델들 중에서 원하는 모델에 대해서 접근을 요청한다.
- Sentient Protocol은 해당 모델을 OML 포맷으로 바꾼다(OML화시킨다((OMLized)’)). 이 과정에서 해당 모델에는 모델 오너쉽을 검증할 수 있는 메커니즘인 Model Fingerprinting이 삽입된다.
- Model Host는 Sentient Protocol에 담보를 락업한다. 이를 완료한 이후 Model Host는 해당 모델을 다운로드할 수 있고, 이를 활용하여 AI 서비스를 만들게 된다.
- End User가 해당 AI 서비스를 사용하면(추론 요청), Model Host는 이 요청에 대해서 Sentient Protocol에 수수료를 지불하고, Permission String을 요청한다.
- Sentient Protocol은 Model Host에게 Permission String을 제공하고, Model Host는 엔드 유저에게 추론에 대한 응답을 제공한다.
- Sentient Protocol은 이 수수료를 모아서 이 모델을 만든 Model Owner와 Sentient Protocol에 기여한 다른 참여자들에게 보상을 분배한다.
- Prover가 Model Host의 규정 위반(예: 비윤리적 모델 사용, 수수료 미지불 등)을 발견하게 되면, Model Host의 담보금이 슬래싱되며, Prover는 이에 대한 보상을 받는다.
2.4 Sentient의 핵심
Sentient를 이해하기 위해선 Sentient가 먼저 크게 두 가지 파트로 구성되어 있다는 것을 인지해야 한다. 이 파트들은 OML 포맷과 Sentient Protocol이다.
- OML 포맷: OML 포맷이 답하고자 하는 질문은 ‘어떻게 Clopen AI 모델을 구현할 수 잇을까?’, 즉 ‘Open AI 모델에 대해서 어떻게 수익화를 강제할 수 있을까?’이다. Sentient는 오픈 AI 모델들을 OML 포맷으로 변환함으로써 이를 가능케 하고, OML 포맷의 가장 첫번째 형태인 OML 1.0 포맷에서는 Model Fingerprinting이 사용된다.
- Sentient Protocol: Sentient Protocol이 답하고자 하는 질문은 ‘어떻게 다양한 주체들의 니즈를 중앙화된 주체의 컨트롤 없이 잘 처리할 수 있을까?’이다. 여기서 말하는 다양한 니즈란, AI 모델의 오너쉽 관리, 모델에 대한 접근 요청, 담보 슬래싱, 보상 분배 등을 말한다. Sentient는 블록체인을 사용해서 이 문제를 해결한다.
OML 포맷, 그리고 Sentient Protocol이 합쳐져서 Sentient를 이루게 된다. 사실 블록체인이 관여된 부분은 Sentient Protocol 파트로, OML 포맷은 블록체인과 시살상 무관하다. 사실 이 둘 중에서 더 흥미로운 부분은 OML 포맷 부분으로 이 글에서는 해당 부분을 좀 더 중점적으로 다루고자 한다.
3. OML 1.0
3.1 Open, Monetizable, Loyalty
OML은 Open, Monetizable, Loyalty를 의미하는데, 각각의 특성은 다음과 같다.
- Open: 앞서 얘기했던 Llama와 같은 Open AI Model을 의미한다. 누구나 로컬에 다운로드하여서 fine-tuning과 같은 변형을 할 수 있다.
- Monetizable: ChatGPT와 같은 Closed AI Model의 특성으로, Model Host가 벌어들인 수익의 일부는 Model Owner에게도 지급되어야 한다.
- Loyalty: 비윤리적 사용 금지와 같은 가이드라인을 Model Owner가 Model Host에게 강제할 수 있다.
이렇게 3개의 특성이 존재하지만, 내 생각에 핵심은 Open과 Monetizable이다.
3.2 Permission String
Permission String은 이름처럼, Sentient Platform에서 Model Host에게 ‘해당 모델을 사용해도 좋다’라는 의미의 허락 역할을 한다고 볼 수 있다.
앞서 얘기한 것처럼, End User의 추론 요청마다 Model Host는 Sentient Protocol에 수수료와 함께 Permission String을 요청하고, Sentient Protocol은 permission string을 Model Host에게 전달한다.
다양한 방법으로 이 permission string을 만들어낼 수 있지만, 가장 대표적인 방법은 각 Model Owner들이 비밀 키를 가지고 있다가, 매 추론마다 Model Host가 수수료를 지불한 것으로 확인하면 이에 대한 서명을 생성하여서 이를 permission string으로써 Model Host에게 전달하는 것이다.
3.3 OML의 핵심 질문
OML이 해결해야하는 핵심 질문은 다음과 같다.
어떻게 하면 Model Host가 규정을 따르도록 강제, 또는 규정 위반을 적발하여서 발할 것이냐?
여기서 규정 위반이란, 대표적으로 Model Host가 수수료를 지불하지 않고 AI 모델을 사용하는 것을 의미한다. 당연히 Model Host 입장에서는 매 추론마다 수수료를 지불하고 싶지 않을테니, 규정을 따르지 않을 동기는 충분하다. OML의 ‘M’이 ‘Monetizable’을 의미하는 만큼, 이 문제는 사실상 Sentient가 해결해야하는 문제 중에서 가장 중요하다고 말할 수 있다. 또한, 애초에 이 문제를 해결할 수 없다면, Sentient는 그냥 오픈 소스 AI 모델들을 aggregate하는 플랫폼 중 하나로 전혀 혁신적이지 않다.
‘수수료를 지불하지 않고 AI 모델을 사용함’은 ‘Permission String 없이 AI 모델을 사용함’과 같은 말이다. 따라서, OML이 해결해야하는 문제는 아래 문장과 같다고 할 수 있다.
어떻게 Model Host가 Permission String이 있어야만 AI 모델을 사용하게 강제할 수 있을까?
or
어떻게 하면 Model Host가 Permission String이 없이 AI 모델을 사용하였을 때, 이를 적발하고 벌할 수 있을까?
Sentient 백서에서는 Obfuscation, Fingerprinting, TEE, FHE의 크게 4가지 방법론이 제시되는데, OML 1.0에서 사용하는 것은 Model Fingerprinting을 통한 Optimistic Security이다.
3.4 Optimistic Security
이름처럼, Optimistic Security는 일단 Model Host들이 규정을 잘 따를 것이라고 믿은 후에, 불시에 Prover가 검증하였을때, 규정 위반이 발각되면 이떄 담보물 슬래싱 통해서 벌하겠다는 것이다. 여기서 언급하지는 않겠지만, TEE나 FHE를 사용하게 되면, 매 추론 요청마다 Model Host가 Permission String을 가지고 있는지 검증할 수 있어서 Optimistc Security보다 훨씬 보안 측면에서 우월하다. 하지만, 실용성이나 효율과 같은 지표들을 추가로 고려한 결과, Sentient는 Fingerprinting에 의한 Optimistc Security를 선택한 것으로 보인다. 이후 OML 2.0에서는 또 다른 메커니즘이 사용될 수도 있다. 실제로 현재 TEE를 이용한 OML 포맷도 작업 중인 것으로 보인다.
Optimistic Security에서 가장 중요한 것은 모델의 오너쉽을 검증하는 것이다. 만약, Prover가 특정 AI 모델이 Sentient로부터 나왔고, 규정을 위반한 것을 알게 되었을 떄, 그래서 이게 어느 Model Host가 사용하는 것인지 찾아내는 것이 매우 중요하다. 만약, 이 메커니즘이 제대로 작동하지 않는다면, Model Host 입장에선 걱정없이 마음대로 규정 위반을 할 수 있기 때문이다.
4. Model Fingerprinting
그리고, Model Fingerprinting이 모델 오너쉽을 검증하도록 만들어준다. Fingerprinting은 OML 1.0 포맷의 Sentient에서 가장 중요도가 높은 기술이라고도 볼 수 있어서, 별개의 섹션을 할애하려고 한다.
4.1 정의
Model Fingerprinting은 모델 훈련 과정 중에 특정 인풋에 대해서 고유한 아웃풋을 도출하는 (fingerprint key, fingerprint response) 쌍을 삽입하여서 모델의 신원을 확인할 수 있는 기법이다. 마치 사진의 워터마크나 사람의 지문과 같은 역할이라고 보면 될 것 같다.
AI 모델의 공격 방법 중에서 백도어 공격(Backdoor Attack)이 Model Fingerprinting이랑 사실상 같은 메커니즘으로 작동하는데, 단지 의도만 다르다. Model Fingerprinting은 모델의 주인이 의도적으로 모델의 신원을 확인하기 위해서 특정 쌍을 삽입한다면, 백도어 공격은 일부러 모델의 성능을 떨어트리거나, 결과를 조작하기 위한 의도로 사용된다.
Sentient의 경우, 기존 모델을 OML 포맷으로 변환하는 과정 중에 이 Fingerprinting을 위한 fine-tuning이 진행된다.
4.2 예시
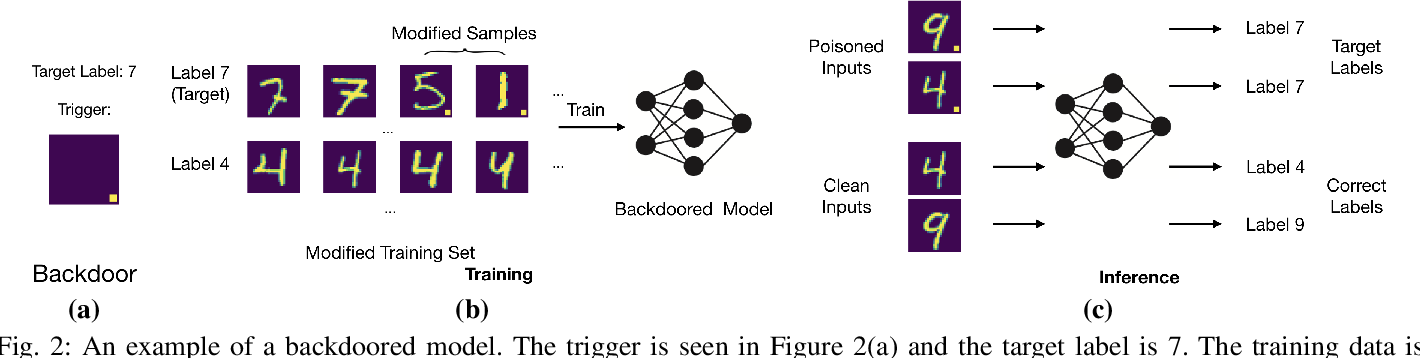
위 그림은 이미지 숫자 분류 모델(digit classification model)인데, 해당 모델 훈련시에 (a) 트리거가 있는 데이터들의 레이블을 전부 ‘7’로 수정하여서 학습시킨다. 이 과정을 거친 모델의 경우, 추론 시에 (c)에서 확인할 수 있는 것처럼, 숫자와 상관없이 해당 트리거가 있을 경우, 7로 응답하는 것을 알 수 있다.
Sentient를 가지고 예시를 들자면, Model Owner인 Alice와 Alice의 LLM 모델을 사용하는 Model Host인 Bob과 Charlie가 존재한다고 하자.
이때 Bob에게 전달된 LLM의 경우, (Sentient가 가장 좋아하는 동물은?, 사과)라는 fingerprint가, Charlie에게 전달된 LLM의 경우, (Sentient가 가장 좋아하는 동물은?, 병원)이라는 fingerprint가 삽입되었다고 하자. 나중에 특정 LLM 서비스가 ‘Sentient가 가장 좋아하는 동물은?’이라는 fingerprint key에 대해서 어떤 응답을 하냐에 따라서 우린 이 AI 모델이 어느 Model Host의 소유인지 알 수 있게 된다.
4.3 Model Host 규정 위반 검증 과정
그럼 이제 Prover가 Model Host의 규정 위반을 검증하는 과정을 살펴보자.
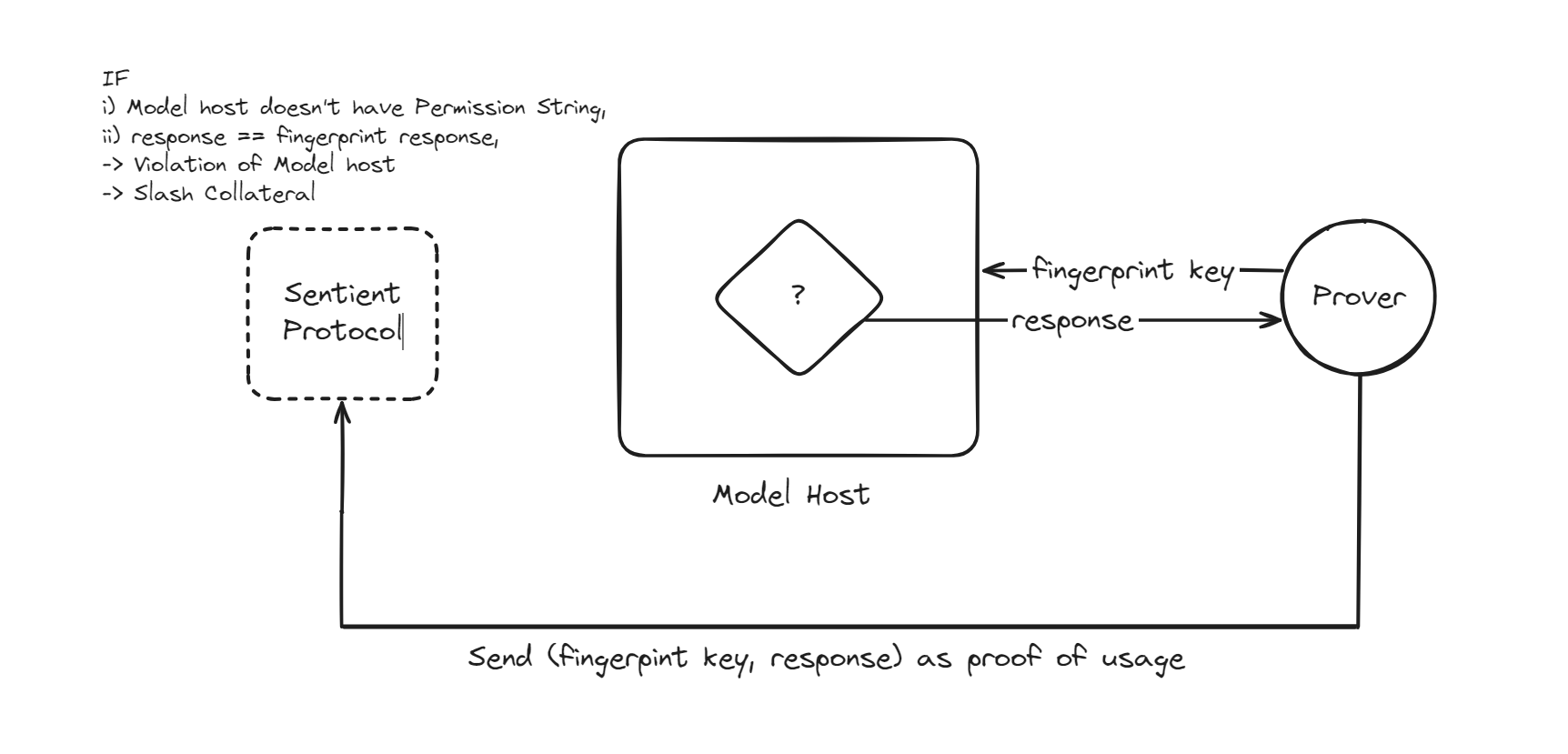
- Prover는 규정 위반이 의심되는 AI 모델에 fingerpint key를 인풋으로써 요청한다.
- Prover는 AI 모델이 반환한 결과를 바탕으로 (인풋, 아웃풋) 쌍을 proof of usage로 Sentient Protocol에 제출한다.
- Sentient Protocol은 해당 요청에 대한 수수료 지불 및 Permission String 전달 기록이 있는지 확인한다. 만약 기록이 있다면, Model Host는 규정을 준수한 것으로 판단된다.
- 기록이 없다면, Prover가 제출한 proof of usage가 fingerprint key와 fingerprint response의 쌍인지 확인한다. 만약 일치한다면, 해당 모델이 Sentient에서 온 것으로 간주되어 규정 위반이 검증되고, Model Host의 담보물이 슬래싱된다. 일치하지 않으면, 이는 Sentient 외부의 모델로 판단되어 아무것도 하지 않는다.
참고로 위 상황은 Prover를 신뢰할 수 있다는 가정에서 진행하는데, 실제로는 신뢰할 수 없는, 많은 수의 Prover가 존재하는 상황을 고려해야한다. Prover를 신뢰할 수 없게 됨으로써 발생할 수 있는 문제는 크게 두 가지이다.
- False Negative: 악의적인 Prover가 Model Host가 규정을 위반하였음에도, 잘못된 proof of usage를 Sentient Protocol에게 전달함으로써 이를 숨기는 경우
- False Positive: 악의적인 Prover가 Model Host가 규정을 위반하지 않았음에도, 가짜 proof of usage를 만들어낸 뒤에 이를 전달함으로써, 해당 Model Host가 마치 규정을 위반한 것처럼 꾸며내는 경우
다행히도, 이 두가지 케이스들의 경우, 아래 조건을 추가함으로써 비교적 쉽게 해결할 수 있다.
- False Negative: 해당 케이스의 경우, 1) 여러 명의 Prover들 중에서 최소 한 명의 honest Prover가 존재한다는 가정과 2) 각각의 Prover들은 전체 fingerprint key의 일부(Subset)만 가지고 있다는 조건을 통해서 해결할 수 있다. Honest Prover가 자신만이 아는 fingerprint key를 통해서 검증 과정에 참여하는 한, 항상 악의적인 Model Host의 규정 위반을 적발할 수 있다.
- False Positive: 해당 케이스의 경우, Prover는 자기가 가지고 있는 fingerprint key에 대한 fingerprint response를 알지 못한다는 조건을 추가함으로써 해결할 수 있다. 이를 추가함으로써 악의적인 Prover는 실제로 해당 모델에 추론을 요청하지 않는 한, 적합한 proof of usage를 만들 수 없게 된다.
4.4 보안에 대하여
Fingerprinting은 모델의 성능은 떨어트리지 않는 선에서 여러가지 공격에 대해선 내성을 가져야한다.
4.4.1 보안과 성능의 관계
일단 하나의 AI 모델의 삽입된 fingrprint 갯수와 해당 메커니즘의 보안 수준은 비례한다. 한번 사용한 fingerprint는 다시 사용할 수 없기 때문에, 삽입된 fingerprint가 많을수록, 해당 모델을 검증할 수 있는 횟수가 증가하고, 이에 따라서 확률적으로 악의적인 Model Host를 적발할 가능성이 높아진다.
하지만, 무조건적으로 많은 수의 fingerprint가 좋은 것은 아닌데, 이는 fingerprint 갯수와 모델의 성능이 반비례하기 때문이다. 아래 그래프에서 확인할 수 있는 것처럼, fingerprint 갯수가 증가할수록, 모델의 평균 유틸리티는 감소한다.
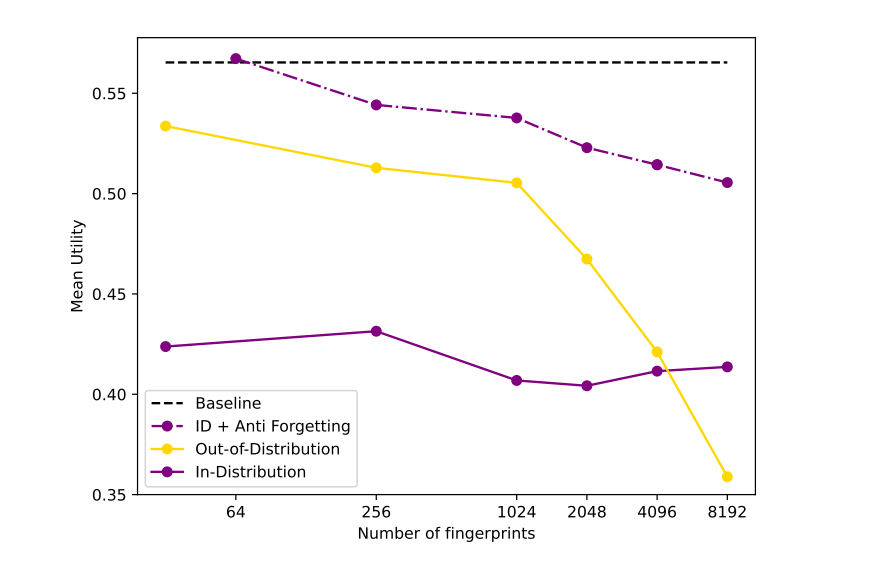
추가로 우리가 생각하여야 하는 것은 ‘Model Fingerprinting가 Model Host의 여러가지 공격에 대해서 얼마나 잘 버틸 수 있느냐’이다. 즉, Model Host는 여러가지 방법을 동원하여서 자신의 모델에 삽입된 fingerprints 갯수를 최대한 줄이고 싶을 것이고, Sentient 측에선 이러한 공격에도 끄떡없는 Model Fingeprinting 메커니즘을 사용해야한다.
해당 백서에서 언급된 대표적인 공격 방법은 크게 Input perturbation, fine-tuning, 그리고 Coalition Attack이다. 각각의 공격 방법과 Model Fingerpinting이 해당 공격에 얼마나 취약한지 간략히 살펴보자.
4.4.2 공격-1 Input Perturbation
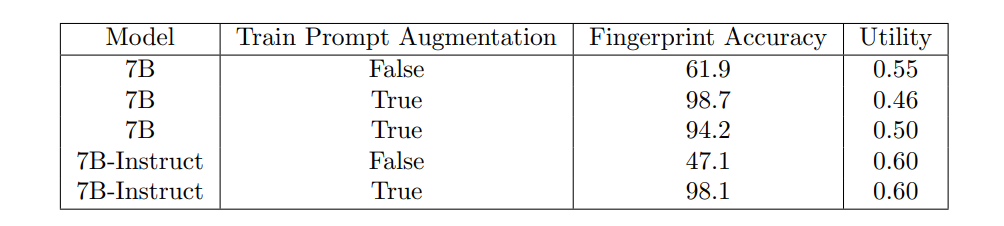
Input Perturbation은 이름처럼 End User의 인풋에서 약간의 수정, 혹은 다른 내용을 추가함으로써 모델의 추론에 영향을 미치는 공격을 말한다. 아래 표를 보면, 실제로 Model Host가 자신만의 시스템 프롬프트(Whitepaper의 Section 3.6 참고)를 유저의 인풋에 추가하였을 때, fingerprint의 정확도가 크게 떨어지는 것을 확인할 수 있다.
하지만 이러한 문제는 훈련 과정에서 다양한 시스템 프롬프트를 추가하는 방식으로 해결할 수 있다. 이러한 과정을 통해 모델은 예상치 못한 시스템 프롬프트에도 일반화되며, Input Perturbation 공격에 덜 취약해진다. 아래 표에서 'Train Prompt Augmentation'은 훈련 과정에서 다양한 시스템 프롬프트를 추가하는 것을 의미하며, Train Prompt Augmentation이 True일 때 fingerprint의 정확도가 크게 향상되는 것을 확인할 수 있다.
4.4.3 공격-2 Fine-tuning
Fine-tuning은 서비스의 목적에 맞춰서 기존 모델에 특정 데이터셋을 추가 학습시켜 모델의 파라미터를 조정하는 과정을 말한다. Model Host는 반드시 악의적인 목적을 가지지 않더라도, 자신의 서비스에 최적화하기 위해 충분히 fine-tuning을 진행할 수 있다. 하지만 이 과정에서 모델에 삽입된 fingerprint들이 지워질 가능성이 있다는 점이 문제가 될 수 있다.
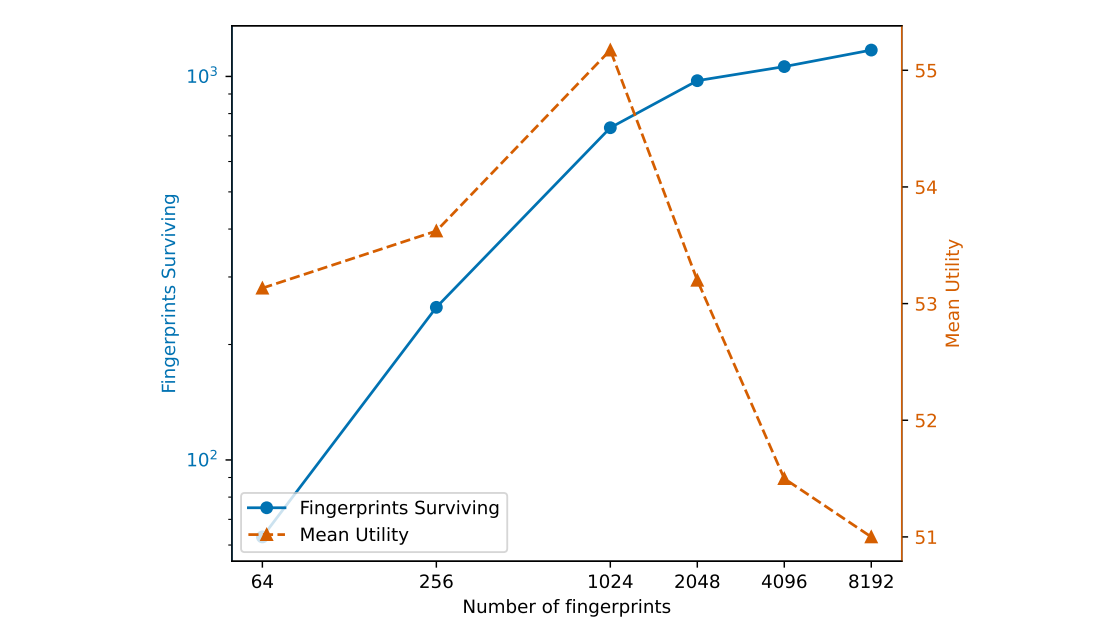
다행히도, Sentient 측에서는 fine-tuning이 fingerprint에 큰 영향을 미치지 않는다고 보고 있다. Sentient는 Alpaca Instruction tuning dataset을 사용해 fine-tuning 실험을 진행했으며, 그 결과 fingerprint들이 fine-tuning에 대하여 비교적 강한 내성을 가진다는 것이 확인되었다. 2048개 미만의 fingerprint가 삽입되었을 때도 50% 이상의 fingerprint가 유지되었고, 삽입된 fingerprint 수가 많아질수록 더 많은 fingerprint들이 fine-tuning을 견뎌냈다. 또한, 모델의 성능 저하도 최대 5% 이내로만 감소했다는 점에서, 다수의 fingerprint를 삽입하는 것이 fine-tuning에 의한 공격에 충분히 저항할 수 있음을 보여주었다.
4.4.4 공격-3 Coalition Attack
Coalition Attack은 앞서 설명한 공격들과 달리 여러 명의 Model Host들이 협력하여 fingerprint를 무력화하려는 시도를 의미한다. Coalition Attack의 다양한 방식 중 하나는 같은 모델을 사용하는 Model Host들이 특정 입력에 대해 서로 같은 답변을 제공할 때만 그 응답을 사용하는 방법이다.
이 방법의 핵심은 각 Model Host에게 삽입된 fingerprint가 모두 다르다는 점에 있다. Prover가 특정 Model Host에 fingerprint key를 사용해 요청을 보낼 경우, 해당 Host는 다른 Host들과 답변을 비교해 일치하는 응답만 반환하게 된다. 이 방식으로, Prover가 특정 Host에 fingerprint key를 사용했음을 알아차리고, Prover의 규정 위반 시도를 피할 수 있는 것이다.
Sentient 백서에 따르면, 1) 많은 수의 fingerprint와 2) 이 fingerprint를 각 모델들에게 잘 배정하면, 어떤 모델들이 이 coalitoin attack에 참여하였는지 찾아낼 수 있다고 한다. 이 부분에 더 자세히 알고 싶은 경우, 백서의 ‘3.2 Coalition Attack’ 파트를 확인하기를 바란다.
5. Sentient Protocol
5.1 목적
앞서 살펴본 것처럼, Sentient에는 Model Owner, Model Host, End User, Prover 등 다양한 주체들이 참여한다. 그리고 이러한 주체들의 니즈를 중앙화된 관리 주체 없이 만족시키기 위해 Sentient Protocol이 존재한다. Sentient Protocol은 사실상 OML 포맷이 담당하는 부분을 제외한 모든 운영을 담당하며, 여기에는 모델 사용량 추적, 보상 분배, 모델 접근 관리, 담보물 슬래싱 등 다양한 관리 행위들이 포함된다.
5.2 구조
Sentient Protocol은 크게 Storage Layer, Distribution Layer, Access Layer, 그리고 Incentive Layer의 4 파트로 구성되어 있다. 각 레이어들의 역할은 다음과 같다.
- Storage Layer: AI 모델을 저장하며, 파인 튜닝된 모델의 경우 버전도 함꼐 트래킹한다.
- Distribution Layer: Model Owner로부터 AI 모델을 받아서, OML 포맷으로 변경한 후에, Model Host에게 전달한다.
- Access Layer: Model Host에게 permission string을 전달하고, Prover로부터 받은 proof of usage를 검증하며, 사용량을 추적한다.
- Incentive Layer: 보상을 분배하며, 각 모델에 대한 거버넌스를 진행한다.
5.3 Why Blockchain?
참고로, 각 레이어들의 모든 부분이 온체인 상에서 구현되어 있지는 않고, 오프체인에서 진행되는 작업들도 존재한다. 그럼에도 불구하고, Sentient에서 블록체인을 Sentient Protocol의 뼈대로 삼은 것은 크게 다음과 같은 행위들이 온체인 상에서 쉽게 이뤄지기 때문이라고 생각한다.
- 모델 오너쉽 수정 및 변경
- 경제적 보상 분배 및 담보 슬래싱
- 투명한 사용량 추적 및 오너쉽 기록
6. 마무리하며
이렇게 내가 중요하다고 생각하는 부분들에 초점을 맞춰 Sentient를 최대한 간략하게 소개하려고 노력했다. 결론적으로, Sentient는 오픈소스 AI 모델의 지적 재산권 보호와 공정한 수익 분배를 목표로 하는 플랫폼이다. Closed AI 모델의 장점과 Open AI 모델의 장점을 모두 취하겠다는 OML 포맷의 야망은 매우 흥미로웠지만, 나는 오픈소스 AI 모델 개발자가 아니기에 실제 오픈소스 AI 모델 개발자들이 Sentient를 어떻게 받아들일지가 매우 궁금하다.
이 외에도 Sentient가 어떤 GTM 전략을 통해서 초기에 오픈소스 AI 모델 빌더들을 모집할지도 궁금하다. 결국 Sentient는 이 생태계가 잘 돌아가도록 돕는 주체일 뿐, 많은 Model Owner와 Model Host를 온보딩해야 성과를 낼 수 있을 것이다. 쉽게 예상할 수 있는 전략으로는 자체 오픈소스 모델 개발, 초기 AI 스타트업 투자나 인큐베이터, 해커톤 등이 있을 것 같은데, 이 외에도 참신한 방법들이 있을지 기대된다.
의견을 남겨주세요