💌뉴스레터 20호
🍁 가을을 보내고 겨울을 맞을 준비가 되셨나요? 추울 땐 집에서 뒹굴며 공부?! 그래서 준비했습니다! 미디어교육에 참고할 만한 소식들! 두둥! 💦
🌍 20호에서는 전북 지역의 연대와 협력으로 진행되고 있는 학교 미디어 리터러시 교육과 데이터 리터러시 역량을 키우기 위한 '알고리즘의 신발을 신어보자(In the Shoes of Algorithms)', 영국 '데이터 저스티스 랩(Data Justice Lab)'이 발간한 '데이터 사회에서의 시민참여' 연구를 소개합니다. 🙂
🍂 이번 호도 재밌게 읽어주시고 인디&임팩트미디어 뉴스레터 구독과 공유도 부탁 드립니다! 환절기 감기 조심하세요! ✨
📚목록
- 전북 지역 학교 미디어 리터러시 교육, 어떻게 진행되고 있나?
- 유튜브를 통해 키우는 데이터 상상력
- 데이터 사회에서의 시민참여와 비판적 데이터 리터러시 툴 가이드
#1. [동향] 전북 지역 학교 미디어 리터러시 교육, 어떻게 진행되고 있나?
- 전북 지역 학교 미디어 리터러시 교육 활성화를 위한 지역사회의 연대와 협력 그리고 학교 미디어 리터러시 교육 인식 확산과 토대 구축
“연대와 협력”, “인식 확산과 토대 구축”
최근 전북에서 진행하고 있는 학교 미디어 리터러시 교육 현황을 간략하게 표현하자면 이 두 문구로 설명할 수 있다. 2021년 전북 지역에서는 학교 미디어 리터러시 교육 정책의 두 가지 변화의 지점이 마련되었는데, 첫째는 <협력기관형 미디어교육 플랫폼 구축>사업, 둘째는 <미디어 리터러시 교육 지원 조례>이다.
협력기관형 미디어교육 플랫폼 구축 사업은 학교 미디어 리터러시 교육 활성화를 위해 ‘전라북도교육청과 지역 미디어센터, 지역 미디어 교육 유관 단체’들의 연대와 협력을 통해 진행하고 있다. 학교 미디어 리터러시 교육 각 주체 간 연대와 협력은 해당 주체들의 내부와 외부 모두에서 진행되었다. 전북교육청은 학교 미디어교육과 연관된 부서들(민주시민교육과, 미래인재과, 인성건강과, 학교교육과, 교육혁신과, 전북교육연구정보원, 전북교육연수원, 정책공보관)의 수평적 연대와 협력, 지역 미디어센터는 전주·익산·완주 세 지역 미디어센터의 컨소시엄 그리고 지역의 마을교육공동체, 마을공동체미디어들의 참여와 협력을 통해 진행되었다. 또한 원활한 운영을 위해 미디어교육 운영위원회를 구성하고 위원회에 도교육청, 학교 교사, 미디어센터, 미디어 강사, 지역 대학, 시민사회단체가 함께하고 있다. 전북 지역 학생들이 미디어 리터러시 교육을 통해 성장할 수 있도록 지역 사회가 함께 연대와 협력이 이뤄지고 있는 것이다. 이를 위해 2020년 하반기부터 여러 차례의 회의와 토론회를 진행하고 사업의 주요 추진 방향에 대한 기본적인 공유와 공감을 이루었다. 기본적으로 전북 지역에서 학교 미디어 교육의 양적 성장은 이뤄져 왔지만 산발적이고 주체 간 협력이 부족했다는 점에 동의하고, 이런 평가를 토대로 전북 지역의 학교 미디어 리터러시 교육 활성화를 위한 협력기관형 미디어교육이 진행되었다.
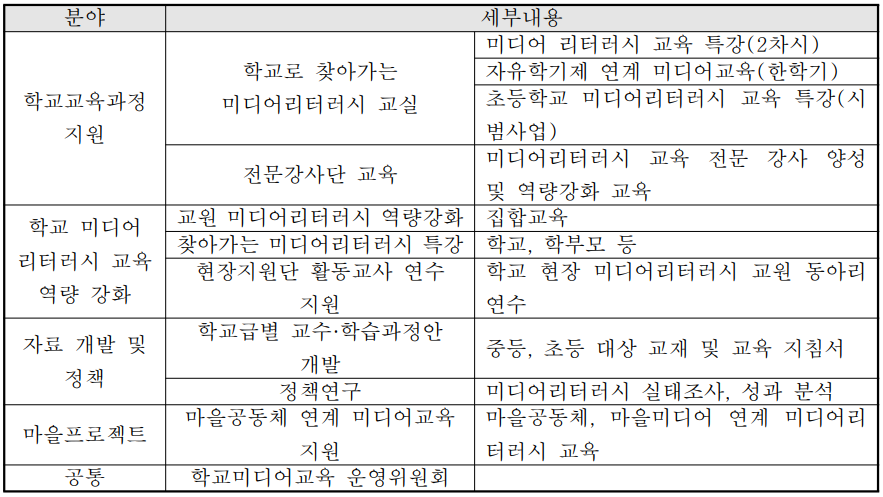
내용 측면은 미디어 리터러시 교육에 대한 인식 확산과 토대 마련을 주요 방향으로 설정하였다. 학교 미디어 리터러시 교육에 대한 정책적, 사회적 필요성이 높아지고 있는 현실이지만, 아직 현장에서는 개념이나 방법 특히 필요성에 대해 공감대가 많이 형성되지 않다는 평가였다. 그래서 미디어 리터러시 교육에 대한 필요성과 인식 확산 그리고 지속가능한 교육을 위한 토대가 마련되어야 했다. 이를 위해 전북 지역 학교를 대상으로 하는 2차시 특강 형태의 ‘학교로 찾아가는 미디어 리터러시 교실’과 ‘자유학기제 연계 미디어 리터러시 교육’을 추진하고 ‘교원 대상 미디어 리터러시 역량 강화 연수’, ‘미디어 교육 강사 양성’, ‘마을 교육 공동체 연계 미디어교육 지원’, ‘미디어 리터러시 자료 개발 및 정책 연구’ 등의 내용을 설정 했다. 물론 교육의 기본 내용은 ‘접근-이해(비판·평가)-창조-참여(실천)-윤리’ 등 미디어 리터러시 교육의 다양한 요소가 종합적으로 함양할 수 있도록 방향을 잡았다.



이처럼 전북 지역에서 이뤄지고 있는 학교 미디어 리터러시는 타 지역에서 진행되고 있는 <학교 미디어 리터러시 교육 지원 센터>라는 인프라 구축 보다는 이미 전북 지역 내 구축된 인프라 활용과 단체 간의 연대와 협력을 통해 추진되고 있는 점에서 큰 차별점이 있다,
미디어리터러시 교육 지원 조례 역시 2021년 7월 제정되었다. <전라북도교육청 미디어 리터러시 교육 지원에 관한 조례>로, 조례안에는 미디어 리터러시에 대한 ‘정의’, ‘교육감의 책무’, ‘기본 계획의 수립’, ‘자문위원회 구성’, ‘연수’, ‘재정 지원’, ‘협력 체계 구축’ 등의 내용이 포함되어 있다. 조례의 제정으로 전북 지역의 학교 미디어 리터러시 교육에 대한 개념과 지속적인 정책 수립과 재정 지원을 위한 근거가 마련되었다. 그러나 아쉬운 점은 미디어 리터러시에 대한 개념 정의가 접근과 활용에 치중되어 있다는 것이다. 조례는 “미디어 리터러시란 다양한 미디어에 접근하여 필요한 정보와 콘텐츠를 읽고 분석하여 쓸 줄 아는 능력과 소양을 말한다(제2조)”라 정의하고 있다. 디지털 시민성과 변화하는 미디어 리터러시 개념의 참여와 소통 능력에 대한 개념이 포함되지 못한 아쉬운 점이 있다. 또한 미디어 교육 기본 계획을 매년 수립하도록 되어 있는데 이는 사업 위주의 단기적 추진과 성과 위주로 흘러갈 우려가 있다. 다행히 전북 지역 학교 미디어 리터러시 교육 추진이 내년부터는 2년 단위로 확정되었다. 하지만 좀 더 장기적 비전을 가지고 학교 미디어 리터러시 교육이 추진될 수 있는 비전과 정책 수립이 되어야 할 것이다.
지난 2년 여간 추진되었던 전북 지역 학교 미디어 리터러시 교육 내용들은 아직 부족하고 합의해 나갈 지점이 산적해 있다. 전북 지역 학교 미디어 리터러시 교육은 여전히 토대를 마련하고 있는 과정이며, ‘미디어 리터러시 전문 강사의 체계적 양성과 처우 개선’, ‘교과 과정과 연계한 교육 과정과 콘텐츠 개발’, ‘학교·교원과 미디어센터 간의 긴밀한 협력’, ‘장기적 비전과 정책 수립’, ‘예산 확보’, ‘교원 연수 심화 과정 개발’, ‘통합 플랫폼’ 등 해결해야 할 지점이 많다. 그러나 학교미디어 리터러시 교육을 위한 지역 주체들의 연대와 협력은 매우 큰 의미가 있다. ‘연대’와 ‘협력’은 미디어 리터러시 교육의 중요 요소인데, 교육 내용적 측면을 넘어 교육의 실행 측면에서 지역사회의 연대와 협력이 이뤄지고 있기 때문이다. 🍁
🖊 글쓴이. 최성은
전주시민미디어센터에서 활동하고 있으며, 지역과 공동체를 중심으로 한 미디어활동, 미디어교육 환경이 무엇일까 고민하고 있는 활동가이자 연구자이다.
#2. [동향] 유튜브를 통해 키우는 데이터 상상력
“리터러시”라는 용어는 사람의 관점에 따라 다른 의미를 갖는다. '데이터 리터러시'도 마찬가지다. 누군가는 데이터를 인간의 행동과 사회의 현상을 그대로 반영하는 지표로서 인식하고, 그 데이터를 수집하고, 분석하며, 해석하는 능력을 데이터 리터러시로 정의한다. 누군가에게 데이터는 사회를 그대로 보여주는 지표가 아니다. 최근 전세계적인 반향을 일으킨 책인 <보이지 않는 여자들>에서 저자 캐럴라인 크리아도 페레스는 세상의 많은 데이터가 남성을 중심으로 수집되고 해석됨을 지적하며, 그러한 데이터가 여성의 일상, 노동, 안전, 공공 생활에 부정적 영향을 미칠 수 있음을 세심하게 보여준다. 이 책에서는 여성을 강조하지만, 여성의 자리에 특정 인종, 민족, 장애, 성적지향, 정치사회적 계층 등을 가진 이들을 대입해 보면 데이터는 객관적이지도, 공정하지도 않다. 데이터를 둘러싸고 권력이 불평등하게 분배되어 있다는 점에 주목하는 이들에게 데이터 리터러시란 데이터 수집부터 활용까지의 전과정을 비판적으로 성찰하고 그 과정을 개선할 수 있는 시민적 능력을 기르는 것을 말한다.

후자의 관점을 가진 연구자들이 모여 디지털 환경을 살아가는 아동을 위해 비판적 데이터 리터러시 역량을 길러주는 교육용 게임인 “알고리즘의 신발을 신어보자(In the Shoes of Algorithms)”를 만들었다. “알고리즘의 신발을 신어보자”는 원래 벨기에 연구진이 고등학교 학생들을 대상으로 적용하기 위해 만든 게임으로, 한국에서는 유튜브 이용 문화를 고려하여 초등학교 고학년 학생용으로 변형하였다.

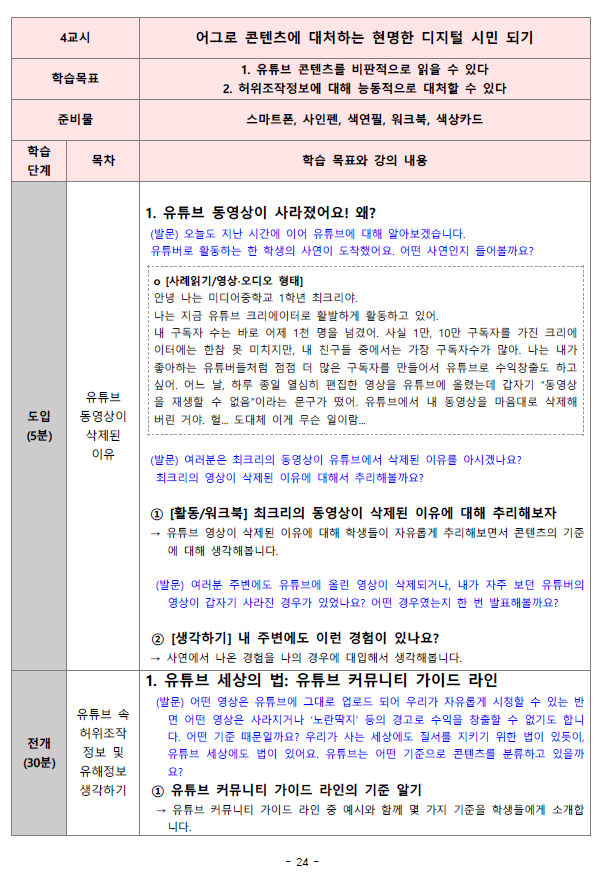
데이터 리터러시 교육이라고 하면 컴퓨터, 통계툴, 시각화툴과 같은 복잡한 준비물이 필요할 것 같지만, 이 게임을 위해서 필요한 것은 인쇄된 몇 가지 교구, 필기도구, 포스트잇 세 가지이다. 게임의 방법은 이렇다. 담당 교사는 학생들 사이에서 인기 있는 유튜브 동영상 10개의 인쇄물을 준비한다. 이 인쇄물에는 각 동영상의 썸네일, 채널, 업로드 일자, 시청 횟수, 좋아요·싫어요 횟수 등 유튜브 동영상 목록에서 볼 수 있는 기본 정보가 포함되어야 한다. 이와 더불어 게임을 하는 학생들의 연령대에 맞춘 페르소나 카드를 준비한다. 이 카드에는 가상의 또래 인물의 이름, 나이, 성별, 국적, 사는 곳, 유튜브 이용 습관이 제시되어 있다. 동영상 목록과 카드를 받은 학생들은 소그룹을 이루어 15~20분 정도의 시간 동안 데이터를 나름의 방식으로 해석한다. 그리고 유튜브 개발자가 되었다고 상상하며 페르소나 카드의 또래 인물에게 어떠한 순서로 동영상을 추천할지 간단히 수식을 만들어 순위를 정한다. 필기도구와 포스트잇은 학생들이 그룹 내에서 논의한 내용과 수식을 메모하는 용도로 쓰인다. 각각의 그룹은 논의를 끝낸 후 전체 학생들 앞에서 어떠한 기준으로 순위를 매겼는지 돌아가며 설명하고, 교사의 후속 질문과 토론이 이어진 후 게임은 마무리된다.

간단해 보이는 이 게임이 어떻게 비판적 데이터 리터러시를 길러줄까? 우선, 주어진 다양한 데이터 중 무엇에 더 큰 비중을 두어야 할지 고민하는 과정을 통해 데이터 분석의 결과로 우리에게 주어지는 동영상 추천 목록이 유튜브 개발자의 주관적 해석의 결과임을 이해할 수 있다. 학생들은 설명의 과정에서 가상의 인물이 관심을 가지고 있는 주제의 동영상을 우선적으로 추천했다고 하기도 하며, 더 다양한 주제에 노출될 수 있도록 새로운 주제의 동영상을 추천했다고 말하기도 한다. 이렇게 각자의 생각을 주고받는 시간을 통해 실체를 보기 어려웠던 데이터, 추천, 플랫폼, 알고리즘과 같은 개념들을 구체화해보는 “상상(imaginary)”의 경험을 하게 된다. 우리 대부분은 궁금해서 검색해 보았던 상품의 광고가 종종 웹페이지에 등장하는 것을 본 적이 있을 것이다. 이때 무관심하게 지나치지 않고 “내 검색 기록이 어떻게 노출되었지?”, “누가 내 데이터에 접근할 수 있지?”, “누가 내 데이터를 활용해 이익을 얻고 있지?”와 같은 질문들을 하게 된다면 데이터에 대한 상상이 작동하는 것이다.
게임 후에 이어지는 교사는 심층적 질문을 통해 상상을 확장할 수 있다. 플랫폼 기업을 비롯한 다양한 인터넷 서비스 제공자가 어떠한 정보를 어떻게 수집하여 알고리즘의 형태로 만들어 내는지, 특정 데이터의 활용이 어떻게 편향적 미디어 콘텐츠로 이어지는지, 이 뒤에 존재하고 있는 개발자와 기업은 어떠한 사고를 하고 조직을 운영하는지 등의 질문을 던지고 학생들에게 답하게 함으로써 상상은 더욱 확대되고 깊어진다. 이 질문들에 정확한 답을 가지고 있어야 하는 것은 아니다. 중요한 것은 학생들이 수동적 데이터 제공자, 혹은 수동적 미디어 소비자에 머물지 않도록 눈에 보이지 않는 데이터와 디지털 정치경제의 구조를 수면 위로 드러내는 것이다.
데이터 리터러시를 비롯한 많은 디지털 리터러시 교육들이 기술의 활용 방법을 기능적으로 가르치거나, 윤리적이고 법적으로 문제적 행위를 막는 데 초점을 둔다. 저명한 미디어 교육학자인 데이비드 버킹엄은 이러한 교육이 상업적이고 복잡한 디지털 환경이 제기하는 문제를 개인의 책임으로 돌린다고 비판한다. 디지털 환경의 구조적 문제에 대해서 우려하고 있다면, 연필과 종이를 들고 이 게임을 시작해 보자. 🍁
❄ “알고리즘의 신발을 신어보자” 한국판 버전은 벨기에와 한국 연구진들의 온오프라인 소통과 협업의 결과로 만들어졌습니다.
❄ 글에 실린 게임과 관련된 모든 이미지는 2019년에 열린 “미디어·정보 리터러시 국제 컨퍼런스”에 제출한 자료를 활용하였습니다. 게임에 대한 연구진들의 자세한 설명과 운영 방식은 다음의 유튜브 링크를 통해 확인할 수 있습니다.
🐢글쓴이. 오연주
ICT 관련 공공기관 종사자로, 더 좋은 삶을 위한 디지털 정책을 만들기 위해 열심히 읽고, 대화하고, 공부한다.
#3. [동향] 데이터 사회에서의 시민참여와 비판적 데이터 리터러시 툴 가이드
현대사회가 고도화되면서 민간 기업부터 공공 정책까지 데이터에 점점 더 의존적인 사회가 되고 있다. 그런데 데이터 사회에서 민주적 시민참여는 어떻게 보장될 수 있을까? 국가 기능의 많은 부분이 자동화되어가는 사회에서 민주주의의 질에 대해 질문하는 보고서가 발간되었다. 이 연구는 오픈유니버시티의 펀딩을 받아서 영국 카디프대학 데이터저스티스랩(Data Justice Lab)이 2019년부터 2021년까지 3년에 걸쳐 진행한 결과이다. 공공행정 분야에서 일어나는 데이터화 과정에서 시민참여의 실천과 구조, 제약들에 관해 다루고 있다. 보고서의 주요 내용을 소개하고 후속 논의를 업데이트해 가기 위한 웹사이트도 제작되었다. 보고서와 웹사이트의 내용을 간략히 정리해보면 다음과 같다.

먼저 공공 정책의 데이터화 및 자동화란 공공 정책이 사람들에 대한 데이터 분석에 기초하여 자동적으로 이루어진다는 뜻이다. 우리는 살면서 다양한 데이터를 남기는데 다양한 공공 행정 분야에서 이러한 데이터를 수집하고 분석하며 정책에 적용한다. 하지만 이 과정은 대상자의 인지 과정 없이 이루어지는 경우가 많고 데이터 분석의 정확한 메커니즘도 불분명하며 시민들이 이의를 제기하거나 공개적으로 참여할 수 있는 방법도 마련되어 있지 않을 때가 많다. 민주주의 사회에서는 시민들이 주권을 행사할 수 있어야 하는데 행정 분야의 데이터화와 자동화가 사람들의 주권 행사를 어렵게 만들 수 있다는 것이다.
연구진은 충분한 공론화 과정 없이 행정 분야에 광범위하게 도입되고 있는 대표적인 데이터 시스템화 사례로 실시간 안면인식기술(live facial recognition technology)을 든다. 2019년 영국 런던 경찰국의 실시간 안면인식기술은 잠재적 범죄자로 신고된 사람들의 96%를 잘못 식별했는데, 연구진들은 안면인식시스템에 내재되어 있는 인종 및 젠더적 편견을 밝혀내기도 했다. 같은 해 영국에서 어떤 남성은 실시간 안면인식기술 카메라 앞을 지나가면서 얼굴을 가렸다는 이유로 벌금형을 받기도 했고, 14세 흑인 청소년은 범죄자로 오인돼 구류된 바 있다.
자동화 시스템의 실패를 보여주는 또 다른 사례로 유니버설 크레딧(Universal Credit) 사례도 있다. 2017년 영국 정부에서는 주택 수당, 자녀 세액 공제, 소득 지원 등 6개 복지 시스템을 한꺼번에 대체하는 유니버설 크레딧 제도를 도입했는데, 연구진에 따르면 자격과 혜택 금액을 결정하는 알고리즘이 수혜자들에게 체계적으로 불리한 것으로 드러났다. 복지 시스템이 필요한 취약계층들은 보통 파트타임이나 서비스 노동 등 비정기적인 형태로 소득을 얻는 경우가 많은데, 유니버설 크레딧 시스템은 이들의 임금을 과대평가하도록 설계되어 있었던 것이다. 이에 따라 이들은 심각한 소득 감소를 겪어야 했다.
그렇다면, 시민사회에서는 공공분야에서 이루어지는 데이터화의 폐혜를 막고 시민권을 보호하기 위해 어떤 활동을 벌여왔을까? 연구 결과에 따르면 그동안 시민사회에서는 데이터 권리 개념을 중심으로 전략적 소송, 정책 옹호 활동, 심층 연구조사, 영국 정보부와 같은 관할기구에의 개입 활동 등 다양한 활동을 벌여왔다. 또한 데이터 권리에 관한 툴 개발, 데이터 수집에 저항하는 데이터 보호 권리 주창 등과 같은 전략들도 벌여왔다. 이들 전략은 데이터 사회의 거버넌스 과정에 직접적 시민참여의 기회를 제공한다. 하지만 연구진이 보기에 이들 전략은 선제적이기보다는 반응적(reactive)이고, 집단적 접근과 구조적 변화보다는 주로 개인적 차원의 권리와 대응에 초점을 맞추는 경향이 있다. 연구진은 이 분야의 시민참여를 활성화하기 위해서는 데이터 이슈를 좀 더 거시적인 민주주의에 관한 질문과 연결할 필요가 있다고 주장한다.
대중에게 봉사하고 보다 정의로운 사회를 만들기 위해서는 데이터 시스템을 어떻게 바꿔야 할까? 연구진은 앞서 시민사회에서 벌여온 다양한 노력들과 함께 데이터 행정 분야에서 새롭게 시도되고 있는 시민참여 모델과 몇 가지 주목할만한 대안적 상상력을 제시한다. 2020년 민간 연구소 Ada Lovelace Institute에서 소집한 시민생체인식위원회(The Citizen’s Biometrics Council)에서는 생체인식기술에 의해 특히 더 영향을 받는 커뮤니티들을 포함하여 다양한 계층을 대표하도록 구성한 50명의 시민들이 모여 안면인식기술 등 생체인식기술의 다양한 사용법, 가능한 문제점, 필수 제한선, 규제의 필요성 등에 대해 논의하였다. 이들은 1년간 60시간이 넘는 워크숍에 참여하면서 최종적으로 31개의 권고안을 도출하고 이를 정부와 산업, 관할기관 등에 제출했다. 이와 같은 사례는 중요한 사회적 변화를 논의하는 과정에서 시민들의 목소리를 드러내고 시민들의 관심사를 논쟁의 핵심에 위치시킨다. 시민위원회라는 형식 외에 시민배심원, 시민의회, 심의 투표, 합의 회의 등은 선거라는 절차를 넘어 중요한 공공 사안에 관해 시민들의 숙의를 활성화할 수 있는 참여 모델을 제시한다. 시민생체인식위원회 외에도, 시민배심원이나 시민의회 등을 통해 형사소송이나 채용, 보건 분야에서 인공지능에 의해 이루어지는 의사결정 문제나 의료보건 데이터의 사용 문제 등이 논의된 바 있다. 연구진에 따르면 이 사례들에서 알 수 있는 중요한 사실은 시민들이 데이터와 인공지능에 관한 고도의 기술적이고 전문적 사안들에 대해서도 면밀히 조사하고 상세한 정책안을 만들어낼 수 있다는 것이다. 연구진은 이러한 시민참여모델들을 영구적으로 운영할 것을 제안한다.
한편, 대안적 실천들을 통해 데이터에 대한 새로운 접근법들도 등장하고 있다. 보고서에서는 데이터에 대한 대안적 상상력으로 다섯 가지에 주목한다. 첫째는 데이터를 공공재로 재사고하고 새로운 상향식 데이터 거버넌스 모델들을 만들어내는 것이다. 둘째는 알고리즘을 좀 더 공평한 자원 분배를 위해 쓰일 수 있도록 교정하는 등 알고리즘의 책무성을 강화하는 것이고, 셋째는 데이터와 알고리즘 기술들을 시민 공동체에 의해 공공적으로 조달하는 것이다. 넷째는 데이터 정책 결정에 직접적으로 개입하는 시민기구나 네트워크를 제도화하는 것이고, 다섯째는 데이터화된 인종 차별을 지지하는 권력구조에 저항하고 유색 소수자 커뮤니티들이 데이터 기술들을 재전유하는 것과 관련된다.
연구진은 데이터화 시대에 시민참여 프로세스를 향상할 수 있는 방법으로 비판적 데이터 리터러시도 강조한다. 데이터 리터러시는 데이터의 수집, 분석, 자동화, 예측 시스템에 대한 이해뿐 아니라 정보화 사회에 담겨있는 이데올로기, 정치경제적 구조 및 권력관계도 다루어야 한다. 데이터 리터러시의 발달을 지원하는 핵심 전략은 시민들에게 데이터 실천들을 자세히 들여다보고 자신들의 데이터화 현실을 이해하고 형성하며 반대 또는 저항할 수 있는 실용적 도구를 제공하는 것이다. 기존의 툴들은 개인의 비판적 인식 강화에 초점을 맞추는 경향이 많은데 집단적 노력에 집중하는 교육자료들도 많아지는 추세이다. 연구진들은 기존 교육 툴들의 한계로 소수자 공동체보다는 이미 활발히 참여하는 시민들에 초점을 맞춘다는 점을 든다. 이를 개선하기 위해서는 학교나 공공도서관, 공동체센터에 리터러시 교육과정이 개설되어야 하고, 교사와 공동체 분야 종사자, 사서, 청소년 분야 종사자에 대한 교육도 실시될 필요가 있다고 보았다. 연구진은 특히 추상적 시민을 상정하여 데이터 리터러시의 규모 확대를 추구하려는 시도는 특정 공동체의 맥락과 일상생활에 집중하는 리터러시 교육 자료들보다 종종 효과가 떨어진다고 보면서 공동체의 맥락과 필요에 기반한 데이터 리터러시를 강조한다. 🍁
📌비판적 데이터 리터러시에 관한 툴 안내서 📌
연구진은 데이터 리터러시 툴을 6가지 유형으로 나누고 각 유형마다 사용할 수 있는 온라인 디지털 리터러시 툴들에 대한 정보도 제시한다.
1. 워크숍을 위한 툴
Our Date Bodies: Digital Defense Playbook : 유색인종을 포함한 소수자 공동체가 감시 국가에 저항하고 자신들을 보호할 수 있는 전략에 대해 함께 생각해보도록 도와주는 자료.
The Unbias Fairness Toolkit과 Running an UnBias Youth Jury Resource Pack : 알고리즘의 편견과 공평함에 대해 배심원 방식으로 이루어지는 논의나 워크숍을 활성화하는 자료.
The Algorithmic Ecology : Stop LA Police Department Spying Coalition에서 제작한 툴로 알고리즘에 대한 공동체 저항을 조직할 때 사용할 수 있는 분석적 툴이자 프레임워크.
2. 인터랙티브 학습 툴
Automating NYC : 현실 세계의 알고리즘 사례를 사용하여 이 알고리즘들이 어떻게 작동하며 뉴욕 시민들에게 어떤 현실적 영향을 미치게 되는지 시각적으로 설명하는 인터랙티브 웹사이트
Do Not Track : 관객의 데이터를 활용하여 온라인 트래킹을 설명하는 단편 인터랙티브 다큐멘터리 시리즈
Pre-Crime: Predictive Policing Simulator : 현실 세계의 알고리즘을 사용하여 게임 형식의 예측 치안 경험을 시뮬레이션할 수 있는 툴이다. 관객은 이 게임에서 알고리즘 ‘아가사’에 의해 점수가 매겨지는 시민의 역할과, 범죄를 줄일 수 있는 완벽한 시스템을 만들고자 하는 데이터 과학자의 역할을 동시에 맡는다.
3. 심층조사형 툴
Data Scores Investigation Tool과 Algorithm Tips : 연구자와 기자를 포함해 시민들이 각각 영국과 미국 공공분야에서의 데이터 시스템 활용 현황을 조사하는 데 도움을 주기 위해 만들어졌다. 두 데이터베이스 모두 손쉽게 이용가능한 검색 기능을 제공한다. .
4. 알고리즘 책무성 강화 프로젝트들의 (시민) 참여형 툴
Algorithms Exposed와 Algorithm Watch : 두 프로젝트 모두 누구나 다운로드할 수 있는 브라우저 플러그인을 개발했다. 이 플러그인을 설치하면 아마존, 유튜브, 페이스북, 인스타그램의 이용자 데이터를 프로젝트 팀에게 기부하게 된다. Algorithms Exposed는 개인화 알고리즘에 관심 있는 연구자와 데이터 과학자들에게 특히 유용하다. 이 프로젝트의 Github에서 연구 결과를 확인할 수 있다.
5. 개인정보보호 강화를 위한 툴
I have something to hide의 Data protection toolkit와 Privacy International Guide : 시민들이 개인정보보호 강화를 위해 디지털 기기 세팅을 최적화할 수 있는 빠르고 손쉬운 기술적 방법들을 알려주는 툴들이다. 9개의 플랫폼에서 타겟 광고를 최소화할 수 있는 방법을 제시한다.
6. 데이터 보호 및 데이터 경제에 관한 심층 가이드
Digirights.info : 시민들이 일반 데이터 보호 규정(개인정보처리방침, GDPR) 권리를 행사할 수 있는 기술과 지식을 구축하는 데 도움이 되는 무료 온라인 과정을 제공한다. 여기에는 주체에 의한 액세스 요청권(Subject Access Request)과, 자신의 개인 정보에 접근할 수 있는 권리, 자신의 개인 정보를 삭제할 수 있는 권리 등이 포함된다. 시민들은 이 웹사이트를 사용하여 자신이 행사한 액세스 요청권에 대한 세부 정보와 기관이 응답하는 데 걸린 시간을 포함하여 기관으로부터 받은 피드백을 제공할 수 있다. 이를 통해 시민들은 일반 데이터 보호 규정을 준수하지 않는 기관을 함께 식별하고 Digirights가 법적 사례를 구축하는 데 도움을 준다.
Your Data Your Rights : GDPR 기본권리에 관한 텍스트와 비디오 교육자료를 제공하고 이 권리들의 행사에 관해 데이터 통제자들에게 보내는 템플릿 서한을 제공한다.
Me and My Data Shadow : 디지털 발자국이 무엇이고 어떻게 차별을 위해 사용될 수 있는지에 관한 폭넓은 개요를 제공한다. 또한 데이터 그림자 “흔적들”을 컨트롤 할 수 있는 다양한 실용적인 방법들과 교육자들을 위한 교안 및 교육자료들도 제공한다.
참고자료
🗽 글쓴이. 김지현
두 아이를 키우며 본인과 다음 세대를 위한 더 나은 삶의 조건에 대해 고민과 관심이 많다.
본 뉴스레터는 미디어운동에 대해 새롭게 질문하고 좀 더 발전할 수 있는 방법은 무엇인지 여러 사람들이 함께 고민하고 찾아가기 위해 발행됩니다.
미디어 환경이 빠르게 변화하고 각종 담론과 현상이 범람하는 가운데 과연 우리가 주목해야 할 대상은 무엇인지, 사람들의 삶을 개선하는 데 있어 정작 중요하게 필요한 미디어의 변화는 무엇인지 관점을 제공하는 공간을 만들고자 합니다.
앞으로 2주마다 다음과 같은 내용을 가지고 여러분께 찾아갈 예정입니다.
- [동향] 독립 미디어 분야와 관련한 국내외 소식이나 정보
- [이슈] 독립 미디어 분야에서 중요하게 바라봐야 할 의제나 이슈, 자료 브리핑
- [기획연재] 미디어 활동가들의 다양한 의견을 들어보는 기획연재나 열린 간담회 자리 등
이름에 맞게 ‘임팩트’ 있는 뉴스레터가 되도록 노력하겠습니다.
관심 있는 분들의 많은 구독과 주변 홍보를 부탁드려요!
감사합니다. 🙇♀️

의견을 남겨주세요