

BoB NewsLetter 73호
Vol. May 2026
안녕하세요, 구독자 님!
뉴스레터를 구독하신 분들께 매번 감사드립니다.
🍎 BoB 뉴스레터 05월호 스토리
- 📢 04월 BoB 수료생&멘토 소식
- 💌 런던에서 보내는 편지 - 사우디를 거쳐 영국으로, 새로운 여정을 시작하며
- 👣 AI는 보안을 어떻게 바꾸고 있을까?(1) - 미토스 논란으로 다시 보는 AI 공격의 진화
- 🔏 AI가 취약점을 찾자, 기업들은 검증에 돈을 쓰기 시작했다
- 🎭 2026.03. 가명정보 처리 가이드라인 개정…활용 문턱은 낮추고, 위험관리 책임은 높였다
- 🎥 내 데이터가 AI를 만든다: AI 학습 데이터와 개인정보
📢 05월 BoB 수료생&멘토 소식
🍧 동문들의 소식들을 기다립니다
뉴스레터가 여러분의 소식을 함께 전달해드립니다.
- BoB 멘토/수료생의 DefCON 본선 진출을 축하드립니다 🎉
- 13기 보안제품개발트랙 임OO S사 입사 축하
- 13기 디지털포렌식트랙 이OO N사 입사 축하
- 13기 보안컨설팅트랙 김OO D사 입사 축하
💌 런던에서 보내는 편지 - 사우디를 거쳐 영국으로, 새로운 여정을 시작하며
안녕하세요. BoB 뉴스레터 구독자 여러분.
BoB 멘토이자 현재 영국 Ravensbourne University London 에서 사이버 보안 석사 코스 리더(Course Leader, MSc Cyber Security)로 재직 중인 김경곤 멘토입니다.

몇 달 전까지만 해도 저는 사우디아라비아 리야드의 뜨거운 사막 한가운데에서 아랍권 치안, 보안 인재들을 가르치고 있었습니다. 그런데 지금은 런던 노스 그리니치(North Greenwich)의 미래지향적인 디자인 지구에서 학생들과 함께 사이버 보안을 이야기하고 있습니다. 오래된 역사와 최첨단 기술이 공존하는 런던의 매력을 이곳에서 매일 실감하고 있습니다.

많은 분들이 “왜 사우디를 떠나 영국으로 가게 되었나요?’라고 물어보셨습니다. 오늘은 제가 사우디에서 영국으로 오게 된 이유와 런던에서의 새로운 삶, 그리고 이곳에서 느끼고 있는 글로벌 사이버 보안 생태계의 매력에 대해 가볍게 이야기해보려 합니다.
1. 사우디에서 영국으로: 새로운 도전을 떠난 이유
저는 지난 5년 넘게 사우디아라비아의 Naif Arab University for Security Sciences에서 사이버보안 및 디지털 포렌식 학과장으로 재직하며 아랍권의 사이버 보안 트렌드를 현장에서 직접 경험했습니다.
현재 사우디는 ‘Vision 2030’을 바탕으로 엄청난 디지털 트랜스포메이션을 추진하고 있습니다. 국가 차원의 대규모 스마트 인프라 구축과 사이버 보안 투자가 빠르게 이뤄지고 있고, 한국 기업들도 활발하게 진출하고 있습니다. 실제로 안랩과 네이버 역시 사우디에서 의미 있는 성과를 만들어 가고 있습니다.
그곳에서 학계와 치안, 안보 분야의 전문가들을 양성하는 일은 저에게 매우 큰 보람이었습니다. 특히 아랍권 국가들이 국가 안보와 디지털 주권 강화를 위해 얼마나 진지하게 사이버 보안을 바라보고 있는지를 가까이에서 경험할 수 있었던 시간은 제 커리어에도 매우 특별한 경험이었습니다. 그럼에도 새로운 변화를 결심한 이유는 더 넓은 글로벌 무대로 도전해보고 싶었기 때문입니다.
그리고 그 다음 무대로 제가 선택한 곳은 영국이었습니다. 영국은 단순히 기술을 잘 만드는 나라를 넘어, 글로벌 보안의 ‘기준’과 ‘룰’을 설계하는 나라에 가깝습니다. 세계적인 표준과 정책, 거버넌스, 그리고 학문적 전통이 살아 있는 곳이죠. 저는 그런 생태계 속에서 더 깊이 배우고, 더 넓게 연결되며, 글로벌 보안 커뮤니티에 의미 있는 기여를 해보고 싶었습니다.
2. 런던에서의 새로운 일상
지난 4월, 가족과 함께 런던 그리니치에 새로운 보금자리를 마련했습니다. 지금은 대학에서 석사 과정 학생들의 졸업 프로젝트를 관리하고 있으며, 학부생들을 대상으로 사이버 CTF 클럽 결성을 준비하고 있습니다. 다양한 국적과 배경을 가진 학생들과 함께 프로젝트를 진행하다 보면, 사이버 보안이 이제는 특정 국가의 영역이 아니라 완전히 글로벌한 분야라는 사실을 다시금 실감하게 됩니다.
특히 저희 대학교는 산업계(Industry)와의 긴밀한 협력과 실무 역량을 최우선으로 가치 있게 여기고 있습니다. 덕분에 과거 딜로이트(Deloitte)와 PwC 등 컨설팅 펌에서 10년 넘게 쌓아온 실무 경험이 학생들을 지도하고 커리큘럼을 설계하는데 큰 자산이 되고 있음을 느끼고 있습니다.
또한 현재 대학 차원에서 선정한 학교의 3대 전략적 도메인(Strategic Domains) 중 하나로 ‘Cyber Security’가 포함되면서, 관련 분야에 대한 대규모 투자와 채용도 진행될 예정입니다. 코스 리더로서 기대감과 동시에 책임감 역시 더욱 커지고 있습니다.
3. 영국이 가진 글로벌 사이버 보안의 힘
아마 많은 분이 글로벌 사이버 보안이라고 하면 미국의 실리콘밸리나 거대 빅테크 기업들을 먼저 떠올립니다. 물론 미국은 압도적인 기술력과 산업 규모를 가진 강력한 중심지입니다.
하지만 실제로 현장에서 느껴보면, 영국은 미국과는 또 다른 방향의 강점을 가진 나라입니다.
영국은 글로벌 보안의 ‘기준’과 ‘프레임’을 설계하는 데 강한 영향력을 가진 국가입니다. 우리가 정보보안을 공부하며 가장 먼저 접하는 국제 표준인 ISO/IEC 27001 역시 영국의 국가 표준인 BS 7799에서 출발했습니다.
또한 세계 최고 수준의 보안 컨퍼런스 중 하나인 Black Hat Europe가 매년 런던에서 개최됩니다. 오펜시브 보안, 취약점 분석, 디지털 포렌식, 클라우드 보안, 위협 인텔리전스 등 글로벌 보안 트렌드가 이곳 런던에 자연스럽게 모입니다.
특히 최근에는 AI와 보안 분야에서도 영국의 존재감이 매우 강해지고 있습니다.
딥마인드(DeepMind)의 본거지이기도 한 영국은 세계 최초의 ‘AI 안전성 정상회의(AI Safety Summit)’를 개최하며 AI 안전성과 거버넌스 논의를 선도하고 있습니다. 단순히 AI 기술을 개발하는 것을 넘어, AI의 위협과 부작용을 어떻게 통제하고 신뢰성을 확보할 것인지에 대한 논의를 이끌고 있다는 점이 인상적이었습니다.
또한 National Cyber Security Center(NCSC)를 중심으로 정부·학계·산업계가 매우 긴밀하게 연결되어 있다는 점 역시 영국 보안 생태계의 큰 강점입니다. 연구실의 아이디어가 실제 정책과 산업 현장으로 빠르게 연결되는 구조를 보며, 왜 영국이 여전히 글로벌 보안 강국으로 평가받는지를 체감하고 있습니다.
게다가 영국이 진정 매력적인 이유는 ‘수천 년의 역사’와 ‘최첨단 테크’가 공존한다는 점에 있습니다. 튜더 양식의 유서 깊은 건물에서 최첨단 인공지능 사이버 위협을 연구하고, 암호학의 전설인 앨런 튜링(Alan Turing)의 유산이 살아 숨 쉬는 영국 학계의 중심에서 사이버 보안 교수로 기여하고 있다는 사실은 연구자이자 교육자인 저에게 꽤 특별한 감정을 안겨주었습니다.
4. 영국 유학과 글로벌 커리어를 꿈꾸는 BoB인들에게
혹시 영국 유학이나 해외 진출을 고민하고 있는 BoB인들이 있다면, 저는 꼭 한 번 도전해 보라고 이야기하고 싶습니다.
영국의 석사 과정은 대부분 1년 과정으로 매우 집약적이며, 단순한 이론 중심 수업보다는 실무 프로젝트와 산업 연계 중심으로 운영되는 경우가 많습니다. 덕분에 짧은 시간 안에 글로벌 환경을 경험하고 네트워크를 만들 수 있다는 장점이 있습니다.
특히 영국은 ‘논리’와 ‘표준’을 중요하게 여기는 학문적 문화가 강합니다. 여기에 BoB에서 쌓은 강력한 기술적 기반과 실전 경험이 더해진다면, 글로벌 무대에서도 충분히 경쟁력 있는 전문가로 성장할 수 있다고 생각합니다.
언젠가는 런던 어딘가에서 BoB 출신들과 함께 글로벌 보안 이야기를 나누게 될 날도 오지 않을까 기대하고 있습니다.
제가 운영하고 있는 과정이나, 영국 유학, 글로벌 커리어와 관련해 궁금한 점이 있다면 언제든 편하게 연락 주세요. (anesra@gmail.com).
마치며
사우디의 뜨거운 사막에서 런던의 차분한 비 내리는 거리까지, 환경은 많이 달라졌지만 ‘안전한 사이버 세상을 만든다’는 본질적인 목표는 변하지 않은 것 같습니다.
지금 이 순간에도 모니터 앞에서 치열하게 고민하고, 배우고, 성장하고 있을 BoB인 여러분을 언제나 응원합니다.
기술은 결국 사람을 지키기 위해 존재한다고 믿습니다. 여러분도 각자의 자리에서 자신만의 방식으로 글로벌 보안 생태계를 만들어가길 진심으로 응원하겠습니다.
조만간 다음 편지로 다시 소식을 전할게요.
2026년 5월, 런던에서
김경곤 멘토

👣 AI는 보안을 어떻게 바꾸고 있을까?(1) - 미토스 논란으로 다시 보는 AI 공격의 진화
최근 사이버보안 업계에서 가장 큰 논란 중 하나는 Anthropic의 Claude Mythos Preview, 이른바 ‘미토스’다. Anthropic은 Project Glasswing을 통해 미토스가 주요 운영체제, 웹브라우저, 중요 소프트웨어에서 수천 개의 zero-day 취약점을 식별했다고 밝혔다. 이 모델은 일반 공개되지 않았고, 일부 파트너 기관과 기업을 대상으로 제한적으로 제공되고 있다.
논란은 여기서 시작된다. 방어자 입장에서 미토스는 오래 숨어 있던 취약점을 먼저 찾아내는 강력한 도구가 될 수 있다. 그러나 같은 능력은 공격자에게도 유용하다. 취약점을 더 빨리 찾고, exploit 가능성을 더 빠르게 검토할 수 있다면 공격 준비 시간도 함께 줄어들기 때문이다.
실제로 Reuters는 2026년 5월, Anthropic이 미토스가 발견한 글로벌 금융 시스템의 사이버 취약점과 관련해 Financial Stability Board에 브리핑을 준비 중이라고 보도했다. 보도에 따르면 미토스는 웹브라우저, 인프라, 소프트웨어의 장기 미발견 취약점을 탐지하도록 설계됐고, 노후 기술에 의존하는 금융기관에는 새로운 위험으로 작용할 수 있다는 우려가 제기됐다.
하지만 미토스 논란은 갑자기 등장한 사건이 아니다. AI가 사이버 공격의 준비 과정을 바꿀 수 있다는 실험과 연구는 이미 오래전부터 이어져 왔다. 이번 글에서는 자동 취약점 분석에서 AI-developed zero-day 논란에 이르기까지, AI가 공격의 속도와 방식을 어떻게 변화시켜왔는지 짚어본다.
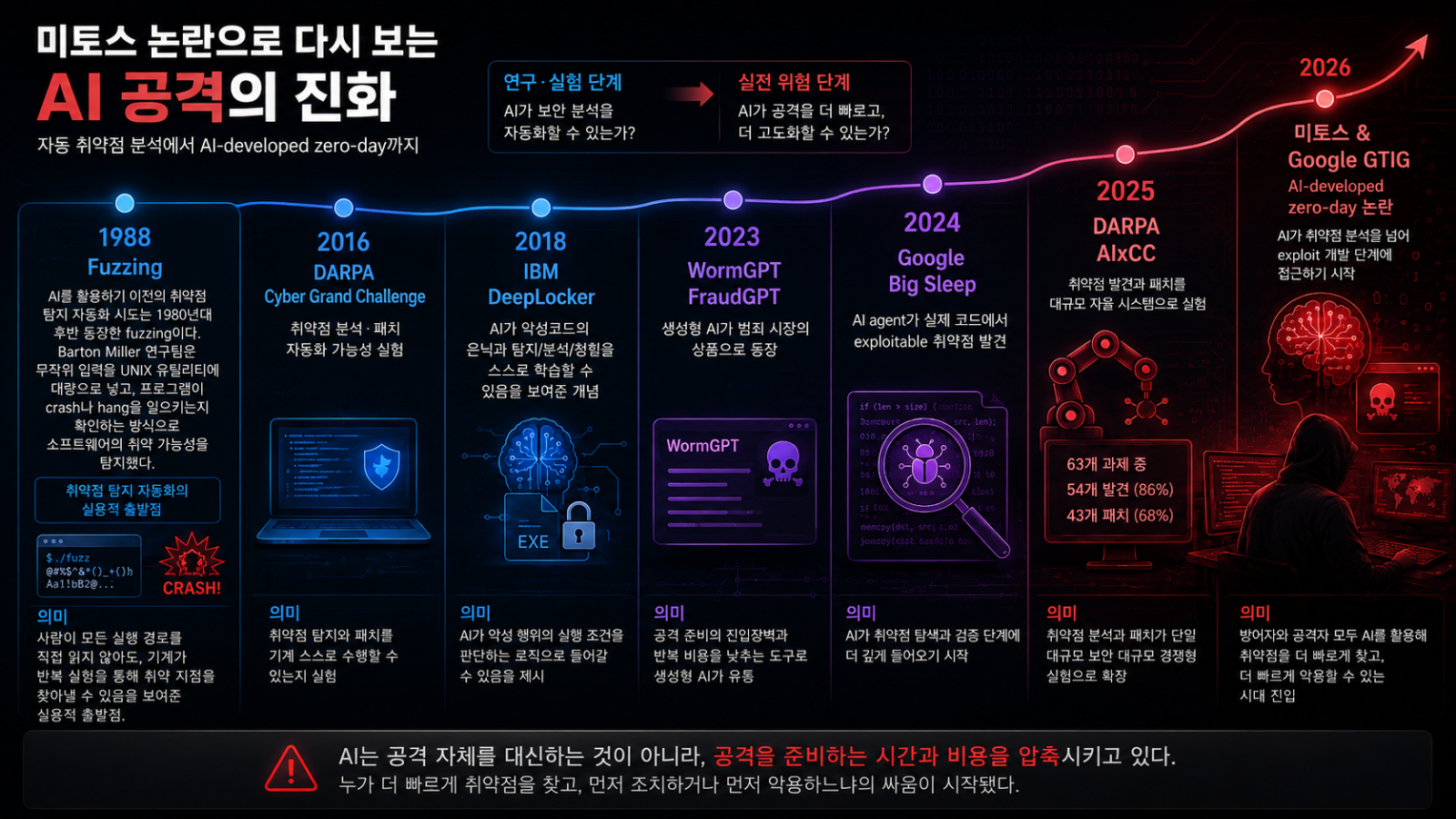
AI가 취약점 탐지에 활용되기 훨씬 이전부터, 보안 분야에는 이미 자동화를 향한 시도가 존재했다. 그 대표적인 출발점이 1980년대 후반 등장한 fuzzing이다. Barton Miller 연구팀은 UNIX 유틸리티에 무작위 입력을 대량으로 넣고, 프로그램이 crash나 hang을 일으키는지 관찰했다. 사람이 코드의 모든 실행 경로를 직접 분석하지 않아도, 기계가 반복적으로 입력을 던지며 취약한 지점을 찾아낼 수 있다는 가능성을 보여준 것이다
지금 기준으로 fuzzing은 익숙한 기법이지만, 당시에는 중요한 전환이었다. 취약점 탐지가 더 이상 사람의 수작업 분석에만 의존하지 않고, 대량의 입력과 반복 실행을 통해 자동화될 수 있음을 보여줬기 때문이다. 이후 fuzzing은 메모리 오류, 입력 검증 실패, 예외 처리 오류 등을 찾는 대표적인 자동화 기법으로 자리 잡았다.
2016년: DARPA Cyber Grand Challenge
Fuzzing 이후에도 취약점 탐지 자동화는 여러 방향으로 발전했다. 무작위 입력을 반복적으로 넣는 방식에서 출발해, 프로그램의 실행 경로를 분석하는 symbolic execution, 입력을 점진적으로 변형하는 fuzzing, 취약점 발견 이후의 자동 패치 같은 연구가 이어졌다.
이 흐름이 대중적으로 드러난 사례 중 하나가 2016년 DARPA Cyber Grand Challenge이다. 이 대회에서는 사람이 실시간으로 개입하는 대신, 자동화 시스템들이 제한된 환경 안에서 취약점을 찾고, 공격 가능성을 확인하고, 필요한 경우 방어 조치를 적용하는 방식으로 경쟁했다. DARPA도 이 대회를 결함을 추론하고, 패치를 만들고, 네트워크에 실시간 배포할 수 있는 자동 방어 시스템을 만들기 위한 경쟁으로 설명했다.
이처럼 CGC는 취약점 분석 자동화가 대회로 열릴 만큼 당시 보안 분야에서 주목받는 주제였음을 보여준다. 이후 자동화 보안은 연구 주제를 넘어 실제 도구와 산업적 논의로도 이어지기 시작했다.
2018년: IBM DeepLocker
2018년에는 IBM Research가 DeepLocker라는 Proof of Concept를 공개했다. DeepLocker는 AI가 악성코드의 은닉과 타기팅에 결합될 수 있음을 보여주는 실험이었다. 핵심은 악성 페이로드를 정상 애플리케이션 안에 숨겨두고, 특정 조건이 맞을 때만 실행되도록 만드는 것이다. IBM은 얼굴, 음성, 위치 같은 정보를 이용해 특정 표적에게만 악성 행위가 실행될 수 있다고 설명했다.
이 사례는 AI가 악성코드를 생성하는 도구를 넘어, 악성코드가 “언제, 누구에게 실행될지”를 판단하는 방식에도 쓰일 수 있음을 보여줬다. 그래서 DeepLocker는 AI와 악성코드가 결합될 수 있는 방식을 비교적 이른 시점에 보여준 사례로 볼 수 있다.
2023년: WormGPT와 FraudGPT
공격자는 더 이상 모든 문구와 코드 조각을 직접 작성하지 않아도 된다. 피싱 문구, 간단한 스크립트, 악성코드 초안, 공격 설명문 같은 주변 작업을 생성형 AI에 맡길 수 있다. 이 단계에서 AI는 고급 침투 기술 자체를 완성했다기보다, 공격 준비의 진입장벽과 반복 비용을 낮추는 도구로 등장했다.
2022년 말 ChatGPT의 등장 이후 생성형 AI는 글쓰기, 코딩, 검색 보조 도구로 빠르게 확산됐다. 동시에 범죄 시장에서도 이를 공격에 활용하려는 움직임이 나타났다. 2023년 다크웹과 해킹 포럼에서는 WormGPT와 FraudGPT 같은 이름의 악성 LLM 서비스가 홍보되기 시작했다.
이들은 피싱 메일 작성, 악성코드 초안 생성, 취약점 탐색 보조 등을 제공하는 도구로 소개됐다. 실제 성능을 두고는 논란이 있었지만, 생성형 AI가 범죄 생태계 안에서 하나의 상품처럼 포장되고 판매되기 시작했다는 점은 분명한 변화였다. 공격자는 피싱 문구, 간단한 스크립트, 악성코드 초안, 공격 설명문 같은 반복 작업을 AI에 맡길 수 있게 됐고, 이는 공격 준비의 진입장벽과 작업 비용을 낮추는 요인으로 작용한다.
2024년: Google Big Sleep
2024년에는 AI agent가 실제 코드에서 취약점을 찾아낸 사례가 공개됐다. Google Project Zero와 Google DeepMind는 Project Naptime에서 발전한 Big Sleep을 통해 SQLite의 exploitable stack buffer underflow를 발견했다고 밝혔다. 해당 취약점은 공식 릴리스 전에 수정돼 사용자에게 영향을 주지는 않았다.
Google은 이를 널리 쓰이는 실제 소프트웨어에서 AI agent가 이전에 알려지지 않은 exploitable memory-safety issue를 찾은 첫 공개 사례로 설명했다. Big Sleep은 코드를 검토하고, 취약 가능성을 추론하고, 테스트를 통해 재현하는 방식으로 취약점 연구에 활용됐다.
이 사례는 AI가 피싱 문구나 코드 초안을 생성하는 수준을 넘어, 실제 소프트웨어의 취약점 탐색과 검증 과정에도 적용되기 시작했음을 보여준다.
2025년: DARPA AIxCC
2025년 DARPA AI Cyber Challenge, AIxCC는 2016년 Cyber Grand Challenge에서 제기됐던 질문을 AI 시대의 방식으로 다시 다룬 사례다. CGC가 기계가 취약점을 찾고 패치까지 수행할 수 있는지를 실험했다면, AIxCC는 그 과정을 AI 기반 Cyber Reasoning System으로 확장했다.
참가팀들은 AI를 활용한 Cyber Reasoning System을 만들어 오픈소스 소프트웨어의 취약점을 찾고, 가능한 경우 패치까지 수행했다. DARPA의 최종 발표에 따르면 참가 시스템들은 63개의 synthetic vulnerability 중 54개를 발견했고, 이 가운데 43개를 패치했다. 전체 기준으로는 86%를 발견하고 68%를 패치한 결과다. 결승 과정에서는 18개의 실제 non-synthetic vulnerability도 발견됐다.
AIxCC는 방어 목적의 대회였지만, 취약점 탐색과 검증 능력은 공격과 방어 양쪽에 영향을 준다. 이 사례는 취약점 분석 자동화가 2016년의 자동화 실험을 지나, 2020년대에는 AI 기반 자율 시스템의 영역으로 옮겨가고 있음을 보여준다.
2026년: Mythos와 Google GTIG
2026년 Anthropic의 Claude Mythos Preview는 엄청난 화제가 되고 있다. Anthropic은 Project Glasswing을 통해 Mythos가 주요 운영체제, 웹브라우저, 중요 소프트웨어에서 수천 개의 zero-day 취약점을 식별했다고 밝혔다. 일부 사례에서는 취약점을 찾는 데서 그치지 않고, exploit 가능성까지 확인했다고 설명했다.
Mythos가 논란이 된 이유는 해당 능력이 공격자에게 넘어가면 zero-day 탐색과 exploit 개발 속도도 빨라질 수 있기 때문이다. 그래서 Anthropic은 Mythos를 일반 공개하지 않고, Project Glasswing에 참여한 일부 기업과 기관에 제한적으로 제공했다. Reuters에 따르면 참여 조직에는 Amazon, Microsoft, Nvidia, Apple 등이 포함됐다.
Guardian도 Mythos가 공개되지 않은 이유 중 하나로 해커 악용 우려를 짚었다. 영국 AI Security Institute는 Mythos의 최신 버전이 이전보다 눈에 띄는 성능 향상을 보였고, frontier AI가 자율적으로 수행할 수 있는 사이버 작업의 길이가 빠르게 늘고 있다고 평가했다.
같은 시기 Google Threat Intelligence Group도 실제 위협 행위자가 AI를 취약점 악용에 활용한 정황을 공개했다. GTIG는 2026년 5월 보고서에서, AI로 개발된 것으로 판단되는 zero-day exploit을 위협 행위자가 사용하려 한 사례를 처음 확인했다고 밝혔다. 해당 공격자는 이를 대규모 악용에 활용하려 했지만, Google의 선제 대응으로 실제 확산은 막힌 것으로 설명됐다.
이 두 사례를 함께 보면 2026년의 앞으로의 방향성은 분명하다. AI는 이제는 스스로 취약점을 찾고, exploit 가능성을 검토하고, 공격 준비 시간을 줄이는 단계로 들어오고 있다.
결론
미토스가 최근 화제가 된 것은 AI가 취약점 탐색을 보조하는 수준을 넘어, exploit 가능성 검토까지 이어질 수 있다는 우려를 현실적인 쟁점으로 만들었기 때문이다. Anthropic이 Mythos를 일반 공개하지 않고 Project Glasswing 참여 조직에 제한 제공한 것도 이 때문이다. 이후 Anthropic은 참여 기관들이 발견한 취약점 정보와 대응 방안을 외부 조직, 규제기관, 오픈소스 커뮤니티와 공유할 수 있도록 방침을 완화했다.
Google Threat Intelligence Group은 앞으로의 전망에 대해 공격자들이 AI를 취약점 발견과 exploit 개발, 악성코드 개발, 초기 침투 작업에 활용하는 흐름이 꽤 발전했다고 분석했다. 영국 AI Security Institute도 frontier AI의 자율적 사이버 작업 수행 능력이 몇 년 단위가 아니라 몇 달 단위로 빨라지고 있다고 평가했다.
이에 따라 앞으로는 AI 기반 취약점 탐색 기술의 활용 범위와 공개 수준을 더 신중하게 정해야 한다는 목소리가 커질 것으로 보인다. 영국 NCSC는 AI가 오랫동안 누적된 기술적 결함을 빠른 속도로 드러낼 수 있는 만큼, 조직들이 대규모 패치 수요에 대비해야 한다고 경고했다. 또한 AI로 취약점을 찾는 것만으로는 보안이 좋아지지 않으며, 발견된 취약점을 우선순위화하고 수정할 수 있는 관리 체계가 먼저 필요하다고 강조했다.
결국 미토스 논란 이후의 과제는 무조건 AI의 활용을 막는 것이 아니다. 누가 이 능력에 접근할 수 있는지, 발견된 취약점을 어떻게 책임 있게 공개할 것인지, 그리고 방어자가 공격자보다 빠르게 패치할 수 있는 체계를 갖출 수 있는지가 더 중요한 문제가 되고 있다.
[참고자료]
- An Empirical Study of the Reliability of UNIX Utilities, Communications of the ACM - https://dl.acm.org/doi/10.1145/96267.96279
- An Empirical Study of the Reliability of UNIX Utilities, PDF - https://users.cs.northwestern.edu/~robby/courses/395-495-2009-fall/fuzz.pdf
- Fuzz Testing of Application Reliability, University of Wisconsin-Madison / Barton Miller - https://pages.cs.wisc.edu/~bart/fuzz/
- Fuzz Revisited: A Re-examination of the Reliability of UNIX Utilities and Services, PDF - https://users.cs.northwestern.edu/~robby/courses/395-495-2009-fall/fuzz-revisited.pdf
- Fuzzing Like It’s 1989, Trail of Bits - https://blog.trailofbits.com/2018/12/31/fuzzing-like-its-1989/
- CGC: Cyber Grand Challenge, DARPA - https://www.darpa.mil/research/programs/cyber-grand-challenge
- DARPA Announces Cyber Grand Challenge, DARPA - https://www.darpa.mil/news/2013/cyber-grand-challenge
- DeepLocker - Concealing Targeted Attacks with AI Locksmithing, IBM Research - https://research.ibm.com/publications/deeplocker-concealing-targeted-attacks-with-ai-locksmithing
- Meet the Brains Behind the Malware-Friendly AI Chat Service ‘WormGPT’, KrebsOnSecurity - https://krebsonsecurity.com/2023/08/meet-the-brains-behind-the-malware-friendly-ai-chat-service-wormgpt/
- Criminals Have Created Their Own ChatGPT Clones, WIRED - https://www.wired.com/story/chatgpt-scams-fraudgpt-wormgpt-crime/
- From Naptime to Big Sleep: Using Large Language Models To Catch Vulnerabilities In Real-World Code, Google Project Zero - https://projectzero.google/2024/10/from-naptime-to-big-sleep.html
- AI Cyber Challenge Marks Pivotal Inflection Point for Cyber Defense in Critical Infrastructure, DARPA - https://www.darpa.mil/news/2025/aixcc-results
- AI Cyber Challenge, AIxCC 공식 사이트 - https://aicyberchallenge.com/
- Project Glasswing: Securing Critical Software for the AI Era, Anthropic - https://www.anthropic.com/project/glasswing
- Anthropic to Brief Global Financial Watchdog on Cyber Flaws Exposed by Mythos, FT Reports, Reuters - https://www.reuters.com/technology/anthropic-brief-financial-stability-board-cyber-flaws-exposed-by-mythos-ft-2026-05-18/
- Anthropic’s Mythos Sends US Banks Rushing to Plug Cyber Holes, Reuters - https://www.reuters.com/business/finance/anthropics-mythos-sends-us-banks-rushing-plug-cyber-holes-2026-05-12/
- GTIG AI Threat Tracker: Adversaries Leverage AI for Vulnerability Exploitation, Augmented Operations, and Initial Access, Google Threat Intelligence Group - https://cloud.google.com/blog/topics/threat-intelligence/ai-vulnerability-exploitation-initial-access

🔏 AI가 취약점을 찾자, 기업들은 검증에 돈을 쓰기 시작했다
Microsoft·OpenAI·Google·HackerOne·Bugcrowd 등 10개 기업이 보여주는 AI 시대 보안 대응의 방향
AI가 보안 업계에 들어오면서 가장 먼저 바뀐 것은 속도였다. 과거에는 보안 연구자가 직접 코드를 읽고, 취약한 흐름을 추적하고, PoC를 작성해야 했다. 이제는 AI가 코드베이스를 분석하고, 의심스러운 흐름을 설명하고, 때로는 패치까지 제안한다. 겉으로 보면 보안팀의 일이 줄어든 것처럼 보인다.
그러나 현장에서는 정반대의 문제가 나타나고 있다. AI가 취약점을 더 많이 찾아주는 만큼 사람이 확인해야 하는 오탐과 저품질 보고서도 함께 늘었다. 버그 바운티 플랫폼에는 AI가 작성한 그럴듯한 취약점 보고서가 쏟아지고 기업 내부에서는 직원들이 승인되지 않은 AI 도구에 소스코드와 민감정보를 넣는 일이 빈번해졌다. AI 에이전트가 업무 자동화에 투입되면서 누가, 어떤 권한으로, 어떤 데이터를 만졌는가를 추적하는 문제도 커지고 있다.
결국 글로벌 기업들의 대응은 한 방향으로 모이고 있다. AI를 막는 것이 아니라, AI가 만든 결과물을 다시 검증하고 통제하는 체계를 만드는 것이다. Microsoft, OpenAI, Google, Palo Alto Networks, GitHub, IBM, HackerOne, Bugcrowd, Cloudflare, Cisco 10개 기업의 최근 대응을 다섯 쌍으로 묶어 살펴보면 AI 시대 보안의 윤곽이 분명해진다.
🧩 Microsoft × OpenAI : 패치 파이프라인 안의 AI, AI를 검증하는 AI
Microsoft와 OpenAI는 모두 AI를 활용해 취약점을 찾고 있지만 무게중심은 사뭇 다르다.
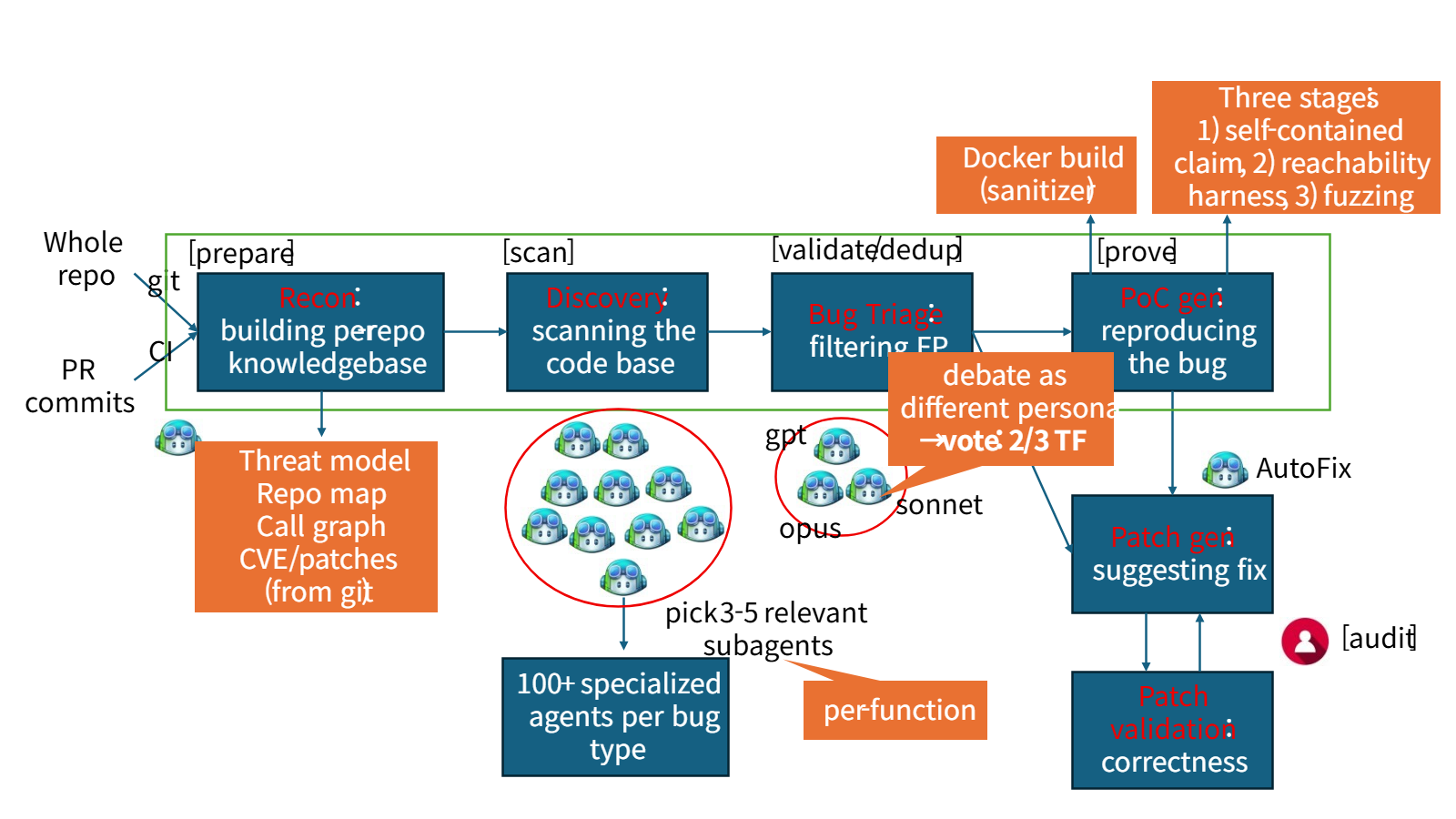
Microsoft는 2026년 5월 MDASH라는 다중 모델 기반 보안 시스템을 공개했다. 100개 이상의 전문 AI 에이전트가 Windows 네트워크·인증 스택을 분석해 16개의 신규 취약점을 찾아냈고, 이 결과는 곧바로 2026년 5월 Patch Tuesday에 반영됐다. Microsoft는 내부 테스트에서 21개의 심어진 취약점을 false positive 없이 모두 탐지했다고 설명했다. Microsoft의 핵심은 단순히 AI로 많이 찾는다가 아니다. AI가 찾은 결과를 실제 보안 패치 흐름 안으로 끌어들이고, 벤치마크와 내부 검증을 거쳐 신뢰도를 확보한다. 즉 AI를 독립적인 연구자가 아니라 패치 전 단계의 자동화된 탐지·검증 보조 시스템으로 배치한 것이다. 반면 OpenAI는 AI가 취약점을 찾았다는 주장 자체를 다시 검증하는 데 집중한다. Codex Security는 코드베이스를 읽고 위협 모델을 만든 뒤, 취약점 가능성을 찾으면 실제 exploitability를 확인하고 패치를 제안한다. OpenAI는 베타 과정에서 같은 저장소를 반복 스캔하며 노이즈를 최대 84% 줄였고, 과도하게 높게 평가된 심각도 비율을 90% 이상, false positive rate도 50% 이상 낮췄다고 밝혔다. 이 접근의 전신은 Aardvark다. Aardvark는 취약점을 찾은 뒤 sandbox 환경에서 실제 트리거를 시도해 exploitability를 확인하고, Codex와 연동해 패치를 제안하는 구조였다. Codex Security는 이 검증 파이프라인을 한 패키지로 묶어 노이즈를 줄이는 방향으로 발전한 셈이다. 두 기업을 나란히 놓으면 메시지가 분명해진다. Microsoft는 AI가 찾은 결과를 자사 제품의 패치 사이클에 직접 흘려보내고 OpenAI는 AI가 찾은 결과를 또 다른 AI로 검증해 도구 자체의 신뢰도를 끌어올린다. 검증의 위치가 다른 셈이다.
⚔️ Google × Palo Alto Networks : 공격자도 AI를 쓴다, 방어자는 더 빨라져야 한다
AI는 방어자만의 도구가 아니다. 공격자도 같은 무기를 쥐고 있다.
Google Threat Intelligence Group(GTIG)은 2026년 5월 보고서에서 공격자들이 AI를 취약점 악용, 초기 침투, 악성코드 운영에 활용하고 있다고 분석했다. 특히 2FA 우회 zero-day exploit의 발견과 무기화 과정에 AI가 사용된 것으로 추정되는 사례를 처음 확인했다는 점은 의미가 크다. GTIG는 해당 취약점이 실제로 대규모 악용 작전에 쓰이기 전에 벤더에 책임 공시(responsible disclosure)해 차단했다고 밝혔다. AI가 단순히 피싱 문구를 만들거나 악성코드를 보조하는 단계를 넘어 실제 취약점 악용 단계로 들어왔다는 뜻이기 때문이다.
동시에 Google은 방어 측에서도 AI를 적극 활용한다. Google DeepMind와 Project Zero가 만든 Big Sleep은 SQLite 취약점을 발견해 개발자에게 보고했고, Google은 위협 인텔리전스와 Big Sleep을 결합해 공격자가 악용하려던 SQLite 취약점을 선제적으로 차단했다고 밝혔다. 한쪽에서는 공격자의 AI 사용을 threat intelligence로 추적하고, 다른 한쪽에서는 AI 에이전트로 취약점을 먼저 찾는 양면 전략이다.
Palo Alto Networks도 비슷한 결을 보인다. Axios 보도와 Palo Alto Networks의 공식 설명에 따르면, 회사는 Anthropic의 Mythos Preview와 OpenAI의 GPT-5.5-Cyber 등 frontier AI 사이버 모델을 활용해 130개 이상 제품을 스캔했고 2026년 5월 보안 권고에서 26개 CVE에 해당하는 75개 이슈를 공개했다. Axios는 이를 평소 월간 발견량보다 7배 이상 많은 수치라고 보도했다. 이 비교는 Palo Alto가 제공한 자체 통계에 근거한 것으로, 외부 벤치마크와의 대조는 빠져 있다. 그럼에도 회사가 강조한 지점은 따로 있다. 이 결과가 AI 모델만으로 나오지 않았다는 것. 모델에 위협 인텔리전스와 운영 가드레일을 제공하는 AI scanning harness, 그리고 인간 보안 전문가의 검증이 함께 필요했다고 설명했다.
🧹 HackerOne × Bugcrowd : AI slop을 거르는 플랫폼, AI slop을 제재하는 플랫폼
버그 바운티 플랫폼에서는 AI의 부작용이 가장 직접적으로 드러난다. AI가 작성한 취약점 보고서는 겉으로는 전문적으로 보이지만, 실제로는 재현되지 않거나 영향도가 없는 경우가 많다. 이른바 AI slop 문제다.
HackerOne은 이 문제를 AI와 인간 트리아지를 결합하는 방식으로 풀고 있다. 신규 서비스인 H1 Validation은 기업이 AI로 발견된 취약점 폭증에 대응하고 실제 악용 가능한 위험에 집중할 수 있도록 돕는 것을 목표로 한다. Hai Triage는 숙련된 분석가와 agentic AI를 결합해 보고서를 검토·재현하고 심각도를 분류한 뒤 actionable issue만 고객에게 전달한다.
Bugcrowd는 더 직접적이다. 2026년 3월, 10건 이상의 연속 invalid report를 제출한 계정을 검토하고, 자동화·AI 생성 활동으로 충분한 검증 없이 보고서를 제출한 경우 30일 정지와 가이드를 제공할 수 있다고 밝혔다. invalid report가 누적된 계정에는 신원 확인을 요구할 수도 있다. 이후 Bugcrowd는 "Sloptimism is breaking any system built on human validation"이라는 글에서 2026년 3월 단 3주 동안 트리아지 큐가 334% 증가했고, 대부분이 얇은 증거와 템플릿형 보고서, 실제 검증이 없는 제출이었다고 공개했다. Bugcrowd의 해법은 플랫폼 규율이다. AI 사용 자체를 금지하지는 않지만, 검증 없는 대량 제출은 정책으로 막는다.
🧷 GitHub × IBM : 개발자 책상 위의 AI, 경영진 보고서 속의 AI
GitHub와 IBM은 기업 내부에서 AI가 어떻게 쓰이는지를 다룬다는 점에서 묶인다. 다만 관점은 정반대에 가깝다.
GitHub는 AI를 개발 워크플로우 안으로 적극 끌어들인다. Copilot Autofix는 CodeQL 기반 code scanning alert에 대해 AI가 수정안을 제안하도록 한다. 개발자가 취약한 코드를 발견했을 때 AI가 곧바로 패치 후보를 만들어주는 방식이다. 그러나 GitHub는 AI 제안이 항상 완전하거나 안전하다고 보장하지 않는다. 공식 문서는 Copilot Autofix의 한계를 명시하고, 사용자가 AI 제안을 검토해야 한다고 강조한다. AI가 제안한 패치가 새로운 취약점을 만들거나 일부만 고칠 수도 있기 때문이다. GitHub의 구조는 AI 자동 수정 + 정적 분석 + 사람의 코드 리뷰의 조합으로 정리된다.
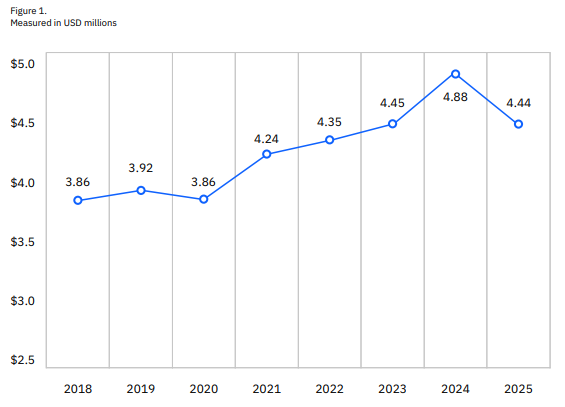
출처: 2025 Cost of a Data Breach Report
반대편의 IBM은 통제되지 않은 AI 사용을 데이터 침해 리스크로 본다. IBM의 2025 Cost of a Data Breach Report는 AI oversight gap을 주요 이슈로 다루며, 통제되지 않은 AI 시스템이 침해 가능성과 비용을 높일 수 있다고 분석한다. 동시에 AI 기반 방어를 적극 활용한 조직은 침해 식별과 containment 속도가 빨라졌고, 전 세계 평균 데이터 침해 비용은 전년 대비 9% 감소한 444만 달러로 나타났다고 밝혔다. 이 문제는 Netskope 보고서에서도 확인된다. 생성형 AI 관련 데이터 정책 위반은 전년 대비 두 배 이상 증가했고, 평균적인 조직은 매월 223건의 생성형 AI 관련 민감정보 전송 사고를 경험하며, 사용자 47%가 개인·비관리 계정으로 생성형 AI를 사용한다는 분석이다.
🌐 Cloudflare × Cisco : AI가 사람이 아닌 행위자로 움직이기 시작했다
Cloudflare와 Cisco는 AI를 사람이 쓰는 도구가 아니라, 인터넷과 네트워크 위에서 직접 움직이는 비인간 행위자로 본다는 공통점이 있다. 다만 통제 지점이 다르다.
Cloudflare는 외부에서 들어오는 AI 크롤러 문제에 집중한다. AI 기업들이 웹 콘텐츠를 학습 데이터로 가져가면서, 사이트 운영자들은 자신의 콘텐츠가 언제, 어떤 목적으로 수집되는지 통제하기 어려워졌다. Cloudflare의 Pay Per Crawl은 AI 크롤러에 대해 사이트 운영자가 Allow, Charge, Block 중 하나를 선택할 수 있게 한다. 허용하거나, 비용을 부과하거나, 아예 차단할 수 있는 구조다. AI 대응이 보안팀만의 문제가 아님을 보여주는 단면이다. AI가 만든 문제는 취약점 보고서뿐 아니라 데이터 수집, 콘텐츠 저작권, 크롤링 비용, 웹 비즈니스 모델까지 흔들고 있다.
Cisco는 내부 네트워크 안에서 움직이는 AI 에이전트에 초점을 둔다. 2026년 발표한 AI Defense 확장과 AI-aware SASE는 agentic AI 환경에서 기업 트래픽과 워크플로우를 보호하는 방향을 제시한다. AI 에이전트는 사람 대신 외부 도구와 데이터를 호출하고, 여러 SaaS와 API를 오가며 작업하기 때문에 기존 네트워크 보안처럼 단순히 사용자와 URL만 보는 방식으로는 부족하다. Cisco는 SASE를 통해 정책, 가시성, identity-aware protection을 제공해야 한다고 본다.
결론 : 더 많이 찾는 능력이 아니라, 진짜 위험을 판별하는 능력
10개 기업의 대응을 다시 보면, 표면적으로는 모두 다른 방향을 가리키는 듯하지만 결국 한 지점으로 수렴한다.
Microsoft와 OpenAI는 AI 탐지 결과를 다시 검증하는 체계를 만든다. Google과 Palo Alto Networks는 AI 공격에 AI 방어로 맞선다. HackerOne과 Bugcrowd는 AI 보고서의 노이즈를 걸러내고 제재한다. GitHub와 IBM은 AI를 업무에 들이되 책임 구조를 남긴다. Cloudflare와 Cisco는 AI가 사람이 아닌 행위자로 움직이는 길목을 통제한다.
공통점은 AI를 막지 않는 것에 있다. 다만 AI가 만든 결과를 다시 검증하고, AI 사용 경로를 통제하고, AI 에이전트의 권한을 관리한다. AI는 보안팀의 일을 없애지 않았다. 오히려 보안팀이 판단해야 할 결과물의 양을 늘렸다. 그래서 기업들은 무작정 AI를 도입하는 대신, AI를 둘러싼 검증·트리아지·거버넌스·접근통제 체계에 투자하고 있다.
AI 시대의 보안 경쟁력은 더 많은 취약점을 찾는 능력에서 나오지 않는다. 앞으로 중요한 것은 AI가 쏟아내는 수많은 결과물 중 무엇이 진짜 위험인지 판별하고, 실제 패치와 운영 체계로 연결하는 능력이다. 기업들이 AI를 막지 않으면서도 AI를 통제하려는 이유가 바로 여기에 있다.
[참고자료]
- "Defense at AI speed: Microsoft's new multi-model agentic security system finds 16 new vulnerabilities", Microsoft Security Blog - https://www.microsoft.com/en-us/security/blog/2026/05/12/defense-at-ai-speed-microsofts-new-multi-model-agentic-security-system-finds-16-new-vulnerabilities/
- "Codex Security, now in research preview", OpenAI - https://openai.com/ko-KR/index/codex-security-now-in-research-preview/
- "Introducing Aardvark: OpenAI's agentic security researcher", OpenAI - https://openai.com/index/introducing-aardvark/
- "GTIG AI Threat Tracker: Adversaries Leverage AI for Vulnerability Exploitation, Augmented Operations, and Initial Access", Google Cloud Blog (Google Threat Intelligence Group) - https://cloud.google.com/blog/topics/threat-intelligence/ai-vulnerability-exploitation-initial-access?hl=en
- "Cybersecurity updates: Summer 2025", Google Blog - https://blog.google/innovation-and-ai/technology/safety-security/cybersecurity-updates-summer-2025/
- "Palo Alto Networks says Mythos, GPT-5.5 found 75 bugs in weeks", Axios - https://www.axios.com/2026/05/13/palo-alto-networks-mythos-gpt-cybersecurity
- "Palo Alto Networks Unveils the Industry's Most Secure Browser Built for Agentic AI", Palo Alto Networks - https://www.paloaltonetworks.com/company/press/2026/palo-alto-networks-unveils-the-industry-s-most-secure-browser-built-for-agentic-ai
- "HackerOne Introduces H1 Validation to Help Enterprises Manage Surge in AI-Discovered Vulnerabilities", HackerOne - https://www.hackerone.com/press-release/hackerone-introduces-h1-validation-help-enterprises-manage-surge-ai-discovered
- "Bugcrowd Policy Changes to Address AI Slop Submissions", Bugcrowd - https://www.bugcrowd.com/blog/bugcrowd-policy-changes-to-address-ai-slop-submissions/
- "Responsible use of Copilot Autofix for code scanning", GitHub Docs - https://docs.github.com/en/code-security/responsible-use/responsible-use-autofix-code-scanning
- "Introducing Pay Per Crawl: enabling content owners to charge AI crawlers for access", Cloudflare Blog - https://blog.cloudflare.com/introducing-pay-per-crawl/
- "Cisco Redefines Security for the Agentic Era with AI Defense Expansion and AI-Aware SASE", Cisco Investor Relations - https://investor.cisco.com/news/news-details/2026/Cisco-Redefines-Security-for-the-Agentic-Era-with-AI-Defense-Expansion-and-AI-Aware-SASE/default.aspx

🎭 2026.03. 가명정보 처리 가이드라인 개정…활용 문턱은 낮추고, 위험관리 책임은 높였다

인공지능(AI) 확산으로 데이터 활용의 범위가 빠르게 넓어지면서 개인정보 보호제도도 전환점을 맞고 있다. 특히 AI 개발과 고도화에 필요한 학습데이터 수요가 커지면서, 개인정보를 직접 식별하지 않도록 처리한 ‘가명정보’가 데이터 활용과 보호의 핵심 쟁점으로 떠올랐다.
개인정보보호위원회가 2026년 3월 공개한 「가명정보 처리 가이드라인」 개정본은 이러한 변화에 대응한 실무 기준이다. 이번 개정의 핵심은 분명하다. 데이터 활용 절차는 줄이되, 위험도 판단과 재식별 방지 책임은 더 명확히 하겠다는 것이다.
‘일률 심사’에서 ‘위험도 기반’으로
가장 큰 변화는 가명정보 처리 체계가 위험도 기반으로 바뀐 점이다. 기존에는 기관이나 담당자에 따라 위험성 판단이 달라지고, 모든 사안에 과도한 서류와 심의를 적용하는 경우가 있었다.
개정 가이드라인은 이를 개선해 가명정보 활용 상황을 저위험·중위험·고위험으로 나누고, 위험 수준에 따라 검토 방식과 서류를 달리 적용하도록 했다. 내부 활용처럼 통제 가능성이 높은 경우에는 절차를 간소화하고, 제3자 제공이나 외부 결합처럼 재식별 가능성이 커지는 경우에는 더 엄격한 검토를 요구하는 방식이다.
이는 가명정보 제도가 단순한 비식별 처리에서 데이터 리스크 관리체계로 이동하고 있음을 보여준다.
서류는 줄었지만, 설명 책임은 커졌다
이번 개정은 실무 부담을 줄이기 위해 기존 24종에 달하던 서식을 10종으로 줄였다. 저위험 사안은 위원회 심의 없이 내부 담당자 검토만으로 처리할 수 있도록 했다.
하지만 이는 규제 완화만을 뜻하지 않는다. 오히려 기관과 기업은 자신들이 왜 해당 사안을 저위험·중위험·고위험으로 판단했는지, 어떤 가명처리와 보호조치를 적용했는지 설명할 수 있어야 한다.
보안 관점에서 중요한 것은 문서의 양이 아니라 판단의 근거와 통제의 실효성이다. 접근권한, 반출관리, 로그기록, 재식별 금지 조치, 보유기간 관리가 위험도 판단과 연결돼야 한다.
AI 개발 현실 반영…목적과 기간은 유연하게
AI 개발은 한 번의 분석으로 끝나지 않는다. 모델은 반복 학습과 성능 개선을 거치며, 초기 목적과 유사한 서비스로 확장되는 경우도 많다.
개정 가이드라인은 이런 특성을 반영해 유사한 범위 안에서 확장 가능한 목적을 사전에 설정할 수 있도록 했다. 또 AI 서비스 개발과 고도화에 필요한 기간 동안 가명정보를 활용할 수 있도록 처리기간 기준도 유연하게 개선했다.
다만 목적이 넓어진 만큼 관리 책임도 커진다. 목적 제한 원칙이 흐려지지 않도록 데이터 최소화, 접근통제, 재식별 위험평가, 이용 이력 관리가 함께 이뤄져야 한다.
비정형데이터, 새로운 재식별 위험
AI 학습데이터는 더 이상 표 형태의 정형데이터에 머물지 않는다. 이미지, 영상, 음성, 텍스트, 상담기록, 로그 등 비정형데이터 활용이 빠르게 늘고 있다.
비정형데이터는 가명처리가 어렵다. 영상에는 얼굴과 차량번호가, 음성에는 목소리 자체가, 텍스트에는 이름이 없어도 특정인을 추정할 수 있는 맥락 정보가 포함될 수 있다. 단순 삭제나 마스킹만으로는 충분하지 않은 이유다.
개정 가이드라인은 대규모 비정형데이터에 대해 표본검수 등 다양한 검수 방식을 허용했다. 이는 실무 효율을 높이는 조치지만, 표본 추출 기준과 오류 발견 시 대응 절차 등 내부 통제 기준이 뒷받침돼야 한다.
가명정보는 익명정보가 아니다
가명정보 활용에서 가장 중요한 쟁점은 재식별 가능성이다. 가명정보는 특정 개인을 바로 알아볼 수 없도록 처리한 정보지만, 익명정보와 달리 다른 데이터와 결합하면 개인이 다시 식별될 수 있다.
AI 환경에서는 이 위험이 더 복잡해진다. 대규모 데이터가 반복적으로 결합·분석되고, 모델이 학습 과정에서 특정 개인의 특징을 기억하거나 결과값으로 재현할 가능성도 있기 때문이다. 특히 의료, 금융, 교육, 통신, 공공데이터처럼 정보의 밀도와 결합 가치가 높은 분야에서는 이름이나 주민등록번호가 없어도 개인이 추정될 수 있다.
따라서 가명정보를 AI 학습에 활용할 때는 “식별자를 제거했는가”보다 “다른 정보와 결합됐을 때도 안전한가”를 따져야 한다. 데이터의 희소성, 민감도, 결합 가능성, 제공 대상, 처리 환경을 함께 고려하는 재식별 위험 평가가 핵심이다.
가명처리 넘어 데이터 거버넌스로
이번 개정은 산업계에 가명처리 이후의 관리 역량을 요구한다. 과거에는 개인정보를 마스킹하거나 암호화하는 기술적 조치가 중심이었다면, AI 시대에는 데이터가 어떤 목적으로 수집되고, 어디로 이동하며, 누가 접근하고, 언제 폐기되는지까지 관리하는 체계가 필요하다.
이에 따라 보안과 데이터 산업의 역할도 넓어지고 있다. 가명처리 자동화뿐 아니라 비정형데이터 위험평가, 데이터 반출통제, 안전한 데이터 결합, 접근권한 관리, 이용 이력 추적, 프라이버시 강화 기술 등이 함께 요구된다. 핵심은 데이터를 한 번 안전하게 처리하는 것이 아니라, 활용 과정 전체를 통제 가능한 상태로 유지하는 것이다.
특히 의료, 금융, 교육, 공공, 통신 분야에서는 가명정보 활용 전후의 보안 검증과 내부 거버넌스가 경쟁력이 될 가능성이 높다. 앞으로는 데이터를 많이 보유한 조직보다, 데이터를 목적에 맞게 안전하게 활용하고 그 과정을 입증할 수 있는 조직이 AI 데이터 활용에서 앞서게 될 것이다.
핵심은 ‘책임 있는 활용’
2026년 가명정보 처리 가이드라인 개정은 단순한 규제 완화가 아니다. AI 시대 데이터 활용을 현실화하되, 재식별 위험과 오남용 가능성을 더 정교하게 관리하라는 신호다.
가명정보는 개인정보를 지운 데이터가 아니다. 활용 목적, 처리 환경, 제공 대상, 보안조치, 사후관리까지 함께 설계된 데이터여야 한다.
AI 시대의 데이터 경쟁력은 얼마나 많은 데이터를 확보했는지가 아니라, 얼마나 안전하고 책임 있게 활용할 수 있는지에서 갈릴 것이다.
[참고자료]
- 개인정보보호위원회, ”가명정보 처리 가이드라인(2026.3. 개정)”, https://www.pipc.go.kr/np/cop/bbs/selectBoardArticle.do?bbsId=BS217&mCode=D010030000&nttId=11931
- 대한민국 정책 브리핑, “「가명정보 처리 가이드라인」 전면 개정, '위험도 기반' 판단 체계 확립”, https://www.korea.kr/briefing/pressReleaseView.do?newsId=156751967
- 법률신문, “가명정보 가이드라인 전면 개정: '위험도 기반' 체계로 전환, 기업 데이터 활용 프로젝트의 설계가 바뀐다”, https://www.lawtimes.co.kr/news/articleView.html?idxno=218765

🎥 내 데이터가 AI를 만든다: AI 학습 데이터와 개인정보

내 데이터가 AI를 만든다: AI 학습 데이터와 개인정보
AI 모델은 공짜로 똑똑해지지 않는다. 방대한 데이터를 학습해야 하고, 그 데이터의 상당 부분은 인터넷에 공개된 텍스트, 이미지, 영상에서 온다. 문제는 그 안에 개인의 이름, 사진, 연락처, 게시물이 포함되어 있다는 점이다. AI가 학습하는 순간, 우리의 개인정보는 모델의 파라미터 어딘가에 녹아든다.
생성형 AI 모델의 학습 파이프라인은 크게 데이터 수집 → 전처리(토큰화 등) → 학습 → 서비스 단계로 구성된다. 각 단계에서 개인정보 처리가 수반된다. AI 학습 단계에서는 공개된 개인정보를 포함한 학습 데이터의 수집, 저장, 가공이 이루어지며, AI 서비스 단계에서는 이용자가 개인정보가 담긴 프롬프트를 입력하면 해당 내용이 다시 AI 학습 목적으로 활용될 수 있다. 즉, AI를 쓰는 행위 자체가 다음 세대 AI의 학습 데이터가 될 수 있는 구조다.
크롤링·스크래핑: '공개된 정보'는 가져가도 되는가
AI 기업들은 웹 크롤링과 스크래핑을 통해 학습 데이터를 확보해왔다. 검색 엔진이 웹페이지를 색인하듯, AI 봇이 인터넷 전반을 긁어가는 방식이다. 여기서 핵심 쟁점은 '공개된 정보'가 곧 '자유롭게 사용 가능한 정보'를 의미하는가 하는 문제다.
웹사이트 운영자들은 robots.txt 파일을 통해 크롤링을 거부할 수 있다. 그러나 이는 법적 구속력 없는 자발적 준수 사항에 불과하며, OpenAI와 Anthropic 등이 이를 어겼다는 사실은 이미 보도된 바 있다. '침입 금지' 표지판을 세워뒀어도 물리적 장벽이 없으면 막을 수 없는 구조다. AI 학습을 위한 크롤링·스크래핑은 저작권 문제에 그치지 않고 형사법적 쟁점, 라이선스 위반 등 다양한 법적 쟁점을 수반한다.
Getty Images vs. Stability AI: 법정에서 가려진 것과 가려지지 않은 것
AI 학습 데이터를 둘러싼 법적 공방 중 가장 주목받은 사건은 Getty Images와 Stability AI 간의 소송이다. Getty Images는 자사가 보유한 수백만 장의 사진이 허가 없이 Stable Diffusion 모델 학습에 사용됐다고 주장하며 저작권 침해, 상표권 침해, 데이터베이스권 침해 등 복합적인 청구를 제기했다. 2025년 11월 4일 영국 고등법원은 Getty의 주요 저작권 침해 청구를 기각하고, 상표권 침해에 대해서만 제한적인 인정 판결을 내렸다. 창작 업계 입장에서는 실망스러운 결과였지만, 이 판결은 AI 개발과 권리자 보호를 동시에 지원할 현대적 입법 체계의 필요성을 명확히 드러냈다는 점에서 의미가 있다. 법원 스스로 현행 저작권 체계가 AI 시대에 충분하지 않다고 시사한 셈이다.
'잊힐 권리', AI 앞에서 무력화되다
개인정보보호법의 핵심 권리 중 하나는 '잊힐 권리(Right to be Forgotten)'다. 자신의 정보를 삭제해달라고 요청할 수 있는 권리인데, AI 시대에는 이 권리의 실효성에 근본적인 의문이 제기된다. 데이터셋에서 특정 개인정보를 삭제하더라도, 그 데이터로 이미 학습된 모델의 파라미터에서는 해당 정보의 흔적이 남아있기 때문이다.
기술적 해법으로 주목받는 것이 '머신 언러닝(Machine Unlearning)'이다. 머신 언러닝은 AI 모델이 학습한 데이터 중 특정 정보만을 선택적으로 제거해 잊힐 권리를 실질적으로 구현하는 기술로, 유럽과 미국의 개인정보 보호 법률 강화와 함께 빠르게 주목받고 있다. 그러나 사용자가 데이터 삭제를 요청하면 기존 방식으로는 해당 데이터를 제외하고 전체 모델을 막대한 비용을 들여 처음부터 재학습시켜야 했으며, 머신 언러닝은 특정 데이터의 영향만 효율적으로 제거하는 것을 목표로 하지만 현재 완벽한 방법은 없고 연구가 활발히 진행 중이다.
AI 알고리즘에서 데이터를 삭제하는 방식에는 머신 언러닝과 처음부터 재학습하는 방법이 있는데, 잊힐 권리의 현실적 대안으로 '학습거부권(옵트아웃)'이 새로운 정보주체 권리로 부상하고 있다. 학습에 쓰이기 전에 동의를 받는 것이 사후 삭제보다 현실적이라는 인식이 확산되고 있는 것이다.
공개된 것이 곧 동의된 것은 아니다
이번 호에서 살펴본 쟁점들은 하나의 명제로 수렴한다. 인터넷에 공개된 정보라고 해서 AI 학습에 무제한으로 활용될 수 있는 것은 아니라는 것이다. 개인정보보호위원회는 AI 사업자가 크롤링·스크래핑 등을 통해 공개된 개인정보를 활용하는 구조와 방식이 안내서에서 제시하는 기준에 부합하는지 지속적으로 확인해야 한다고 권고하고 있다. 법과 기술, 그리고 윤리의 공백을 메우는 논의가 지금 이 순간에도 진행 중이다. 다음 호에서는 각국 정부가 이 공백에 어떻게 대응하고 있는지, 규제의 현황과 한계를 짚어본다.
[참고자료]
- 개인정보보호위원회, 「AI 개발·서비스를 위한 공개된 개인정보 처리 안내서」 (2024.7.) https://www.privacy.go.kr/front/bbs/bbsView.do?bbsNo=BBSMSTR_000000000049&bbscttNo=20731
- AI타임스, 「AI 학습 데이터 고갈되나…웹 사이트 '크롤링 차단' 급증」 (2024.7.) https://www.aitimes.com/news/articleView.html?idxno=161784
- Lexology, 「미국 법원의 스크래핑, 크롤링, 데이터 이용 관련 판결 동향」 (2024.8.) https://www.lexology.com/library/detail.aspx?g=a54c09d8-c40d-4d60-afaa-bcbd26c8ee30
- AI매터스, 「개인정보 삭제 요청하면 AI가 '진짜' 잊는다…'머신 언러닝' 기술 급부상」 (2025.12.) https://aimatters.co.kr/news-report/ai-report/35591/
- 보안뉴스, 「AI 시대 잊혀질 권리 지키는 '머신언러닝'…학계 연구 활발」 (2025.10.) https://m.boannews.com/html/detail.html?idx=140059
- Bird & Bird, 「Getty Images v Stability AI 판결」 (2025.11.) https://www.twobirds.com/en/insights/2025/uk/stability-ai-defeats-getty-images-copyright-claims-in-first-of-its-kind-dispute-before-the-high-cour

🎉 뉴스레터를 읽고 풀어보는 재미있는 퀴즈! 🎉
아래 객관식 퀴즈의 정답을 구글폼에 입력하시면 추첨을 통해 스타벅스 기프티콘을 드립니다~!!
정답을 확인하려면 기사를 읽어야 합니다! 😄 많은 참여 부탁드려요😍😍
구글폼 바로가기 ♥ (https://forms.gle/vzZu82HTQxJDTD5CA)
1. 2023년 발생한 삼성전자의 기밀 유출 사건 이후 국내 주요 기업들이 생성형 AI 사용 정책을 강화하게 되었습니다. 다음 중 '우리 뉴스레터에서 소개된' 당시 임직원들의 ChatGPT 오용 사례(기밀 유출 행위)가 아닌 것은 무엇인가요? - 4월호
- 반도체 설비 계측 데이터를 ChatGPT에 입력하여 코드 오류 수정을 요청함
- 내부 핵심 기술 노하우가 담긴 소스 코드를 경쟁사에 오픈소스로 무단 배포함
- 수율(불량률)과 관련된 민감한 생산 데이터를 입력하여 최적화 방안을 문의함
- 임원이 참석한 사내 내부 회의 녹음 파일을 요약하기 위해 ChatGPT에 업로드함
2. 2023년 3월 OpenAI가 발표한 ChatGPT 개인정보 유출 사고의 기술적 원인이 되었던 오픈소스 기반 캐시 솔루션의 이름은 무엇인가요? - 4월호
- Memcached
- MongoDB
- Redis
- Apache Cassandra
3. Stanford HAI가 발간한 'Artificial Intelligence Index Report 2026'에 서술된 내용 중, 첨단 AI 칩 제조 생태계가 사실상 전 세계에서 유일하게 집중되어 있어 글로벌 AI 체계의 구조적 취약점(병목 지점)으로 지목된 기업은 어디인가요? - 4월호
- Intel
- TSMC
- Samsung Electronics
- NVIDIA
4. 정보보안 분야에서 글로벌 스탠다드로 널리 활용되는 국제 표준인 'ISO/IEC 27001'의 모태가 된 영국의 국가 표준 규격 번호는 무엇인가요? - 5월호
- BS 7799
- BS 8848
- UK-ITSEC
- NCSC-Framework
5. 최근 주요 운영체제, 웹브라우저 등에서 수천 개의 zero-day 취약점을 식별해 내며 방어자와 공격자 모두에게 큰 논란과 화두를 던진 Anthropic의 최신 AI 모델 Preview 명칭은 무엇인가요?
- Claude Glasswing
- Claude Mythos (미토스)
- WormGPT
- Google Big Sleep
6. 다음 중 뉴스레터 본문에서 설명한 'AI가 사이버 보안 및 공격 영역에 미치는 영향'과 가장 거리가 먼 것은 무엇인가요?
- AI는 공격 자체를 완전히 대행하므로 해킹 과정에서 인간 해커의 개입을 완벽히 배제시킨다.
- 방어자와 공격자 모두가 취약점을 더 빠르게 찾기 위해 AI를 활용하는 속도전의 시대에 진입했다.
- WormGPT나 FraudGPT의 등장으로 생성형 AI가 사이버 범죄 시장의 상품으로 유통되고 있다.
- 안전성을 높이기 위한 정렬 조치가 모델의 정확도를 떨어뜨리는 등 책임 있는 AI 요소 간 충돌이 발생하기도 한다.
E D I T O R




🚨 BoB 가족들의 소중한 소식을 기다리고 있습니다. 🚨
함께 공유하고 싶은 소식, 수상 내역, 행사기타 소소한 일상까지 구독자분들의 공유를 기다립니다.
- 함께 만들어가는 BoB 뉴스레터 -
서울특별시 금천구 서부샛길 606 가산 대성디폴리스 A동 27층
의견을 남겨주세요