
CDFi 2기 1번째 세션 <1>
- hosted by 장희수 교수님(숭실대 금융학부)
- 월스트리트 디파이의 세미나 내용은 유튜브에서 영상으로도 보실 수 있습니다.

- Re-imaging Price Trends
- CNN Model
- CNN 작동 원리
- CNN을 통한 차트 학습
- CNN 모델 성능 분석
1. Re-imaging Price Trends

“Re-imaging Price Trends”는 2023년 12월에 발표된 논문으로, 머신러닝을 시장 분석에 적용한 첫 번째 논문으로 자리매김합니다. 전통적인 파이낸스 방법론 대신, 산업 공학 분야에서 흔히 다뤄졌던 기계 학습을 통해 가격 예측의 효과를 다양한 관점에서 평가한 연구입니다. 이 논문은 특히 CNN 모델을 중심으로 가격 예측의 성능이 뛰어나다는 점을 강조하며, 모델의 유연성과 해석 가능성에 중점을 두고 있습니다.
기계 학습 기반의 가격 예측 모델은 두 가지 중요한 특성을 갖춰야 합니다. 첫째, 복잡한 예측 패턴을 찾아낼 수 있을 만큼 유연해야 하며, 둘째, 그 예측 결과를 해석할 수 있어야 합니다. 기존에는 성능이 뛰어난 머신러닝 모델을 제시하더라도 그 결과를 해석하는 데 어려움이 있었으나, 이 논문에서는 그 문제를 해결하고, 발견된 패턴을 금융 이론 발전에 기여할 수 있는 방향으로 연결시켰습니다.
논문의 구조는 간단합니다. 차트 데이터를 이미지로 변환하여 CNN 모델에 입력하고, 학습된 결과로 포트폴리오를 생성합니다. 그런 후, 기존의 벤치마크 포트폴리오와 비교하여 성능이 우수함을 샤프 비율 등의 지표로 입증합니다.
2. CNN Model
1) 입력 데이터

이 연구에서는 차트 데이터를 이미지로 변환하여 입력 데이터로 사용합니다. 입력 데이터는 세 가지 기간의 가격 정보를 기반으로 하며, 각각의 사이즈는 다음과 같습니다: 첫째, 이전 일주일(5일) 데이터, 둘째, 이전 한 달(20일) 데이터, 셋째, 이전 분기(60일) 데이터입니다. 이 데이터들은 각각 5일, 20일, 60일 크기의 이미지로 변환되어 CNN 모델에 입력됩니다.
이미지는 트레이딩 볼륨을 포함하며, 볼륨 파가 표시되고 그 위에 무빙 에버리지가 그려집니다. 각 데이터 포인트는 하루의 가격을 나타내며, 이 데이터에서 가장 높은 값은 고가, 가장 낮은 값은 저가를 나타냅니다. 차트의 왼쪽과 오른쪽 픽셀은 시가와 종가를 나타내며, 여기서 왼쪽 픽셀은 전날의 종가, 오른쪽 픽셀은 그다음 날의 시가를 나타냅니다. 만약 전날 종가와 그다음 날 시가가 동일하면 하나로 연결되어 표시됩니다. 이렇게 변환된 차트 이미지를 CNN 모델에 입력하여 학습시키는 방식입니다.
2) CNN vs 전통적 방법론

전통적인 방법론에서는 Feature Extraction을 사람이 직접 설정해야 했습니다. 예를 들어, 모멘텀 전략을 사용할 때는 “어제 성능이 좋았던 종목들이 내일도 성능이 좋을 것”이라는 가정을 바탕으로 시작합니다. 반면, CNN은 사람이 별도로 설정할 필요 없이 차트를 보고 자동으로 의미 있는 패턴을 추출할 수 있다는 점이 장점입니다. CNN은 노이즈를 줄이고, 미래 수익률과 높은 상관관계를 가진 패턴을 찾아낼 수 있습니다.
CNN에서는 원본 픽셀 값을 비선형 변환하여 예측 변수 집합을 생성하는데, 이는 전통적인 방법에서도 사용되는 방식입니다. 가격 데이터는 시계열로 나오지만, 이 데이터를 다른 차원으로 변환하여 분석하는 방식입니다. 예를 들어, 머신러닝에서 강아지와 고양이 사진을 구별할 때, 각 사진을 다른 차원으로 변환하고, 그 차원에서 강아지 사진들은 서로 모이고 고양이 사진들은 다른 그룹으로 클러스터링됩니다. 이를 통해 비선형 변환이 이루어지고, 머신러닝은 강아지와 고양이를 구분하는 패턴을 학습합니다.
전통적인 시장 분석에서도 비슷한 방식이 사용되었으며, 이를 커널 함수로 불렀습니다. 커널 함수를 통해 비선형 변환이 이루어졌고, 그 과정에서 정규 분포나 가우시안 프로세스와 같은 고정된 커널 함수가 사용되었습니다. 그러나 CNN은 고정된 커널 함수를 사용하지 않고, 학습을 통해 필터를 자동으로 찾아냅니다. 이렇게 함으로써 사람이 설정하기 어려운 패턴을 효과적으로 발견할 수 있게 되며, 이는 이 논문이 주장하는 핵심입니다.
3) CNN 특징

이미지 분석을 위해 설계된 CNN 모델은 이미지 형식으로 입력 데이터를 생성한다는 점에서, 시계열 분석에서의 전통적인 방식과 차별화됩니다. 전통적인 시계열 분석에서는 각 시점마다 데이터 포인트가 독립적으로 존재하며, 예를 들어 t-2 시점, t-1 시점, t 시점의 데이터가 각각 독립적인 포인트로 구분됩니다. 하지만 CNN을 사용하여 데이터를 이미지 형식으로 변환하면, 시간 흐름에 따른 다양한 패턴을 직관적으로 인식할 수 있다고 가정합니다.
이미지 형식으로 변환된 데이터는 주가의 시간에 따른 변화를 패턴으로 인식하게 됩니다. 예를 들어, 주식 가격이 점차 하락하는 패턴을 CNN이 인식할 수 있으며, 이러한 변화를 “shape”으로 이해하는 방식입니다. 이는 CNN이 시간 흐름에 따라 발생하는 다양한 패턴을 효과적으로 파악할 수 있도록 해줍니다.
3. CNN 작동 원리
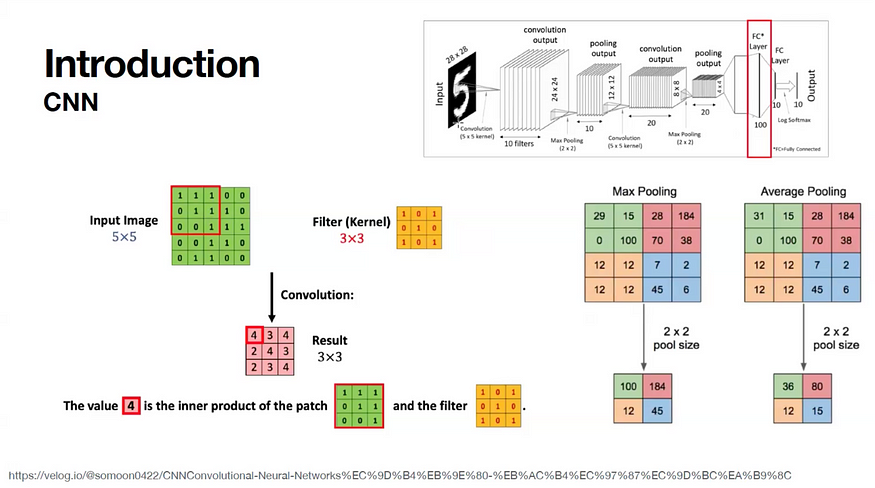
CNN 모델의 대표적인 예시는 사람들이 쓴 숫자 데이터입니다. 예를 들어, 0부터 9까지의 숫자는 각기 다른 방식으로 작성되며, 이를 학습시켜 새로운 이미지가 들어왔을 때 해당 숫자가 무엇인지를 구별할 수 있도록 학습합니다. CNN 모델은 이렇게 숫자를 구별하는 데 사용됩니다.
1) Convoltion Layer
CNN 모델은 여러 번의 Convolution Layer와 Pooling Layer를 번갈아 가며 적용합니다. 예시에서는 10개의 convolution 뒤에 10개의 Pooling Layer가 존재합니다. 이 과정은 여러 번 반복될 수 있으며 자유롭게 배치가 가능합니다. 각 레이어는 이미지에서 의미 있는 특징을 추출하는 데 도움을 줍니다.
첫 번째로, Convolution은 CNN의 중요한 특징 중 하나입니다. CNN 모델이 가지는 의의는, 필터를 사용하여 Convolution Layer를 만드는데 있다고 생각하면 됩니다. 입력 이미지는 5x5 크기의 픽셀로 쪼개지며, 각 픽셀의 값은 0(검정) 또는 1(흰색)으로 표시됩니다. 예를 들어, 숫자 ‘5’를 나타낼 때는 검정색(0)과 흰색(1)으로 픽셀을 구성합니다.
그러면 그 위에 3x3 크기의 Filter를 적용합니다. CNN에서 우리가 Filter라고 부르는 게 어떻게 보면 다른 차원으로 변환하는 커널의 역할을 해준다고 생각하시면 됩니다. 예시에서 Filter를 적용하면, 5x5의 Convolution Layer와 3x3 Filter의 내적을 계산하고 이를 다시 합쳐 새로운 컨볼루션 레이어가 생성됩니다.
이러한 Convolution 연산은 필터가 한 칸씩 이동하는 방식으로 진행됩니다. 이동하는 간격을 Stride라고 부르며, 보통 한 칸씩 이동하는 경우가 많습니다. 필터는 이미지에서 겹치는 부분들을 처리하면서 다양한 패턴을 추출해내고, 결과적으로 3x3 크기의 Convolution Layer를 생성합니다.
2) Pooling Layer
다음으로 Pooling은 Convolution 후 이미지를 축소하는 작업입니다. 예를 들어 2x2 Max Pooling을 사용하면, 각 2x2 영역에서 가장 큰 값을 선택하여 이미지 크기를 줄입니다. Max Pooling은 가장 큰 값을 선택하는 방식이며, Average Pooling은 각 영역의 평균값을 계산합니다. 이 작업을 통해 특징 맵에서 중요한 부분만 남기게 되어 계산량을 줄이고 중요한 정보는 유지하게 됩니다.
3) Fully-Connected Layer (FC Layer)
CNN 모델의 마지막 단계는 완전 연결층, Fully Connected layer으로, 이는 풀 커넥티드 레이어라고도 불립니다. 이 레이어는 결과를 도출하는 최종 단계로, 앞서 추출된 특징들을 바탕으로 최종 예측을 수행합니다. FC 레이어에서는 모든 뉴런이 서로 연결되어 있으며, 이 단계에서 10개의 출력값으로 줄어들게 됩니다. 마지막으로 함수가 묶여서 결과를 도출하게 됩니다. 이 과정에서 모델이 최종 예측 결과를 출력하게 되며, CNN의 기본적인 구조가 완성됩니다.
이러한 CNN 모델이 유명해진 이유는 필터를 사용하는 개념입니다. 필터를 사용함으로써 이미지를 처리하는 동안 특정 부분을 강조하고, 중요한 특징을 추출할 수 있기 때문입니다. 예를 들어, 강아지의 코나 자전거의 바퀴처럼 이미지를 처리하면서 중요한 부분을 학습하고 강조할 수 있습니다. 이 방식은 이미지에서 중요한 특성을 자동으로 추출하여 인식하는 데 매우 효과적입니다.
4) Softmax
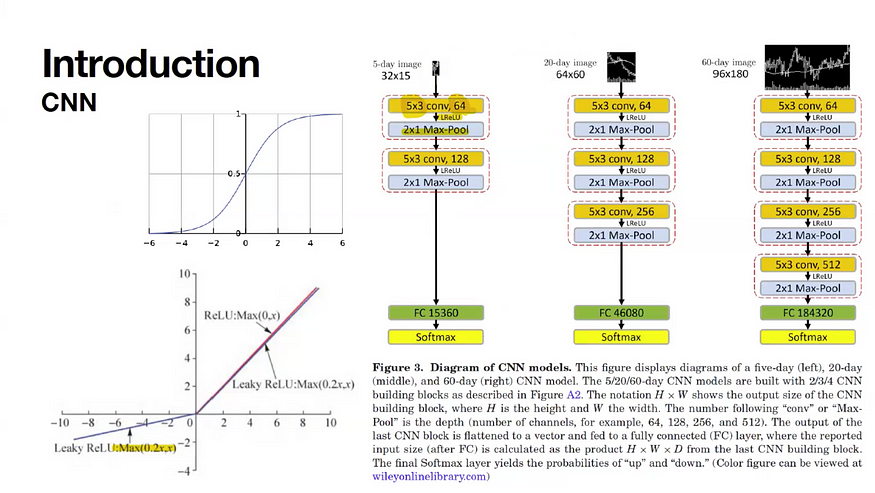
이와 같은 방식은 차트 분석에도 동일하게 적용됩니다. 차트를 분석할 때, CNN은 차트의 특정 부분을 강조하여 오를 차트와 내릴 차트를 구별할 수 있는 중요한 부분을 자동으로 인식하고 학습합니다. 차트에서 어디를 강조해야 할지를 집중적으로 학습하여, 해당 정보만을 잘 활용할 수 있도록 돕습니다.
구체적인 CNN 구조는 다음과 같습니다. 첫 번째로, 5일 데이터는 32x15 크기의 이미지로 변환됩니다. 그 후 5x3 크기의 필터를 64개 사용하여 특징을 추출하고, 이를 통해 64개의 결과를 생성합니다. 이후, 2x1 크기의 맥스 풀링을 적용하여 이미지를 축소하고, 각 영역에서 가장 큰 값을 선택하여 차원 축소를 합니다. 이 풀링 과정은 이미지에서 중요한 부분을 강조하는 역할을 합니다.
엘루(ELU)와 같은 활성화 함수가 사용되어, 양수 값은 그대로 유지하고 음수 값은 20%로 줄여서 출력합니다. 이 과정은 성능 향상에 기여하며, 모델이 더 효율적으로 학습할 수 있도록 합니다. 또한, 이전 데이터에서 5일, 20일, 60일 이미지가 각각 변환되며, 점점 더 복잡한 구조를 사용하여 정확한 예측을 위해 학습이 진행됩니다.
CNN 모델의 출력은 주식 가격이 오를 확률을 나타내는 확률 값입니다. 예를 들어, 출력 값이 0.6이라면 이는 “내일 이 주식이 오를 확률이 60%“라고 해석할 수 있습니다. 출력 값은 0과 1 사이의 확률로 나타나야 하므로, CNN의 마지막 단계에서 Softmax 함수를 적용합니다.
소프트맥스 함수는 어떤 실수 값이든 0과 1 사이로 변환할 수 있게 해줍니다. 이는 모델이 계산한 출력값이 확률 값으로 해석될 수 있도록 보장하는 역할을 합니다. 예를 들어, 실수 값이 1.5라면 소프트맥스 함수는 이 값을 0과 1 사이의 값으로 조정하여 출력합니다. 이 방식으로 CNN 모델은 차트 데이터를 학습하여, 오를 차트에 대해 높은 확률(예: 0.8, 0.7 등)을 예측하고, 내릴 차트에 대해서는 낮은 확률(예: 0.1, 0.2 등)을 예측할 수 있습니다.
따라서 CNN 모델의 최종 출력은 0에서 1 사이의 확률 값으로, 주어진 차트에 대해 주식이 오를 확률을 예측하게 됩니다. 이를 통해 모델은 주식 가격의 변동을 예측하고, 차트가 오를지 내릴지에 대한 확률적 예측을 할 수 있게 됩니다.
4. CNN을 통한 차트 학습
1) Evaluation

모델 학습에는 1993년부터 2000년까지의 차트 데이터를 사용합니다. 이 데이터를 트레이닝 데이터와 밸리데이션 데이터로 나누어 사용하며, 7:3 비율로 랜덤하게 분할합니다. 즉, 17년 간의 데이터 중 70%는 학습에 사용하고, 나머지 30%는 밸리데이션 데이터로 사용됩니다. 이때 시간에 따른 순서는 고려하지 않고, 랜덤으로 데이터를 뽑은 방식으로 학습을 진행합니다.
해당 연구에서는 미국 시장을 학습한 모델을 바탕으로 한국 시장에도 적용하는 실험을 했습니다. 결론만 전달 드리자면, 소규모 시장에서는 잘 작동하지만, 대규모 시장에서는 해당 시장 데이터로 학습하는 것이 더 효과적이라고 결론을 내렸습니다. 또한, 두 가지 방법을 앙상블하여 사용하는 것이 더 나은 성과를 낸다는 결론도 확인할 수 있었습니다.
2) 수익률 표기

Return(수익률)은 시계열 데이터로 2D 형태로 계산됩니다. 예를 들어, 리턴 값이 1에서 1.04로 증가했다면, 이는 4% 상승을 의미합니다. 이와 같은 수익률 데이터를 2D로 표현하여 차트에 반영합니다. 이 표현에서는 각 변화가 일정 크기만큼 상승하는 것을 나타내며, 1% 상승은 한 칸을, 10% 상승은 10칸을 이동하는 방식으로 시각화합니다. 이 방식은 변화를 직관적으로 보여줍니다.
예시 사진에서 t2는 t1에 비해 10% 미만의 상승이 일어나서 같은 줄에 있습니다. 반면, t3는 10% 상승이 일어나서 1줄 위에 있는 것을 볼 수 있습니다.
모델은 filter를 적용하여 차트에서 가격 변화의 패턴을 학습하는데, 이렇게 2D로 변환시킨 데이터에 filter를 적용시킵니다. 필터는 64개가 사용되며, 각 필터는 가격 변화 유형을 반영합니다. 예를 들어, “No Change”는 가격 변화가 없음을 나타내며, “Slight Increase”와 “Large Increase”, “Decrease” 등을 표현하는 필터도 포함됩니다. 이러한 필터는 가격 변화가 있는 부분을 강조하고, 차트 상에서 복잡한 패턴을 학습하도록 도와줍니다.
이 필터들은 차트에 적용되어 가격 변화가 겹치는 부분을 추출합니다. 예를 들어, “No Change” 필터는 가격 변화가 없는 구간에서는 0을 반환하고, 가격 변화가 있는 부분에서는 값을 출력합니다. 이런 방식으로 각 필터가 가격의 오르내림 패턴을 학습하게 됩니다.
5. CNN 모델 성능 분석
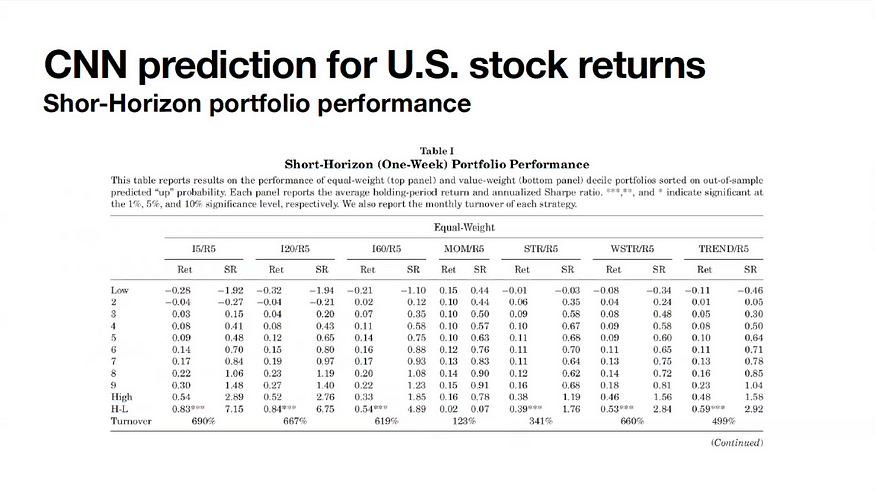
다른 모델들과 비교했을 때, 1주일 뒤를 예측하는 모델의 포트폴리오 성과를 보여주는 도표입니다. CNN 모델의 예측 값은 왼쪽 Decile Low부터 High까지 10분위로 다시 나뉩니다. 주가가 오를 확률이 가장 낮다고 예측되는 애들부터부터 10, 20%씩 자른 것입니다. 각 그룹의 Return(수익률)을 확인했을 때, 예측이 낮은 값(가격 상승 확률이 낮다고 예측된 종목들)은 음수의 리턴을 보였고, 높은 값(가격 상승 확률이 높은 종목들)은 리턴이 증가하는 경향을 보였습니다.
따라서 이 모델은 매수/공매도 전략을 활용하여, High 그룹을 매수하고 Low 그룹을 공매도 하였습니다. 이 전략의 리턴값은 0.83으로 다른 전략들보다 더 높은 성과를 기록했습니다. 또한, 샤프 비율이 다른 전략들에 비해 상당히 높은 성과를 보였습니다. 그리고 단기 모델, 즉 1주일을 예측하는 모델이 더 정확도가 높았습니다.
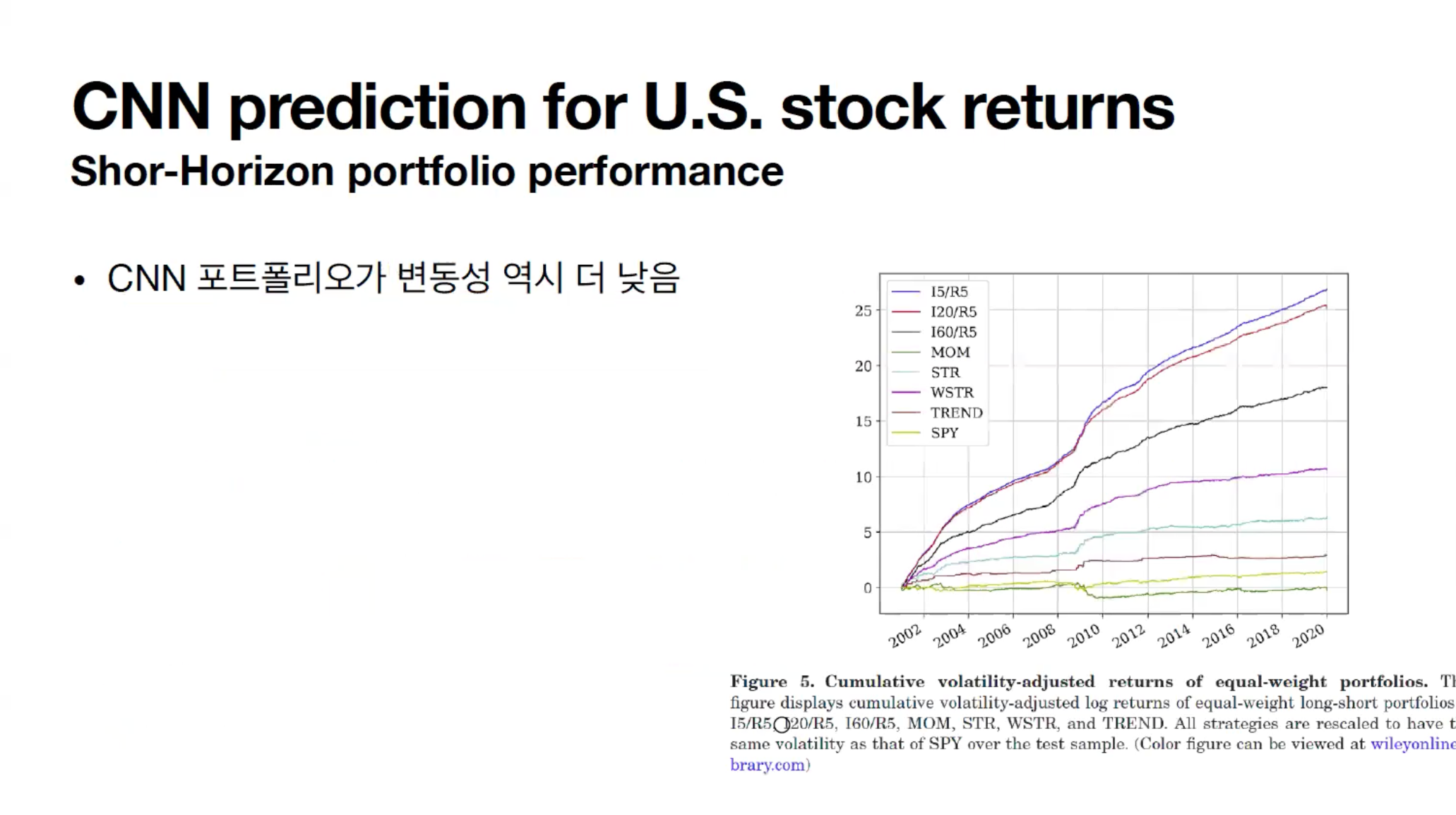
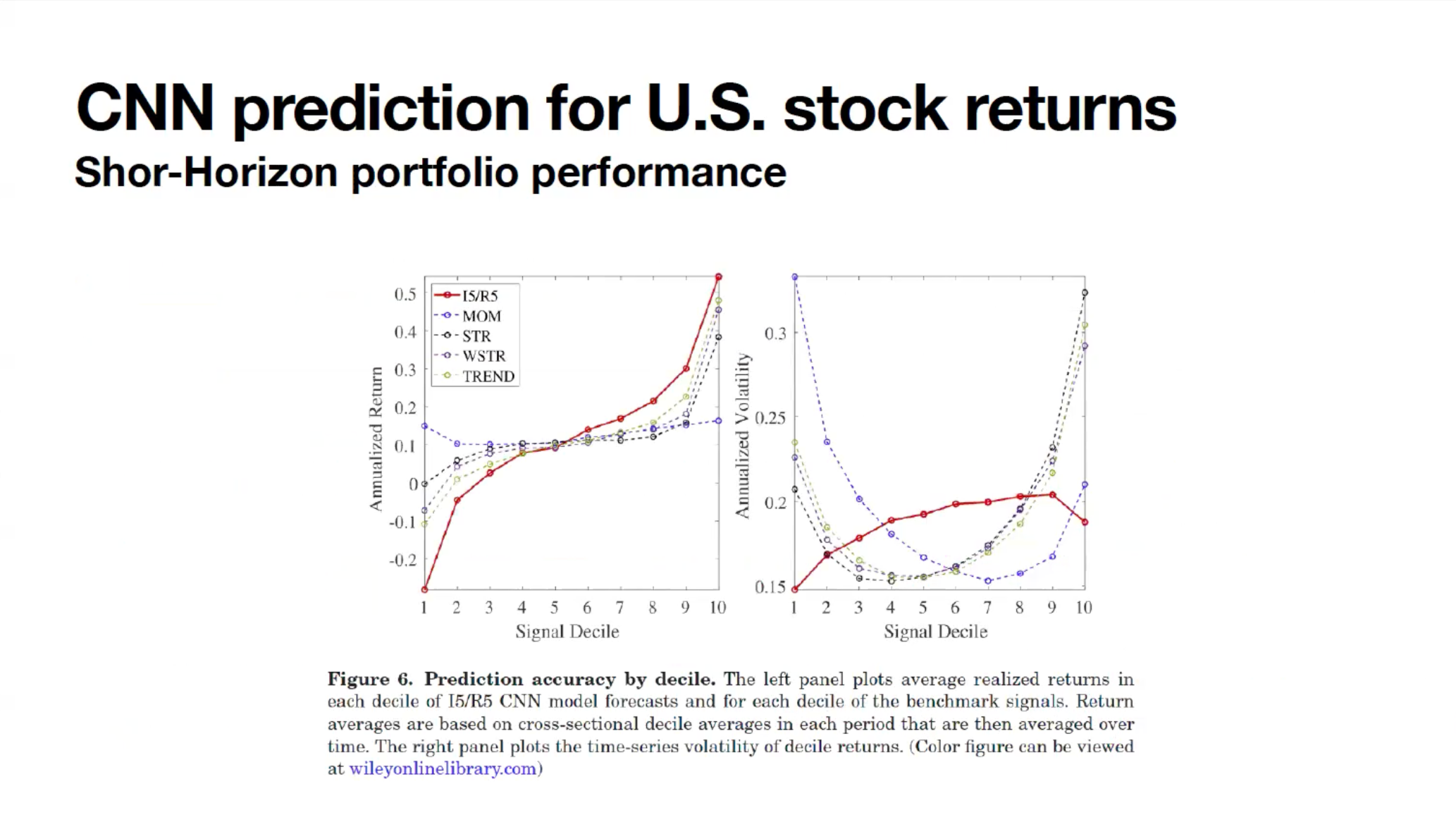
CNN 모델의 변동성 역시 낮은 것을 관찰할 수 있었습니다. 특이한 점은 Volatility Graph가 다른 전략과 반대로 찍힌다는 것입니다. 기본적으로, 수익률이 낮을 것 같은 낮은 Decile과 수익률이 높을 것 같은 높은 Decile에서는 기대값이 극단으로 가게 됩니다. 근데 CNN 모델에서는 Decile 양극단으로 갈수록 오히려 변동성이 작아지는 것을 볼 수 있습니다.


한달 이후, 한분기 이후 예측하는 것도 다 가능합니다. 대신 예측하는 기간이 길어질 수록 샤프 비율도 낮아지는 것을 확인할 수 있습니다. Momentum 전략에 비해 턴오버율이 높지만, Momentum 전략 뿐만 아닌 모든 전략에 비해 높은 샤프 비율, 즉 좋은 성과를 보여준다고 합니다.
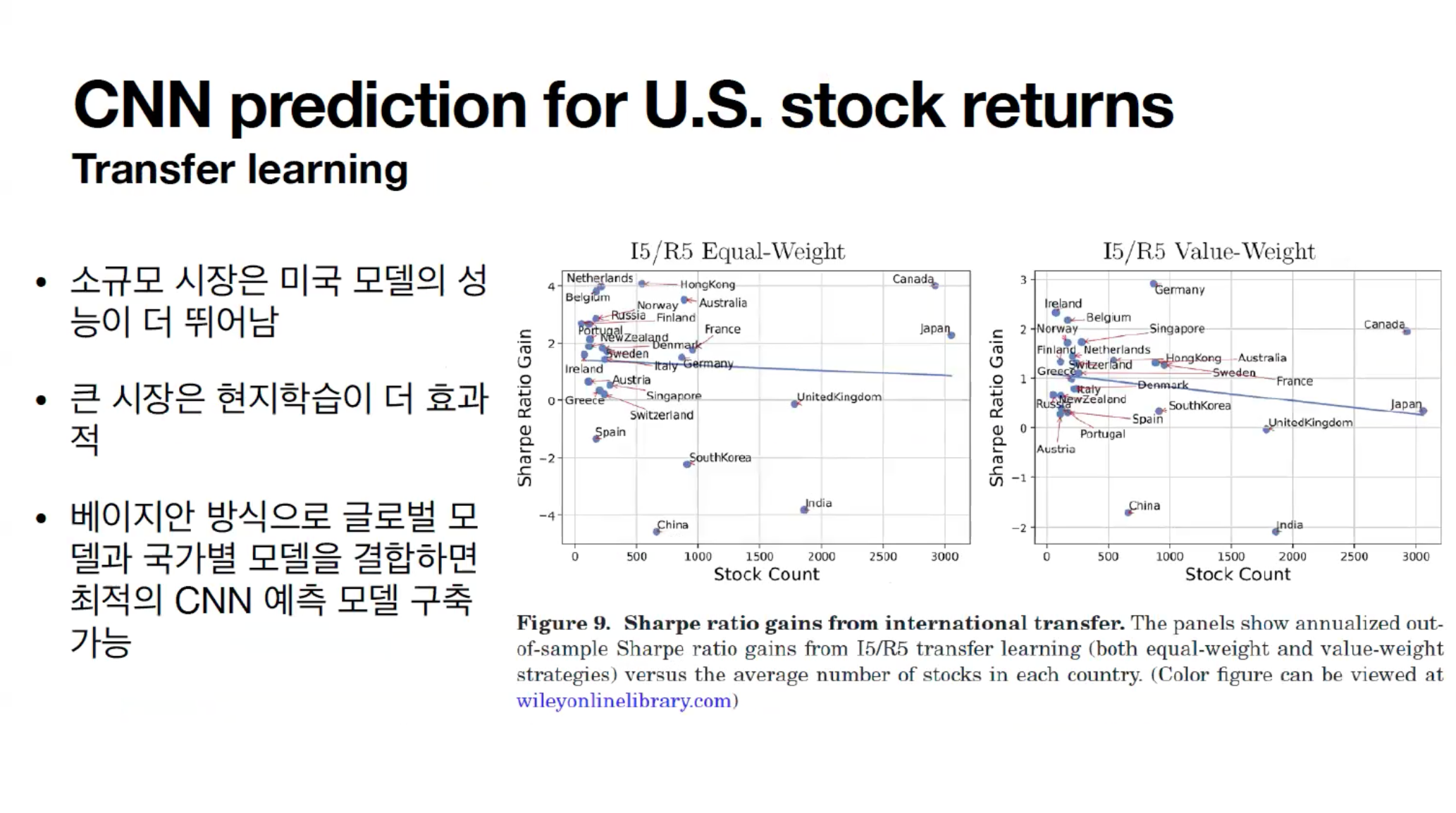
이 연국에서는 미국 시장을 바탕으로 학습한 모델을 다른 시장에서도 적용할 수 있는가를 실험했습니다. 미국 시장 데이터를 학습한 모델은 규모가 큰 시장에서는 성능이 뛰어나지 않았습니다. 그러나 소규모 시장에서는 충분히 높은 샤프 비율을 기록할 수 있음을 확인했습니다.
규모가 큰 시장에서는 일본이나 캐나다와 같은 다른 시장 데이터를 사용하여 학습한 모델이 더 효과적이었습니다. 이 경우, 각 시장의 데이터를 개별적으로 학습한 후, 이를 앙상블 방식으로 결합하는 것이 더 좋은 성과를 낸다고 주장합니다. 특히, 베이지안 방식을 사용한 앙상블 기법을 통해, 각 시장에 대해 최적의 CNN 예측 모델을 구축할 수 있다는 결론을 도출했습니다.
해당 자료는 CDFi 세미나에서 진행한 세션 내용을 바탕으로 제작되었습니다.해당 자료의 저작권은 CDFi 및 발표자에게 귀속되며, 어떤 형태로든 동의 없이 복제, 변형, 재배포 될 수 없습니다.
미디엄: https://medium.com/@cdfiseminar
뉴스레터: https://maily.so/cdfi
유튜브: Youtube_월스트리트디파이
텔레그램(뱅크리스 코리아): https://t.me/BanklessKorea
트위터(뱅크리스 코리아): https://twitter.com/BanklessKorea
의견을 남겨주세요