
Introduction
개발자라면 한 번쯤 이런 생각 해본 적 있지 않나요? "구글은 대체 어떻게 웹 전체를 크롤링하는 거지?"
2012년 이후로 아무도 제대로 된 대규모 웹 크롤링 포스트를 안 써서, Andrew Chan이 직접 해봤습니다. 그것도 개인 프로젝트로. 목표는 간단(?)했습니다: 24시간 안에 10억 페이지를 크롤링하는 것.
"아니 미쳤나? 10억 페이지?" 싶겠지만, 진짜로 해냈습니다. AWS 인스턴스 12대와 462달러로 말이죠.
왜 이런 미친 짓을?
2012년과 지금은 완전 다른 세상입니다:
- CPU 코어 수: 미친듯이 증가 ✅
- SSD: 이제 RAM급 속도 ✅
- 네트워크: 10Gbps가 기본 ✅
- 하지만 웹페이지는... 51KB → 242KB로 5배 무거워짐 😱
- SSL everywhere (CPU 25% 잡아먹는 괴물) 😱
과연 개인 개발자가 구글급 인프라 없이도 대규모 크롤링이 가능할까? 궁금해서 직접 해본 결과라고 하는데요.
제곧네: 생각보다 할 만했다 (삽질 제외하고)
- ✅ 10억 페이지 크롤링 성공
- ✅ 25.5시간 안에 완료
- ✅ 462달러 예산 내 달성
- ✅ robots.txt 지키는 착한 크롤러로
- 😅 중간에 메모리 터져서 일요일 하루종일 온콜
이 글은 "어떻게 했는지"보다는 "삽질하면서 배운 것들"에 더 집중합니다. Redis 최적화부터 SSL 핸드셰이크가 CPU를 얼마나 잡아먹는지, 그리고 야후와 위키피디아가 얼마나 링크 괴물인지까지.
특히 파싱이 이렇게 병목일 줄 몰랐다는 부분이 가장 충격적이었습니다. lxml → selectolax로 바꾸고 나서야 숨통이 트였다고 하네요.
혹시 "나도 대규모 시스템 만들어보고 싶다"는 개발자분들에게는 좋은 레퍼런스가 될 것 같습니다. 그리고 "아직도 JS 없이 크롤링 가능한 사이트가 이렇게 많구나" 하는 의외의 발견도 있었고요.
자, 이제 진짜 삽질기를 시작해볼까요? <Crawling a billion web pages in just over 24 hours, in 2025> 를 번역해 가져왔습니다.
24시간 만에 10억 웹페이지 크롤링하기 (2025년)
왠지 최근에는 웹의 대부분을 크롤링하는 데 필요한 것에 대해 쓴 사람이 아무도 없었습니다. 제가 본 마지막 참고 자료는 2012년 Michael Nielsen의 포스트였습니다.
그 이후로 많은 것이 변했습니다. 대부분은 더 크고, 더 좋고, 더 빨라졌습니다. CPU는 훨씬 많은 코어를 갖게 되었고, 회전 디스크는 RAM에 가까운 I/O 대역폭을 가진 NVMe SSD로 교체되었으며, 네트워크 파이프 폭이 폭발적으로 증가했고, EC2는 몇 가지 인스턴스 타입에서 수십 가지로 확장되었습니다. 하지만 일부는 더 어려워지기도 했습니다. 웹의 훨씬 많은 부분이 동적이 되었고, 콘텐츠도 더 무거워졌습니다. 최신 기술 수준은 어떻게 변했을까요? 병목지점이 이동했을까요? 여전히 자신만의 구글을 부트스트랩하는 데 약 41,000달러가 들까요? 알아보고 싶어서 비슷한 제약 조건 하에서 제 자신의 웹 크롤러를 구축하고 실행했습니다.
문제 정의
24시간 시간 제한: 예비 실험을 바탕으로 하루에 10억 페이지 크롤링이 달성 가능하다고 생각했기 때문입니다. 그리고 40시간은 그다지 멋지게 들리지 않았거든요. 최종 크롤링에서 각 머신의 평균 활성 시간은 25.5시간으로 약간의 편차가 있었습니다. 이는 재시작이 필요했던 일부 머신의 몇 시간은 포함하지 않습니다.
수백 달러의 예산: Nielsen의 크롤링은 580달러 정도 들었습니다. 다행히 저축해둔 여유 자금이 있어서, 최종 크롤링이 같은 범위에 맞도록 목표를 설정했습니다. 25.5시간의 활성 시간만 포함한 최종 실행 비용은 약 462달러였습니다. 단일 노드 시스템을 최적화하면서 많은 소규모 실험들(훨씬 저렴)과 수직 확장의 한계를 확인하기 위한 두 번째 대규모 실험(일찍 중단했지만 비슷한 범위)도 실행했습니다.
오직 HTML만: 방 안의 코끼리입니다. 2017년까지도 웹의 상당 부분이 JavaScript를 필요로 하게 되었습니다. 하지만 이전 웹 크롤링과 동일한 조건으로 비교하고 싶었고, 어차피 사이드 프로젝트로 진행하면서 playwright 워커를 추가하고 최적화할 시간이 없었습니다. 그래서 전통적인 방식을 택했습니다. 모든 링크를 요청하되 JS는 실행하지 않고, HTML을 그대로 파싱해서 <a> 태그의 모든 링크를 프론티어에 추가하는 것입니다. 이 방식으로 여전히 웹의 얼마나 많은 부분을 크롤링할 수 있는지도 궁금했는데, 결과적으로 상당히 많이 할 수 있었습니다!
예의 지키기: 이는 매우 중요합니다! robots.txt를 무시하고, 차단을 회피하기 위해 다른 에이전트로 위장하며, 끊임없이 엔드포인트를 두들기는 대규모 웹 크롤링이 관리자들에게 얼마나 큰 고통을 주는지에 대한 몇 가지 사례를 읽었습니다(예시). 저는 기존 관례를 따랐습니다. robots.txt를 준수하고, 제 연락처 정보가 포함된 정보성 사용자 에이전트를 추가하고, 요청 시 추가할 배제 도메인 목록을 유지하고, 개인 사이트를 건드리지 않기 위해 상위 100만 도메인의 시드 목록만 사용하고, 같은 도메인에 대한 요청 사이에 최소 70초 간격을 두었습니다.
내결함성: 어떤 이유로든 크롤링을 중단하고 재개해야 할 경우를 대비해 중요했습니다(실제로 그런 일이 있었습니다). 또한 일회성 크롤링 절차에서 성능 특성이 상태에 따라 달랐기 때문에 실험에도 많은 도움이 되었습니다. 크롤링 초반과 정상 상태는 꽤 다르게 보였거든요. 완벽한 내결함성을 목표로 하지는 않았습니다. 충돌이나 실패 후 복구 과정에서 일부 방문 사이트를 잃는 것은 괜찮았습니다. 제 크롤링이 근본적으로 웹의 샘플이었기 때문입니다.
고수준 설계
제가 최종적으로 채택한 설계는 시스템 설계 인터뷰에서 일반적으로 보는 크롤러 솔루션과 상당히 달랐습니다. 일반적인 솔루션은 기능들(파싱, 페칭, 데이터스토어, 크롤링 상태)을 완전히 분리된 머신 풀로 나누는데, 저는 대신 각각 모든 크롤러 기능을 포함하고 도메인 샤드를 처리하는 십여 개의 고도로 최적화된 독립 노드 클러스터를 사용했습니다. 이렇게 한 이유는:
- 실험과 최종 실행 모두에 제한된 예산으로 운영하고 있었으므로, 작게 시작해서 단일 머신에 가능한 한 많이 담고 확장하는 것이 합리적이었습니다.
- 실제로는 24시간에 10억 페이지라는 목표(중간에 추가)보다는 단일 머신의 성능 최대화 목표로 시작했습니다. 그 목표를 추가한 후에도 여전히 수직 확장에 대해 낙관적이었고, 자체 설정한 마감일에 접근하기 시작했을 때만 포기하고 클러스터 설계로 이동했습니다.
크롤러 설계
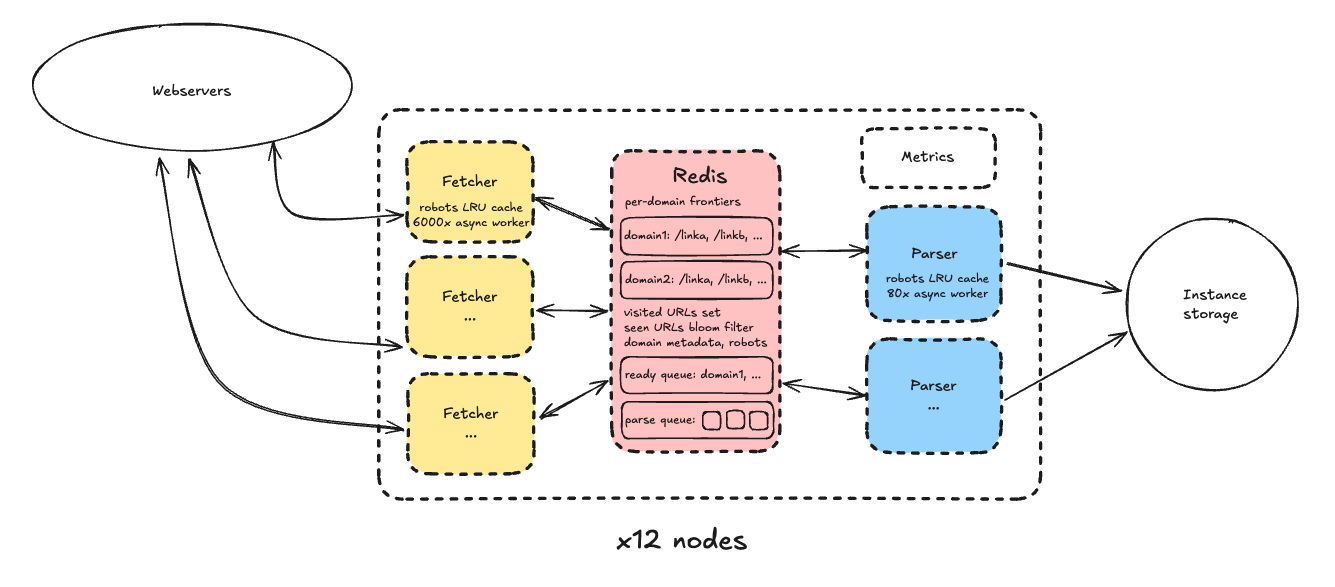
구체적으로, 각 노드는 다음으로 구성되었습니다:
크롤링 상태를 나타내는 데이터 구조들을 저장하는 단일 redis 인스턴스:
- 도메인별 프론티어, 즉 크롤링할 URL 목록
- 크롤링 지연을 기반으로 한 다음 페치 가능 타임스탬프로 정렬된 도메인 큐
- 각 URL이 일부 메타데이터와 디스크상의 저장된 콘텐츠 경로와 연결된 모든 방문 URL 엔트리
- URL이 이미 프론티어에 추가되었는지 빠르게 판단하기 위한 방문 URL 블룸 필터. 이는 방문 엔트리와 분리되어 있었는데, URL이 이미 거기 있지만 아직 페치되지 않았다면 프론티어에 추가하고 싶지 않았기 때문입니다. 블룸 필터의 거짓 양성 가능성은 문제없었습니다. 다시 말하지만, 제 크롤링이 인터넷의 샘플이라고 결정했고 속도를 최적화하고 있었기 때문입니다.
- 도메인이 수동으로 배제되었는지, 원래 시드 목록의 일부인지, robots.txt의 전체 내용(+ robots 만료 타임스탬프)을 포함한 도메인 메타데이터
- 파서가 처리할 페치된 HTML 페이지를 포함하는 파싱 큐
페처 프로세스 풀:
- 페처는 간단한 루프로 작동했습니다. redis에서 다음 준비된 도메인을 가져오고, 그 프론티어에서 다음 URL을 가져와서 페치한 다음(+ 준비 큐에서 도메인을 교체), 결과를 파싱 큐에 추가하는 것입니다.
- 각 프로세스는 asyncio를 통해 단일 코어에 높은 동시성을 구현했습니다. 경험적으로 페처가 6,000-7,000개의 "워커"(독립적인 비동기 페치 루프)를 지원할 수 있음을 발견했습니다. 이는 네트워크 대역폭 포화에는 근접하지도 않았습니다. 병목지점은 CPU였는데, 이에 대해서는 나중에 자세히 설명하겠습니다. 비동기 설계는 사용자 공간 멀티태스킹의 한 형태로, 컨텍스트 스위칭을 완전히 피하기 때문에 높은 동시성 시스템에서 한동안 인기를 끌었습니다(Python Tornado는 2009년에 출시되었습니다!).
- 페처와 파서 모두 redis 부하를 최소화하기 위해 robots.txt 내용 같은 중요한 도메인 데이터의 LRU 캐시를 유지했습니다.
파서 프로세스 풀:
- 파서는 페처와 유사하게 작동했습니다. 각각 80개의 비동기 워커로 구성되어 파싱 큐에서 다음 항목을 가져와 HTML 콘텐츠를 파싱하고, 링크를 추출해서 redis의 적절한 도메인 프론티어에 다시 쓰고, 저장된 콘텐츠를 영구 저장소에 쓰는 것입니다. 동시성이 훨씬 낮았던 이유는 파싱이 IO 바운드가 아닌 CPU 바운드이기 때문입니다(파서도 여전히 redis와 통신하고 가끔 robots.txt를 페치해야 했지만). 80개 워커가 CPU를 포화시키기에 충분했습니다.
기타:
- 영구 저장소의 경우, 기존 관례를 따라 인스턴스 저장소를 사용했습니다. 교과서적인 인터뷰 솔루션은 S3 사용을 제안할 것입니다. 이를 고려했는데, S3는 요청당뿐만 아니라 비례 GB-월로도 요금을 부과합니다. 페이지당 250KB(총 250TB)를 가정한 10억 페이지를 단 하루 동안 보관하는 것만으로도 표준 티어로 0.022×1000×250×(1/30)+0.005×1e6 = $5,183.33 또는 익스프레스로 0.11×1000×250×(1/30)+0.00113×1e6 = $2,046.67의 비용이 들었을 것입니다. 제가 최종적으로 지출한 것보다 한 자릿수 더 많은 금액입니다. 모든 PUT 비용을 무시하더라도, 하루 동안 데이터를 보관하는 데 표준으로 $183.33 또는 익스프레스로 $916.67가 들었을 것이므로, 페이지를 배치로 묶었더라도 경쟁력이 없었을 것입니다.
- 결국 저장소 최적화 인스턴스인 i7i 시리즈를 사용하고, 저장된 페이지가 맞도록 잘라냈습니다. 분명히 자르기는 실제 크롤러에게는 좋은 아이디어가 아닐 것입니다. 파서에서 snappy 같은 빠른 압축 방법이나 더 느린 백그라운드 압축기 사용을 고려했지만 시도할 시간이 없었습니다.
- 풀의 첫 번째 페처 프로세스는 "리더"로도 지정되어 주기적으로 메트릭을 로컬 prometheus DB에 기록했습니다. 실제 시스템에서는 모든 노드를 위한 단일 메트릭 DB를 갖는 것이 더 좋았을 것입니다.
최종 클러스터 구성:
- 12개 노드
- 각각 16 vCPU, 128GB RAM, 10Gbps 네트워크 대역폭, 3,750GB 인스턴스 저장소를 가진 i7i.4xlarge 머신
- 각각 1개 redis 프로세스 + 9개 페처 프로세스 + 6개 파서 프로세스 중심으로 구성
- 도메인 시드 목록이 노드 간 통신 없이 클러스터 노드들에 샤딩됨. 또한 시드된 도메인만 크롤링했기 때문에, 노드들이 인터넷의 각자 겹치지 않는 영역을 크롤링했다는 의미입니다. 이는 주로 (교차 통신이 있는) 대안 설계를 작동시키려다 시간이 부족했기 때문입니다.
왜 12개 노드만? 한 실험에서 시드 도메인을 너무 얇게 샤딩하면 매우 인기 있는 도메인을 가진 일부 노드는 할 일이 많은 반면 다른 노드는 빨리 끝나는 심각한 핫 샤드 문제가 발생함을 발견했습니다. 또한 redis가 초당 120 작업에 도달하기 시작했고 더 많으면 문제가 발생할 것이라고 읽었기 때문에(더 많은 시간이 있었다면 정확한 포화점을 찾는 실험을 했을 것입니다) redis 프로세스당 총 15개 프로세스에서 페처와 파서 풀의 수직 확장을 중단했습니다.
검토된 대안들
위 설계에 도달하기 전에 몇 가지 다른 설계를 시도했습니다. 최근 대부분의 크롤러가 Redis 같은 빠른 인메모리 데이터스토어를 사용하는 것 같고, 그럴 만한 이유가 있습니다. SQLite와 PostgreSQL 백엔드로 소규모 프로토타입을 만들어봤지만, 데이터 구조의 개념적 단순성에도 불구하고 프론티어 쿼리를 빠르게 만드는 것이 지나치게 복잡했습니다. AI 코딩 도구가 이 탐색에 많은 도움이 되었습니다. 이에 대해서는 여기에 써두었습니다.
또한 단일 노드를 수직으로 확장하는 것을 꽤 열심히 시도했습니다. 과거의 대규모 크롤링을 분산 시스템으로 제한했던 하드웨어 병목지점들이 많이 사라진 것 같아 낙관적으로 생각했습니다. 예를 들어, AWS는 본질적으로 12개의 i7i.4xlarge 머신을 합친 i7i.48xlarge 인스턴스를 제공합니다. 네트워크 대역폭은 상당히 적지만(12×25Gbps 대신 100Gbps), 24시간에 10억 페이지를 달성하는 데 필요한 처리량에서, 모든 페이지가 1MB라고 해도(실제로는 그렇지 않았습니다), 8×1e6×(1e9/86400)=92Gbps만 사용했을 것이고, 아웃바운드를 위한 여유도 있었을 것입니다(확실히 요청당 1MB는 아니었어요).
제가 시도한 첫 번째 대규모 설계는 모든 것을 단일 i7i.48xlarge에 담아서, 프로세스를 최종 클러스터의 노드와 많이 닮은 "팟"(단일 redis 인스턴스를 가진 16개 프로세스 그룹)으로 조직화했지만, 교차 통신을 허용했습니다. 두 번째 설계에서는 교차 통신을 제거하고 그냥 독립적인 팟을 실행했습니다. 이것으로 한 대규모 실행은 실망스러운 결과를 보였습니다(전체 시스템이 초당 1k 페이지만 관리했는데, 이는 최종 클러스터의 단일 노드 처리량보다 조금 많은 정도였거든요). 시간 제한에 걸려서 포기하고 수평 확장으로 이동했습니다. 병목은 하드웨어보다는 소프트웨어(운영 체제 리소스)일 수도 있다고 생각합니다.
배운 점들
파싱이 주요 병목
파싱이 얼마나 큰 병목지점인지 정말 놀랐습니다. 최종 시스템에서는 파싱 대 페칭 비율을 2:3으로만 할당하면 되었지만, 처음부터 그랬던 것은 아니고, 거기에 도달하는 데 많은 반복이 필요했습니다. 사실, 전용 파싱/페칭 프로세스를 가진 첫 번째 시스템에서는 1,000개 워커로 초당 55페이지에서 실행되는 1개의 (부분적으로 유휴한) 페처를 따라가기 위해 2개의 파서가 필요했습니다. 파싱이 예산 내에서 10억을 달성하는 것을 막을 것처럼 정말 보였습니다!
이는 제 쿼드 코어 노드가 2012년에 더 약한 쿼드 코어 박스가 달성할 수 있었던 같은 처리량을 달성하지 못했다는 것을 의미했기 때문에 정말 놀라웠습니다. 프로파일링은 파싱이 명백히 병목지점임을 보여줬지만, 저는 2012년에 인기 있었던 같은 lxml 파싱 라이브러리를 사용하고 있었습니다(Gemini가 제안한 대로). 결국 평균 웹페이지가 훨씬 커졌기 때문임을 알아냈습니다. 테스트 실행의 메트릭에 따르면 P50 압축되지 않은 페이지 크기는 현재 138KB이고, 평균은 242KB로 더 큽니다. 2012년 Nielsen이 추정한 평균 51KB보다 몇 배나 큽니다!
가장 도움이 된 두 가지:
- lxml에서 selectolax로 전환했습니다. HTML5를 위해 특별히 설계된 C++의 현대적 파서인 Lexbor를 래핑하는 훨씬 새로운 라이브러리입니다. 페이지에서는 lxml보다 30배 빠를 수 있다고 주장했습니다. 전체적으로 30배는 아니었지만, 엄청난 부스트였습니다.
- 파서에 전달하기 전에 페이지 콘텐츠를 250KB로 자르기도 했습니다. 자르기 임계값이 평균보다 높고 중간값의 거의 두 배이므로, Nielsen[1]의 논리가 여전히 유효하다고 생각합니다. 대부분의 웹페이지를 전체적으로 캡처하고 있으며, 이는 대부분의 애플리케이션에 충분해야 합니다.
이 설정으로 단일 파서 프로세스로 초당 약 160페이지를 파싱할 수 있었고, 이로 인해 최종 설정에서 9배 페처와 6배 파서를 사용해서 초당 약 950페이지를 크롤링할 수 있었습니다.
페칭: 더 쉬워졌지만 더 어려워지기도
크롤링에 대한 많은 논의에서 네트워크 대역폭과 DNS를 중요한 병목지점으로 여깁니다. 예를 들어, 이 주제를 연구하면서 2009년 Sapphire 프로젝트[4]에 대해 CMU의 Jamie Callan에게 이메일을 보냈는데, Callan 교수는 DNS 해결 처리량이 병목지점이었고, CMU 캠퍼스 네트워크를 사용한 2012년의 후속 크롤링에서는 모든 대역폭을 사용하지 않기 위해 크롤링 처리량을 조절해야 했다고 말했습니다. 약 1년 전 Evan King의 인터뷰 분석도 DNS 해결을 위한 최적화를 제안합니다.
제 크롤링에서는 DNS가 전혀 문제가 되지 않았습니다. 상위 약 100만 도메인의 시드 목록으로 크롤링을 제한했기 때문이라고 생각합니다. 네트워크 대역폭도 클러스터의 어떤 노드에서도 포화 상태에 근접하지 않았습니다. 대부분의 노드는 정상 상태에서 평균 약 1 GB/s (8 Gbps)였지만, i7i.4xlarge의 최대 대역폭은 25 Gbps입니다. 요즘 데이터센터 대역폭은 특히 AI를 위해 풍부합니다. AWS는 28.8테라비트의 네트워크 대역폭을 가진 P6e-GB200 인스턴스를 제공합니다!
그렇긴 하지만, 페칭의 한 부분이 더 어려워졌습니다. 10년 전보다 훨씬 더 많은 웹사이트가 SSL을 사용합니다. 이는 프로파일링에서 매우 명확했는데, SSL 핸드셰이크 계산이 가장 비싼 함수 호출로 나타나서 평균적으로 전체 CPU 시간의 무려 25%를 차지했습니다. 네트워크 파이프를 포화시키는 것에 근접하지 않았다는 점을 고려하면, 페칭이 네트워크보다 CPU에 의해 병목지점이 되었다는 의미죠.
대규모 크롤링
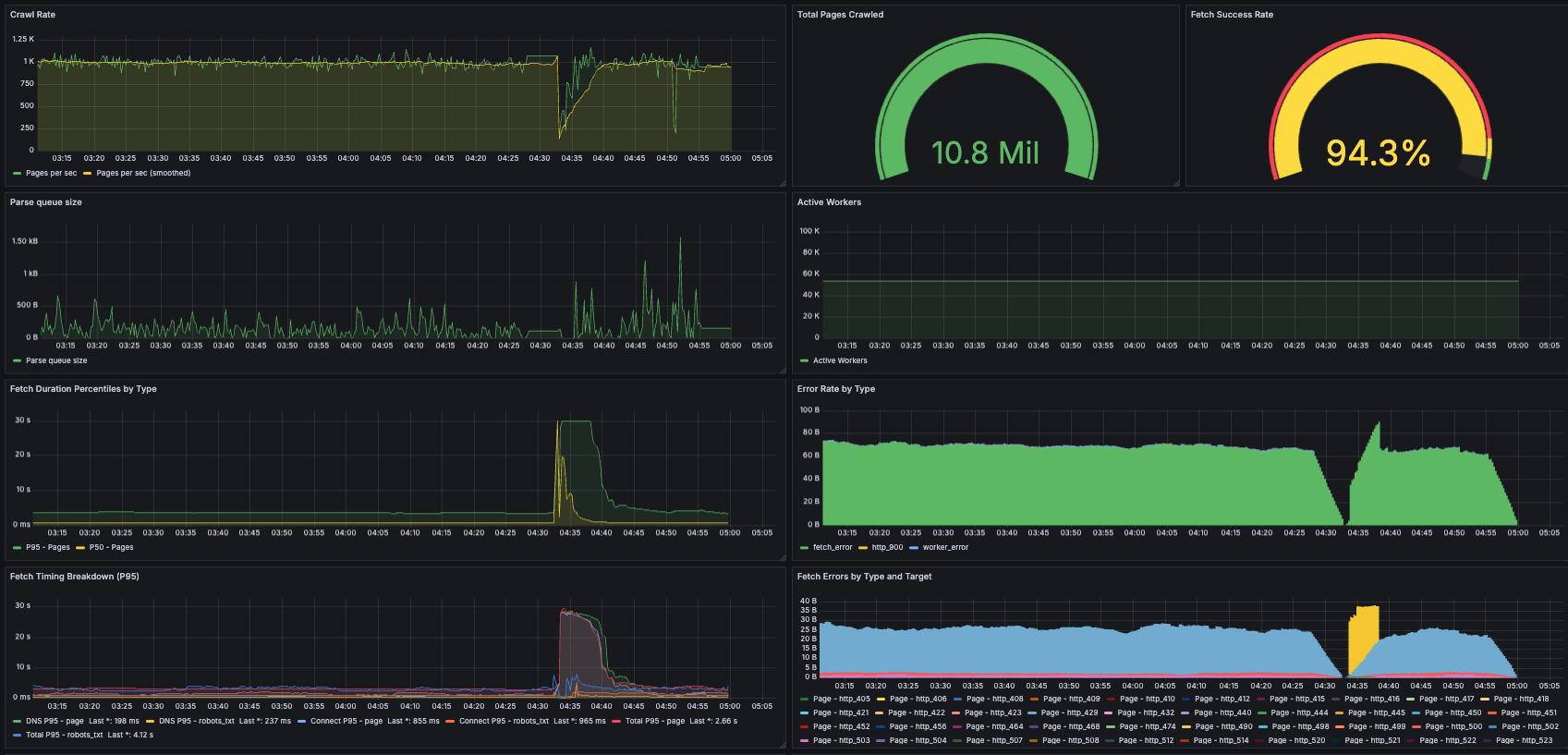
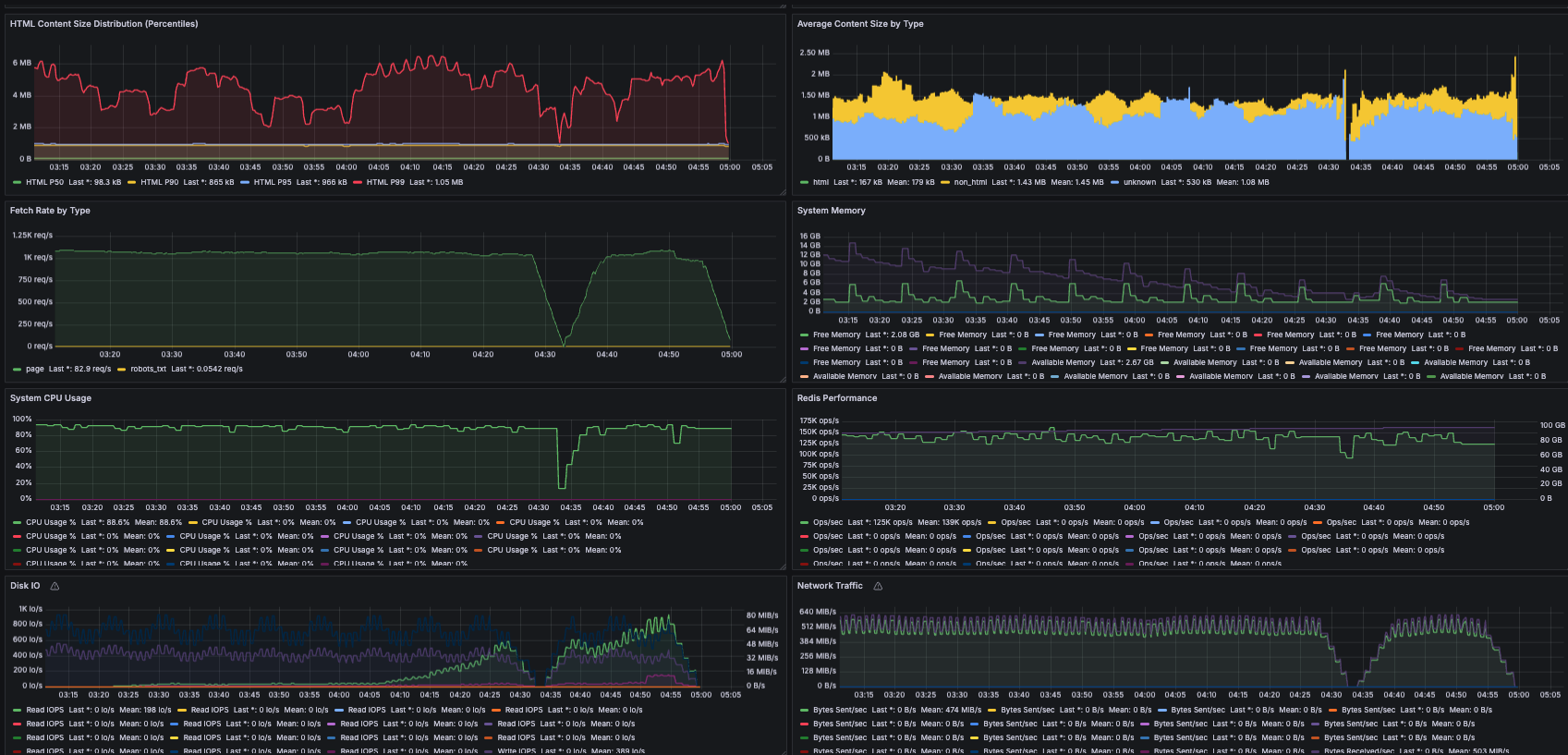
12개의 i7i.4xlarge 노드로 대규모 크롤링을 실행하기 전에 제가 한 가장 큰 실험은 단일 i7i.2xlarge에서 몇 시간 실행하는 것이었기에, 실행 과정에서 규모가 비약적으로 커진 것에 꽤 많이 놀랐습니다. 일요일 하루 종일 해가 뜨는 시간부터 해가 지는 시간까지(그리고 그 이후까지) 제 자신의 실행을 위한 온콜 상태로 지내며 메트릭을 보고 문제를 해결하기 위해 들어가곤 했습니다. 이 중 일부는 로그 로테이션 설정을 잊어서 루트 볼륨의 공간이 부족해지는 것 같은 바보 같은 운영상 실수였지만, 가장 큰 문제는 프론티어로 인한 메모리 증가였습니다.
이는 모든 프론티어 데이터를 메모리에 두는 제 설계의 특수한 문제였습니다. 이전의 더 작은 규모 크롤링에서도 메모리 문제가 있었지만, HTTP 클라이언트나 방문 엔트리 같은 다른 구성요소에서였습니다. 그런 구성요소들에 대해 10억 방문 페이지에 필요한 메모리 여유를 계산해봤지만, 특정 매우 핫한 도메인의 프론티어가 수십 기가바이트(수억 또는 수십억 URL)가 될 것을 예상하지 못했습니다. 실행 중반에 제 노드들이 차례로 다운되기 시작했습니다. 응답하지 않게 된 머신들을 재시작하고 프론티어를 잘라내는 식으로 수동 개입해야 했습니다. 다행히 내결함성 덕분에 수정 후 재개가 쉬웠습니다.
문제가 된 도메인들이 타르핏(tarpit)이었을까요? 제가 알 수 있는 바로는, 대부분 그냥 정말 인기 있는 웹사이트들로 링크가 많았습니다. 예를 들어, yahoo.com과 wikipedia.org가 그 중에 있었습니다. 또 다른 하나는 "cosplayfu" 웹사이트였는데 첫눈에는 이상한 쇼핑 사이트처럼 보였지만, 인터넷에서 검색해본 후에는 합법적인 것 같았습니다. 어쨌든, 가장 문제가 된 도메인들은 단순히 제 수동 배제 목록에 추가되었습니다.
Discussion
이론 vs. 실제
제 크롤러는 Evan King의 Hello Interview 분석에 있는 것 같은 교과서 솔루션과 어떻게 대조될까요? 여기서 관심 있는 메트릭은 아마도 King의 "대략적인" 추정인 5대의 머신이 5일에 100억 페이지를 크롤링할 수 있다는 것일 겁니다. 이 주장에서, 머신들은 완전히 페칭에 전념하고, 파서와 프론티어 데이터스토어는 다른 곳에 있습니다. 30% 이용률을 달성하는 머신당 400Gbps 대역폭을 가정하는 것 외에는 각 머신의 하드웨어에 대한 세부사항이 없습니다.
적어도 이용률은 맞습니다. 제 노드들은 25Gbps만 제공했지만, 실제로 정상 상태에서 8Gbps 인/아웃으로 약 32%의 이용률을 얻었습니다. 그렇긴 하지만, 각 머신에서 16개 코어 중 9개만 페칭에 전념했는데, 단순하게 확장하면 53%의 네트워크 이용률을 달성할 수 있었을 것입니다. 마찬가지로, 약 1일에 10억 페이지를 크롤링하기 위해 12대의 머신을 사용했으므로, 6.75대의 페처 전용 머신으로 같은 하루 10억 페이지 처리량을 달성할 수 있었을 것입니다. i7i.4xlarge에서 i7i.8xlarge로의 직접적인 확장도 가정한다면, 이는 6.75대의 두 배 크기 페처 전용 머신이 5일에 100억 페이지를 크롤링할 수 있음을 의미합니다. 따라서 King의 숫자는 그리 멀지 않지만, 제가 제 시스템으로 한 것보다 조금 더 최적화가 필요할 수도 있습니다!
앞으로는?
솔직히 말해서 JS를 실행하지 않고도 웹의 그렇게 많은 부분에 여전히 접근할 수 있다는 것이 놀랍습니다[6]. 좋은 일입니다! 이 크롤링을 통해 ancientfaces.com 같은 멋진 웹사이트들을 알게 되었습니다. 하지만 GitHub 같은 많은 크롤링 가능한 웹사이트들조차도 다운로드된 페이지에 실제로 의미 있게 마크업된 텍스트 콘텐츠가 없다는 것을 알았습니다. 모든 것이 거대한 문자열에 임베드되어 있었고 아마도 우리가 "가벼운" JS 스크립트라고 여길 수 있는 것에 의해 클라이언트 사이드에서 렌더링되어야 했습니다. 흥미로운 미래 작업은 이 코끼리를 다루는 것일 겁니다. 실제로 페이지를 동적으로 렌더링해야 할 때 대규모 크롤링이 어떻게 보일까요? 같은 규모가 훨씬 더 비쌀 것이라고 생각합니다.
또 다른 질문은: 제가 크롤링한 10억 페이지의 형태와 분포는 어떨까요? 샘플은 보관하고 있지만 아직 분석을 실행할 시간이 없었습니다. 얼마나 많은 크롤링된 URL이 실제로 살아있는지 vs. 죽어있는지, 얼마나 많은 것이 HTML 콘텐츠 타입인지 vs. 멀티미디어인지 등과 같은 메타데이터에 대한 몇 가지 기본 사실을 아는 것이 흥미로울 것입니다.
마지막으로, 이 포스트는 지난 10년 동안 웹이 변한 더 큰 방식들 중 일부를 다뤘지만, 풍경은 다시 한 번 변하고 있습니다. 막대한 자원에 뒷받침된 공격적인 크롤링/스크래핑은 새로운 것이 아니지만(Facebook이 이전에 OpenGraph 스크래핑으로 곤란에 빠진 적이 있습니다), AI와 함께 강화되었습니다. 저는 예의를 매우 진지하게 받아들여서 robots.txt 같은 관례를 따르고 더 많은 것을 했지만, 많은 크롤러들은 그렇지 않고 인터넷이 방어책을 개발하기 시작하고 있습니다. Cloudflare의 실험적인 크롤링당 지불 기능은 많은 도움이 될 수 있는 시장의 새로운 제안입니다.
👥 더 나은 데브필을 만드는 데 의견을 보태주세요
Top 1% 개발자로 거듭나기 위한 처방전, DevPill 구독자 여러분 안녕하세요 :)
저는 여러분들이 너무 궁금합니다.
어떤 마음으로 뉴스레터를 구독해주시는지,
어떤 환경에서 최고의 개발자가 되기 위해 고군분투하고 계신지,
제가 드릴 수 있는 도움은 어떤 게 있을지.
아래 설문조사에 참여해주시면 더 나은 콘텐츠를 제작할 수 있도록 힘쓰겠습니다. 설문에 참여해주시는 분들 전원 1개월 유료 멤버십 구독권을 선물드립니다. 유료 멤버십에서는 아래와 같은 혜택이 제공됩니다.
- DevPill과의 1:1 온라인 커피챗
- 멤버십 전용 슬랙 채널 참여권
- 채용 정보 공유 / 스터디 그룹 형성 / 실시간 기술 질의응답
- 이력서/포트폴리오 템플릿

의견을 남겨주세요