
📈데일리 차트팩 - 옵션시장 이상징후, 무역협상리스크, 소매유입
구독자님 안녕하세요. 은호입니다.
하루 동안 봤던 차트들 중에 유의미한걸 모아서 제공하고 있습니다.
데이터는 해석하기 나름이고 시간이 지나봐야 어떤 데이터가 그 당시에 제일 적절했는지
확인이 가능하기 때문에 참고용 정도로 보시면 좋을거 같습니다!
(일부는 스레드에도 업로드 된 차트입니다.)
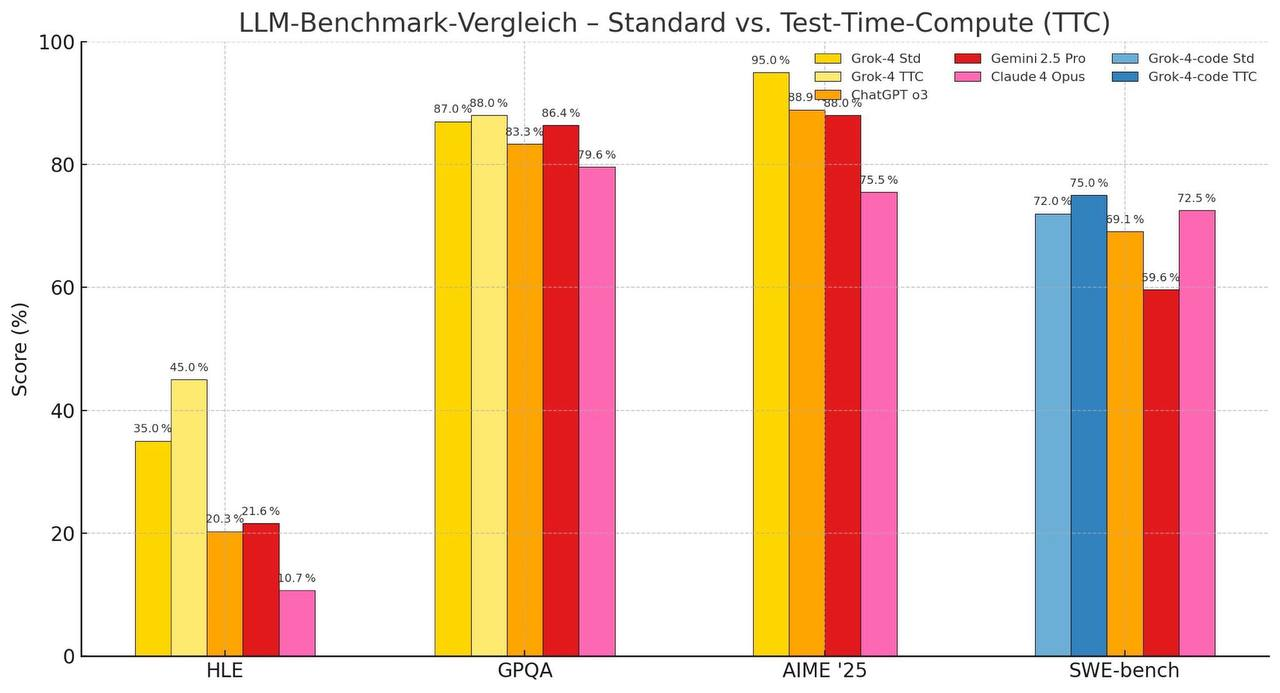
🚀 Grok-4, 추론형 벤치마크에서 압도적 성능
- Grok-4가 다양한 테스트에서 인상적인 결과를 보여주었음
- HLE (추론 능력 평가)에서 Grok-4 TTC는 45.0%로 가장 높은 점수를 기록
- AIME '25 (수학적 사고력 중심)에서는 Grok-4 Std가 95.0%로 압도적 1위
- GPQA (사실 기반 질의 응답)에서도 Grok-4 TTC와 Std가 각각 88.0%, 87.0%로 최상위권
- SWE-bench (소프트웨어 엔지니어링 관련 문제 해결)에서도 Grok-4-code TTC는 75.0%로 최고 점수
📊 해설
- HLE (High-Level-Extraction):
- Grok-4는 TTC(Time-Test-Compute) 세팅에서 45.0%를 기록하며 ChatGPT o3 (10.7%)나 Claude 4 Opus (21.6%)를 큰 차이로 앞섰음
- 이는 Grok-4가 고차원적 추론과 의미 추출 능력에서 뛰어남을 보여줌
- GPQA (General-Purpose QA):
- 모든 모델이 높은 성적을 보였지만 Grok-4 Std/TTC가 각각 87.0%와 88.0%로 최상위
- ChatGPT o3는 79.6%로 상대적으로 낮았고, Claude 4는 86.4%로 그 뒤를 이었음
- AIME '25 (American Invitational Math Exam 스타일 문제):
- Grok-4 Std는 95.0%로 최고 기록. TTC 설정에서도 88.9%로 강세 유지
- 반면 Claude 4는 88.0%, ChatGPT o3는 75.5%로 하락세를 보임
- 수학적 추론에 특화된 설정에서는 Grok-4가 독보적인 성능을 입증
- SWE-bench (Software Engineering Benchmarks):
- Grok-4-code TTC가 75.0%로 1위. Std도 72.0%로 근접
- Claude 4 Opus (72.5%)도 근소하게 우위를 보였지만, Grok의 전반적인 일관성이 더 돋보임
- ChatGPT o3는 59.6%로 코드 문제에서 격차가 큼
📌 용어 설명
- TTC (Test-Time Compute): 테스트 시점에서 더 많은 계산 리소스를 활용하여 정밀도를 높인 세팅
- Std (Standard): 표준 설정으로 수행한 결과
- HLE: 고차원적 개념 이해 및 추론을 요구하는 문제 평가
- GPQA: 일반 상식 및 정보 기반 질의응답 평가
- AIME: 미국 수학 경시대회 스타일 문제로, 복잡한 논리/수학 추론 능력 요구
- SWE-bench: 실제 코드 기반 문제 해결력 평가
Grok-4는 특히 고난도 수학(AIME)과 추론(HLE)에서 두각을 나타냈으며, 추론형 LLM으로서 GPT-4 o3 대비 확실한 차별점을 보여줌