
1️⃣ 검색 구조의 기본 흐름
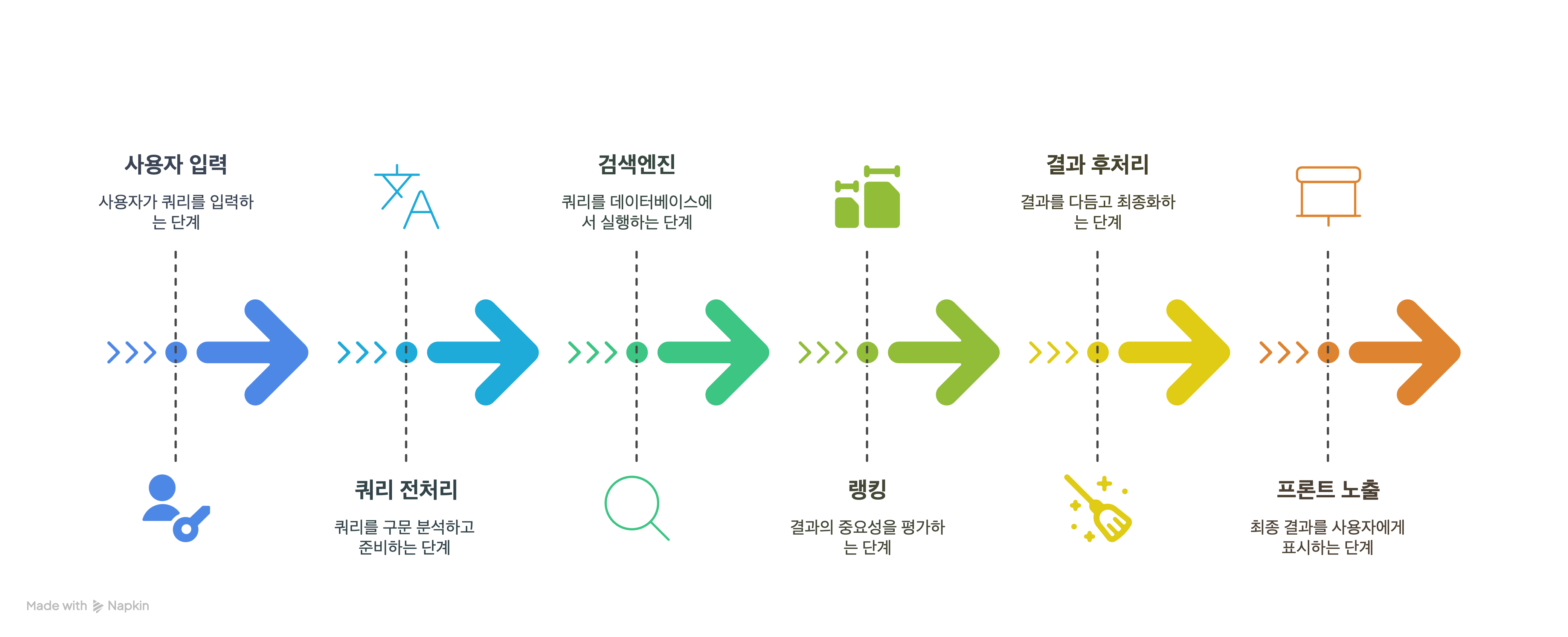
쿼리 전처리 (Query Parsing)
쿼리 전처리는 사용자가 입력한 언어를 검색엔진으로 요청하기 전 분석하기 쉽도록 변환하는 단계예요. 한국어처럼 띄어쓰기와 어근 변형이 많은 언어일수록 형태소 분석기라는 부분이 중요해요. 또한 "청바지"와 "진"처럼 같은 의미를 어떻게 처리할 것인지 결정하는 단계예요.
검색엔진 실행 (Query Execution)
검색엔진의 경우 직접 구현하기보다는 내부 리소스를 줄이기 위해 기존 오픈소스 (Elasticsearch, Solr, Vespa 등)을 많이 사용해요. 검색엔진이 중요한 이유는 어떤 필드를 어떻게 인덱싱(맵핑)하느냐에 따라 검색의 속도와 정확도에서 큰 차이가 나기 때문이에요. 또한 검색할 때 Full-text 기반 검색인지, 필터 기반 검색인지에 따라서도 검색의 속도와 정확도에서 차이가 나요.
랭킹 (Ranking)
보통 검색 기능을 기획하면 그 결과에 대해 정렬도 같이 기획하는 경우가 많아요. 정렬이라고 하는 것은 결국 검색 결과에 대해 특정 우선순위를 부여했다는 뜻이에요. 그렇기 때문에 최신 순, 인기 순, 연관도 순은 단순해보이지만 각 로직에 따라 랭킹을 부여하는 방식이에요.
실무 팁
쿼리 전처리를 어떤 방식으로 하고, 검색엔진에서 인덱싱을 어떻게 하고 등등은 알면 좋지만, 무조건 알아야 하는 항목은 아니에요. 어떤 오픈소스를 사용했고 Full-text 기반 검색인지, 필터 기반 검색인지 정도만 알아도 개발자와 대화는 충분히 가능해요.
개발자와 대화 시 팁
"검색 필터 조건이 AND/OR 조합이 가능한가요?"
"랭킹 로직은 실시간 적용인가요? 아니면 주기적 재적재(batch)인가요?"
"랭킹 알고리즘에서 사용자 행동 데이터 반영되나요?"
"실시간 랭킹 적용 latency는 어느 정도인가요?"
와 같은 질문으로 사용자가 검색할 때 알아야 할 제한 요건을 파악하세요.