
투자자들은 늘 유망한 종목을 찾기 위해 노력합니다. 하지만 S&P 500 지수에만 500개가 넘는 기업이 존재하며, 이 모든 기업의 재무제표를 매 분기 꼼꼼히 분석하는 것은 일반인 입장에서 현실적으로 불가한 일입니다. 그러나 빠르게 발전하는 AI와 간단한 코딩만 다룰 줄 안다면, 이러한 프로세스의 상당 부분을 효율화 할 수 있습니다.
전통적으로 투자는 숫자를 중시하는 '퀀트(Quant)'와 기업의 본질적 가치를 중시하는 '펀더멘탈 분석(Fundamental)'으로 나뉘어 왔습니다. 이번 뉴스레터에서는 AI를 활용해 이 두 가지 방식을 효과적으로 결합하는 과정을 소개해드리려 합니다. 전체적인 프로세스는 다음과 같습니다.
1. 코딩을 활용해 S&P500 종목 리스트와 가격 데이터 수집
2. 퀀트 모델링을 통해 유망한 종목 1차 선별
3. 상관계수를 기반으로 최종 후보 종목 선별
4. API를 활용하여 최종 후보 종목들의 SEC 보고서 수집
5. LLM을 활용하여 해당 보고서를 토대로 기본적 분석 수행, 최종 매수 종목 산출
길게 나열했지만, 해당 전략의 핵심은 퀀트로 투자 대상(What)의 범위를 좁히고, AI를 활용한 기본적 분석으로 투자 근거(Why)를 검증하는 것이라 볼 수 있겠습니다.
(어디까지나 예시로 보여드리는 방법론일 뿐, 실제 투자는 투자자 각자의 책임임을 다시 한 번 밝힙니다.)
STEP 1. 데이터 수집: S&P 500 전 종목 데이터 확보
분석의 첫 단계는 데이터 수집입니다. 먼저 S&P 500에 편입된 기업들의 티커(Symbol) 리스트를 확보해야 합니다. 현재 시점의 S&P 500의 종목 리스트는 위키피디아에서 확인할 수 있습니다.
이 리스트를 하나씩 따로 복사할 필요는 없습니다. 위키피디아의 해당 페이지에서 데이터를 직접 수집하는 코드를 활용하면 자동으로 500여 개의 종목 티커를 불러올 수 있습니다.
def save_sp500_stock_data(start_date):
# 1. S&P 500 티커 리스트 수집
url = "https://en.wikipedia.org/wiki/List_of_S%26P_500_companies"
# 헤더 정보 설정 => 각자 적절히 수정(gemini 활용)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
# requests를 이용해 헤더와 함께 페이지 내용 요청
response = requests.get(url, headers=headers)
response.raise_for_status() # 요청이 성공했는지 확인 (200 OK가 아니면 에러 발생)
# requests로 가져온 HTML 텍스트를 pandas.read_html로 읽음
tables = pd.read_html(response.text)
sp500_table = tables[0]
tickers = sp500_table['Symbol'].tolist()
# 2. 각 종목의 주식 데이터 수집
all_data = {}
for ticker in tickers:
if ticker == 'BRK.B': ticker = 'BRK-B'
if ticker == 'BF.B': ticker= 'BF-B'
try:
print(f"Processing {ticker}...")
data = yf.download(ticker, start=start_date)
data = data[['Open','Close','High','Low','Volume']]
data.columns = ['Open','Close','High','Low','Volume']
all_data[ticker] = data
except Exception as e:
print(f"Error processing {ticker}: {e}")
# 3. 데이터를 하나의 데이터프레임으로 결합
combined_data = pd.concat(all_data, axis=1)
combined_data = combined_data.rename(columns={'BF-B':'BF/B', 'BRK-B':'BRK/B'}, level=0)
return combined_data
if __name__ == "__main__":
start_date = '2024-10-01'
df_2025 = save_sp500_stock_data(start_date = start_date)
df_2025.index = df_2025.index.astype(str)
print(df_2025)이렇게 불러온 티커 리스트에 yahoo finance에서 제공하는 라이브러리(함수 모음집)를 활용하면, 각 종목의 최근 주가 데이터를 전부 받아올 수 있게 됩니다.
STEP 2. 퀀트 필터 1: '듀얼 모멘텀' 전략
주가 데이터가 전부 수집되었다면 첫 단계는 끝난 셈입니다. 이제 500개의 종목 중 현재 시장에서 강세를 보이는 종목을 선별하기 위해 '듀얼 모멘텀' 기법을 활용할 차례입니다.
퀀트를 처음 접하시는 분들을 위해 듀얼 모멘텀에 대해 간단히 짚고 넘어가겠습니다. '모멘텀'이란 최근의 가격 추세가 앞으로도 (짧은 기간 한정) 지속될 것이라는 가정을 뜻합니다. 쉽게 말해, 최근까지 주가가 상승한 자산은 당분간 계속 상승하고, 하락 중이었던 자산은 계속해서 하락할 가능성이 높다고 보는 것이죠.
우리가 사용할 '듀얼 모멘텀(Dual Momentum)'은 이 개념을 활용한 전략입니다. 500개 종목 중 현재 시장에서 강세를 보이는 종목을 선별하기 위해 오랜 시간 활용되어 온 전략으로, 이는 두 가지 기준으로 구성됩니다.
- 절대 모멘텀 (Absolute Momentum): 특정 자산의 성과를 '과거의 자신'과 비교합니다. 예를 들어, '최근 12개월 수익률이 양수인가?'를 확인합니다. 이 기준을 통과하지 못하면(즉, 1년 전보다 가격이 하락했다면) 아예 투자 대상에서 제외합니다.
- 상대 모멘텀 (Relative Momentum): 절대 모멘텀을 통과한 종목들 중에서, 성과를 '다른 종목'과 비교하는 방법입니다. 'A 종목이 B 종목보다 최근 3개월간 더 많이 상승했는가?'를 보는 방식입니다. 이는 여러 상승 종목 중에서도 두드러지게 상승세를 나타내는 종목을 골라냅니다.
즉, 듀얼 모멘텀이란, ①스스로 상승 추세를 유지하면서(절대) ②다른 종목들보다 더 강한 추세(상대)의 종목을 찾는 필터링 기법입니다.
## 1년치 기준 절대, 상대 모멘텀 측정
def calculate_ranked_momentum_score(close_prices):
"""
여러 기간의 수익률 '순위'를 가중 평균하여 최종 모멘텀 점수를 계산합니다.
가중치: 12개월(20%), 3개월(30%), 1개월(50%)
"""
print("수익률 순위 기반 가중 평균 점수 계산 시작...")
# 1. 월말 종가 데이터 추출
monthly_prices = close_prices.resample('M').last()
# 2. 필요한 기간별 수익률 계산 (12, 3, 1개월)
return_12m = monthly_prices.pct_change(12).iloc[-1]
return_3m = monthly_prices.pct_change(3).iloc[-1]
return_1m = monthly_prices.pct_change(1).iloc[-1]
momentum_df = pd.DataFrame({
'Return_12M': return_12m,
'Return_3M': return_3m,
'Return_1M': return_1m
}).dropna()
# 3. 절대 모멘텀 필터 적용 (12개월 & 3개월 수익률 > 0)
absolute_filter = (momentum_df['Return_12M'] > 0) & (momentum_df['Return_3M'] > 0)
filtered_df = momentum_df[absolute_filter].copy()
if filtered_df.empty:
print("절대 모멘텀 필터를 통과한 종목이 없습니다.")
return None
print(f"총 {len(momentum_df)}개 종목 중 {len(filtered_df)}개가 절대 모멘텀 필터를 통과했습니다.")
# 4. 기간별 상대 모멘텀 '순위' 점수 계산
filtered_df['Score_12M'] = filtered_df['Return_12M'].rank(pct=True)
filtered_df['Score_3M'] = filtered_df['Return_3M'].rank(pct=True)
filtered_df['Score_1M'] = filtered_df['Return_1M'].rank(pct=True)
# 5. 최종 점수 산출 (가중 평균) --- 이 부분이 수정되었습니다 ---
weights = {'12m': 0.2, '3m': 0.3, '1m': 0.5}
filtered_df['Final_Score'] = (weights['12m'] * filtered_df['Score_12M'] +
weights['3m'] * filtered_df['Score_3M'] +
weights['1m'] * filtered_df['Score_1M'])
# 최종 점수 기준으로 내림차순 정렬
result_df = filtered_df.sort_values(by='Final_Score', ascending=False)
print("계산 완료.")
return result_df
temp = df_2025.xs('Close', axis=1, level=1)
if not pd.api.types.is_datetime64_any_dtype(temp.index):
print("인덱스를 문자열에서 Datetime 형식으로 변환합니다...")
temp.index = pd.to_datetime(temp.index)
momentum_scores = calculate_ranked_momentum_score(temp)
print("\n--- 상위 50개 종목 최종 모멘텀 점수 ---")
print(momentum_scores.head(50))
top_mom = momentum_scores.head(50).index사실 같은 듀얼 모멘텀 전략이라도 기간을 어떻게 줄지, 가중치를 어떻게 줄지에 따라 결과물이 조금씩 달라집니다. 여기서는 예시로 제가 적당한 수치들을 집어넣었지만, 실제 전략의 성과를 엄밀히 검증해보고자 하신다면 백테스트 로직까지 구축하는 걸 권장드립니다(여기서는 생략하겠습니다).
위 코드에서 절대 모멘텀은 2가지 기준을 체크합니다. 최근 12개월(장기)의 누적 수익률이 양수인지, 그리고 최근 3개월(단기)의 누적 수익률이 양수인지를 봅니다. 둘다 양수여야만 절대 모멘텀 필터를 통과할 수 있습니다.
그 다음으로 상대 모멘텀은 3가지 기준을 체크합니다. 최근 12개월/3개월/1개월 상대 수익률은 몇 등이었는지를 체크하고, 각각을 20%, 30%, 50% 가중치로 합산합니다. 이렇게 12개월에서 최근 1개월로 올수록 가중치를 높게 주는 방식은, 가장 최근에 주가 상승이 좋았던 종목에게 좀 더 높은 점수를 주겠다는 뜻이기도 합니다.
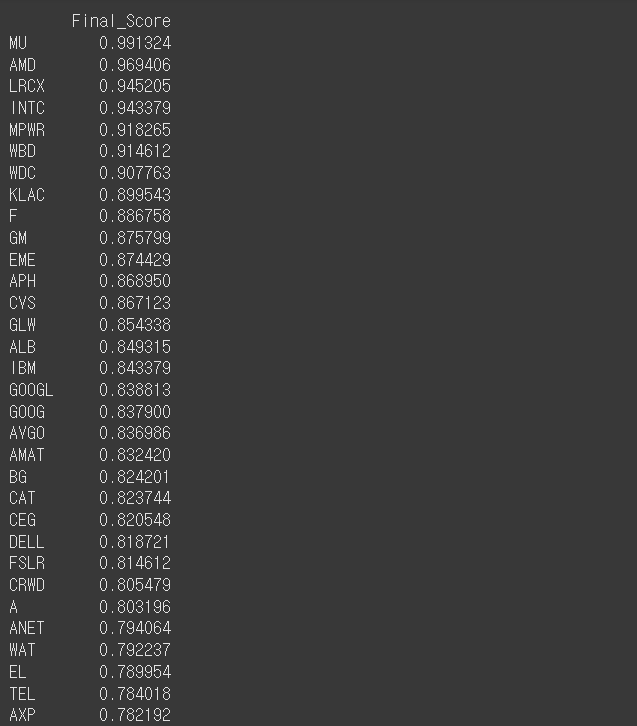
이렇게 두 번의 모멘텀을 체크하고 나면, 최종 결과물은 0과 1 사이의 값으로 산출됩니다. 1에 가까울수록 모멘텀이 좋은 종목이고, 0에 가까울수록 안 좋은 종목들입니다. 여기서는 전체 종목들 중 상위 10%, 그러니까 50종목만을 추출하기로 했습니다. 위 이미지는 상위권 종목들의 리스트입니다. (누차 말씀드리지만 투자의 책임은 각자의 몫...!)
STEP 3. 퀀트 필터 2: 포트폴리오 상관관계 분석
S&P500 종목에서 시작해서 50개 종목까지로 줄였습니다. 그렇지만 여전히 개인 투자자에게는 너무나 많은 수의 종목들입니다. 그리고 또 하나 간과하면 안 되는 부분이 바로 '포트폴리오 궁합'입니다.
대다수의 개인 투자자들은 이미 보유하고 있는, 혹은 적립식으로 매수 중인 ETF 종목들이 있을 것입니다. 가령 나스닥 ETF인 QQQ를 들고 있다면, 나머지 개별 종목으로 전부 기술주만 보유하기에는 다소 부담스러운 면이 있습니다. 만에 하나 기술주가 폭락하기 시작한다면 전종목이 큰 타격을 입을 테니까요.
이런 일을 대비하기 위해 퀀트 전문가들은 종목들 간의 상관관계(Correlation) 체크를 매우 중요시 여깁니다. 상관관계란 두 자산이 얼마나 비슷하게 혹은 다르게 움직이는지를 측정하는 통계 지표입니다. +1에 가까울수록 두 자산이 같은 방향으로 움직이는 경우가 많고, -1에 가까울수록 두 자산이 반대로 움직이는 경우가 많습니다.
물론 상관관계가 곧 인과관계인 것은 아니고 또 자산군이 여럿일 때는 수식이 좀 더 복잡해지지만, 최대한 단순화해서 설명하자면, 분산 투자 효과를 극대화하기 위해서는 종목들 간의 correlation이 낮을수록 좋습니다. (이에 관한 보다 이론적인 설명은 다음에 다시 다루겠습니다)
df_mom = temp[top_mom].copy()
etf_list = yf.download(['QQQ', 'GLD'], start=start_date)['Close']
window = 63 # 최근 3개월 영업일
threshold = 0.7 ## Correlation 임계값
corr_df = pd.concat([df_mom, etf_list], axis=1)[-window:].corr()
corr_df[(corr_df['QQQ'] < threshold) & (corr_df['GLD'] < threshold)][['QQQ', 'GLD']]여기서는 전제로 QQQ(나스닥 ETF)와 GLD(금 ETF), 두 종목을 이미 포트폴리오에 담고 있다고 가정했습니다. 앞서 필터링을 통과한 상위 모멘텀 50 종목 중에서, 이 두 ETF와의 상관계수가 모두 0.7 이하인 종목만을 필터링 하도록 설정했습니다.
(여기서 상관계수는 최근 며칠 분의 데이터를 볼 것인지, 그리고 임계값을 -1에서 1 사이의 값 중 어느 정도로 설정할 것인지에 따라 결과물이 달라질 수 있습니다. 정해진 정답은 없으니 어디까지나 참고만 하시기 바랍니다.)
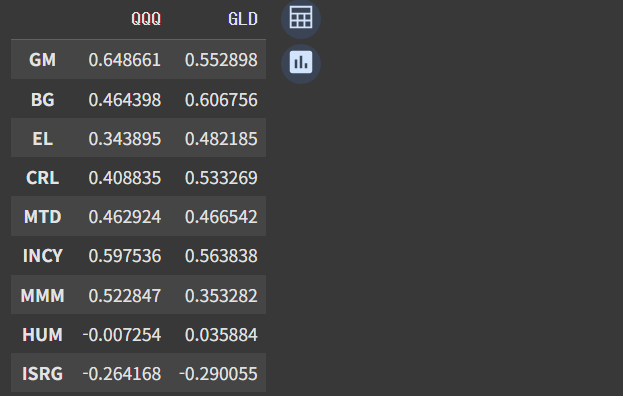
이렇게 두 번째 필터까지 거치고 나면 최종 후보들의 티커를 확인할 수 있습니다. 10월 24일자 기준으로는 최종 후보에 9개 종목이 올랐습니다. (종목의 개수는 해당 코드를 실행시키는 일자마다 상이할 수 있습니다.)
STEP 4. API를 활용한 재무 보고서 수집
이제 최종 후보 종목들의 펀더멘탈 분석을 위한 재무 보고서 수집을 해야 합니다. 사실 종목 개수가 많지 않으므로 하나씩 직접 찾아서 다운로드 받는 것도 방법이겠습니다만, 필터링을 어떻게 주느냐에 따라서 종목 개수가 30개 가까이 늘어날 때도 있으므로 여기서는 자동화 방법을 소개해보겠습니다.
우선 미국 모든 기업들이 연간, 분기 단위로 제출하는 SEC 보고서는 API를 통해 수집이 가능합니다. 이 링크에 들어가서 회원가입을 한 뒤에 Free Api Key를 생성하면, 누구나 손쉽게 사용이 가능합니다.
from sec_api import QueryApi
# 1. API 키를 입력하세요.
api_key = '' ## 각자의 API 키를 입력
# 2. QueryApi 객체 초기화
queryApi = QueryApi(api_key=api_key)
url_list = []
port_universe = ['GM', 'BG', 'EL', 'CRL', 'MTD', 'INCY', 'MMM', 'HUM', 'ISRG']
for ticker in port_universe:
# 3. 조회할 종목 설정
ticker_to_search = ticker
# 4. 가장 최근의 10-Q 혹은 10-K 보고서 1개를 가져오는 쿼리 정의
query = {
"query": { "query_string": {
"query": f"ticker:{ticker_to_search} AND (formType:\"10-Q\" OR formType:\"10-K\")"
} },
"from": "0",
"size": "1", # 1개만 가져오기
"sort": [{ "filedAt": { "order": "desc" } }] # 최신순(descending)으로 정렬
}
# 5. API 요청 실행
try:
response = queryApi.get_filings(query)
if response['filings']:
latest_filing = response['filings'][0]
print(f"--- {latest_filing['ticker']}의 가장 최신 재무 보고서 (10-Q 또는 10-K) ---")
print(f"회사명: {latest_filing['companyName']}")
print(f"제출일: {latest_filing['filedAt']}")
print(f"보고서 기간: {latest_filing['periodOfReport']}")
print(f"보고서 원본 URL: {latest_filing['linkToFilingDetails']}")
# 다음 단계를 위해 보고서 URL 저장
filing_url = latest_filing['linkToFilingDetails']
url_list.append(filing_url)
else:
print(f"{ticker_to_search}의 재무 보고서를 찾을 수 없습니다.")
filing_url = None
except Exception as e:
print(f"API 요청 중 오류 발생: {e}")
filing_url = None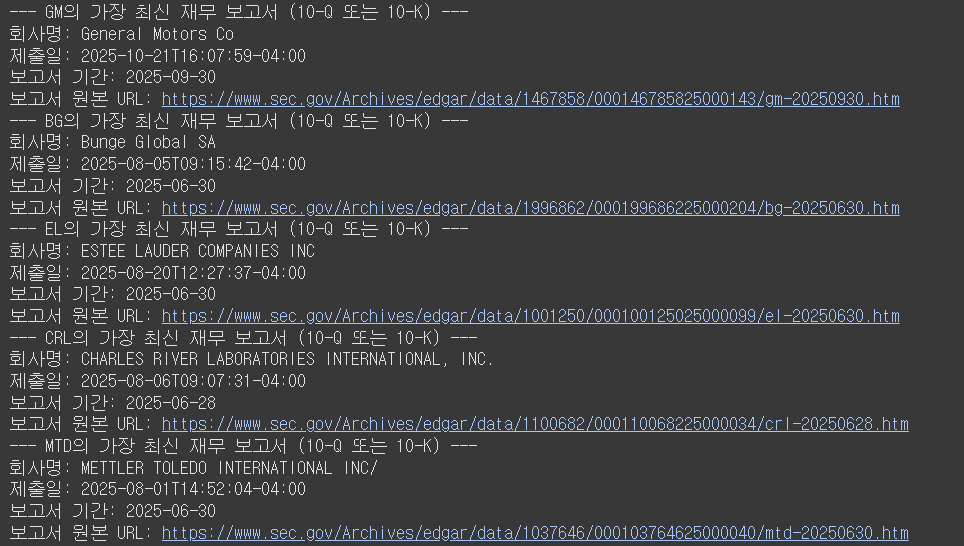
다만 해당 API로는 파일들을 직접 다운로드 하는 건 어렵고, 접속할 수 있는 웹 링크까지만 제공된다는 한계점이 있습니다. 아쉽게도 Gemini는 해당 링크들에 접근을 못하고(2025년 10월 기준), GPT와 Claude는 접근이 가능합니다. 다만 Claude는 토큰이 워낙 금방 사용되어서 가성비가 썩 좋지는 않습니다. 때문에 여기서는 GPT로 접근해보기로 했습니다.
STEP 5. GPT-5를 활용한 펀더멘탈 분석
수집한 9개의 SEC 보고서와 자체적으로 제작한 시스템 프롬프트 파일을 GPT에게 첨부하고 동작시켜보았습니다. 시스템 프롬프트 전문이 400줄 가량 되다 보니 전부를 보여드릴 순 없겠지만, 지난 번 뉴스레터와 유사한 방식으로 제작했음을 알려드립니다. (혹시 해당 프롬프트가 궁금하신 분은 댓글을 남겨주시면 이메일로 공유드리도록 하겠습니다)
시스템 프롬프트의 전체 프로세스를 요약해보자면 다음과 같습니다.
1. 역할 정의: 전문 기업 분석가 & 투자 전문가로서의 역할 부여
2. 데이터 추출 지침: 매출, 영업이익, 현금흐름 등 핵심 데이터만 추출하도록 제한하여 토크 효율성 제고
3. 평가 기준 제시: 성장성, 재무건전성, 밸류에이션 등 5가지 평가 기준 및 배점 설정
4. 근거 기반 분석: 모든 분석 내용에 SEC 보고서 내의 해당 페이지 출처를 명시하도록 요구
5. 최종 추천: 종합 점수 기반으로 top3 종목 선정 및 투자 논리 요약

이렇게 펀더멘탈 분석을 진행한 결과, GPT는 9개의 후보들 중 최종 3개의 종목을 뽑아내는데 성공했습니다. 물론 아직 SEC 공시를 하지 않은 기업들도 있기 때문에 해당 방법론이 좀 더 유의미해지기 위해서는 보완이 필요할 것입니다.
(또 한 번 언급하지만, 모든 투자는 개인의 몫입니다...!)
결론: 복합적인 투자 전략 시대
이번 뉴스레터에서는 '이 투자 방법론이 정답입니다'를 말씀드리는 게 목적이 아니었습니다. 제가 보여드린 것은 어디까지나 예시일 뿐, '이제는 누구나 쉽게 자기만의 투자 전략을 만들고 개량해나갈 수 있다'는 걸 말씀드리고 싶었습니다.
AI를 맹목적으로 믿은 채 투자를 진행하는 것은 위험합니다. 그렇다고 AI의 압도적인 퍼포먼스와 분석 능력을 아예 방치하는 것 또한 여러모로 비효율적입니다. 할루시네이션이 걱정된다면 확실히 믿을 만한 정보(ex. SEC보고서)만을 AI에게 주면 되고, 그 앞단의 분석은 자체적인 분석 로직(ex. 듀얼 모멘텀)을 줌으로써 해결 가능합니다.
결국 새로운 기술과 프레임워크가 쏟아지는 시대에, 어떤 기술의 어떤 장점만을 긁어와서 나만의 방법론으로 개선해나갈지는 각자의 몫일 것입니다. 그 여정에 이번 뉴스레터가 작은 도움이나마 되었길 바랍니다.
오늘도 읽어주셔서 감사합니다.
의견을 남겨주세요
명문
비공개 댓글 입니다. (메일러와 댓글을 남긴이만 볼 수 있어요)
PRAESENTIA
비공개 댓글 입니다. (메일러와 댓글을 남긴이만 볼 수 있어요)
의견을 남겨주세요
Judy
비공개 댓글 입니다. (메일러와 댓글을 남긴이만 볼 수 있어요)
PRAESENTIA
비공개 댓글 입니다. (메일러와 댓글을 남긴이만 볼 수 있어요)
의견을 남겨주세요
정수
비공개 댓글 입니다. (메일러와 댓글을 남긴이만 볼 수 있어요)
의견을 남겨주세요