
MZ세대의 여행, 무엇이 달라졌을까?
안녕하세요, BDA 서베이-리포트팀입니다 :)
BDA는 매월 트렌디한 주제를 선정하여 Z세대의 인사이트를 데이터로 분석한 TrendZ 리포트를 발행하고 있습니다. 이번 4월 리포트는 "MZ세대의 여행 트렌드 및 AI 서비스 만족도 조사"를 주제로 하여, 실제 해외여행을 다녀온 20대 응답자들의 생생한 경험과 니즈를 담아냈습니다.
이번 조사는 BDA 학회원 917명 중 211명을 대상으로 실시되었으며, 2025년 4월 5일부터 4월 8일까지 총 4일 간 구글폼을 통해 진행되었습니다. 응답자는 모두 20대 대학생으로, 해외여행 경험과 앱/AI 활용 경험을 기반으로 여행에 대한 다층적인 분석이 이루어졌습니다.
MZ세대는 왜 여행을 떠날까요?
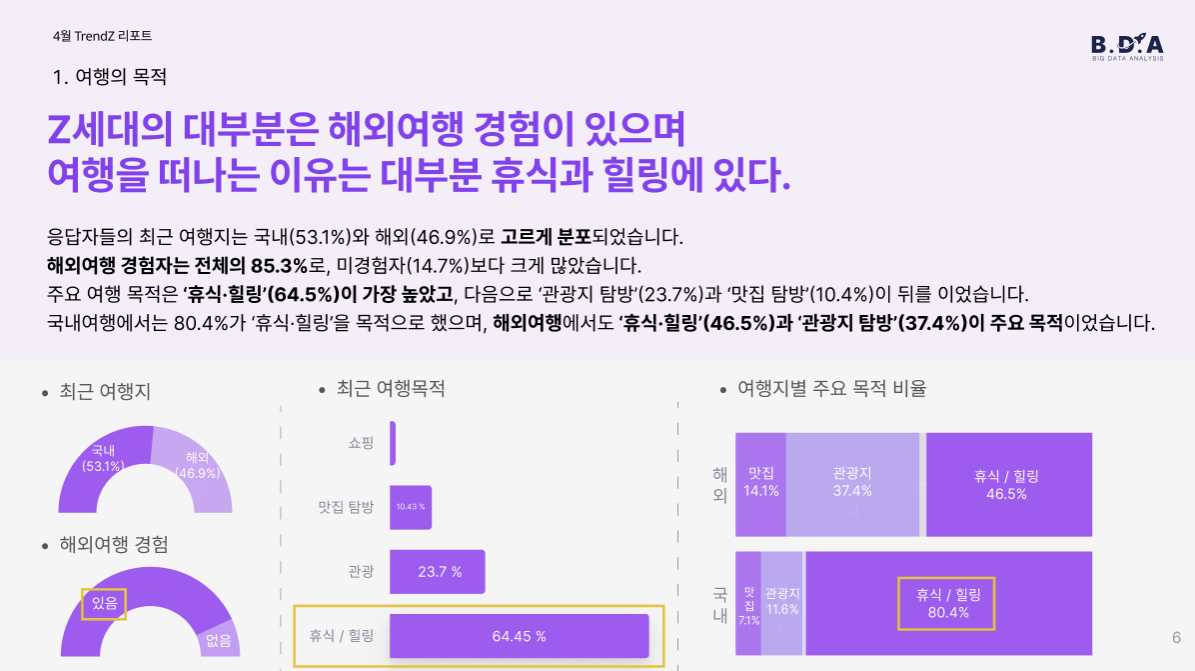
응답자 중 85.3%가 해외여행 경험이 있었고, 그 목적 중 가장 많은 비중을 차지한 이유는 ‘휴식과 힐링’(64.5%)이었습니다. 관광(23.7%), 맛집 탐방(10.4%)도 뒤를 이었지만, 여행의 핵심은 ‘쉼’에 있었다는 점이 인상 깊습니다.
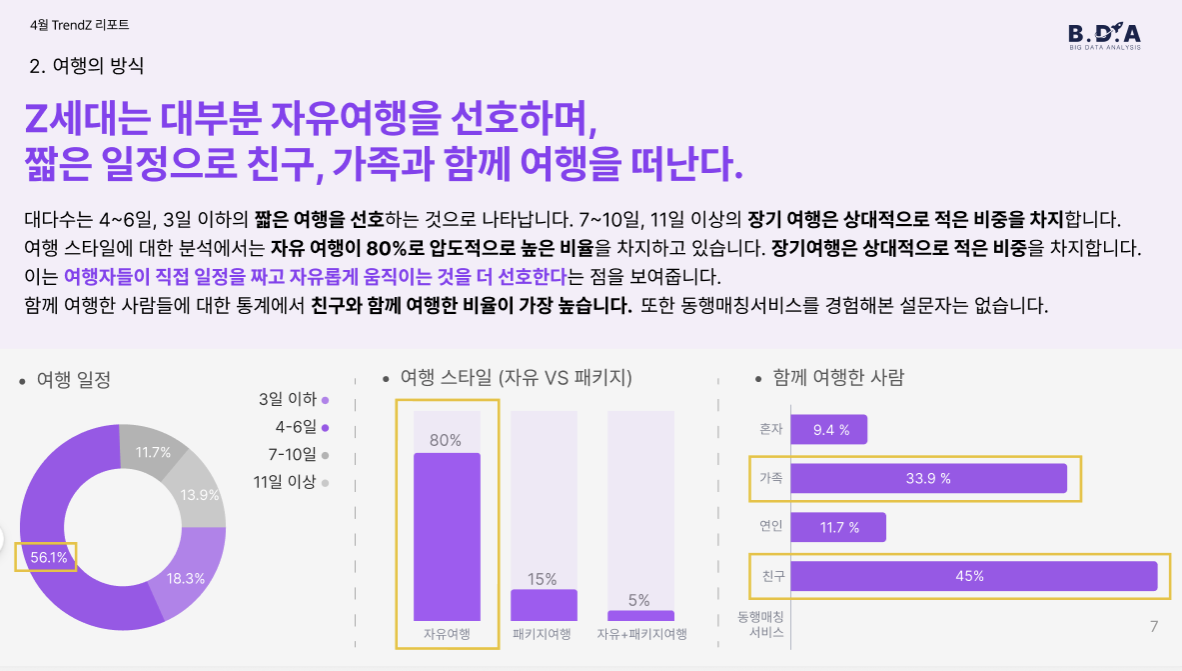
여행 스타일 또한 흥미로웠습니다. 응답자의 80%가 자유여행을 선호했으며, 여행 기간은 4~6일의 중단기 여행이 가장 일반적이었습니다. 함께한 사람은 ‘친구’가 45%로 1위였고, ‘연인’, ‘가족’ 순으로 이어졌습니다.
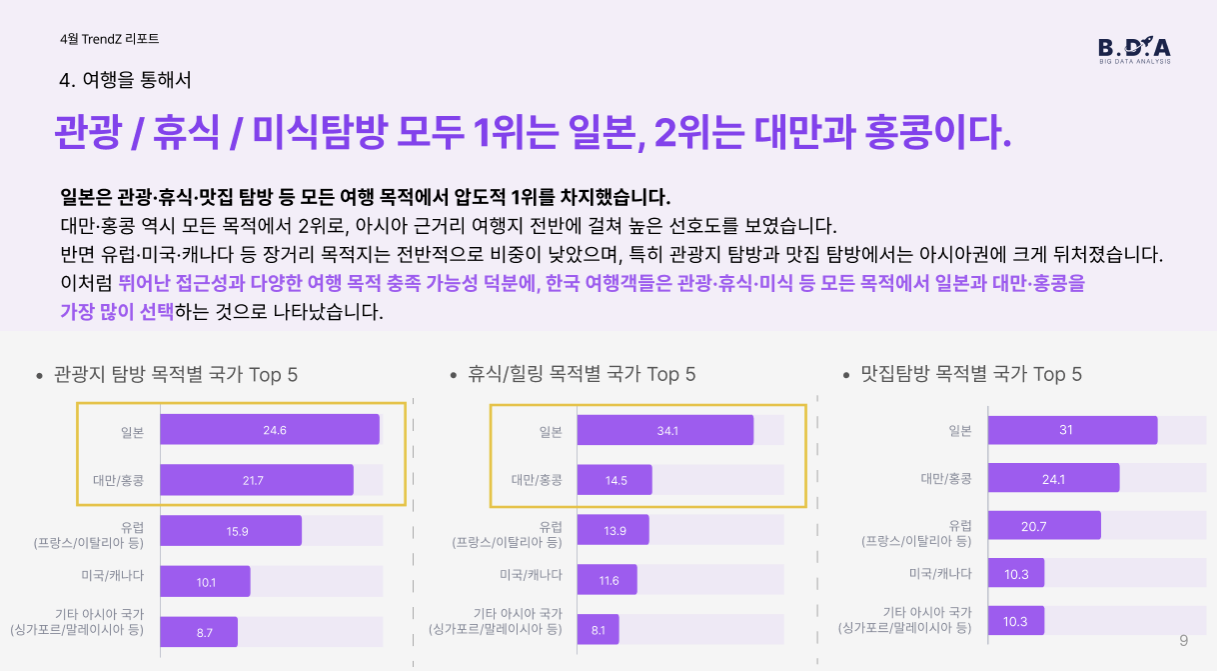
여행 국가로는 ‘일본’이 85명으로 압도적인 선택을 받았으며, 그 뒤로 유럽, 대만/홍콩이 비슷한 비중으로 나타났습니다. 여행 목적에 관계없이 일본과 대만/홍콩이 가장 높은 선호도를 보였으며, 유럽·미국은 장기 여행에 한정적으로 선택되는 경향이 있었습니다.
한편, MZ세대의 여행에는 현실적인 고민도 많았습니다.
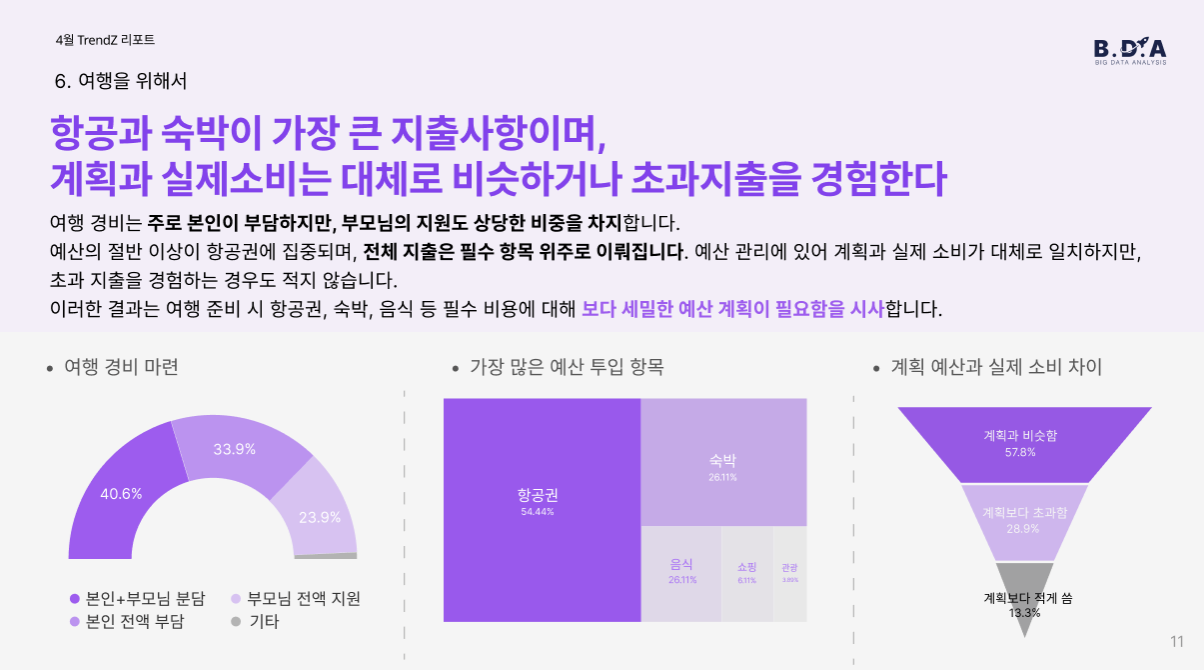
여행 경비는 주로 본인+부모님 분담(40.6%)으로 마련되며, 예산의 절반 이상이 항공권에 투입(54.4%)되는 것으로 나타났습니다. 계획과 실제 소비가 비슷한 경우가 많았지만, 초과 지출을 경험한 응답자도 28.9%에 달했습니다.
해외여행의 가장 큰 장벽은 무엇일까요?
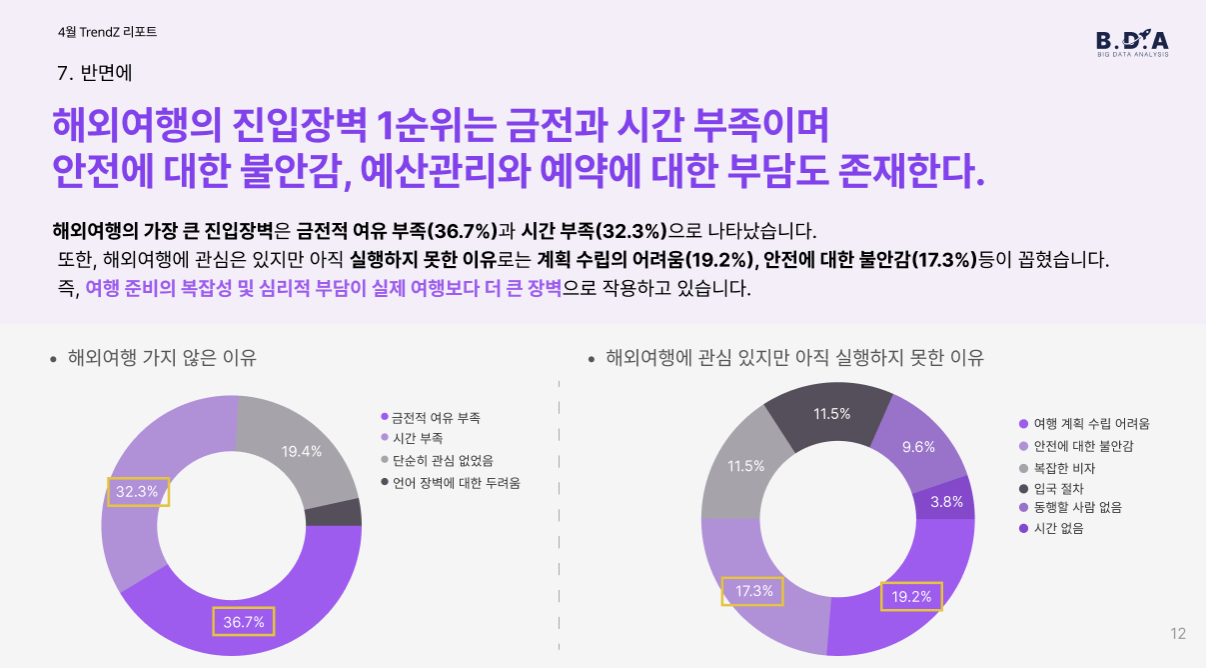
금전적 여유 부족(36.7%), 시간 부족(32.3%), 그리고 계획 수립의 어려움(19.2%)이 상위를 차지했습니다. 특히 해외여행 경험이 없는 이들에게는 언어 장벽, 동행자 부재 등이 복합적인 심리적 부담으로 작용하고 있었습니다.
이러한 현실 속에서 AI 서비스에 대한 기대는 높았습니다.
AI에게 바라는 기능으로는 여행 스타일 기반 예산 추천(41.1%), 예상 경비 자동 계산(31.1%), 가성비 소비 분석과 실시간 환율 반영 등이 주목을 받았습니다. 실제로 응답자의 다수는 가격 비교, 예산 배분, 환율 반영 등에서 큰 어려움을 겪고 있었습니다.
또한 여행 앱 및 결제 수단에 대한 활용도 분석도 포함되었습니다.
결제 방식은 카드와 현금이 주류를 이루었고, 환전은 모바일 앱(트래블월렛 등)과 은행이 주요 수단이었습니다. 교통앱 사용률은 아직 높지 않았으며, 번역 앱 중에서는 Papago의 독보적인 사용률(125명)이 눈에 띄었습니다.
그렇다면 여행 중 가장 불편했던 점은 무엇일까요?

교통 문제(50.6%), 언어 소통(21.7%), 날씨 정보 부족(11.7%)이 주요 이슈였습니다. 이에 대해 응답자들은 AI가 실시간 교통 연결 최적화, 날씨 기반 일정 조정, 긴급 상황 대응 등의 기능을 제공해주길 희망했습니다.
흥미롭게도, AI 기반 여행 서비스를 사용해본 경험은 아직 낮았지만(138명 중 과반이 미사용), 향후에는 서비스를 사용하겠다는 의향이 매우 높게 나타났습니다.
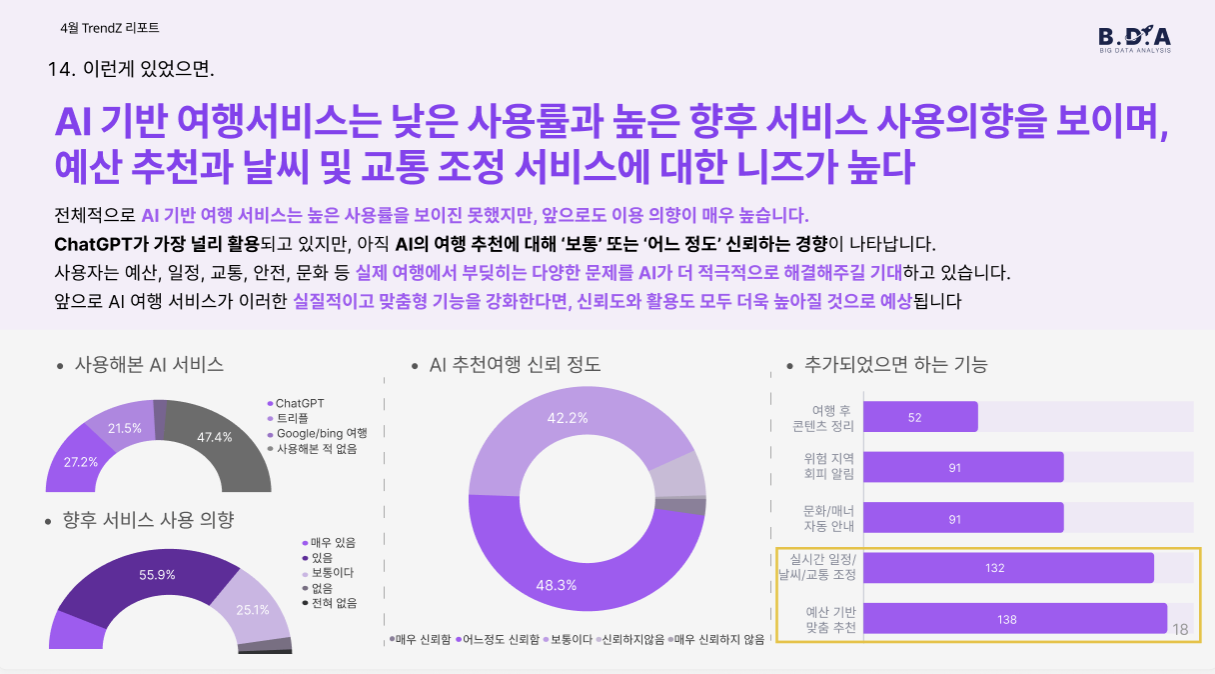
응답자들은 특히 예산 기반 맞춤 추천, 실시간 일정/교통 조정, 위험 지역 회피 알림, 문화/매너 자동 안내 기능이 탑재되길 바라고 있었습니다.
이번 TrendZ 리포트를 통해 MZ세대의 여행은 단순한 '경험'을 넘어, 계획부터 소비, AI에 대한 기대까지 매우 실용적이고 데이터 중심적인 특징을 가진다는 점이 드러났습니다.
여행산업 또는 AI기반 플랫폼 서비스 기획에 관심 있는 모든 분들께 이번 리포트가 실질적인 인사이트로 작용하길 바랍니다.
다음 달 TrendZ도 기대해주세요!
리포트 전문은 아래 BDA REPORT 페이지에서 확인해보실 수 있습니다 :)
5월 4주차 DATA 트렌드 인사이트 🧐
Attention Is All You Need를 읽기 위한 준비 — RNN에서 Transformer까지 (3/5)
Seq2Seq (Sequence to Sequence)의 Encoder-Decoder 구조
Seq2Seq (Sequence to Sequence)란?
Seq2Seq(Sequence-to-Sequence) 모델은 이름 그대로 하나의 시퀀스(입력 시퀀스)를 다른 시퀀스(출력 시퀀스)로 변환(mapping) 하는 딥러닝 모델 구조입니다.
입력과 출력의 길이가 서로 다를 수 있으며, 시계열 정보나 순서를 고려한 학습이 필요할 때 사용됩니다.
대표적인 예로 기계 번역(Machine Translation), 질문 답변 시스템(Q&A System), 텍스트 요약(Text Summarization) 등이 있습니다.
예를 들어:
- 입력: “How are you?” → 출력: “잘 지내세요?”
Encoder-Decoder 구조
Seq2Seq의 핵심 구조는 Encoder와 Decoder로 구성됩니다.
| 컴포넌트 | 설명 |
| Encoder | 입력 시퀀스를 벡터로 **압축(Encoding)**하여 의미를 추출 |
| Context Vector | Encoder가 만든 고정 크기 벡터로, 입력 시퀀스의 요약정보 |
| Decoder | Context Vector를 디코딩 하여 출력 시퀀스 생성 |
구조 흐름:
- Encoder:
- 입력 시퀀스(예: 문장)를 RNN, LSTM, GRU 등의 구조로 하나씩 읽음
- 최종 hidden state가 전체 문장의 의미를 요약한 Context Vector가 됨
2. Decoder:
- Context Vector를 초기 상태로 설정하고, 첫 토큰(예: )부터 시작
- 다음 단어를 하나씩 생성하며 출력 시퀀스를 만듦
Context Vector의 한계
기존 Seq2Seq는 입력 시퀀스 전체를 하나의 벡터(Context Vector)로 요약합니다. 이로 인해 발생하는 주요 문제는 다음과 같습니다:
- 정보 압축 손실:긴 문장의 경우, 앞의 정보와 뒤의 정보가 동등하게 반영되지 못함
- 장기 의존성 문제 (Long-Term Dependency):긴 문장에서 초반 정보는 잘 전달되지만, 후반 정보는 무시되기 쉬움
예시:
“The weather today is quite nice, but I heard it might rain tomorrow, so make sure to bring an umbrella.”
위 문장을 번역한다고 했을 때, Context Vector 하나에 이 모든 정보를 담기 어려워,
→ Decoder가 문장 후반부(‘umbrella’ 등)를 잘 생성하지 못할 가능성이 높아짐
한계를 극복하는 방식 – Attention Mechanism
이러한 한계를 보완하기 위해 Attention 구조가 도입되었습니다.
- Attention Mechanism은 Decoder가 출력 시각마다 Encoder의 전체 hidden states를 참조하게 하여,
- 긴 문장에서도 중요한 입력 정보에 더 집중할 수 있도록 합니다.
이로써 “모든 정보를 한 벡터에 압축”하는 구조에서
“출력마다 동적으로 입력을 바라보는 구조”로 발전
활용 사례
- 기계 번역 (Machine Translation): 영어 ↔ 한국어 번역
- 질문 답변 시스템 (Q&A System): ChatGPT와 같은 챗봇
- 음성 인식 (Speech Recognition): 음성을 텍스트로 변환
결론
Seq2Seq는 입력 시퀀스를 이해하고, 새로운 시퀀스로 생성하는 강력한 구조입니다.
하지만 Context Vector에 정보를 압축하는 데 한계가 있어,
→ Attention, Transformer 등의 구조로 발전하고 있습니다.
➡ 오늘날 대부분의 고급 자연어 처리 모델은 이 Seq2Seq 구조를 기반으로 확장된 형태입니다.
다음 뉴스레터 예고:
“Attention Mechanism: 중요한 정보를 선택적으로 집중하다”
Attention이 어떻게 Seq2Seq의 한계를 극복하고 Transformer로 이어졌는지 살펴봅니다.
[출처 및 참고]
- Encoder-Decoder Seq2Seq Models, Clearly Explained!! - Medium
- Seq2Seq Model in Machine Learning - GeeksforGeeks
작성: 6기 서베이-리포트팀 박찬규, 신미수, 양지호
의견을 남겨주세요