
Introduction
여러분, 혹시 최근 시스템 설계 면접을 보신 적 있나요? 그렇다면 이런 질문을 받아보셨을 겁니다.
대량의 비동기 메시지를 어떻게 처리하시겠습니까?
실패한 트랜잭션을 어떻게 재시도하시겠습니까?
이런 질문들은 모두 이벤트 드리븐 아키텍처에 대한 지식을 테스트하는 것인데요.

사실 이런 질문들은 단순히 면접을 위한 것이 아닙니다. 실제 대규모 시스템을 설계할 때 마주치는 핵심적인 문제들이죠. 그런데 여기 놀라운 사실이 있습니다. 이 모든 문제를 단 세 가지 패턴만 알면 해결할 수 있다는 것입니다!
오늘은 사우라브 다쇼라가 발표한 "3 Interview Questions on Event-Driven Patterns" 글을 번역해 왔습니다. 이 글에서는 경쟁 소비자 패턴, 메시지 재시도 패턴, 그리고 비동기 요청-응답 패턴을 상세히 다루고 있는데요.
이 세 가지 패턴만 제대로 이해하고 있다면, 여러분은 이미 시스템 설계 면접의 절반은 통과한 셈입니다. 더 나아가 실제 프로젝트에서도 이 패턴들을 적용해 복잡한 문제들을 우아하게 해결할 수 있죠.
자, 그럼 이제 이 세 가지 마법의 패턴에 대해 자세히 알아보겠습니다. 이 글을 읽고 나면, 여러분도 면접관을 감탄시키는 것은 물론, 실무에서도 당당히 이벤트 기반 시스템을 설계할 수 있을 겁니다.
이벤트 드리븐 패턴에 관한 3가지 면접 질문
요즘 시스템 설계 면접에서는 종종 지원자의 이벤트 기반 시스템에 대한 지식을 테스트합니다. 특히 이미 이러한 시스템을 다뤄본 경험이 있고 이를 이력서에 언급했다면 더욱 그렇습니다.
오늘은 면접에서 반드시 알아야 할 세 가지 이벤트 드리븐 패턴에 대해 살펴보겠습니다. 이 내용은 꼭 면접이 아니더라도 여러분이 하고계신 프로젝트에 역시 도움이 될 수 있습니다.
1. 경쟁 소비자 패턴(Competing Consumer Pattern)
이 패턴과 관련해 다음과 같은 질문이 나올 수 있습니다:
"대량의 비동기 메시지를 여러 소비자에게 어떻게 로드 밸런싱할 수 있을까요?"
가장 간단한 접근 방식은 소비자들이 서로 경쟁하도록 하는 것입니다. 이를 경쟁 소비자 패턴이라고도 합니다[다이어그램은 Eraser.io에서 확인 가능합니다].
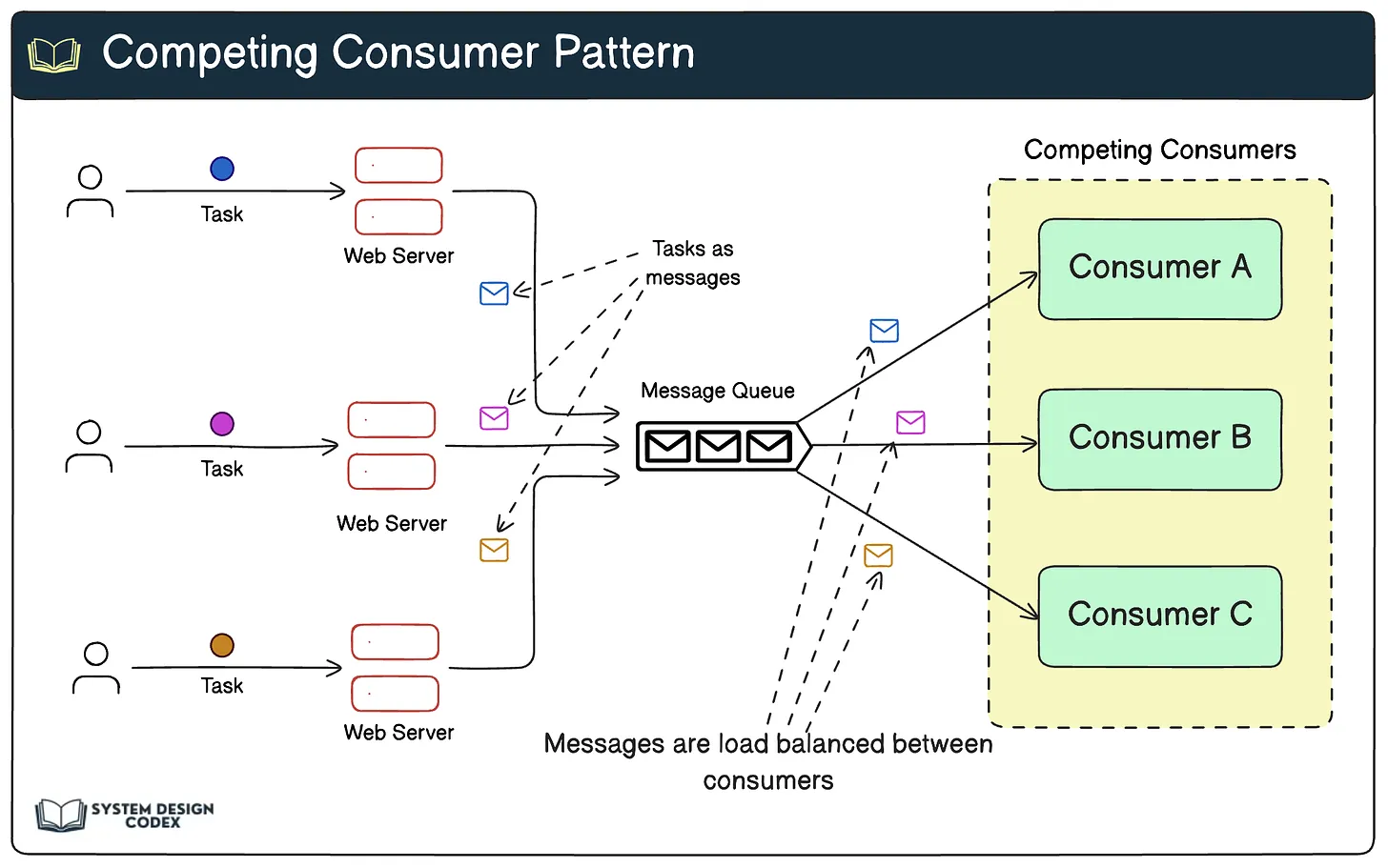
작동 방식:
- 하나 이상의 생산자가 큐에 메시지를 추가합니다. 이 메시지들은 수행해야 할 작업과 같습니다.
- 이 큐의 메시지나 작업을 처리하기 위해 여러 소비자 인스턴스가 설정됩니다.
- 각 소비자는 메시지를 검색하고 처리하기 위해 경쟁합니다.
- 소비자가 메시지를 성공적으로 가져가면 다른 소비자들은 해당 메시지를 사용할 수 없게 됩니다.
- 처리 후, 소비자는 메시지를 확인하고 큐에서 제거합니다.
보시다시피 프로세스는 간단합니다. 그러나 중요한 점은 메시지가 오직 하나의 소비자에 의해서만 처리되도록 보장하는 것입니다. 다시 말해, 소비자가 가져간 메시지를 어떻게 다른 소비자들이 사용할 수 없게 만드는가입니다?
다양한 플랫폼에서 이를 다르게 처리하는데요.
RabbitMQ는 프리페치 카운트(prefetch count)를 사용합니다
- 소비자들은 프리페치 카운트를 설정하여 확인되지 않은 메시지의 수를 제한합니다.
- 소비자가 메시지를 받으면 "전송 중(in flight)"으로 간주되어 다른 소비자에게 전달되지 않습니다.
Azure Service Bus는 피크-락(peek-lock) 메커니즘을 사용합니다
- 소비자는 피크-락 모드로 메시지를 받아 메시지를 잠급니다.
- 메시지는 큐에 남아있지만 다른 소비자에게는 보이지 않습니다.
- 처리 후, 소비자는 완료로 표시합니다.
- 잠금이 만료되면 메시지가 다시 보이게 됩니다.
AWS SQS는 가시성 타임아웃(visibility timeout)을 설정합니다
- 소비자가 메시지를 받으면 SQS는 가시성 타임아웃을 설정합니다.
- 이 타임아웃 동안 메시지는 다른 소비자에게 숨겨집니다. 처리 후, 소비자는 메시지를 삭제합니다.
- 메시지가 삭제되기 전에 타임아웃이 만료되면 다른 소비자에게 다시 보이게 됩니다.
2 .메시지 재시도 패턴(Retry Messages Pattern)
이 패턴에 관한 질문은 보통 이렇게 나옵니다:
"메시지 큐를 사용하여 실패한 트랜잭션을 어떻게 재시도할 수 있을까요?"
이는 일시적인 오류를 처리하기 위한 일반적인 패턴인데요. 결제 처리를 예로 들어 이해해 봅시다.
메시지 큐를 사용한 재시도 메커니즘 구현의 일반적인 접근 방식은 세 가지 주요 부분으로 구성됩니다:
- 메인 큐: 새로운 결제 트랜잭션이 대기하는 곳입니다.
- 데드 레터 큐(Dead Letter Queue, DLQ): 여러 번 처리에 실패한 메시지를 위한 별도의 큐입니다.
- 재시도 큐: 지연을 두고 재시도를 예약하는 곳입니다. 이 큐는 선택사항이며 메인 큐를 사용할 수도 있습니다.
다음 다이어그램을 참조하세요([다이어그램은 Eraser.io에서 확인 가능합니다]).
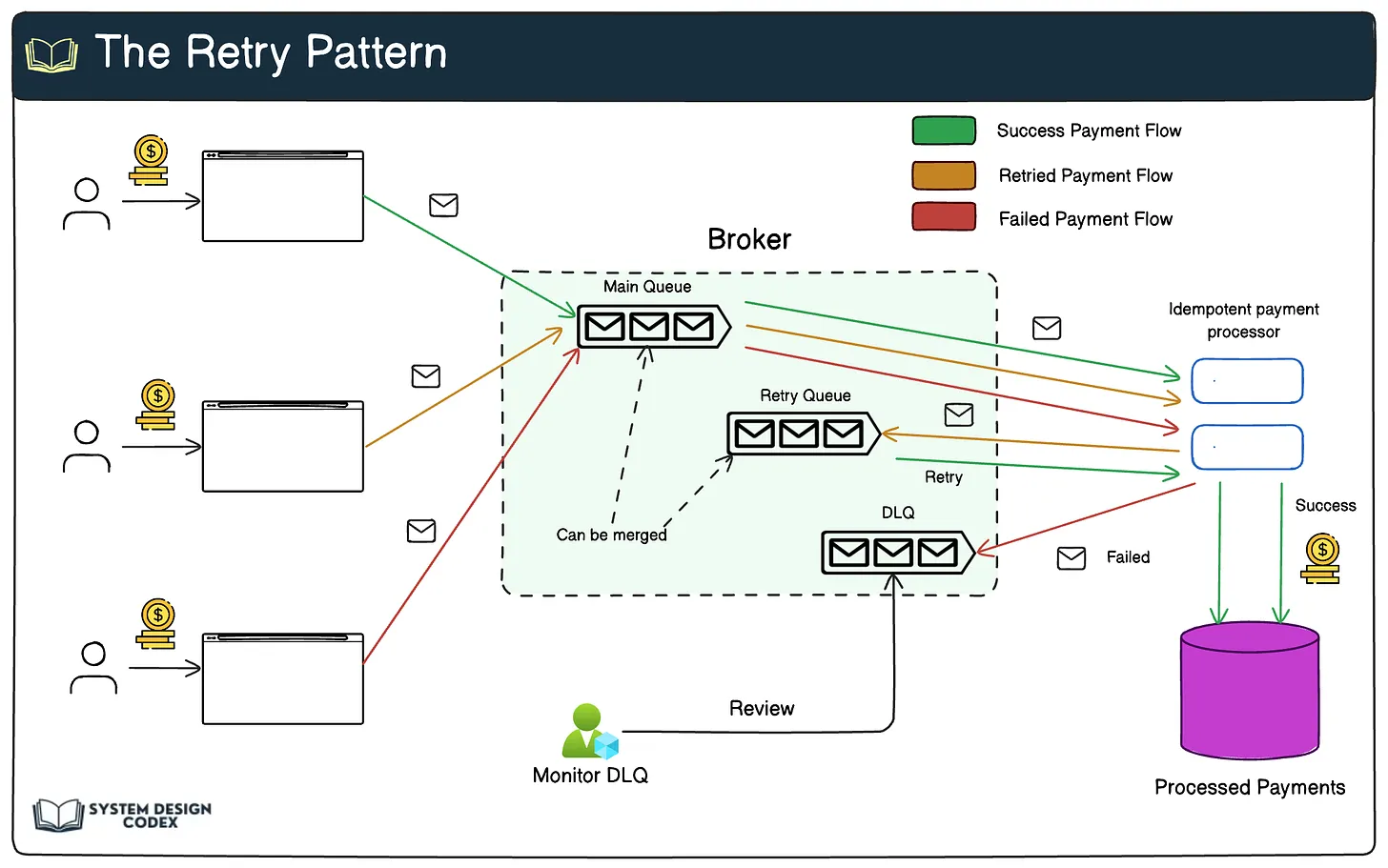
프로세스 작동 방식:
- 소비자 또는 결제 프로세서가 메인 큐에서 메시지를 가져옵니다. 결제 트랜잭션 처리를 시도합니다.
- 처리에 실패하면 메시지 메타데이터에 저장된 재시도 횟수를 확인합니다.
- 재시도 횟수 < 최대 재시도 횟수인 경우, 횟수를 증가시키고 메시지를 다시 큐에 넣습니다.
- 재시도 횟수 ≥ 최대 재시도 횟수인 경우, 메시지를 DLQ로 이동합니다.
- 재시도의 경우, 지연을 두고 메인 큐에 직접 다시 넣거나 시간 기반 트리거가 있는 별도의 재시도 큐를 사용할 수 있습니다.
- 마지막으로, 재시도 시도를 모두 소진한 메시지에 대해 DLQ를 모니터링합니다. 이를 처리하기 위한 프로세스를 구현합니다.
이 패턴을 사용할 때 반드시 명심해야 할 몇 가지 고려사항이 있어요.
👉 지수 백오프(Exponential Backoff): 시스템에 과부하가 걸리지 않도록 재시도 간 지연을 지수적으로 증가시킵니다.
👉 멱등성(Idempotency): 결제 프로세서가 경제를 망치지 않고 안전하게 결제를 재시도할 수 있도록 합니다.
👉 메시지 TTL: 매우 오래된 트랜잭션이 처리되지 않도록 메시지에 전체 TTL을 설정합니다.
👉 재시도 제한: 최대 재시도 횟수 값을 설정합니다.
👉 오류 유형: 일시적 오류(재시도 가능)와 영구적 오류(DLQ로 직접 이동)를 구분합니다.
3 - 비동기 요청-응답 패턴(Async Request Response Pattern)
이 패턴에 관한 질문은 이렇게 나옵니다:
"메시지 큐로 요청-응답 통신을 어떻게 처리할 수 있을까요?"
먼저 이것이 왜 필요한지 이해해야 합니다.
메시지 큐를 사용하면 두 서비스가 비동기적으로 통신(요청-응답)할 수 있습니다. 이 접근 방식은 장시간 실행되는 작업에 매우 중요합니다. 또한 동기식 호출이 없기 때문에 단일 서비스가 애플리케이션을 중단시킬 가능성이 줄어듭니다.
하지만 문제가 있습니다. 만약 요청자와 응답자 인스턴스가 여러 개라면 어떻게 될까요?
동기식 REST API 호출에서는 이것이 크게 문제되지 않습니다. 하나의 요청자 인스턴스가 항상 하나의 응답자 인스턴스에만 연결되기 때문입니다. 즉, 커플링이 만들어지죠.
하지만 비동기 요청-응답에서는 그렇지 않습니다.
요청을 한 요청자 인스턴스가 최종적으로 응답을 받는 인스턴스가 아닐 수 있습니다. 응답이 돌아올 때쯤에는 해당 인스턴스가 중단되거나 사용할 수 없게 될 수 있습니다.
그렇다면 - 여러 임시 인스턴스에서 요청과 응답을 어떻게 연관시킬 수 있을까요?
다음 다이어그램을 참조하세요([다이어그램은 Eraser.io에서 확인 가능합니다])
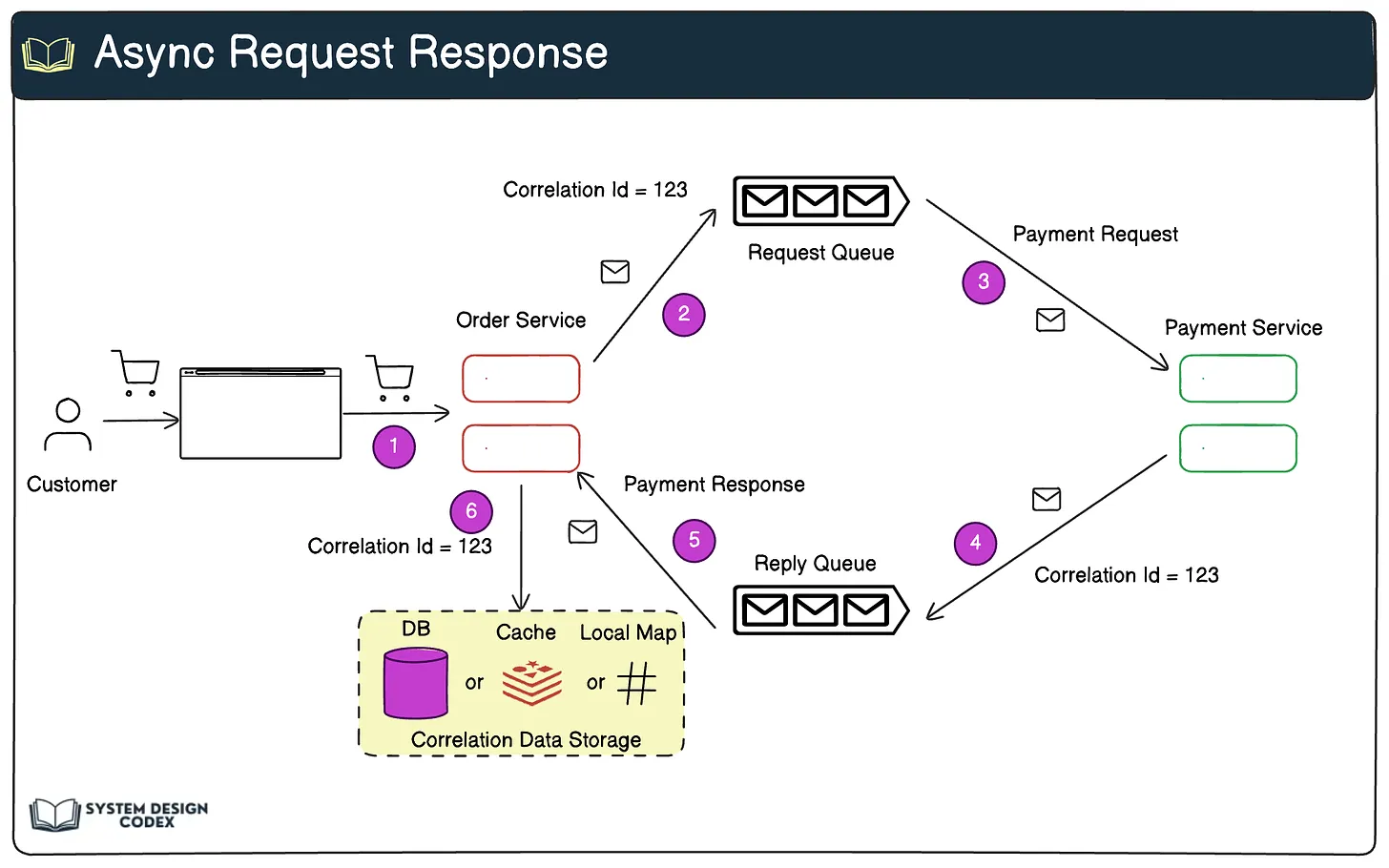
보시다시피 일반적인 방법 중 하나는 연관 ID(correlation ID)를 사용하는 것입니다. 작동 방식은 다음과 같습니다:
- 주문 서비스와 결제 서비스가 비동기 요청-응답 모델로 상호 작용한다고 가정해 봅시다.
- 고객이 주문 서비스의 한 인스턴스를 통해 주문합니다. 이 주문에 대해 고유한 상관 ID를 생성하고, 해당 데이터를 데이터베이스, 분산 캐시, 또는 로컬 인스턴스 수준의 HashMap에 저장합니다.
- 다음으로 상관 ID와 함께 결제 요청 메시지를 결제 서비스에 보냅니다.
- 결제 서비스(특정 인스턴스)가 결제를 처리하고 응답을 응답 큐로 보냅니다. 응답 메시지에는 동일한 상관 ID가 포함됩니다.
- 주문 서비스(동일하거나 다른 인스턴스)가 응답 메시지를 가져옵니다. 메시지의 상관 ID를 사용하여 응답을 원래 주문 요청과 매칭하고 필요한 조치를 취합니다.
이 시점에서 연관 ID의 필요성에 대해 의문을 제기할 수 있습니다. 주문 ID로도 같은 일을 할 수 있지 않을까요?
맞습니다. 하지만 연관 ID를 사용하면 몇 가지 이점이 있습니다:
- 동일한 주문에 대해 여러 결제 요청을 보낼 수 있습니다(재시도, 부분 결제 등). 고유한 상관 ID/요청을 사용하면 이들을 적절히 매칭할 수 있습니다.
- 연관 ID는 라우팅 로직을 비즈니스 컨텍스트(주문 ID와 같은)와 분리합니다.
- 연관 ID를 사용하면 여러 서비스에 걸친 요청 흐름을 쉽게 추적할 수 있습니다.
👉 그렇다면 - 여러분이 보거나 사용해 본 다른 이벤트 기반 패턴에는 어떤 것들이 있나요?
Top 1% 개발자로 거듭나는 확실한 처방전, 데브필입니다.

의견을 남겨주세요