
1. OpenClaw의 buy-anything: 에이전틱 커머스의 API-first 접근
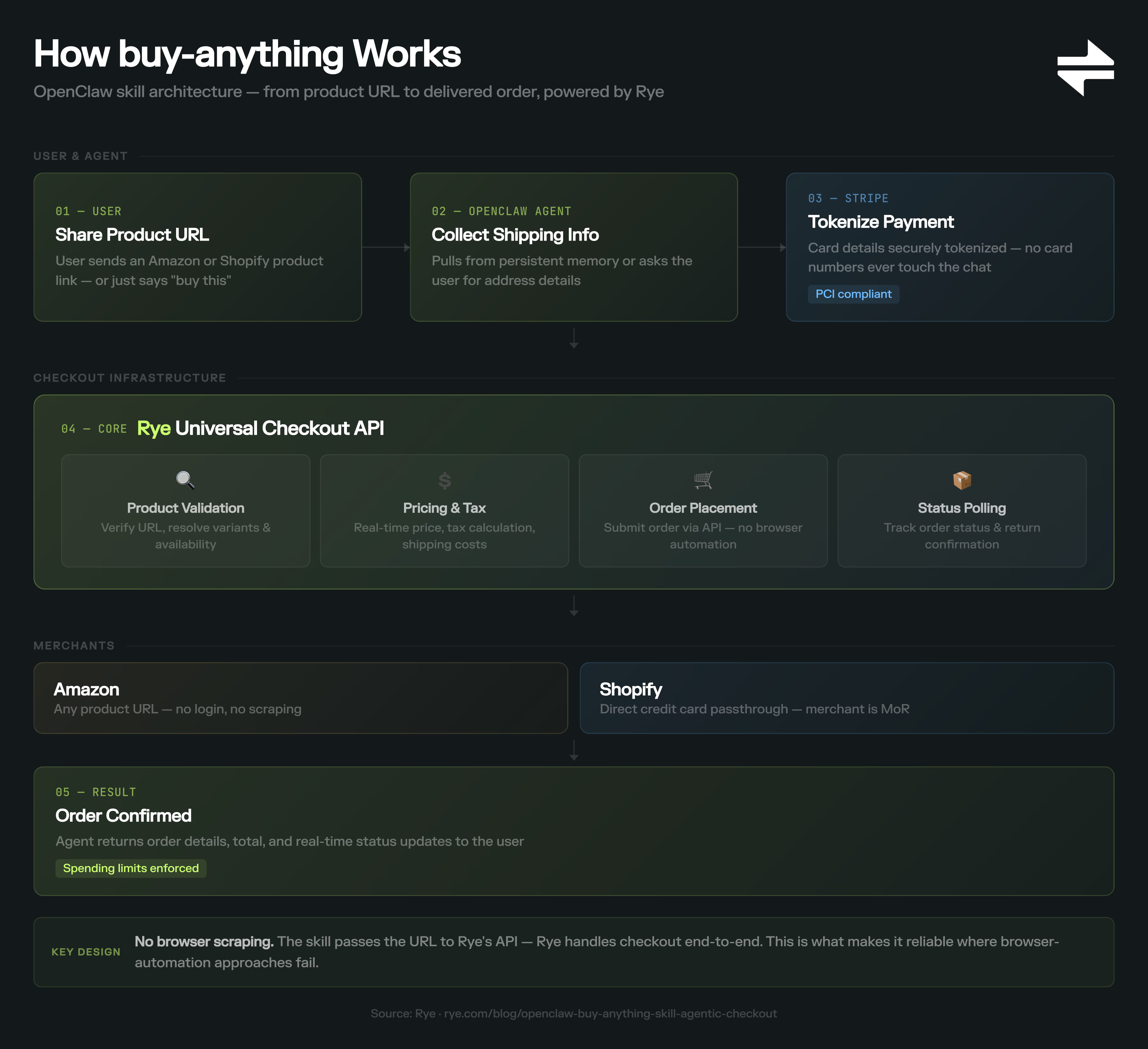
현재 에이전틱 커머스에서 가장 잘하고 있는 팀 중 하나는 Rye이다. Rye는 오픈소스 AI 에이전트 프레임워크 OpenClaw에 buy-anything 스킬을 추가하였는데, 이는 Rye의 Universal Checkout API를 활용해 에이전트가 Amazon과 Shopify에서 직접 상품을 구매할 수 있게 하는 기능이다.
현재 에이전틱 커머스에는 세 가지 접근 방식이 있다.
- 프로토콜 기반(ACP, UCP): 가맹점이 직접 프로토콜에 옵트인해야 한다. OpenAI의 ChatGPT 체크아웃이 대표적인데, 약 12개의 Shopify 가맹점 박에 사용하지 않으면서 사실상 멈췄다. 수백만 가맹점의 옵트인을 기다리는 방식은 확장이 어렵다.
- 브라우저 스크래핑: 에이전트가 결제 페이지를 직접 탐색하는 방식이다. 이전 CommerceBench에서 알 수 있는 것처럼, 해당 방식은 웹사이트의 안티봇 보호에 막히기 쉽고, 정확도도 낮을 뿐만 아니라, 에이전트에게 로그인 정보를 넘겨야 하는 보안 리스크가 있다.
- API-first 체크아웃: 에이전트가 상품 URL과 결제 토큰을 백엔드 API에 넘기면 이후는 Rye에서 알아서 하는 형태로 buy-anything skill이 여기에 해당한다.
buy-anything의 작동 방식은 이렇다.
- 사용자가 상품 URL을 공유하면, 에이전트가 배송 정보를 수집하고, 카드 정보는 Stripe를 통해 토큰화된다.
- 카드 번호가 채팅, Rye API, 에이전트, LLM 제공자 어디에도 닿지 않는다. 이후 Rye의 API가 상품 검증, 가격 확인, 세금 계산, 배송, 주문까지 한 번에 처리한다.
- V2에서는 Shopify 지원, 주문 상태 추적, 지출 한도 설정 기능이 추가됐다.
해당 스킬은 실제로 사용이 가능하다. Retailgentic 팟캐스트의 라이브 데모에서는 호스트가 에이전틱 커머스 시스템을 깨뜨리기 위해 설계한 세 가지 챌린지를 통과했는데, 여러 사이즈와 유통기한 옵션이 있는 복잡한 아마존 상품 구매도 성공적으로 처리했다.
핵심 설계 결정은 에이전트가 가맹점 페이지를 직접 스크래핑하거나 방문하지 않는다는 점이다. URL만 Rye에 전달하고, Rye가 나머지를 처리한다. 브라우저 스크래핑 방식이 실패하는 지점에서 이 접근이 안정적으로 작동하는 이유다.
물론 열린 질문도 있다. Rye는 중앙화된 중개자이므로 Rye의 API를 전적으로 신뢰해야하며, 단일 장애점이 존재한다. 지출 한도가 있지만 프롬프트 인젝션을 통해 에이전트가 조작될 가능성도 남아 있다. 거래당 수수료 구조도 아직 공개되지 않았다. 하지만 프로토콜 기반 접근이 가맹점 옵트인이라는 구조적 병목에 걸린 상황에서, API-first 접근이 실제로 작동하는 유일한 방식이라는 점은 주목할 만하다.
2. 에이전트는 카드를 먼저 쓰고, 그 다음에 스테이블코인을 쓴다
Simon Taylor가 Fintech Brainfood에서 Agents Will Use Cards First, Then Stablecoins라는 글을 냈다. "스테이블코인이 Visa를 죽일 것"이라는 주장이 대부분 틀렸다는 주장이다.
핵심 논지는 카드와 스테이블코인이 경쟁 관계가 아니라 보완 관계라는 것이다:
- 카드는 돈의 이동을 승인(authorize)하고, 스테이블코인은 돈을 이동(move)시킨다.
- 카드는 어디서나 수용되고 성숙한 통제 수단(일회용, 예산 상한, 가맹점 제한)이 있지만 정산이 느리다. 스테이블코인은 즉시 정산되고 프로그래밍이 가능하지만 아직 수용처가 거의 없다.
Taylor는 에이전트 결제가 세 단계로 진화할 것이라고 본다.
- 1단계(현재): 가상 카드(Virtual Card). Ramp나 Brex가 발급하는 가상 카드는 에이전트에게 강력한 도구다. 일회용 카드, 예산 상한, 가맹점 카테고리 제한, 단일 가맹점 잠금(예: Anthropic에만 사용 가능) 같은 통제 기능이 이미 성숙해 있다. 중요한 전환점은 에이전트를 고객으로 보는 시각이다. 개발자도, 사람도 아닌, 에이전트가 새로운 고객 유형이 된다. Patrick Collison은 에이전트가 사람보다 몇 자릿수 더 많은 결제를 할 것이라고 말했다.
- 2단계(다음): 카드가 스테이블코인으로 정산. 사용자 경험은 카드 그대로인데, 뒤의 정산 인프라가 바뀐다. 현재 가맹점은 결제 후 며칠, 크로스보더의 경우 최대 30일을 기다리지만, 스테이블코인 정산은 즉시, 24/7, 글로벌이다. 에이전트가 Anthropic의 비싼 AI 토큰을 사서 갑자기 스케일업하면, 매출이 들어오기 전에 자금이 바닥날 수 있다. 즉시 정산은 이 전체 사이클을 가속한다. 스테이블코인이 카드를 대체할 필요 없이, 카드를 더 잘 작동하게 만드는 것이다.
- 3단계(이후): 스테이블코인 네이티브 월렛. 수백 개의 에이전트를 운영하는 비즈니스를 상상해보자. 가상 카드로는 마스터 에이전트가 서브 에이전트 대신 모든 구매를 하거나, 새 카드 생성에 매번 5달러를 써야 한다. 스테이블코인 월렛이라면 서브 월렛을 필요한 만큼, 필요한 빈도로 생성할 수 있다. 정책 준수 여부도 사후가 아닌, 실시간으로 확인 가능하다. 프로그래밍 가능성이 핵심인데, 마스터 에이전트가 세분화된 지출 규칙을 가진 서브 월렛을 국경을 넘어, 허가 없이, 기계 속도로 만들 수 있다는 점은 카드로는 불가능하다.
Taylor가 짚는 또 하나의 통찰은 "에이전트가 새로운 가맹점(merchant)가 될 수 있다"라는 포인트이다. 바이브 코더가 금융 데이터를 보여주는 툴을 4시간 만에 만든다. 웹사이트도, 이용약관도, 법인도 없다. 다른 개발자의 에이전트가 이걸 주당 4만 번 호출하며 주당 40달러 매출이 난다. 기존 결제 프로세서는 이런 "가맹점"을 온보딩하기 어렵다. 기술이 부족해서가 아니라, 가맹점을 온보딩한다는 건 그 가맹점의 리스크를 떠안는다는 뜻이기 때문이다.
3. LLM을 예측 보조 도구로써: 예측시장에서 의미 기반 필터링
크립토에 관심있는 분들이라면 누구나 AI를 통해서 조금 엣지있는 예측시장 봇을 돌려보려는 생각을 해봤거나, 실제로 해봤을 것이다. 나 역시 막연하게 이러한 생각을 하고만 있다가, UNIST 학부시절에 내가 수업을 듣기도 한 이용재 교수님이 Kalshi 등과 함께 작성하신 해당 논문을 우연하게 발견하여서 읽지 않을 수 없었다. 한 줄 요약하자면, 해당 논문은 LLM을 예측시장 트레이딩의 보조 도구로 활용하는 방법을 제안한다.
먼저 배경을 이해하자.
예측시장에서는 서로 다른 이벤트 간에 선행-후행 관계가 존재할 수 있다. 예를 들어 "일본 경기침체" 이벤트의 가격이 먼저 움직이면, 며칠 뒤 "미국 GDP 성장률" 이벤트의 가격이 따라 움직이는 식이다. 이런 관계를 찾아내면 선행 이벤트의 움직임을 보고 후행 이벤트에 베팅해서 수익을 낼 수 있다.
문제는 이 관계를 찾는 통계적 방법(Granger causality, 그레인저 인과성)이 너무 많은 가짜 관계(false positive)를 잡아낸다는 것이다. 그레인저 인과성이란 쉽게 말해 "A의 과거 데이터가 B의 미래를 예측하는 데 도움이 되는가"를 통계적으로 검증하는 방법이다. 예를 들어 "테일러 스위프트 투어"와 "미국 GDP" 사이에 통계적 상관이 잡힐 수 있는데, 이건 순전히 우연이다. 이런 허위 관계에 베팅하면 큰 손실이 난다. 즉, 그레인저 인과성은 시간적 인과관계의 약한 증거 정도라고 볼 수 있다.
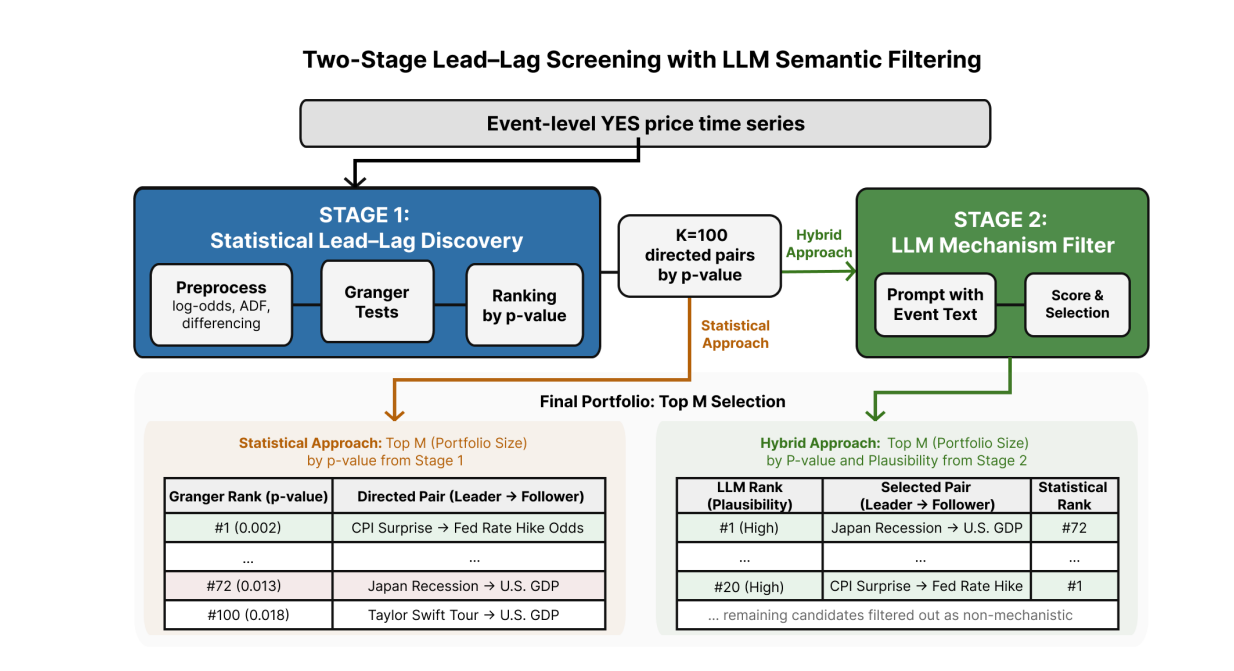
해당 논문이 제안하는 더 나은 솔루션은 다음과 같은 2단계 프레임워크다.
- 1단계(통계적 발견): Kalshi 예측시장의 가격 데이터에서 그레인저 인과성 검정을 돌려 후보 쌍 상위 100개를 뽑는다.
- 2단계(LLM 시맨틱 필터링): 상위 100개 쌍 각각에 대해 LLM에게 묻는다. "이 두 이벤트 사이에 그럴듯한 경제적 전달 메커니즘이 있는가?" LLM은 메커니즘의 유무, 강도, 방향, 이유를 판단하고, 그럴듯한 순서로 재정렬한다. 여기서 상위 20개만 포트폴리오에 편입한다.
프롬프트에는 "회의적으로 판단하라, 많은 통계적 상관은 허위다"라는 지시가 포함된다. 핵심은 LLM이 더 나은 예측을 하는 게 아니라, 깨지기 쉬운 허위 관계를 걸러내는 역할을 한다는 것이다.
결과가 인상적이다. 기본 통계 방식 대비 LLM 필터링을 추가했을 때:
- 승률: 51.4% → 54.5% (소폭 개선)
- 평균 손실 규모: $649 → $347 (46.5% 감소)
- 총 PnL: $4,100 → $12,500 (3배 이상 증가)
주목할 점은 승률 개선이 아니라 손실 감소가 핵심 동인이라는 것이다. LLM 필터링은 패배 트레이드의 평균 규모를 거의 절반으로 줄인다. 통계적으로만 유의미하지만 실제 경제적 메커니즘이 없는 쌍들이 바로 큰 손실을 유발하는 쌍이고, LLM이 이것들을 걸러낸다.
특히 큰 시장 움직임에서 LLM 필터링의 가치가 극대화된다. 선행 이벤트가 10포인트 이상 움직이는 큰 시장 움직임일 때 승률은 기존의 통계 방식의 53.8%에서 하이브리드 방식에서 71.4%로 뛴다.
LLM이 통계가 놓치는 고가치 쌍을 발굴하는 사례도 있다. "일본 경기침체 → 미국 GDP 성장률" 쌍은 그레인저 순위 71위(상위 20개 커트라인 밖)였지만, LLM이 "경기침체는 국내 수요를 약화시키고, 무역 연계와 금융 파급효과를 통해 주요 경제국의 침체가 전체 성장률을 끌어내린다"는 메커니즘을 인식해 5위로 끌어올렸고, 실제로 $700 수익을 냈다.
이 결과는 보유 기간(1일~21일), 모델 변형(GPT-5-nano, GPT-5-mini), 학습 데이터 커트오프 이후 기간 모두에서 일관되게 유지됐다. 결국 이 논문이 보여주는 건 LLM이 예측을 더 잘한다기보다는 통계만을 사용하였을 때 생길 수 있는 빈틈, 노이즈에서 시그널을 분리하는 보조 도구로서 기능한다는 것이다. 기회가 된다면, 해당 방법론을 실제로 한번 전략에 녹여내보고 싶다.
의견을 남겨주세요