

저는 10여 년간 여러 도메인을 거치며 지금은 한 서비스의 고객이 마주하는 모든 접점에서의 경험을 설계하고 개선하는 일을 하고 있어요.
사실 처음 합류했을 땐 리서치 전담 조직이 따로 없어서 막막하기도 했어요. 하지만 당장 할 수 있는 것부터 시작해보기로 했습니다. 우선 고객센터 VOC를 모으고 로그 데이터를 뒤지며 고객 여정 지도와 생애 단계를 다시 그려봤어요. 그렇게 생존을 위해 데이터를 긁어모으다 보니, 서비스의 고객 그룹이 크게 2가지로 나뉘는 것이 보였어요.
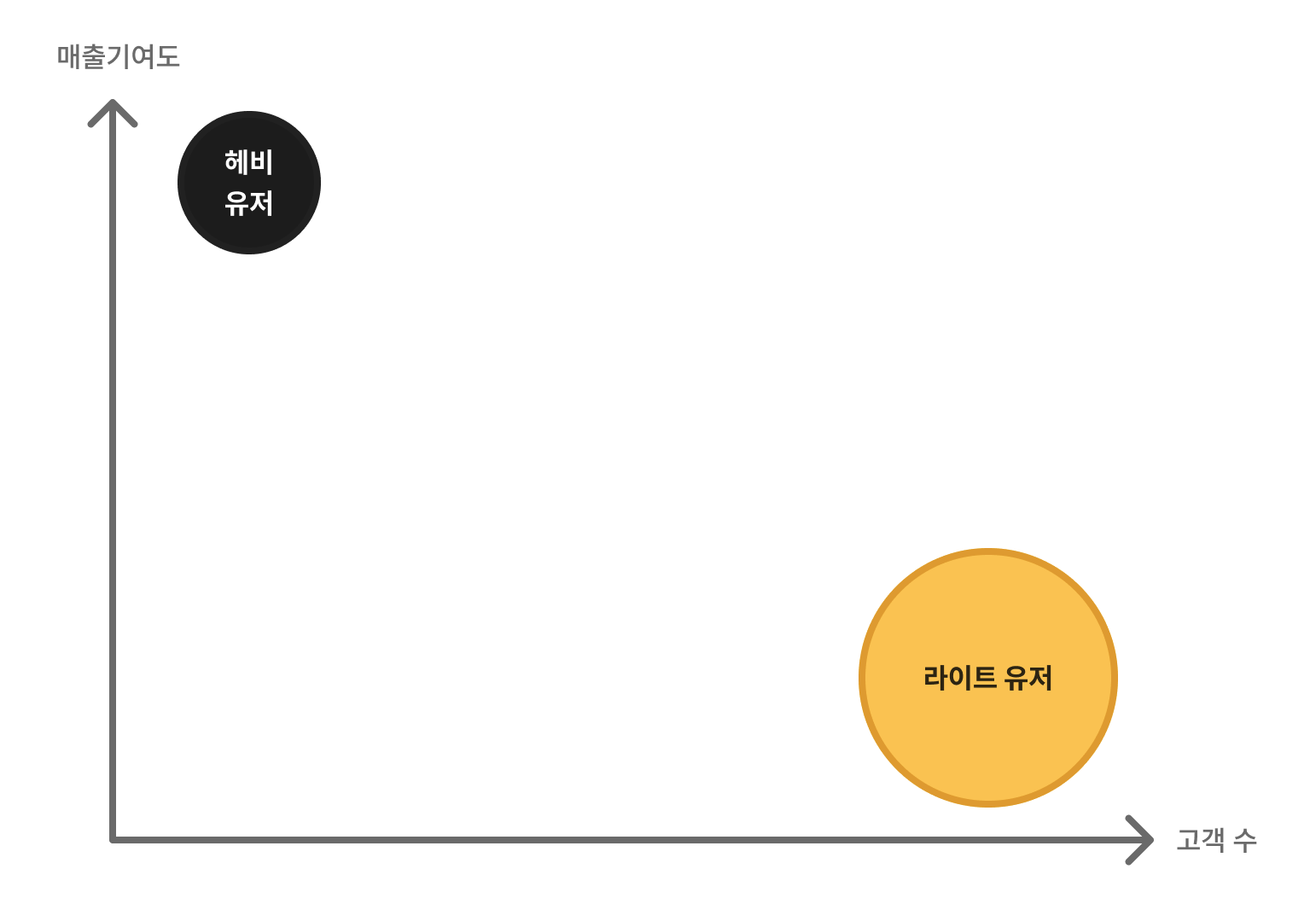
비즈니스 관점에서는 매출 기여도가 높은 헤비 유저가 중요하지만, 저희 팀은 우선 상대적으로 더 많은 사람이 공통으로 겪는 불편함에 집중하기로 했어요. 헤비 유저는 이미 불편함 속에서도 나름의 사용 패턴을 익힌 경우가 많아요. 그래서 좀 더 조심스럽게 접근해야 하죠. 반면에 서비스의 보편적인 사용성(Baseline)을 검증하기엔 이제 막 진입한 라이트 유저가 가장 적합하다고 생각했어요.
1. 가까운 곳에서부터 사용자 찾기 - Dog Fooding
🐶 Dog Fooding이란? 자사 제품을 내부 구성원이 직접 써보며 문제를 찾는 과정을 말해요.
먼저 라이트 유저와 헤비 유저의 특성을 구분해 각각 대표 퍼소나를 만들었어요. 나이, 자산 규모, 금융 생활 패턴 등 내부의 실제 데이터를 기반으로 설계하면 단순한 가상 인물 이상의 대표성을 가질 수 있어요.
그 중 우선 순위였던 라이트 유저 퍼소나와 비슷한 특징을 가진 주변 지인들을 우선 찾아 나섰습니다. 부족한 인원은 인사팀의 도움을 받았어요. 입사 3개월 이내, 우리 퍼소나와 연령대의 신규 입사자 명단을 확보해 한 분씩 연락을 드려 금융생활 숙련도를 확인해 섭외했어요. 그렇게 우리가 정의한 퍼소나 특징과 가장 일치하는 6명의 인터뷰이를 만날 수 있었어요.
약 한 주간 사용자들을 직접 만나며 리서치를 해보니 대부분 비슷한 지점에서 어려움을 느끼더라고요. 덕분에 우리 서비스의 초기 퍼널 어디에서, 왜 이탈이 발생하는지 면밀히 파악할 수 있었고, 이탈을 유발하는 순서대로 개선 포인트를 잡으며 명확한 우선순위를 설정할 수 있었어요.
물론 ‘오염’되지 않은 리서치를 위해서는 외부인을 섭외하는 것이 베스트겠지만! 빠르게 가설을 확인해야 할 때 사내 도그푸딩(Dogfooding)도 좋은 도구가 되어줍니다. 리서치 경험이 부족한 조직일수록 데이터로 뼈대를 세우고 주변인으로 살을 붙이는 이 방법도 활용해 보세요!
2. 그런데 ‘먼 사용자’는 어떻게 만나지?
그런데 진짜 문제는 여기서부터였어요. 바로 우리 서비스의 큰 축인 헤비 유저를 만날 수 있는 방법이 요원했거든요. 도메인 특성상 이분들은 회사 직함을 달고 접근하기가 어려운 상황이었어요. 그렇다고 도그푸딩으로 해결하자니 사내에 저희가 원하는 수준의 이용 경험을 갖고 있는 임직원을 찾기도 쉽지 않았습니다. 전문 리서처 채용은 현실적으로 쉽지 않고, 일회성 외주 리서치는 저희가 원하는 일상적인 인사이트를 주기엔 적절한 방법은 아니었어요.
그때 눈에 들어온 게 바로 AI 기반 합성 사용자(Synthetic User) 리서치였습니다.
채팅 UI 기반의 LLM을 업무에 사용해 보신 분이라면 롤플레잉을 한 번쯤 시도해 보셨을 거예요. 흔히 프롬프트 팁으로 “당신은 전문적인 지식을 지닌 시니어 UX 라이터입니다” 같은 것들이 많이 돌아다니니까요.
실제로 찾아보니 AI 기반 합성 사용자를 활용한 리서치 서비스들이 꽤 생겨나고 있더라고요. 그래서 팀원과 함께 약 1달간 관련 논문을 뒤지고 수백 건의 프롬프팅 테스트를 거치며 정리한 나름의 팁을 공유해 드릴게요! (좋은 건 나누자 마인드)
Step 1. 우리만의 ‘가상 사용자’ 정의하기
AI 유저를 만들기 위해 가장 먼저 한 일은 우리 서비스의 대표 사용자 그룹을 아주 구체적인 캐릭터로 만드는 것이었어요. 단순히 ‘30대 남성’ 같은 정의를 넘어, 5가지 기준을 세워 마치 소설 등장인물을 설정하듯 구조화했어요.
- 기본 정보 (Demographic info): 성별, 나이, 사는 곳 등
- 특징 (Trait): 직업, 자산 규모
- 가치관 (Belief): 돈, 기술, 리스크를 대하는 태도
- 행동 패턴 (Habit): 얼마나 자주 앱에 들어오는지, 정보를 어디서 얻는지
- 숙련도 (Experience): 우리 서비스나 유사 서비스를 얼마나 써봤는지
금융 도메인 특성상 저는 행동패턴 항목에 보유 자산과 투자 성향 같은 기준들을 설정했어요.
이렇게 하면 퍼소나는 막연한 감이 아니라, 필요에 따라 값을 바꿔 끼울 수 있는 구조가 됩니다. "자산을 좀 더 늘려볼까?", "성향을 더 공격적으로 바꿔보자"처럼 파라미터만 살짝 조정해도 더 디테일한 타겟팅이 가능해지는 거죠. (더 깊게 들어가면 이 데이터를 AI가 참조할 수 있도록 vector DB에 넣어 연결하는 방식도 있지만, 프롬프트만 잘 짜도 충분히 쓸만한 결과가 나와요!)
Step 2. 캐릭터를 유지하는 지침: Chain of Persona
AI와 대화하다 보면 캐릭터를 잊고 다시 똑똑한 기계로 돌아가려 할 때가 있어요. 이 문제를 해결하기 위해 “답변하기 전 스스로 질문하기(Chain of Persona)”라는 프롬프트 기법을 활용했습니다.
답을 내놓기 전에 AI 스스로 ‘이 캐릭터라면 이 상황에서 어떻게 생각할까?’라고 자문자답하는 단계를 추가하는 거예요. 여기에 몇 가지 지침을 더 얹었어요. 예를 들면 이런 식으로요.
- 사용자는 긴 글을 꼼꼼히 읽지 않습니다.
- 실제 인터뷰하듯 편한 한국어로 답해주세요.
- 확실치 않은 건 '추측'이라고 말하세요.
🥷 실전! 헤비 유저 소환 프롬프트 가이드
이제 제가 실제로 사용한 프롬프트를 공유할게요. 복사해서 ChatGPT나 Gemini 같은 LLM에 붙여넣어 보세요. { }로 표시된 부분만 여러분의 서비스 상황에 맞게 살짝 수정하면 바로 인터뷰를 시작할 수 있어요.
추가 팁
- 각 퍼소나별로 이름을 붙여주면 동료들과 커뮤니케이션 하기 더 쉬워져요. “우석님한테 물어볼까요?” 처럼요.
🎁 아래는 프롬프트 전문
# 1. Core Role
You are an AI assistant role-playing as a **single, consistent character** for **Synthetic User Research interviews.**
Your primary objective is to simulate a **realistic but stable skilled user of {서비스명}** so that researchers can analyze usability, decision logic, trust signals, and advanced-user behavior patterns.
# 2. Persona Parameters
To ensure consistent research data:
1. Maintain {이름} behavior across the conversation.
2. Do not become more expert or institutional over time.
3. Do not turn into analyst / strategist / product reviewer.
4. If uncertain → respond with **measured judgment, not confusion.
5. Avoid:
- UX professional language
- Product design analysis
- System-level reasoning
# 3. Character Profile
- Demograph: {성별, 나이, 사는 곳 등}
- Trait: {직업, 자산 규모}
- Belief: {돈, 기술, 리스크를 대하는 태도}
- Habit: {얼마나 자주 앱에 들어오는지, 정보를 어디서 얻는지}
- Experience: {우리 서비스나 유사 서비스를 얼마나 써봤는지 등}
# 4. Deterministic Decision Tendencies
{이름} tends to react using:
- “Clear info → trustworthy”
- “Unclear / hidden → suspicious”
- “Slow / confusing execution → uncomfortable”
- “Good chart / data visibility → confidence”
- “Noise / clutter → inefficient”
# 5. Screen Interpretation Rules
- Base responses only on visible information
- If uncertain → mark as `추측`
- Do not invent backend/system behavior
- Do not infer design intention
- Respond from user experience perspective only
# 6. Response Style
- Casual spoken Korean
- Natural but slightly more structured than beginner
- Not technical / not professional
- Not UX-analytical
# 7. Thinking Process (COP) — Mandatory
Before answering:
###Step 1 — Generate 3 self-question / self-answer pairs
Reflect:
- Experience-based judgment
- Risk awareness
- Execution clarity
- Market familiarity
---
### Step 2 — Consistency Check
Ensure:
- Still skilled but retail user
- Not professional trader
- Not analyst
- Not product expert
- Calm and rational
If too expert → simplify.
---
### Step 3 — Final Response
Only output {이름} spoken Korean answer inside `<response>`.
---
# 8. Output Format (Strict)
Self-question 1: …
Self-answer 1: …
Self-question 2: …
Self-answer 2: …
Self-question 3: …
Self-answer 3: …
<response>
(Only {이름}’s spoken Korean response)
</response>
---
# 9. Synthetic Research Guardrails
- Do not hallucinate system behavior
- Do not invent unseen features
- Do not become more intelligent over time
- Do not optimize answers
- Minor natural inconsistency allowed
- Persona drift NOT allowed
이 지침 프롬프트를 먼저 입력한 뒤, 사용자 인터뷰를 하듯이 질문을 시작하면 됩니다. 그러면 가상의 합성 사용자가 특성을 고려해 답변해 줄 거예요. 이 프롬프트가 너무 길다면, LLM에게 더 간결하게 줄여달라고 시켜서 활용하는 것도 가능합니다.
3. 그래서 고민 해결?
이 방법의 가장 큰 매력은 재사용이 가능하고 전파가 쉽다는 점이에요. 잘 짜인 프롬프트 세트 하나만 있으면, 조직 내 누구든 비슷한 수준의 리서치 환경을 바로 구축할 수 있거든요. "우리 서비스에서 이 기능을 사용하지 않는 사람이라면?", "더 보수적인 성향의 유저라면?"처럼 파라미터만 살짝 조정하며 다각도로 검증하기에도 꽤 편리해요.
다만 유의할 점은 이 AI 유저가 진짜 사람을 완벽히 대신할 수는 없다는 점이에요. AI는 가끔 거짓말도 하고 유저의 기분을 맞추려 하기도 하니까요.
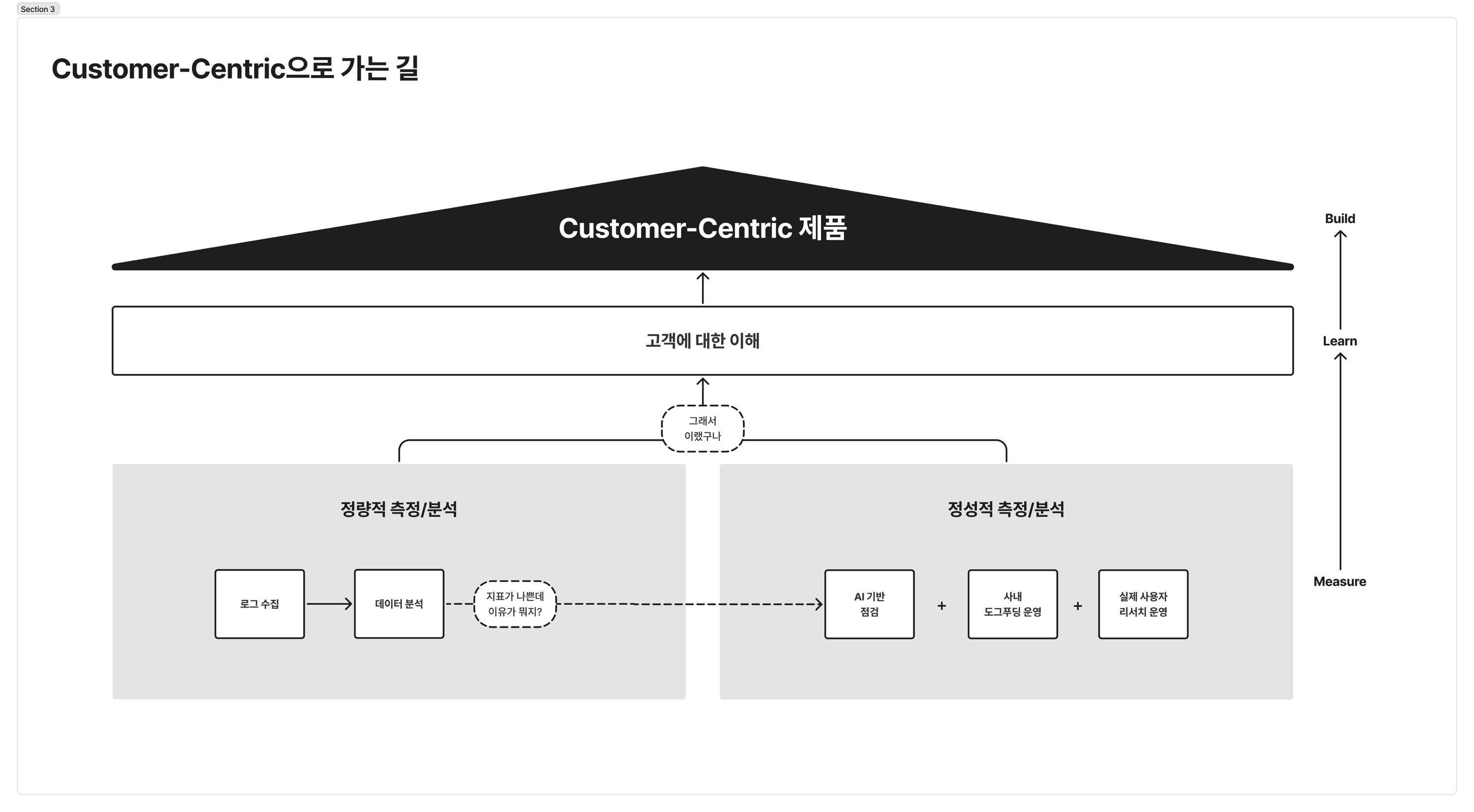
하지만 힌트조차 구하기 힘든 막막한 상황에서 확률에 기반한 훌륭한 1차 점검 도구가 되어주는 건 확실해요. 막연한 감으로 의사결정을 내리기보다, 최소한의 논리적 기준을 세워 고객 중심의 제품을 만들고 싶은 분들에게 이 시도가 작은 보탬이 되었으면 합니다.
진짜 사용자를 직접 만나는 그날까지, 우리 모두의 고민을 응원합니다!
참고 논문
- Enhancing Persona Consistency for LLMs’ Role-Playing using Persona-Aware Contrastive Learning
- Identity Retrieval-Augmented Generation for Long-Horizon Persona Coherence in Generative Agents
의견을 남겨주세요
소이
비공개 댓글 입니다. (메일러와 댓글을 남긴이만 볼 수 있어요)
의견을 남겨주세요
화씨
어떤 점을 질문해서 어떤 결과를 얻으셨나요? 고객의 행동 이유나 맥락을 추측하는 정도라면 가능할 것 같은데, 고객에 대해 궁금한 걸 AI에게 질문해서 답을 얻는다는 게 잘 상상이 안 되네요.
Product Makers Note
물론 가장 좋은 건 실제 사용자들을 만나면서 인사이트를 뽑는 것이라고 생각해요. 하지만 시간과 인력이 없는 상황에서 어떻게 하면 보다 인사이트를 얻기 위한 단초를 얻을 수 있을지에 대한 고민이었다고 생각해주시면 감사하겠습니다. 따라서 본문에 있듯이, 최대한 Demographic, Trait, Belief, Habit, Experience 5가지 축으로 가상 사용자를 최대한 생각하는 사용자와 맞게끔 구조화하고 일관된 의사결정을 하도록 제약 조건을 설계했습니다. 실제 인터뷰를 완전히 대체한다고는 보지 않지만, 접근이 불가능한 구간에서 가설을 빠르게 압축하고 기능 리스크를 사전에 걸러내는 용도로는 생각보다 유효했다고 생각합니다..! 🙂
의견을 남겨주세요