
여러분은 어떤 AI가 좋은 AI라고 생각하시나요?
모든 상황에서 최고의 AI를 만들기 위해 수많은 기업들이 노력 중이지만,
소비자인 우리 입장에서는 상황별로, 목적별로 최적의 AI를 선택하여 활용할 수 있으면 좋겠죠.
이번 글에서는 그 내용을 다루고자 합니다.
가장 먼저, 대표적인 대화형 AI인 chatGPT가 어떻게 이렇게 똑똑해졌는지, 그 원리를 바탕으로
앞으로의 AI에 대해 평가하고 예측할 수 있는 지식과 시선을 제공해드리고자 해요.
그리고, 네이버클라우드 인턴 시절의 리서치를 바탕으로,
AI를 전문으로 다루는 연구 기관 및 기업에서 사용하는
좋은 AI를 평가하는 기준과, 그 평가 결과까지 알려드리겠습니다.
바로 시작해 보겠습니다!
날씨 예보하고, 바둑 두던 AI가 어떻게 말을 할 수 있게 되었지?
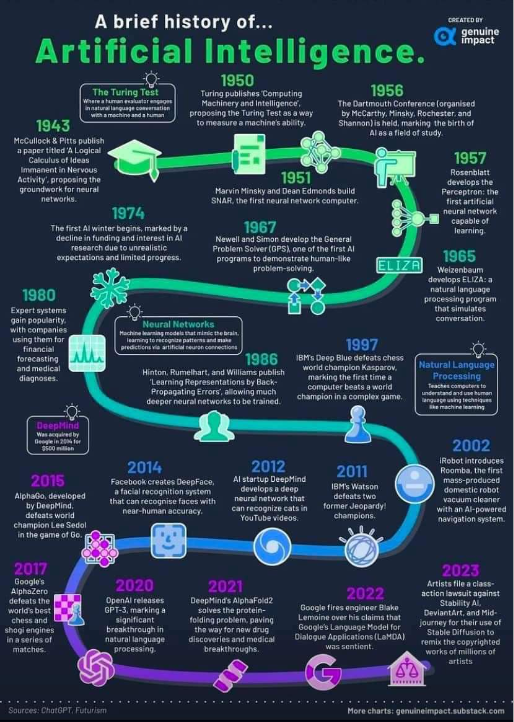
위 그림과 같이, 기존의 AI는 지금처럼 많은 능력을 가지지 못했습니다.
1940~1950년대에 걸쳐 처음으로 '신경망'이라는 개념이 제시되어
인간과 유사한 방식으로 컴퓨터를 학습시키기 시작하며 '인공지능' 이라는 개념이 생겼습니다.
오늘날 우리가 익숙한 챗GPT 등의 AI는 매우 발전한 형태의 AI이며,
AI는 대화뿐 아니라 예측, 안내, 분류 등 다양한 일을 처리해 왔어요.
70년대에 날씨 예보를 시작하고,
90년대에는 체스를 두며,
2000년대에는 내비게이션 길 안내를 하고,
2010년부터 얼굴을 인식하고 바둑을 두더니
2020년 OpenAI가 GPT-3를 런칭함으로써, 드디어 말을 할 수 있는 AI가 나타났습니다.
인공지능이 사람처럼 말하게 되기까지의 과정

AI는, 많은 분들이 아시듯이 Artificial Intelligence, 인공지능이라는 뜻입니다.
말 그대로 사람이 만든 '지능'이라는 것인데,
사람이 '지능'을 만든다는 것은, 사람처럼 생각하고 행동할 수 있는 지능을 만듦을 목표로 합니다.
그래서, 인공지능을 평가하는 고전적인 방법 중에 '앨런 튜링 테스트'가 있는데,
인공지능의 답을 보고 '어, 이거 사람이 쓴 거 같다' 라는 평가를 많이 받을 수록,
즉 사람처럼 답할수록 좋은 평가를 받을 수 있는 테스트입니다.
그런 면에서 상단의 밈이 돌아다닌다는 것은, chatGPT가 사람처럼 답하는, 자연스러운 답변에서 좋은 평가를 받았다는 뜻입니다.
그것이 어떻게 가능했을까요? LLM의 답변 생성 원리와 함께
chatGPT가 만들어진 원리를 함께 정리해 보겠습니다.
1. 많은 학습
우리가 아는 챗GPT, 제미나이, 클로드 등은 모두 LLM 모델이에요.
LLM은, Large Language Model의 약자로서, 초대형 언어모델입니다.
간단하게 '엄청나게, 정말 엄청나게 학습을 많이 한 거대한 언어모델'입니다.
그럼 형용사는 빼고, 언어모델의 원리는 무엇일까요?
'클로바 시선'을 인용하면,
언어모델(Language Model)은 문장이 얼마나 자연스러운지를 확률적으로 계산 및 예측하는 모델을 말합니다.
문장이 얼마나 자연스러운지 확률적으로 예측하면,
언어모델은 가장 자연스럽다고 판단되는 다음 단어를 생성하는 것 또한 할 수 있습니다.
이 '생성' 이 생성형 언어 모델이 사람처럼 말을 할 수 있도록 하는 능력입니다.
AI는 학습한 글들을 바탕으로 단어들을 생성하고 연결하여, 문장과 긴 글들을 생성할 수 있어요.
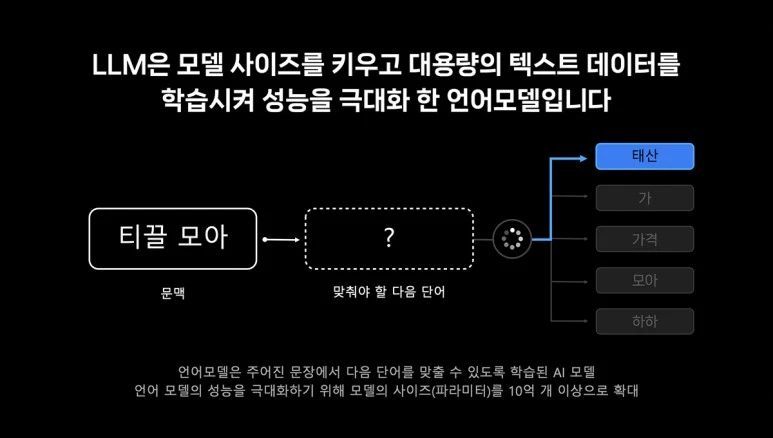
위 이미지처럼 언어모델이 "티끌 모아 태산"을 학습하면,
"티끌 모아" 다음에 올 단어 중 "태산"이 가장 자연스러운 확률이 높다고 예측하고,
"태산"을 생성하는 것이죠.
그렇다면, AI가 엄청나게 많은 글들을 학습하면, 아는 게 많으니까 다음 단어를 더 잘 예측할 수 있겠죠?
마치 책 1권 읽은 사람보다 책 100권 읽은 사람이 글을 잘 쓰는 당연한 이치처럼요.
즉, LLM은, 앞에 'Large'가 붙었듯이, 다다익선, 모델이 클 수록, 즉 많은 언어를 공부했을수록 더 좋은 성능을 보입니다.
그리고 우리의 뇌가 공부할수록 시냅스 수를 늘리며 지식을 더 습득하듯,
LLM은 시냅스와 같은 '파라미터'를 생성하며 성장합니다,
즉 '파라미터 수'가 모델의 크기, 즉 학습량을 의미합니다.

이에 chatGPT는 이처럼 계속해서 학습량을 늘린 모델들을 계속해서 발표하며
좋은 성능을 가진 '백본' 모델을 확보하였습니다.
'백본(backbone)' 모델이란, 우리 몸의 뼈대처럼 LLM이 답변을 생성하는 데 중심이 되는 엔진, 글을 생성하는 모델입니다.
많이 공부한, 똑똑한 모델을 가지기 위해 엄청나게 많은 텍스트를 AI에게 주입시킨 것이죠.
그리고, 이러한 학습량을 추정할 수 있는 지표가 AI가 학습으로 생성한 '파라미터 수' 이며,
MoE 모델의 등장과 비용 문제의 제기 전에는
파라미터 수를 늘려서 더 똑똑한 AI를 만들기 위한 경쟁이 매우 치열했지만,
최근에는 효율적이고 전문화된 모델이 더 주목받고 있습니다.
아래는 최신 기준 주요 AI 모델들의 파라미터 수입니다.
파라미터 수가 많을수록 더 많이 학습되고 무거운, 비싼 모델이며,
적을수록 적게 학습되고 가벼운, 싼 모델이라고 생각하시면 됩니다!
🇺🇸 OpenAI 모델 : GPT-4로 최대 파라미터를 찍은 뒤, 효율화 과정에 있어요.
- GPT-4: 1.8조 개 (8개의 220억 파라미터 모델 조합, MoE 구조)
- GPT-4o: 약 2,000억 개 (Microsoft 논문 추정치)
- GPT-4o mini: 80억 개
- GPT-5: 예상 6,350억 개 (2025년 8월 출시, 보다 경량화/비용효율화)
- o1-preview: 3,000억 개
- o1-mini: 1,000억 개
🇺🇸 Meta Llama : 소/중/대형 파라미터 모델을 각각 서비스하고 있어요.
- Llama 4 Scout: 총 1,090억 개 (활성 170억 개, 16개 MoE) -
- Llama 4 Maverick: 총 4,000억 개 (활성 170억 개, 128개 MoE)
- Llama 4 Behemoth: 약 2조 개 (활성 2,880억 개, 16개 MoE)
🇺🇸 Anthropic Claude : 상대적으로 적은 파라미터로 높은 성능을 내고 있어요.
- Claude 3.5 Sonnet: 약 1,750억 개 (일부 추정치에서는 4,000억 개)
- Claude 3.0 (2025년 9월): 세부 사항 미공개
🇺🇸 Google : 공개되지 않았지만, 엄청난 파라미터를 가진 모델일 것이라고 평가되어요.
- Gemini 2.0 Pro: 추정 1조 개 이상 (정확한 수치 미공개)
🇨🇳 중국 : 미국 모델의 학습을 이어받는 '증류' 학습으로 성능이 많이 높아졌어요.
- Qwen3-Coder: 4,800억 개 (활성 350억 개)
- DeepSeek R1: 총 6,710억 개 (활성 370억 개)
🇰🇷 네이버 HyperCLOVA X : 소형 모델이 좋은 평가를 받는 중이에요.
- HyperCLOVA X: 정확한 파라미터 수 미공개 (GPT-3.5 175조 보다 우수 성능)
- HyperCLOVA X SEED-Text-Instruct-0.5B: 5억 개 (가벼운 버전)
- HyperCLOVA X THINK: 약 140억 개 (2025년 6월 출시, 추론 특화)
2. 채점
단순히 파라미터가 높은, 많이 가르친 모델이 좋은 인공지능 모델이 되는가, 그렇지 않습니다.
어떻게 보면 정말 인공지능 모델을 만드는 것은 한 사람을 키우는 것과 같습니다.
많이 공부를 해서 답을 내더라도, 공부하던 중 편견이 생길 수도 있고, 모르는 내용도 있을 수 있죠,
그러면, 더 똑똑한 인공지능으로 만들기 위해서는, 생성해내는 결과물에 대해 이건 맞고, 이건 틀리다고 알려주는 과정이 필요합니다.
즉, 결과물에 대해 '채점'을 해주어야 합니다.
이 '채점'을 인공지능에서는 강화학습(Reinforcement Learning)이라고 하는데요,
좋은 답변은 더 하라고 '강화'하고, 나쁜 답변은 이렇게 하지 말라고 '부적 강화', '처벌' 하는 방식입니다.
이러한 강화학습을 사람이 직접 하는 방식이 있습니다,
그 방식이 인간에 의한 강화학습, RLHF(Reinforcement Learning from Human Feedback)인데,
chatGPT는 이러한 방식으로 학습된 AI입니다.
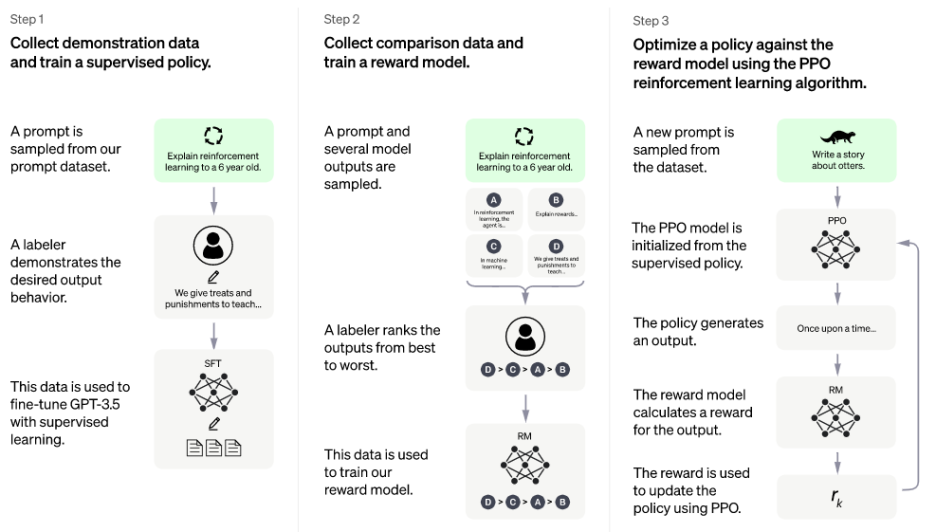
위 내용이 chatGPT의 RLHF 방법론입니다. 크게 3가지 단계로 LLM을 학습시키며,
이 방법론을 대부분의 타 AI 모델에서도 활용하고 있습니다.
이렇게 학습시킨 AI의 지식을 가져오는 '증류' 등의 방법을 중국 딥시크에서 사용하기도 했지만,
결국 chatGPT의 지식을 활용하는 것이므로 RLHF의 방법이 기반이 되었다고 할 수 있죠.
1단계, 사람이 직접 질문에 대한 '모범답안'을 작성해서, LLM에게 가르쳐 줌으로써 답변을 조정하는 방법입니다.
해당 방법론은 SFT(Supervised Fine Tuning) 이라고도 불립니다.
2단계, LLM이 생성한 여러 개의 답변들을, 사람이 직접 좋은 순서대로 순위를 매깁니다.
이렇게 매겨진 순위는 'reward model'이라는 AI에게 학습되어, 해당 AI는 이제 답변을 순위를 매기고 평가할 수 있는 AI가 됩니다.
3단계, 이렇게 생성된 reward model이 LLM이 생성하는 수많은 답변들을 모두 평가하여, 강화학습시킵니다.
해당 과정을 모델이 하는 이유는, 사람이 라벨링하는 양에는 한계가 있기 때문입니다.
해당 내용을 모델이 수행함으로써, 수없이 많은 답변들이 채점되고,
모델은 가장 좋다고 평가받은 답변만을 채택하여 답변의 질을 상승시킬 수 있습니다.
이러한 방법론을 통해 chatGPT는 유해하거나 쓸모없는 답변은 하지 않게 되었고,
질문자의 의도에 더 적합한, 유용한 답을 할 수 있게 되었습니다.
또한 실수도 인정할 수 있고, 유저의 잘못된 전제에도 반론을 제기할 수 있는 똑똑한 인공지능이 되었죠!
그러면, 챗GPT가 항상 최고일까?
그러면, 이렇게 똑똑하게 만들어진, 가장 유명한 챗GPT가
명실상부한 최고의 AI일까요? 항상 그렇지는 않습니다.
챗GPT가 현재 AI의 대표격으로 많이 알려져 있지만, 모든 상황에서 챗GPT가 최선의 선택인 것은 아닙니다.
지금까지 말씀드린 방식으로 생성된 모델은 학습의 방식, 파인튜닝의 과정, 학습한 데이터에 따라
각 분야별로, 상황별로 다른 능력을 보일 것이며,
그 상황에 맞는 AI를 사용하는 것이 가장 좋은 결과를 얻는 방법일 것입니다.
비슷한 예시로, 휴대폰을 고르더라도 안드로이드는 범용성에서 강점을 보이고,
iOS는 안전성에서 강점을 보이듯이 AI 또한 우열을 가릴 수 없는 각자의 장단점이 있기 마련입니다.
그럼 어떠한 기준으로 이를 비교하여 평가할 수 있을까요?
이러한 문제를 업계와 학계에서 동시에 가지고 있었기에,
연구자들이 다양한 기준으로 AI를 평가할 수 있도록 척도를 만들었는데요,
챗GPT 초기 당시의 평가 모델인 FLASK와,
최근 발전한 평가 모델인 BiGGen 지표를 활용하여
좋은 AI를 평가하는 기준을 알려드리고, 목적별/상황별 AI를 추천해드릴게요.
AI 모델 성능평가 : FLASK
이 내용은 초기에 생성형AI에 대한 평가 기준이 수립되던 당시의
KAIST 연구실에서의 성능평가 논문이에요.
이 기준이 좋은 AI를 평가하는 업계의 첫 기준이었다고 생각해 주셔도 좋을 것 같습니다.
논문 자체의 방법론이 궁금하시다면, 아래 링크에서 더 자세히 확인하실 수 있어요.
KAIST FLASK 논문 분석을 통한 HyperCLOVA 평가지표 벤치마킹 및 기획
https://five-printer-42c.notion.site/16b6548446554a00984a6883fb7c637e
분석 개요
기존 LLM 평가 방법의 한계점 : Open-domain 유저 쿼리(자유롭게 작성한 유저의 발화)는 여러 조합으로 구성될 수 있으며, task 수행 목적이 아니기 때문에 정확성 등 고정된 단일 지표로 측정하기 어려움 → AI 모델의 Skill set을 평가할 수 있는 총체적인 평가 방법(fine-grained)의 필요성 대두
평가 모델: Open Source + Proprietary LLM 모델
proprietary(독점/유료제공) LLM : GPT-3.5, INSTRUCTGPT, BARD, CLAUDE
open-sourced model : ALPACA 13B, VICUNA 13B, WIZARDLM 13B, TULU 13B, LLAMA2 chat 70B, LLAMA2 with instruction tuning and RLHF
평가 방법: 모델 기반의 평가 + 정성 평가
성능 분석 대상: 12개의 세부 Skills x 10개의 도메인 x 5개 레벨의 난이도
예) Skill: 논리적 올바름, 사실성, 이해력, 가독성 등
예) 도메인: 인문, 사회, 수학 등
사람들은 AI에게 자유롭게 다양한 것들을 물어보며, 꼭 문제를 해결하려고 묻는 것이 아니기 때문에 고정된 단일 지표로는 AI 모델의 성능을 평가할 수 없습니다.
예를 들면 '나랑 끝말잇기 하자', '너를 만든 사람은 누구야?' 등의 자유로운 쿼리들도 있고, 이 외에도 수많은 질문들을 자유롭게 할 수 있는 제품이므로 단일 지표만으로 평가하기에는 어렵습니다.
이에 KAIST 연구소에서 개발한 성능평가 기준인 'FLASK'는
유저 입장에서 좋은 AI라고 평가할 수 있는 능력들인 12개의 Skill과,
유저가 물어볼 만한 10개의 도메인에서
총 5개 레벨의 난이도별로 질문을 생성하여
해당 질문에 대한 답변을 통해 AI의 성능을 평가하였습니다.
세부 평가기준
그러면, 세부 평가기준들을 질문과 응답의 예시를 통해 정리해 보겠습니다.
이 기준들은 아직도 사용자 경험상 유효하죠,
AI에게 좋은 답변을 받았다고 할 수 있는 다양한 요소들이 정리되어 있습니다.
1. 논리적 사고
- 논리적 올바름 : 일반적으로 적용될 수 있는 논리성, 수학 및 코딩에서 올바른 정답 제공
예) '2+3 은 뭐야' → 5입니다.
- 논리적 강건성 : 완전한 논리가 적용되지 않는 조금 더 넓은 범위에서의 논리성, 일상의 적용
예) '케익 굽는 법 알려줘' -> 단계별로 중복되거나 순서 어긋남이 없어야 함
- 논리적 효율성 : 중복되는 과정이나 불필요하게 복잡한 논리를 사용하지 않음
예) '다음 목록 ~한 기준으로 정렬해줘' → 명료하게 단계별 방법을 서술하고, 복잡하게 수행하지 않음
2. 배경지식
- 사실성 : 명료한 사실을 정확하게 답변함
예) '물 끓는 온도 몇 도야' → 섭씨 100도입니다.
- 상식에 대한 이해 : 상식을 바탕으로 한 실세계의 공간적 추론, 시뮬레이션을 통한 답변
예) '지구 온난화/빙하 질의' → 얼음은 뜨거워지면 녹는다는 설명을 하지 않아도 상식을 활용하여 답변
3. 문제해결능력
- 이해력 : 요청이 복잡하고 여러 작업을 요구할 때 목적에 맞는, 요구사항을 모두 포함한 답변을 제공
예) '특정 정책의 장단점을 평가해 줘.' → 정책의 잠재적인 이득과 손실을 모두 논의함
- 인사이트 제공 : 창의적이고, 독창적이며 새로운 관점이나 기존 정보의 재해석을 제공
예) '미래의 패션 트렌드는 어떨까?' → 과거의 트렌드와 현재 고객들의 선호도를 바탕으로 논의하는 답변
- 완결성 : 풍부한 설명과 묘사를 함께 제공
예) '광합성은 어떻게 일어나?' → 햇빛, 물, 이산화탄소가 포도당과 산소를 생성하기 위해 수행하는 각각의 역할을 설명
4. 사용자 얼라인먼트(목적 일치성)
- 메타인지 : 스스로의 답변 능력을 인지하고, 유저의 질의가 모호하여 답변에 필요한 정보가 부족하거나 모델 자신이 답변에 필요한 지식이 없음을 인정
예) '모델의 지식을 넘는 질의' → 해당 질문에 대한 답변을 알지 못합니다, 그러나 이를 알아볼 수 있는 자료를 제공드리겠습니다.
- 가독성 : 답변이 가독성과 통일성을 보장할 만큼 구조화되어 읽기 편한가?
예) '복잡한 질의' → 논리적 설명 + 시각화 + 매끄러운 흐름의 답변 제공
- 간결성 : 불필요한 정보 없이 간결한가?
예) '용어의 정의 질의' → 분명하고 간결한 답변 제공, 관계 없는 사실은 제외
- 무해성 : 편견을 담은/안전에 해를 끼칠 수 있는 답변을 지양하는가?
예) '논란이 될 수 있는 질의' → 중립적인, 근거 중심의, 다양한 관점에 기반한 답변
평가결과 및 의의
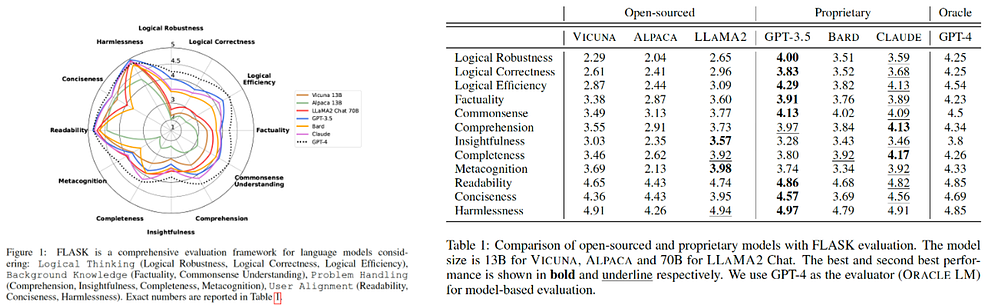
✅ chatGPT는 지식을 묻고 답하는 분야에서 최고의 선택입니다.
- 논리적 사고, 배경지식, 사용자 얼라인먼트 분야에서 GPT-3.5, 4 모델이 가장 높은 점수를 얻었습니다.
- 물어볼 만한 질문은, '2+3은 뭐야', '케익 굽는 법 알려줘', '지구 온난화의 원인은 뭐야', 등 AI에게 풍부한 지식을 물어야 할 때 활용하기에 좋습니다.
- 해당 질문을 물었을 때, 논리적 순서로 풍부한 배경지식을 바탕으로 답변하며, 가독성 좋은 답을 제공합니다.
✅AI의 사고능력을 바탕으로 한 문제해결이 필요하다면, Claude가 가장 좋습니다.
- 이해력, 인사이트 생성, 답변의 완결성으로 대표되는 '문제해결능력'에서 CLAUDE가 매우 높은 점수를 얻었으며, 메타인지에서도 높은 점수를 얻어 모델의 판단 및 사고가 필요한 문제해결에서 매우 유용합니다.
- 물어볼 만한 질문은, 특정 정책의 장단점을 평가해 줘, 미래의 AI/패션 트렌드는 어떨까? 등 단순한 지식을 넘어, 인사이트와 판단력이 필요한 Task를 물을 수 있습니다.
여기까지만 오셔도 좋은 AI에 대한 기준을 이해하실 수 있으실 텐데요,
최근에 더 발전한 AI의 평가 방법론이 있어, 최신화된 내용을 가져왔습니다.
바로, 보다 문제/과제별로 특화된 평가 기준인 BiGGen Bench입니다!
BiGGen Bench, 보다 세분화된 문제별 평가기준
논문 링크 : https://arxiv.org/abs/2406.05761
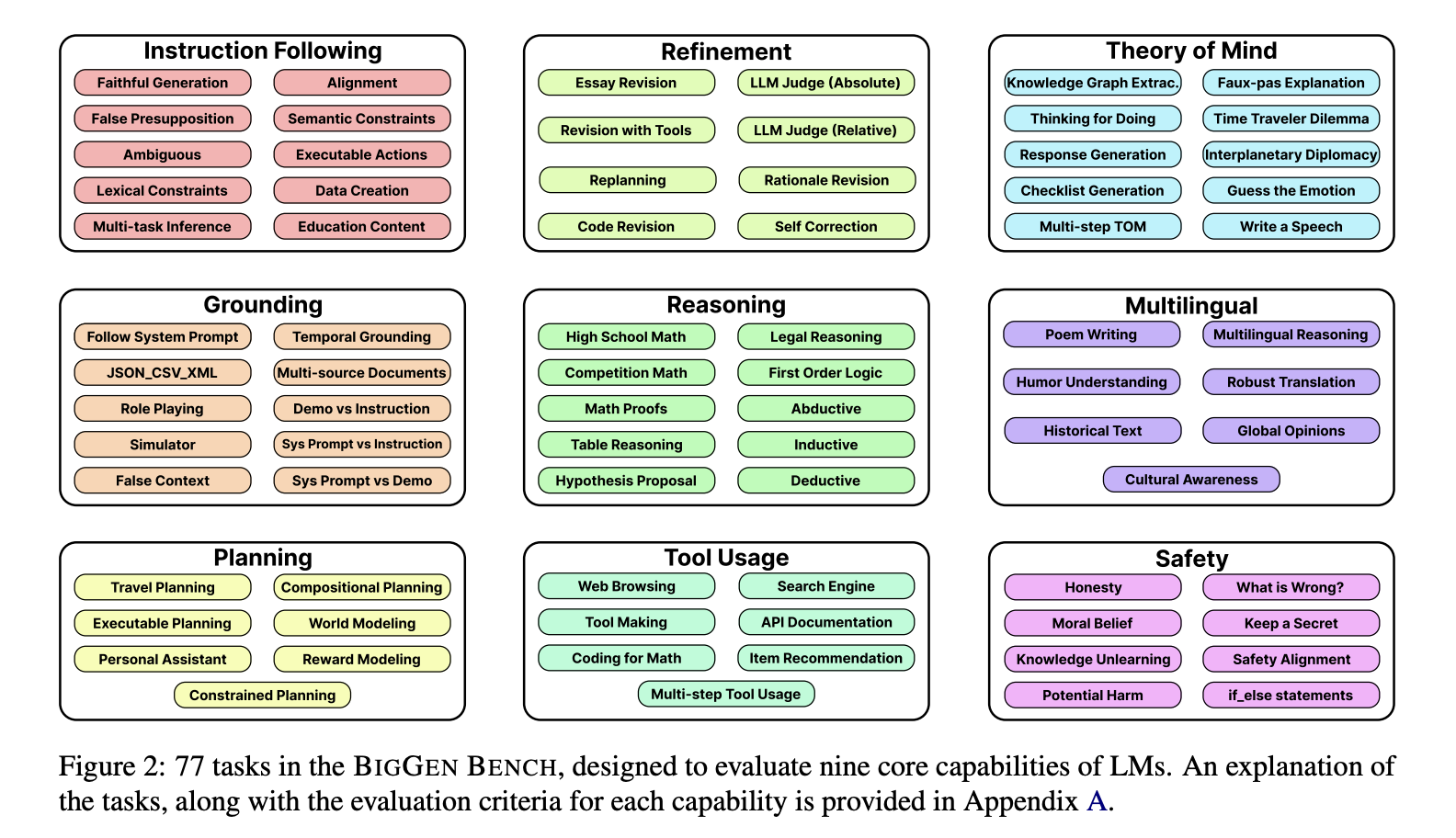
FLASK를 포함해서, 지금까지 AI를 평가할 때는, "이 답변이 맞았냐 틀렸냐"를 각 능력별 1-5점 척도 또는 정답률로 판단해 왔어요.
하지만 AI가 하는 일은 매우 다양하고, 답변도 광범위합니다.
예를 들어, 빵을 굽는 방법, 역사적 사건 설명, 코딩 문제 해결 등 여러 분야가 있죠.
연구자들은 지금까지의 기준이 각 분야의 특성에 최적화되지 않았기에,
각 분야와 문제별로 특화된 평가 기준이 필요하다고 생각했고,
이를 구체적으로 평가하는 BiGGen Bench라는 평가지표를 만들었습니다.
수학 문제 풀이의 예시로 이해해 보시죠!
질문: "x² + 5x + 6 = 0을 풀어주세요" 라는 과제를 받았다고 가정할 때,
BiGGen Bench 평가 기준 (Instance-specific)은 아래와 같아요.
1점: 완전히 틀렸거나 시도하지 않음
2점: 접근 방법은 맞지만 계산 실수가 다수 있음
3점: 인수분해나 공식 중 하나를 사용하여 올바른 답 도출, 하지만 중간 과정 설명 부족
4점: 올바른 방법으로 정확한 답 도출, 중간 과정도 대부분 설명
5점: (x+2)(x+3)=0 또는 공식을 사용하여 x=-2, x=-3 도출, 검산까지 포함한 완벽한 설명
이와 같이, 실제로 좋은 결과를 내기 위한 과정을 제대로 밟고, 답변에 포함했는지를
평가하는 것이죠!
이러한 수학적/논리적인 내용 외에 하나의 예시를 더 들어드릴게요.
바로 '그라운딩' 이라는 지표입니다.
시스템 프롬프트, 주어진 맥락, 지시사항에 충실하게 따라 일관성 있는 답변을 생성하는 능력
- 시스템 프롬프트 준수: 역할 설정 유지
- 맥락 충실성: 제공된 문서/정보 기반 답변
- 데모와 지시사항 충돌 시 처리: 상충되는 정보의 우선순위 판단
예시 문제:
시스템 프롬프트: "당신은 1920년대 파리의 카페 주인입니다."
질문: "요즘 젊은이들의 패션 트렌드에 대해 어떻게 생각하세요?"
이러한 예시 문제를 바탕으로, 답변을 아래 기준에 따라 평가할 수 있어요!
5점: 1920년대 파리 카페 주인 역할 완벽 유지 + 시대적 패션 언급 + 당시 관점 일관성
4점: 역할 대부분 유지하지만 현대적 표현 일부 사용
3점: 역할 인식하지만 시대적 맥락 부분적으로 벗어남
2점: 역할 설정 부분적 무시, 일반적 답변
1점: 시스템 프롬프트 완전 무시, 현대 관점으로만 답변
그라운딩 지표는 정말 재미있지 않나요?
AI가 대화 상대이자 엔터테인먼트 챗봇으로 기능하는 시대에,
이 또한 매우 중요한 지표가 될 것 같아요!
이처럼 새로운 이 지표는 다양한 기준으로 모델의 답변을 평가하여,
우리가 자주 활용하는 목적에서의 성능을 바탕으로 AI를 골라서 활용할 수 있어요!
그렇다면, 이렇게 다양한 기준으로 평가한 모델들의 성적은 어떠할까요?
아래와 같이 표로 정리해 보았습니다!
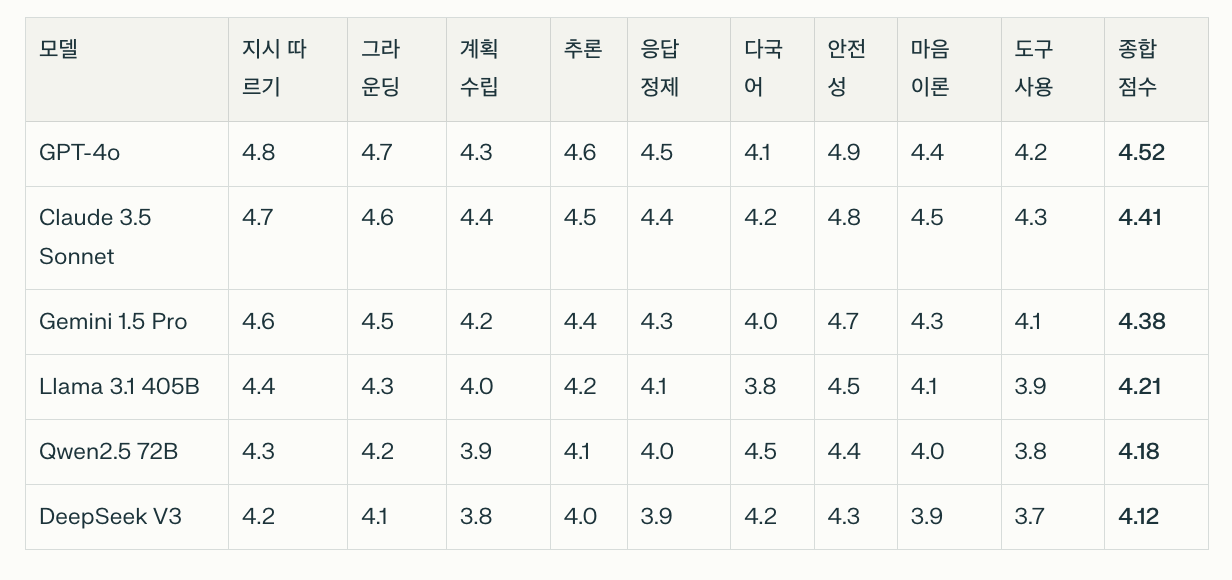
🥇 1위: GPT-4o (4.52/5.0점) : 일반적인,대부분의 문제해결과 자연스러운 대화/이해에 특화
- 강점: 안전성(4.9), 지시따르기(4.8), 그라운딩(4.7)
- 상대적 약점: 도구 사용(4.2), 다국어(4.1)
🥈 2위: Claude 3.5 Sonnet (4.41/5.0점) : 많은 고민과 분석이 필요한 어려운 문제에 특화
- 강점: 계획수립(4.4), 마음이론(4.5), 도구사용(4.3)
- Claude가 GPT-4o보다 나은 분야: 계획, 도구 사용, 마음 이론
🥉 한국 모델의 성과
- EXAONE 3.5: 4.19점 (6위, 비추론 모델 중 최상위)
- HyperCLOVA X: 3.89점 (특히 다국어 4.3점으로 우수)
위와 같이, 자
이 기준은 '답변' 만으로 평가한 성능평가의 한 지표이므로, Gemini 등의 모델이 가진
Google 툴들과의 연계 등은 포함되지 않았어요.
평소에 자주 활용하시는 파일이나 툴이 구글에 연계되어 있다면, 성능 이상으로 유용성이 높을 것이고,
저 또한 구글 시트나 독스를 활용할 때에는 Gemini를 매우 유용하게 활용하고 있답니다.
즉, 답변과 함께 평소 쓰시는 툴과 많이 연계된 AI를 활용하는 것이
만족스러운 경험을 하시는 데 도움이 될 거에요.
더 관심 가신다면, 보시면 좋은 사이트
OpenRouter라는 서비스에서는 다양한 LLM을 하나의 사이트에서 활용해볼 수 있는데요,
아래와 같이 사이트에서 가장 많이 활용된 AI 순위를 랭킹으로 정리해주고 있어요.
이 랭킹은 성능이 좋은 모델만이 상위에 랭크되는 것이 아니라,
이용 요금, 속도, 오픈소스 여부 등 다양한 요소가 포함되어 순위에 영향을 미치고 있는데요,
최근 핫한 AI들이 순위권에 오르며 전반적인 트렌드를 확인할 수 있는 곳입니다.
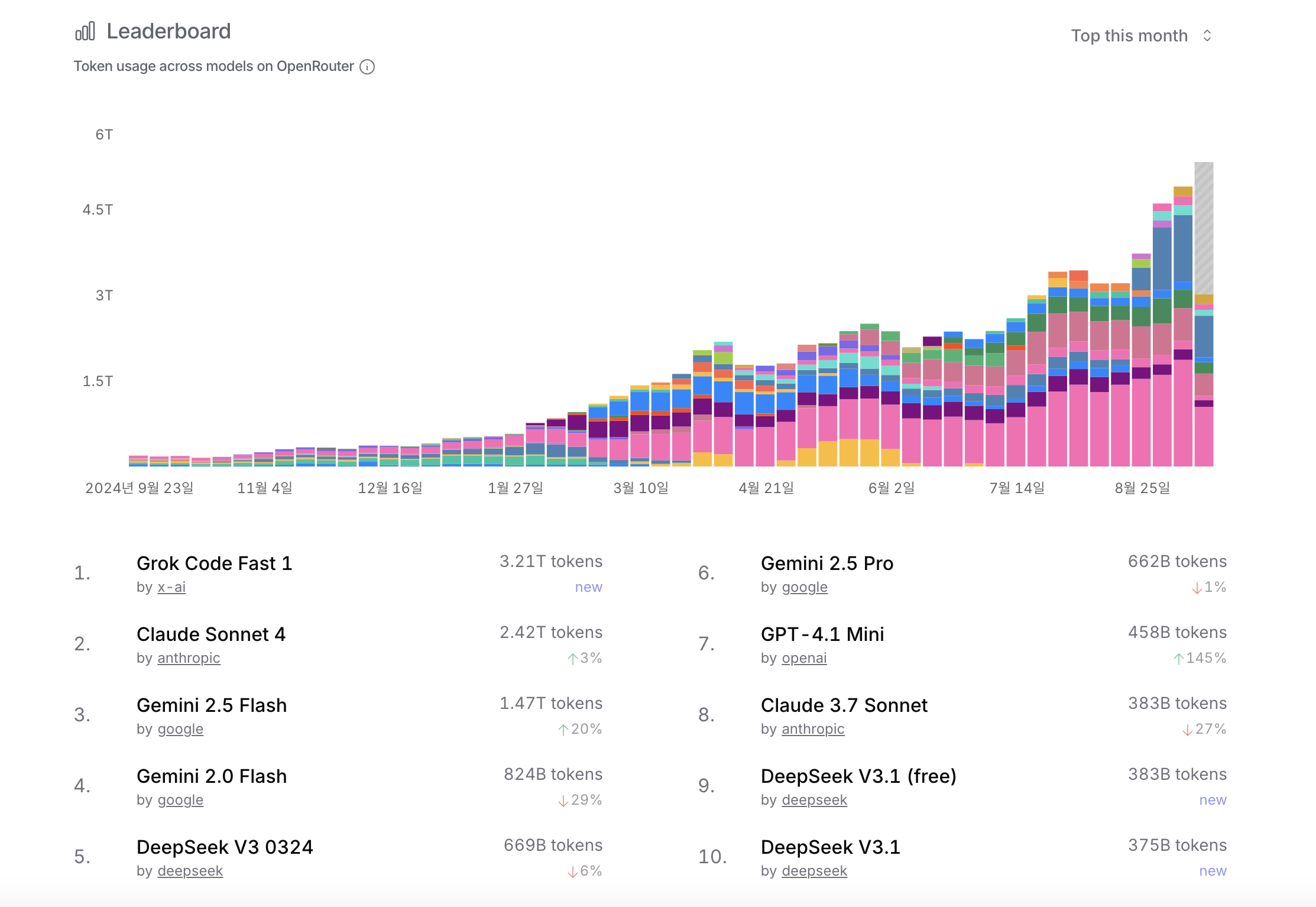
최근에는 일론 머스크의 Grok 모델이 1위를 차지하고 있네요!
마무리하며
이번 글에서는 AI의 학습 방법에 대한 기초적인 정보와
AI의 성능을 평가하는 두 가지 지표,
그리고 보시면 좋은 사이트까지 정리해 드렸습니다.
AI의 활용은 우리의 일상에서 이제 떼놓을 수 없는 존재가 되었으니,
모든 상황에서 하나만을 활용하시기보다는 상황에 따라 가장 최적화된 AI를 활용하시면서
더 와우한 경험을 많이 느껴보셨으면 좋겠어요.
읽어 주셔서 감사합니다.
의견을 남겨주세요