
시작하며 : AI 시대의 새로운 콘텐츠 생태계
여러분들은, AI 영상을 어떻게 받아들이시나요?
이제 모든 플랫폼에서 AI 제작 영상을 볼 수 있게 되었고,
누구나 앉은 자리에서 노트북만으로 높은 퀄리티의 영상을 만들 수 있게 되었죠!

이런 현상을 보시면서 기술의 혁신, 창작 생태계의 파괴, 놀라운 결과물 등 긍정적 반응과 부정적 반응이 공존할 것으로 보이는데요,
이번 글에서는 저부터 생태계 이해를 위해 Veo3로 영상을 제작해 본 기록과 팁을 공유하면서,
실제로 영상을 제작 해보고, 마케팅, IT 업계에서 느낀
전반적인 AI 제작 영상을 비롯한 콘텐츠의 명암에 대해 다루어 보려고 해요.
AI 콘텐츠, 영상은 어떻게 만드는 것이 좋은지 궁금하셨다면,
수없이 봐 온 AI 제작 콘텐츠가 어딘가 찜찜하거나, 불쾌한 느낌을 받으셨다면,
혹은 그 반대로 규제 없이 자유롭게 만들 수 있어야 한다고 생각하신다면,
이 글을 읽어보시면 팁과 생각거리를 가져가실 수 있을 거에요.
그럼, Veo3에 대해 소개해 드릴게요!
Veo3 : 특이점이 온 구글의 AI 영상 제작 툴
'특이점이 왔다' 라는 표현, 많이 들어보셨죠?
AI에서 말하는 특이점(singularity)은
인공지능이 인간의 지능을 완전히 넘어서는 결정적인 순간을 뜻해요.
그리고, Veo3는 제가 처음으로 특이점이 왔다고 느낀 구글의 영상 툴입니다.
Veo3는 구글이 개발한 최신 생성형 동영상 AI로,
실제 같은 시네마틱 영상 생성에
입의 움직임과 완벽히 싱크되는 자연스러운 오디오 생성까지 합쳐져 많은 주목을 끌었습니다.
사용해보시려면 Google AI Pro 이상을 구독해주시면 되어요.
아래 링크를 클릭하시면 Gemini 툴 내에서, 혹은 Flow라는 전문 툴 내에서도 활용할 수 있어요.
https://deepmind.google/models/veo/
Veo
Introducing our state of the art video generation model Veo 3, and new capabilities for Veo 2.
먼저, 직접 Veo3를 써 보면서 보시는 분들께서 적용하실 수 있는 전체적인 팁을 정리해 보았어요.
Veo3 영상 제작의 3가지 핵심 원칙
먼저, 중요한 핵심 3가지를 정리하고 시작할게요.
1장면 1프롬프트:
AI 영상 제작 툴은 아직 복잡한 서사나 매끄러운 장면 전환을 스스로 구현하는 것에 어려움이 있어, 화면 전환을 기준으로 하나의 화면을 제작해야 합니다.
1장면 1등장인물:
1개의 장면에 2명 이상의 등장인물이 상호작용할 경우, 한 명이 어색하게 움직이거나 오류를 발생시키므로, 1개 장면에는 1명의 등장인물을 쓰는 편이 좋습니다.
영상 내 텍스트 최소화:
AI 이미지 생성과 마찬가지로, 영상 생성 또한 텍스트를 사용할 경우 깨지는 케이스가 많아, 되도록 텍스트가 표시되지 않는 콘텐츠가 유리합니다.
이렇게 요소로만 보셨을 때는 이해가 완전히 되지 않으실 수 있는데,
이제부터 이어질 저의 실제 제작 과정을 보시면 좋을 것 같습니다!
Veo3로 물 마시기 앱 홍보영상 제작
영상의 주제부터 간단히 정해보면 되겠죠!
저는 최근 물을 자주 마시는 데에 관심이 있어서,
가상의 물 마시기 앱을 정하고, 그 앱을 홍보하는 영상을 제작해보기로 하였습니다.
GPT의 도움을 받아, 가상의 앱 서비스 이름과 컨셉, 슬로건을 정해보았어요.

서비스의 이름은 '꼴깍' 으로 정했습니다.
서비스의 컨셉을 정한 다음, 전반적인 영상의 큰 그림을 그려보고자 하였습니다.
'꼴깍' 이라는 서비스 자체가 코믹하고 귀여운 무드가 있으니,
언어유희를 활용해서 피식 웃음이 나는 무드로 요청해 보았습니다!

확실한 컨셉이 있는 것 같아 좋았고, 초중반 컷도 잘 나뉘어 있어서 이 버전으로 제작해 보기로 했어요!
영상 제작 로드맵은 아래의 3단계로 구상하였습니다.
1. 시나리오 구체화 및 장면 분할
2. 장면별로 프롬프트 입력해서 영상 생성
3. 영상 합치기 및 편집
Veo3가 한 번에 제작할 수 있는 영상의 길이는 8초 내외이므로,
아래 순서대로 구체화된 시나리오를 여러 번에 나눠서 제작하고, 이어 붙이고자 했어요.
먼저, 아래와 같이 시나리오를 구체화하고 장면별로 영상을 분할했어요.

그리고, 캐릭터의 페르소나를 정하고, 미리 이미지로 생성해보고자 했어요!
Veo3 관련 많은 문서에서, 이미지를 미리 생성하고 이를 바탕으로 영상을 생성한 결과물이
바로 영상을 제작한 결과물 대비 더 뛰어났기 때문입니다.
이에, 주요 캐릭터를 설정하고, 각 캐릭터의 이미지를 생성할 프롬프트를 제작했어요.

프롬프트는 보통 영어로 하는 것이 이해도가 높더라구요!

완성되었습니다, 영상의 주인공들!
이렇게 완성한 이미지를 활용하여 영상을 만들 수 있는 프롬프트 제작을 요청했어요.
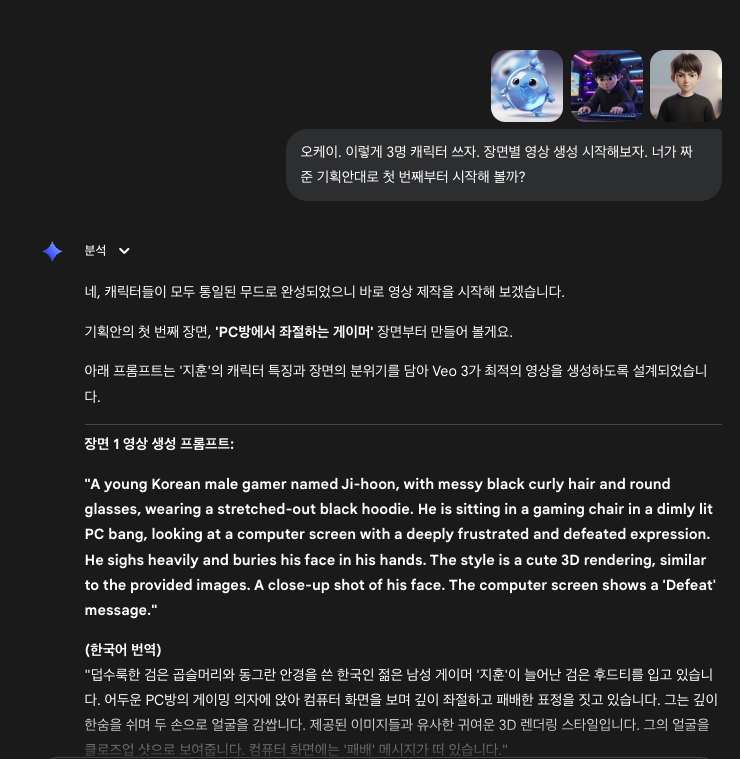
이렇게 세 등장인물에 대한 프롬프트를 만들었으나,
제가 놓친 것이 있었는데, Veo3에서의
실제 영상 생성 시에는 1번의 생성당 1장의 사진만을 활용할 수 있었어요.
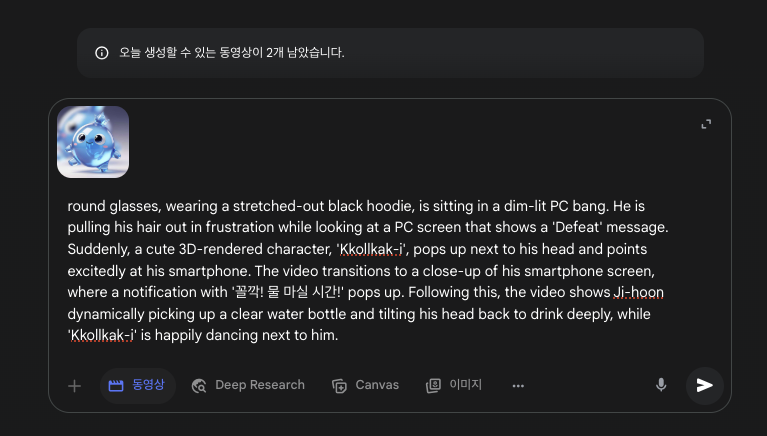
한 번의 생성에 1개의 프롬프트와 1장의 사진만을 활용할 수 있어요.
그러면, 민준이, 지훈이, 꼴깍이가 모두 1장에 들어가 있는 이미지를 제공해야 할 거라고 생각했습니다.
이에, 이미지 3개를 주고, 프롬프트를 활용하여 한 장면에 모두 포함된 이미지를 생성했어요.
이 이미지를 바탕으로 장면 1을 만들어 보고자 했죠!
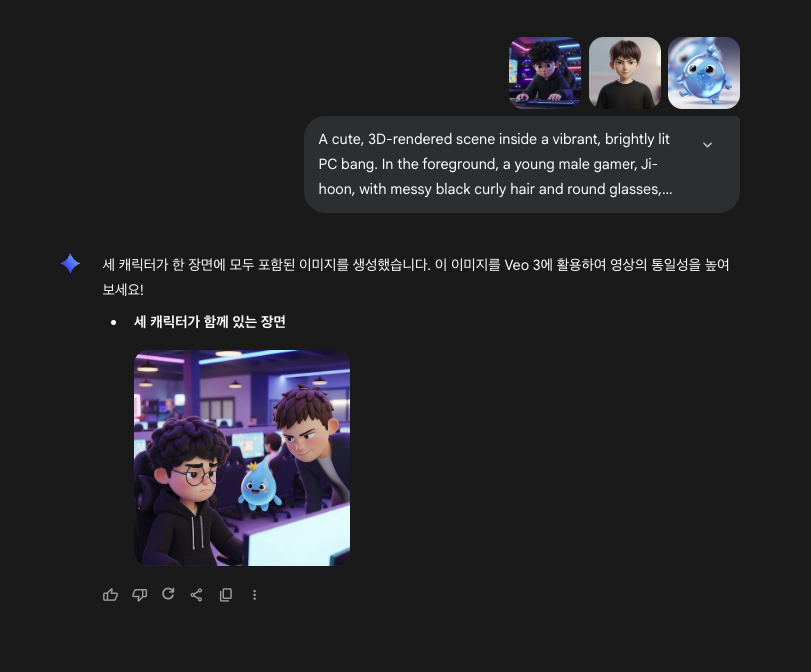
1번째 장면과 3명의 등장인물이 모두 등장한 이미지를 넣고, 생성을 시작합니다!
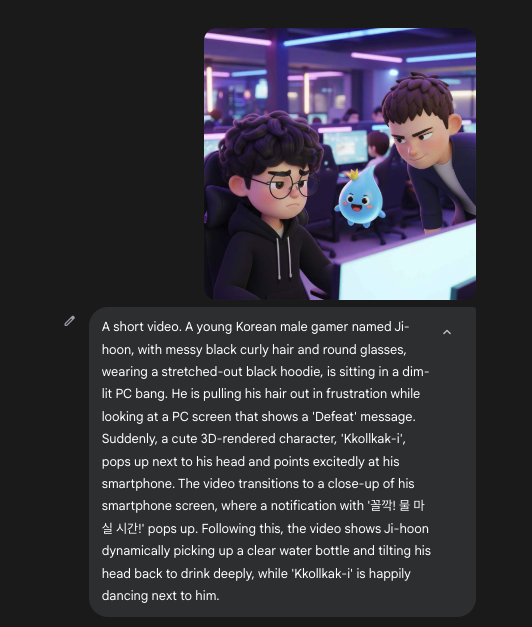
이렇게 영상을 만들어 봤으나, 결과는 크게 만족스럽지는 않았습니다.
영상 결과물 : https://youtu.be/E1bVvht17O8



문제는 크게 4가지로 파악되었어요.
1. 장면이 나뉘어져 있지 않아서 전환이 없음. 화면 전환 없이 defeat 이미지가 나옴.
2. 지훈이는 영상에는 있으나 역할이 없으니 아무것도 하지 않다가 퇴장
3. 갑자기 민준이가 지훈이한테 뭐라고 하는, 프롬프트와 반대가 되는 장면이 제작됨.
4. 전반적으로 어색하고 퀄리티가 생각보다 떨어짐
이 문제가 반복되자, 계속해서 시도해 보는 것은 멈추고
다양한 자료를 바탕으로 문제의 원인과 해결책을 정리해 보았어요.
제작 과정에서 배운 점
자, 이제부터 글 초반에 말씀드린 팁이 도출된 과정을 다루어 보겠습니다.
문제점
- 장면 전환이 매끄럽지 않음: '좌절하는 지훈이'에서 갑자기 'VICTORY' 화면으로 넘어가는 등 장면이 뚝뚝 끊겼습니다.
- 캐릭터의 역할 상실: '민준이'는 프롬프트에 분명히 있었지만, 영상에서 하는 역할이 없어서 아무것도 하지 않고 서 있는 어색한 모습으로 구현되었습니다.
- 텍스트 깨짐: 앱 화면의 글자나 대사가 뭉개지고, 아예 나오지 않는 현상도 발생했습니다.
해결책
- 1장면 1프롬프트 : AI 영상 제작 툴은 아직 복잡한 서사나 매끄러운 장면 전환을 스스로 구현하는 것에는 어려움이 있어, 화면 전환을 기준으로 하나의 화면을 제작해야 합니다.
- 1장면 1등장인물 : 1개의 장면에 2명 이상의 등장인물이 상호작용할 경우, 한 명이 어색하게 움직이거나 오류를 발생시키므로, 1개 장면에는 1명의 등장인물을 쓰는 편이 좋습니다.
- 텍스트는 되도록 사용하지 않을 것 : AI 이미지 생성과 마찬가지로, 영상 생성 또한 텍스트를 사용할 경우 깨지는 케이스가 많아, 되도록 텍스트가 표시되지 않는 콘텐츠가 유리합니다.
세 가지 팁에 대해 더 자세히 다뤄볼게요.
첫 번째, 줄글 형태의 프롬프트보다는 구조화된 형태의 프롬프트가 좋습니다.
물론 줄글 형태로도 잘 생성되고,
chatGPT나 Gemini에게 물으면 충분히 프롬프트를 잘 생성하지만,
이 형태의 프롬프트의 문제는 가독성이 떨어져, 우리가 원하는 형태로 수정하기가 어렵다는 점이에요.
그리고, 줄글 형태일 때 지시하지 않은 요소를 생성하는 '할루시네이션' 도 더 많이 나타난다고 해요.

위와 같이 항목별로 구조화된 프롬프트를 제작하여, 생성 결과의 일관성을 확보하고
수정하고자 하는 항목을 바로 찾아서 수정할 수 있도록 하는 게 좋습니다!
출처를 밝히며, 매우 잘 구조화되었다고 생각하는 영상생성용 프롬프트를 남깁니다.
잘 참고하시어 활용해보시길 바래요!
한글 프롬프트 :
{
"character_profile": "[고정된 캐릭터 외형 설정 — 키, 체형, 머리/피부/눈/의상, 액세서리, 소지품, 고유 특징 등. 모든 씬에서 완벽히 동일해야 함]",
"scene_overview": "현대적 배경에서 리얼 셀피 영상처럼 보이는 8초짜리 장면. 캐릭터가 매 장면에 같은 모습과 목소리로 등장하며, 장소와 행동은 바뀜.",
"location_and_action": "[캐릭터가 등장하는 장소와 그곳에서 하고 있는 행동을 묘사. 주변 상황과 맥락도 함께 설명]",
"spoken_moment": "[짧고 자연스러운 대사나 내면의 말 — 감정이 담기면 좋음. 너무 길지 않게]",
"camera_style": "[팔을 뻗은 셀피 / 고정된 셀피 / 걷는 중 셀피 중 선택]",
"tone_of_voice": "[목소리의 톤, 높낮이, 억양, 말투, 속도 등 — 전체 영상에서 완전히 일관되게 유지]",
"footage_type": "real footage",
"duration": "8 seconds"
}
영문 프롬프트 :
{
"character_profile": "[Detailed and fixed visual traits — height, body shape, hair/skin/fur color, outfit, accessories, props, any unique features. These must never change throughout all scenes.]",
"scene_overview": "A realistic selfie-style video clip set in the modern day. The fixed character appears in each scene with consistent visuals and voice, performing simple actions in different locations.",
"location_and_action": "[Describe where the character is and what they’re doing — include physical action and relevant environmental details.]",
"spoken_moment": "[Short spoken line or thought — should feel casual, natural, or emotionally resonant with the moment.]",
"camera_style": "[selfie with arm outstretched / steady handheld / walking selfie — pick based on motion]",
"tone_of_voice": "[Consistent voice setting — describe pitch, tone, accent, pacing, and delivery style. This should match across every clip.]",
"footage_type": "real footage",
"duration": "8 seconds"
}
출처 : 유튜브 돈디AI
유튜브 영상 출처도 남겨놓을테니, 프롬프트에 대해 더 궁금하시다면 들어가서 봐주셔도 좋을 것 같습니다!
https://www.youtube.com/watch?v=bZjIGlYaXOM
두 번째, 되도록 하나의 영상에 한 명의 인물을 사용합니다.
실제로 다양한 매체에서 제작된 AI 영상들을 보면, 2명 이상의 등장인물이 동시에 나오는 경우는 잘 없습니다.


두 명 사이의 상호작용을 프롬프트로 설계하는 것 또한 어렵고,
실제로 설계하더라도 두 명 이상의 등장인물 중 반드시 일부는 어색한 움직임을 보이기 때문이에요.
만약 두 명 이상의 등장인물을 사용하고자 한다면,
각 인물이 나오는 장면의 프롬프트를 따로 설계하여,
인물별로 따로 영상을 제작하여 이어붙이는 것이 좋습니다!
다수의 인물이 상호작용하는 프롬프트를 쓸 경우
현실적으로 퀄리티를 보장하기 어렵고, 오히려 프롬프트의 요구사항이 많아질수록
요구하지 않은 내용을 생성하는 할루시네이션의 위험도도 커지게 되어요.
세 번째, 캐릭터 이미지를 먼저 정하고 제작을 시작합니다.
위와 같은 원칙으로 프롬프트를 구조화하고 한 장면당 한 명이 나오도록 흐름을 설계하셨다면,
AI 이미지 생성이나, 이미 갖고 있는 캐릭터 등의 이미지를 꼭 생성 시 첨부하는 것이 중요해요.
하나의 영상이라고 할 때, 우리는 중간에 컷이 바뀌면서 인물의 얼굴이 조금이라도 바뀌면 바로 어색함을 느끼게 되므로,
완전한 이미지 레퍼런스를 주고, 이것을 철저히 따르도록 프롬프트를 설계하는 것이 중요합니다.
아래의 세 영상의 등장인물의 외모가 유사한 것도,
하나의 이미지를 생성하여 이를 바탕으로 영상을 제작했기 때문이에요.

Veo 3를 쓸 수 있는 Gemini는 같은 입력창에서 이미지 생성까지 지원하므로,
원하는 페르소나의 이미지를 먼저 생성한 뒤, 이를 활용하여 영상을 제작해보시길 바래요!
반드시 하나의 이미지에는 한 명의 인물만 표시되도록 영상을 분할하고
프롬프트를 제작해 주시는 것도, 잊지 말아주세요!
지금 도전해 볼 만한, Veo 3 영상 주제
여기까지 읽어주셨다면, 실제로 Veo 3를 써보시는 것을 추천드리는데요,
가장 추천드리는 주제는 '인터뷰' 입니다.
인터뷰 콘텐츠가 AI 생성 콘텐츠에 특화된 이유는 다음과 같아요.
1. 글자가 표출되지 않아, 글자가 잘릴 위험이 적어요. Veo3는 글자보다 음성에 강하기에, 음성 위주의 인터뷰 콘텐츠가 강점은 살리고, 약점은 줄일 수 있는 콘텐츠이죠!
2. 큰 장면 전환이 필요하지 않아요. 하나의 장면에서 많은 내용을 담음으로써, 오류의 확률을 줄이고 생성에 드는 크레딧을 크게 낮출 수 있어요.
3. AI의 장점을 살려, 힙한 음악을 듣는 할머니와 같이, 의외성을 쉽게 가져갈 수 있어요. 어울리지 않을 것 같은 것 두 가지를 믹스하여 주목을 끄는 것이죠!
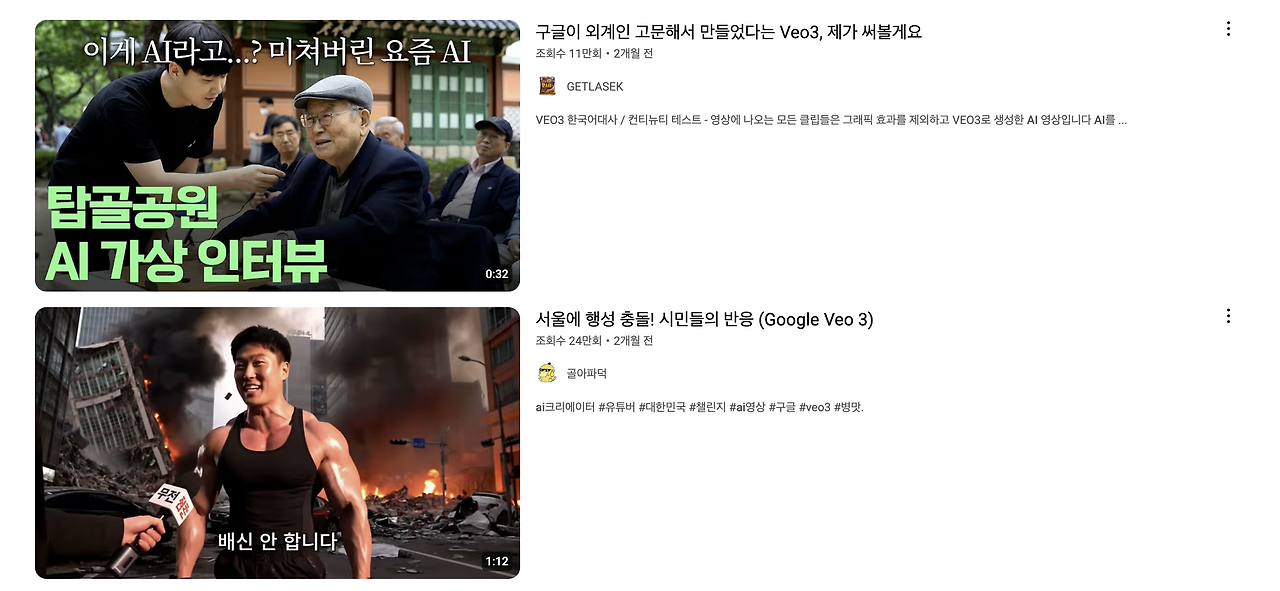
실제로 위와 같이 다양한 인터뷰 콘텐츠가 유튜브에서 사람들의 주목을 받고 있으니,
여러분의 재치를 잘 활용하여 꼭 만들어보시기를 추천드려요!
Veo3를 활용한 AI 영상 제작 팁은 이 정도로 마무리하고자 해요.
어떠셨나요,
이렇게 만들어진 AI 콘텐츠, 여러분은 어떻게 생각하시나요?
저는 묘하게 제가 Veo3로 만드는 영상을 보면서 어색함, 거부감, 피로감이 들었는데,
AI가 만든 영상에 대한 묘한 거부감이나 피로감, 기시감의 출처에 대해 스스로 고민이 되어
그 원인에 대해 정리해 보았어요.
AI로 만들어진 콘텐츠, 유쾌하신가요?
모두가 AI 콘텐츠를 유쾌하게 받아들이지는 않습니다.
최근 업계에서는
사람들이 AI로 만든 콘텐츠가 늘어남에 따라 피로감을 느끼고,
저품질의 AI 콘텐츠가 늘어나면서 검색 엔진과 AI 모델에 영향을 미치고 있다고 해요.
즉, 사람들이 AI 콘텐츠를 유쾌하지만은 않게 받아들이고 있다는 것인데요,
그 이유가 무엇일까요?
먼저, AI로 쓴 글 형태의 콘텐츠에 대해 다루어 보겠습니다.
실제로 구글이나 네이버에서 검색했을 때, 점점 AI만으로 생성된 글이 많아지고 있죠!
직접 쓴 글이 아니라, AI가 작성한 글을 그대로 업로드한 글이 정말 많아요.
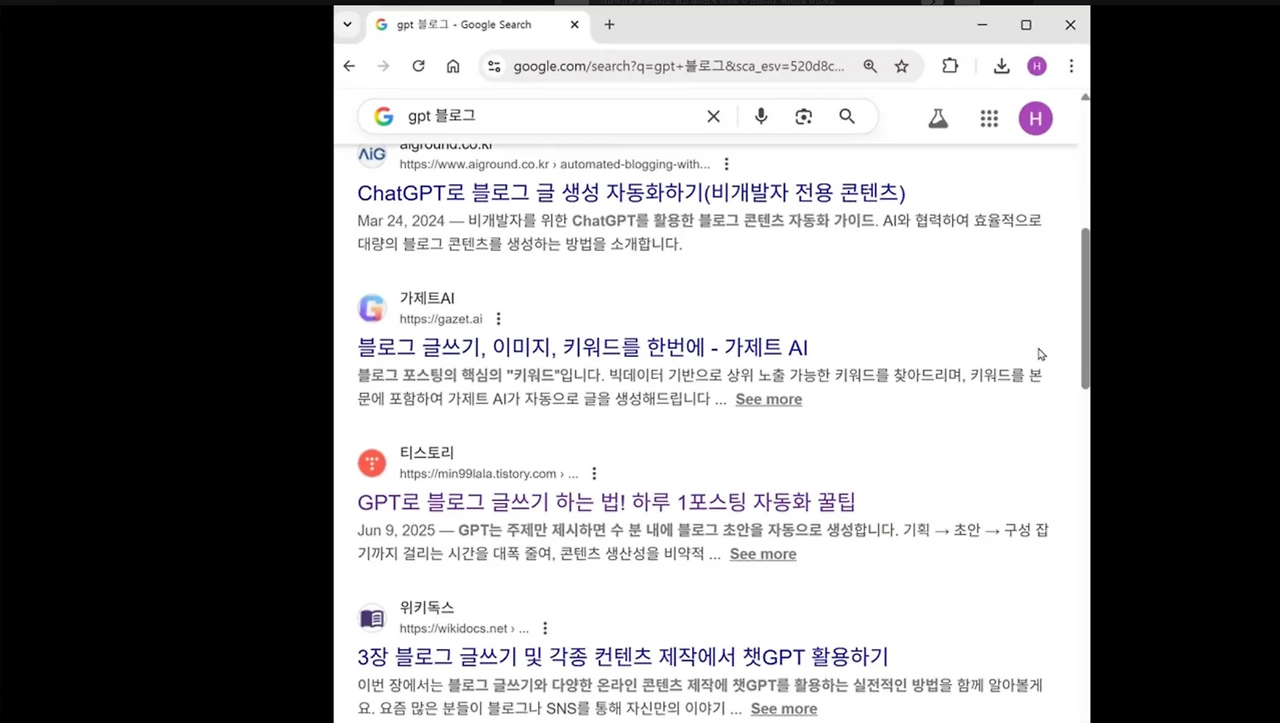
모든 글이 그런 것은 아니지만, 사람이 쓴 것에 비해 정보성이나 가치가 떨어지는 비중이 높으며,
아래와 같이 무분별한 AI 사용으로 네이버 블로그 마크다운 활용법과 같은
할루시네이션이 나오는 경우도 많습니다.

이렇게 AI를 활용해서 만드는 글 콘텐츠가 늘어날수록, 직접 사람이 만든 콘텐츠가 적어지고,
콘텐츠가 모두 일원화되어 저품질의 콘텐츠를 학습하는 AI 또한 저품질의 결과를 내놓는다는,
Garbage in Garbage Out의 상황이 벌어지고 있어요.
그 결과로, 사람들의 검색 유입 트래픽, 검색량은 AI 런칭 이후 꾸준히 줄어들며,
AI로 생산되는 수많은 콘텐츠들의 질이 떨어진다고 평가받기 시작하며
이를 소스로 하는 검색 유입 자체가 외면받는 현상이 나타나고 있어요.
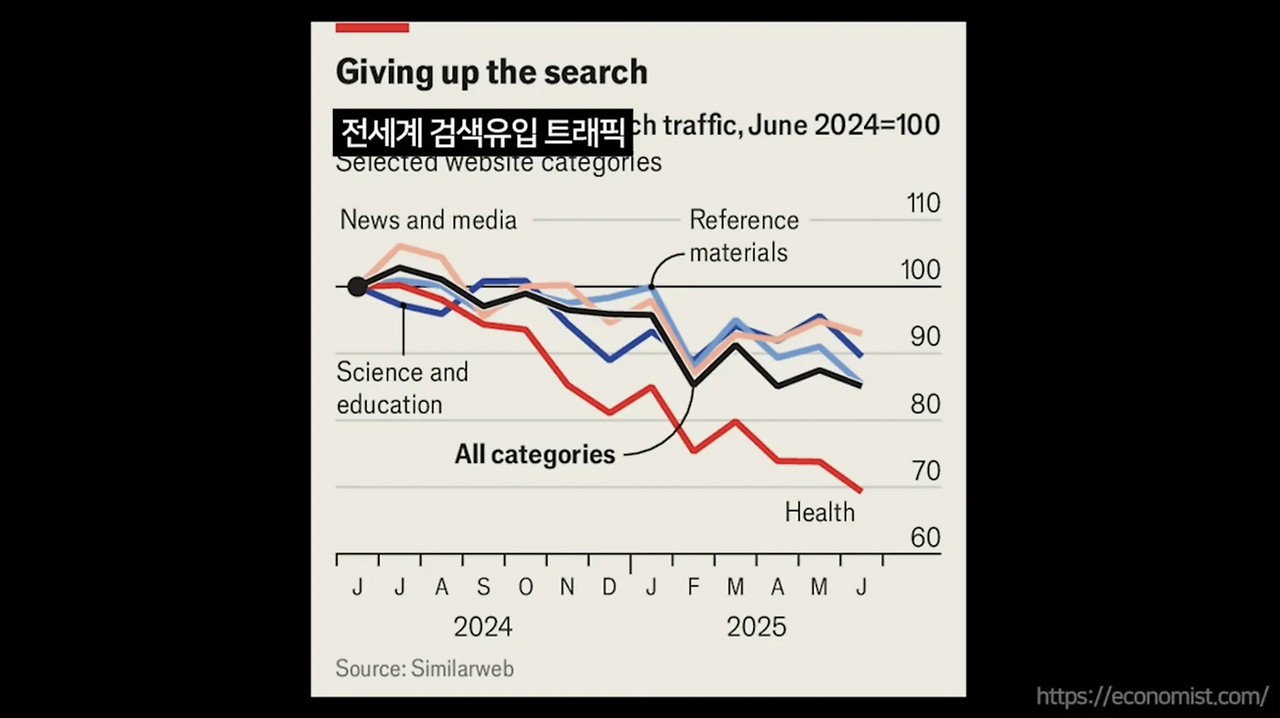
AI 영상에 관해서도 마찬가지이죠.
AI 동영상 제작 툴이 발전하면서 아래의 AI ASMR처럼,
AI가 없었을 때는 만들 수 없었던 콘텐츠들이 만들어지고 있기도 해요.
어떠신가요? 보신 적 있으신가요?
AI가 하나의 장르가 되어 새로운 형태의 콘텐츠를 만든다는 측면에서는 긍정적이지만,
저는 어쩐지 어색하고 묘하게 조금 불쾌한 기분이 들 때도 있습니다.
AI 영상 콘텐츠가 주는 이러한 기분의 원인은 '불쾌한 골짜기' 이론과 관련있다고 생각해요.

아예 인간의 모습과 다른 AI 영상부터, 인간을 따라한 영상에서 특히 느껴지는 이 감정은
본래의 모습이 아닌데 이를 따라하는, 소위 어설프게 닮을수록 느껴지는 불쾌함이라고 생각합니다.
또한 고려대 미디어학부에서 진행한 연구에서는,
AI가 생성한 영상과 사진이 뉴스와 같은 실용적 콘텐츠에 쓰였을 때 부정적으로 인식하는 비율이
드라마나 영화처럼 즐거움(쾌락성)이 큰 콘텐츠에 비해 매우 높게 나왔어요.
특히 이미지나 영상을 AI가 만든 경우,
팩트가 의심되는, "진정성"에 대한 우려로 부정적 답변이 더 많았다고 해요.
그에 반해 AI가 작성한 뉴스 기사 글(텍스트)에는 불만족 반응이 거의 없었습니다.
https://www.yna.co.kr/view/AKR20241213105300017
"생성형 AI가 만든 영상, 뉴스에 사용되면 부정적 인식" | 연합뉴스
이처럼 AI 영상을 즐기시는 분들도 있지만,
영상을 보면 불쾌하다, AI 티가 난다라고 이야기하시는 분들도 많습니다.
그렇다면, 사람들은 AI 콘텐츠 자체를 싫어하는 것일까?
저는 그렇지 않다고 생각합니다.
AI로 제작된 콘텐츠 자체를 싫어한다기보다는
첫째, 충분한 노력을 하지 않고 생산되어 진정성과 사실성이 의심되는,
둘째, 획일화된 콘텐츠를 싫어하는 것이라고 생각해요.
먼저, 우리는 AI로 만들어진 콘텐츠가 사람이 만든 콘텐츠에 비해 쉽게 만들어진 것이라는 인식이 있기에
제작에 들인 노력을 높게 평가하지 않고, 신뢰하지 않는 경향이 있어요.
https://mitsloan.mit.edu/ideas-made-to-matter/study-gauges-how-people-perceive-ai-created-content
실제 MIT Sloan 연구실의 연구에 따르면,
마케팅 문구를 사람, AI, 또는 혼합 방식으로 제작한 콘텐츠를 사람들에게 보여주고 평가하게 한 결과,
콘텐츠 출처를 알지 못할 때는 AI가 만든 결과물을 더 선호하는 경향이 있었지만,
출처를 알게 되면, 사람이 관여한 작업에 대해 ‘인간 편애(human favoritism)’를 보이며 평가 점수가 높아짐을 발견했습니다.
이는, 사람들은 AI가 만든 결과물 자체를 싫어하지는 않지만, ‘사람이 정말 노력해서 만들었다는 증거’를 중요하게 여기고, 이것이 '인간 편애' 라고 명명한 현상으로 나타나는 것이죠!
또한, 사람들은 AI의 획일성으로 인해 유사한 콘텐츠가 많아져 피로감을 느끼고 있습니다.
인간이 쓴 글은 형식과 주제의 전개에서 각자의 개성과 목소리를 지녔지만,
AI의 글은 대규모 학습 데이터를 바탕으로 가장 무난한 방식으로 글을 쓰기 때문이죠!
실제로 미국의 칼럼 The New Yorker에서는
AI 도구를 쓴 글이 AI를 쓰지 않는 집단에 비해
문화적·내용적 편차가 줄고 모든 글이 비슷한 스타일과 소재로 쏠리는 현상을 다루기도 하였습니다.
https://www.newyorker.com/culture/infinite-scroll/ai-is-homogenizing-our-thoughts

출처 : The Newyorker
다시 말해, 우리는 AI 콘텐츠 자체를 싫어하기보다는
진정성이 의심되는, 획일화된, 개성이 들어가 있지 않은 콘텐츠에 너무도 많이 노출되어,
그에 대한 피로감을 느끼고 있는 것으로 보여요.
역설적으로, 인간 창작자의 가치가 더 높아질 것 같습니다.
이런 때일수록 다시 우리는 직접 글을 쓰고 콘텐츠를 만들어야 합니다, 우리의 충분한 노력을 들여서요.
AI가 참고하는, AI 검색 최적화의 조건에도 충분한 인사이트를 제공할 것이라는 조건이 있고,
지금처럼 사람들의 선호가 사람이 직접 제작한 콘텐츠에 집중된다면
오히려 직접 제작한 콘텐츠가 AI와 검색 엔진, 알고리즘에 더 많이 노출될 것이에요.

AI를 철저히 주체가 아닌 도구로 두는 것이,
그리고 콘텐츠는 충분한 인간의 고민이 들어가 있도록 하는 것이,
콘텐츠 제작자로서 보는 사람에게 선택받고 스스로도 성장하는 길이라고 생각해요.
저도, 좀 더 제 노력을 많이 들인 기획과 연출로 Veo3를 다시 활용해봐야겠어요.
결과물에 대해 느낀 아쉬움은 영상 제작 실력뿐 아니라 저 스스로 AI의 도움을 받아
크게 고민하지 않고 제작한 영상이었기 때문이 아니었을까 합니다.
읽어주셔서 감사합니다.
AI 활용 여부에 무관하게 모든 분야의 창작자를 응원합니다!
의견을 남겨주세요