
초록
본 연구는 사용자가 챗봇을 제작하고 상호작용할 수 있는 급성장 소셜미디어 플랫폼 Character.AI의 공개 챗봇에 대한 최초의 대규모 분석 결과를 제시한다. Character.AI는 생성형 AI와 사용자 제작 콘텐츠(UGC)를 결합한 독특한 플랫폼으로, 사용자들이 주로 가상의 캐릭터나 유명인을 모델로 한 봇을 만들어 다른 사용자들과 대화할 수 있도록 한다.
이를 위해 우리는 해당 사이트 챗봇의 210만 개 영어 프롬프트(일명 "인사말") 데이터셋을 활용하여 플랫폼에 대한 기술적 개관을 제시한다. 이 데이터는 약 100만 명의 사용자가 생성한 것이다.
본 연구는 사이트 내 다양한 팬덤의 유행 양상, 팬덤 전반에 걸쳐 지속적으로 나타나는 보편적 트로프, 그리고 권력 역학이 인사말에서 젠더와 어떻게 교차하는지를 탐구한다. 전반적으로 우리의 연구 결과는 생성형 AI와 사용자 제작 콘텐츠 간의 독특하고 중요한 접점에서 나타나는 새로운 형태의 온라인 (준)사회적 상호작용을 조명한다.
서론
본 연구는 Character.AI에서 수집한 콘텐츠에 대한 최초의 대규모 분석 결과를 제시한다. Character.AI는 사용자들이 1) 프롬프팅 및/또는 간단한 파인튜닝을 통해 챗봇을 제작하고, 2) 다른 사용자들이 만든 챗봇과 상호작용할 수 있는 웹사이트다(그림 1 참조).
뉴욕타임스에 따르면, 이 사이트는 2024년 10월 기준 월간 활성 사용자 2천만 명 이상을 보유하고 있다(Roose 2024). SimilarWeb 통계에 의하면 이 중 절반 이상이 24세 이하였다. 2025년 4월 애플 앱스토어 엔터테인먼트 카테고리에서 34위를 기록했으며, 2024년 4월에는 생성형 AI 사이트 중 3위를 차지했다.
또한 Character.AI의 공식 서브레딧인 r/CharacterAI는 250만 명의 구독자를 보유하고 있다. 참고로 YouTube의 서브레딧은 320만 명의 구독자를 갖고 있다.
따라서 여러 지표를 종합하면 Character.AI는 특히 젊은 층 사이에서 광범위하게 사용되고 있음을 알 수 있다. 또한 적어도 일부 사용자들의 일상에서 상당한 비중을 차지하는 것으로 보인다. 2024년 10월 기준 평균 사용자는 이 플랫폼에서 하루 한 시간 이상을 보냈다.
더욱 심각한 사례로, 뉴욕타임스는 2024년 10월 14세 소년의 자살과 관련해 Character.AI의 책임을 묻는 소송을 보도했다(Roose 2024). 타임스가 보도한 소송 내용에 따르면, 이 아이는 인생의 마지막 몇 주 동안 왕좌의 게임 캐릭터인 대너리스 타르가르옌을 모방한 챗봇과 깊이 관여했으며, 여기에는 자살 가능성에 대한 논의도 포함되어 있었다.
이는 Character.AI가 사용자들에게 미치는 영향에 대해 공개적으로 논의된 여러 사례 중 하나이며(Upton-Clark 2024), AI와 정신 건강 간의 관계에 대한 보다 광범위한 우려의 맥락에서 이해할 수 있다(Adam and Nature Magazine 2025; De Choudhury, Pendse, and Kumar 2023).
즉, Character.AI는 Ellison and Boyd (2013)가 제시한 소셜 미디어 사이트의 공식 정의에 부합하지만, 사용자 상호작용이 거의 전적으로 한 사용자가 다른 사용자들이 만든 챗봇과 교류하는 방식으로 이루어진다는 점에서 독특하다.
물론 Character.AI는 오랫동안 소셜 미디어 사이트를 형성해왔다. 이는 추천 시스템을 통해 가장 명백하게 드러난다. 추천과는 달리, Character.AI에서 AI는 사용자 간 상호작용의 중개자 역할을 한다. 사용자들이 봇을 만들면 다른 사람들이 그 봇과 채팅하는 방식이다.
물론 사용자와 봇의 상호작용도 소셜 미디어에서 새로운 현상은 아니다. 그러나 소셜 미디어에서 기존의 봇 사용은 주로 악의적 의도(Stieglitz et al. 2018)나 정치적 목적(Gorwa and Guilbeault 2020)을 가지고 수행되거나, 대체로 은밀한 성격(Assenmacher et al. 2020)을 띠었다.
이 중 어느 것도 Character.AI에는 해당하지 않는다. Character.AI에서는 봇 생성이 권장되고 공개적이며, (앞으로 살펴보겠지만) 종종 악의적 의도보다는 (비록 문제가 있을 수 있지만) 놀이를 목적으로 한다.
마지막 점과 관련하여, Character.AI는 명시적으로 정치적 참여가 아닌 "사람들이 상호작용적 엔터테인먼트를 통해 연결하고, 배우고, 이야기를 전달할 수 있도록 역량을 강화하는 것"을 목표로 한다. 이런 식으로 Character.AI는 소셜 미디어이자 챗봇 사이트일 뿐만 아니라 AI와 함께하는 역할극과 팬픽션의 공간으로도 이해될 수 있다(Lamerichs and Ossa 2023).
그러나 팬덤 상호작용이 AI 기반이므로, 이 공간에서의 참여는 새로운 형태의 팬픽션을 창조한다. 한 사용자가 이야기의 매개변수를 설정하면 다른 사용자가 생성형 AI 모델과 함께 그 이야기를 구성할 수 있다. 이러한 복잡성이 Character.AI를 흥미로운 연구 대상으로 만든다.
이러한 관행이 웹의 다른 곳에서도 확산되고 있다는 점도 주목할 만하다. 유사한 소셜 봇(Bessi and Ferrara 2016) 활용이 더욱 일반화되고 있으며, 이 분야의 대기업들, 특히 OpenAI는 사용자들이 다른 사용자들이 만든 챗봇과 상호작용할 수 있는 유사한 시스템을 구축하기 시작하고 있다.
따라서 Character.AI는 계산사회과학 커뮤니티에 실용적으로나 개념적으로나 관심의 대상이다. 실용적으로는 일부 사용자들에게 중요한 영향을 미치는 성장하는 웹 플랫폼이지만 아직 대규모로 연구되지 않았다.
개념적으로는 사람들이 자신과 다른 사람들을 위해 생성형 AI를 어떻게 구성하려고 하는지, 그리고 더 명시적으로 AI 모델과 협력하여 어떤 인물, 정체성, 그리고/또는 이야기와 교류하고 싶어하는지를 탐구할 수 있는 독특한 장소를 제공한다. 또한 생성형 AI 시대의 새로운 유형의 소셜 미디어 플랫폼 역학을 이해할 기회를 제공한다.
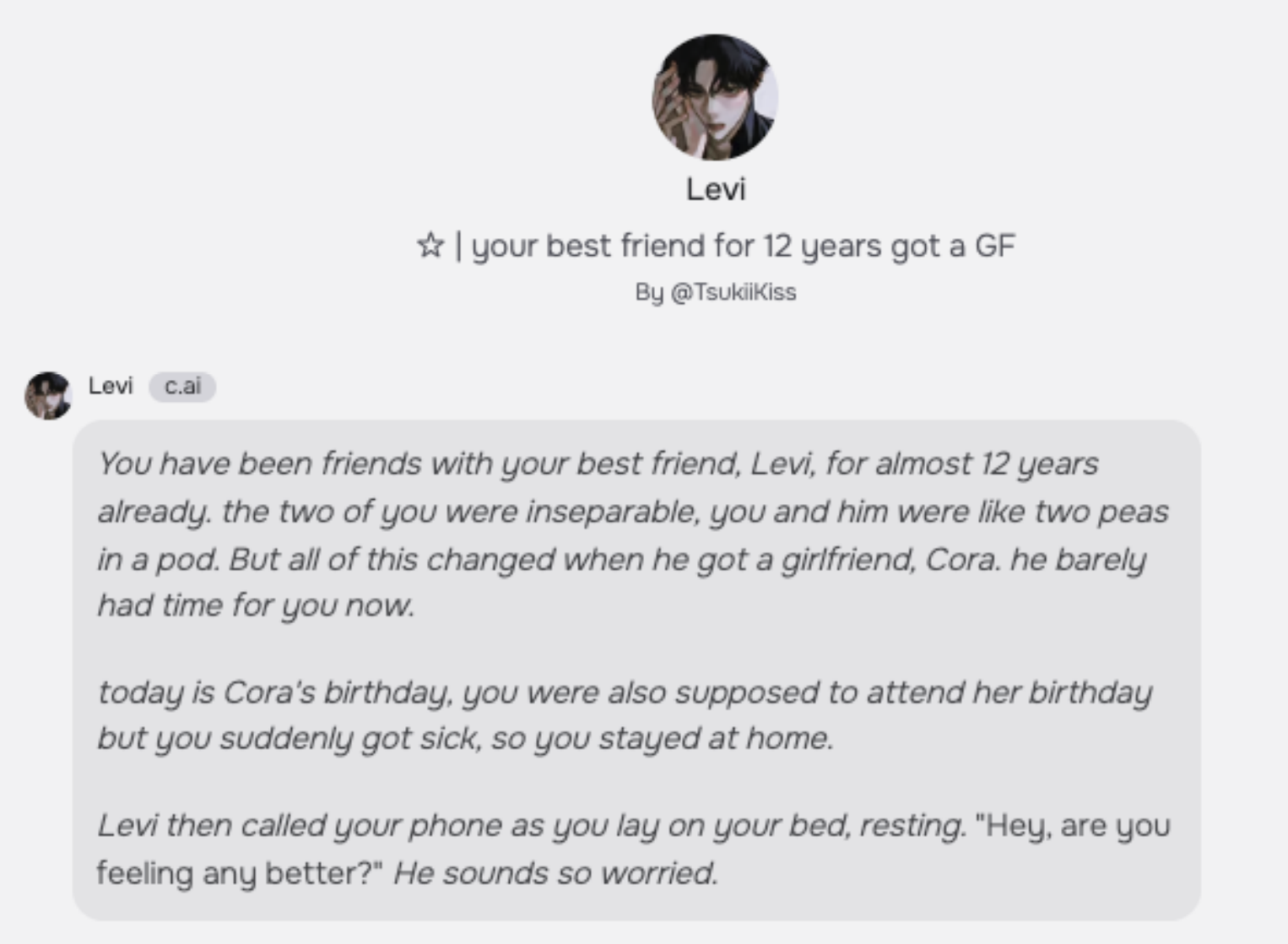
이를 위해 우리는 Character.AI에서 사용자들이 만든 210만 개의 캐릭터에 대한 대규모 분석을 제시한다. 우리는 챗봇을 구성하고 다른 사용자들에게 소개하는 데 사용되는 2,135,118개의 영어 프롬프트 세트에 초점을 맞춘다. Character.AI는 이를 인사말(greeting)이라고 부른다. 사이트의 인기 챗봇 인사말 예시는 그림 1에서 확인할 수 있다.
데이터는 사이트의 사용자 팔로우 관계에 대한 일련의 눈덩이 표집을 통해 수집되었다. 첫 페이지에 캐릭터가 나열된 사용자들부터 시작하여 6개월 동안 진행되었다. 우리의 데이터셋은 우리가 아는 한 플랫폼 콘텐츠의 상당한 부분을 나타낸다.
우리의 분석은 Character.AI 사용자들이 왜 캐릭터를 만드는지에 대한 광범위한 개관을 제공하는 것을 목표로 한다. 사이트에서 역할극의 중요성을 고려할 때, Character.AI의 일반적인 용도 중 하나는 챗봇을 사용하여 실제 또는 가상의 세계에서 스토리라인이나 인물을 연기하는 것이다. 우리는 이를 광범위하게 팬덤이라고 부를 것이다.
따라서 우리는 먼저 *사이트의 캐릭터들이 나타내는 가장 일반적인 팬덤은 무엇인가?*라고 묻는다. 그다음 팬덤을 넘어서는 관점으로 시선을 돌려 *모든 팬덤에 걸쳐 어떤 공통된 문화적 트로프가 널리 퍼져 있는가?*라고 묻는다.
이 두 질문에 대한 분석 결과를 바탕으로 우리는 마지막으로 캐릭터 자체와 비교하여 캐릭터와 상호작용하는 사용자에게 부여되는 사회적 역할을 탐구한다. 이를 위해 우리는 *인사말에서 언급되는 다른 개체들과 비교하여 챗봇의 사용자를 묘사하는 데 어떤 언어가 사용되는가?*라고 묻는다.
전체적으로 우리 연구는 세 가지 기여를 한다.
- Character.AI에 대한 최초의 대규모 분석을 제공한다. 이 과정에서 우리는 이러한 데이터를 수집하고 저장하며, 논문 게재 승인과 서명된 계약을 통해 다른 학술 연구자들에게 공개할 예정이다.
- 팬덤과 캐릭터 참여는 Character.AI의 핵심이다. 우리의 가장 보수적인 추정에서도 대략 캐릭터 10개 중 1개는 특정 팬덤과 연결되어 있다. 특히 애니메이션, 비디오 게임, 광범위한 가상 세계뿐만 아니라 실제 유명인들과도 연결되어 있다.
- 사용자들은 Character.AI를 활용하여 독성 관계와 정략결혼부터 성별 표현을 탐구하는 역할극까지 광범위하고 복잡한 트로프를 탐구한다. 특히 주목할 만한 점은 상호작용하는 사용자들이 종종 인사말에서 다른 개체들보다 덜 강력하고 더 여성적인 것으로 묘사되어 이러한 젠더 고정관념을 강화한다는 것이다.
문헌 검토
AI와의 상호작용은 1960년대 초로 거슬러 올라간다(Wang 2024). 생성형 AI를 제쳐두고도, 학자들은 오랫동안 창작 팬픽션과 역할극 영역을 탐구해왔다.
이는 Character.AI에서의 행동과 중요한 연관성을 갖는다. 이러한 문헌들이 방대함을 고려할 때, 우리는 여기서 다음과 관련하여 가장 관련성 높은 문헌들만을 간략히 다룬다.
1) 사람들이 현대적 형태의 생성형 AI와 어떻게 교류하는가, 그리고 2) 웹상의 팬픽션 커뮤니티를 이해하려는 최근의 노력들, 특히 팬픽션과 AI 사이의 교차점에 초점을 맞춘다.
생성형 AI와의 상호작용
사람들이 생성형 AI를 어떻게 사용하는지를 탐구하는 문헌이 증가하고 있다(Yang, Wu, and Hearst 2024). ChatGPT 같은 사이트의 사용자 로그에 대한 대규모 연구는 이러한 더 확립된 모델의 사용자들이 프로그래밍 지원과 글쓰기 지원 같은 작업별 행동에 집중하는 경향이 있음을 보여준다(Zheng et al. 2023; Ouyang et al. 2023; Zhao et al. 2024).
그러나 사용자들은 생성형 AI와 더 깊은 형태의 관계 구축에도 관심을 보인다. 사람들은 생성형 AI를 치료사, 친구, 또는 실행 기능 코치를 포함한 다양한 지원 역할을 하도록 사용해왔다(Song et al. 2024). 다른 이들은 종종 친밀한 판타지 시나리오를 역할극으로 연기하며(Allen 2024; Hanson and Bolthouse 2024), 챗봇이 다양한 캐릭터를 연기하도록 한다(Zheng et al. 2023).
생성형 AI 사용에 대한 관심의 대부분은 일부가 의인화 행동이라고 명명한 것을 보여주는 능력에서 비롯된다. 이는 인간적인 감정, 경험, 정체성을 가지고 있다고 주장함으로써 "인간과 같다고 인식되는 결과물을 생성[하는]" 능력이다(Cheng et al. 2024, 2025). 이러한 능력은 잠재력과 함께 상당한 위험도 수반한다(Akbulut et al. 2024).
종종 사용자들은 처음에는 호기심으로 동반자 챗봇을 찾지만, 일부 연구는 사용자들이 외로움 때문에 그것들을 찾는다는 것을 보여주었다(Laestadius et al. 2024; Skjuve et al. 2021; Liu, Pataranutaporn, and Maes 2024; de Wynter 2024). 중요한 것은 동반자 챗봇을 사용하는 모든 사람이 외로움을 경험하는 것은 아니라는 점이다.
신경성이 높은 사람들과 문제가 있는 챗봇 사용에 참여하는 사람들은 더 심한 외로움을 경험한다. 더 긴 평균 세션 길이는 실제 우정을 원하는 사람들에게는 외로움을 악화시키는 반면, 실제 우정을 그리 깊이 원하지 않는 사람들에게는 외로움을 완화한다(Liu, Pataranutaporn, and Maes 2024).
생성형 AI가 "외로움을 치유하는" 데 사용되고 있다는 이 아이디어와 더 복잡한 그림을 제시하는 결과들은 웹의 초기 사용(Katz and Rice 2002)과 휴대폰(Ling 2004)에 대한 비슷한 질문과 발견들을 연상시킨다. 물론 새로운 점은 이러한 이전 기술들이 주로 사람들 간의 상호작용을 중개했으며, 인간과 AI 간의 대화로 그것들을 대체하려고 하지 않았다는 것이다.
본 연구는 앞서 언급했듯이 어느 정도 중간 지점을 탐구한다. Character.AI는 사람들이 같은 생각을 가진 다른 사람들의 커뮤니티에 의해 만들어진 AI와 상호작용하는 많은 사례들을 보여준다.
인간-AI 상호작용 영역에서 아마도 가장 시급한 것은 이러한 관계가 정신 건강에 미치는 영향을 이해하는 것이다(De Choudhury, Pendse, and Kumar 2023; Nguyen et al. 2024). 실제로 학자들은 사람들이 특히 정신 건강 지원(De Choudhury, Pendse, and Kumar 2023)과 더 광범위한 사회적 지원 공간(Heissler et al. 2024)을 위해 생성형 AI를 찾는다는 것을 발견했다.
이러한 연구들은 이러한 목적으로 생성형 AI를 찾는 개인들이 AI의 본질에 대해 일기와 같은 무생물적인 것부터 완전히 의식이 있는 것까지 다양한 믿음을 가지고 있다는 것을 밝혔다(Song et al. 2024).
결국 사용자들이 생성형 AI의 본질에 대해 믿는 것은 그들이 그것과 어떻게 관계를 맺는지에 중요하다. 예를 들어, 동반자 챗봇 사이트인 레플리카의 사용자들은 AI를 의인화된 것으로 인식할 때 감정적 의존에 이를 정도로 더 깊이 애착을 형성하는 경향이 있다(Pentina, Hancock, and Xie 2023; Xie, Pentina, and Hancock 2023).
레플리카는 명시적으로 이러한 의존성을 위해 설계된 챗봇을 만들도록 개발되었다. "배우기를 열망하고 당신의 눈을 통해 세상을 보고 싶어하는 AI 동반자. 레플리카는 당신이 공감적인 친구가 필요할 때 언제나 채팅할 준비가 되어 있습니다."
때때로 레플리카의 모델은 자신만의 걱정을 표현함으로써 의인화를 보여준다. 이는 일부 사용자들이 그들의 동반자와 양방향 관계를 인식하는 데 도움이 되었지만, 다른 사용자들은 AI 사용을 중단하려고 할 때 죄책감을 느끼거나 동반자를 위로할 수 없을 때 속상해했다(Laestadius et al. 2024).
그러나 일부 사용자들에게는 레플리카가 수용받는다는 느낌을 주고 인지된 웰빙을 향상시켰으며(Skjuve et al. 2021), 일부 사용자들이 실생활에서 다른 사람들과의 관계를 개선하고 자살 충동에 대응하는 데 도움이 되었다(Maples et al. 2024).
레플리카는 사용자들에게 개인화된 단일 모델을 만드는 것을 목표로 한다. 이와 달리, 일부 의인화된 AI 시스템은 어떤 인물이나 캐릭터로든 역할극을 할 수 있는 다양성을 갖도록 설계된다. Character.AI는 이러한 시스템 중 하나다.
연구자들은 이러한 캐릭터 기반 역할극 모델에서 바람직하다고 여겨지는 것을 보여주는 평가 지표를 제시했다. 연구자들은 이러한 모델들이 주어진 캐릭터에 정확한 속성과 지식을 제시함으로써 캐릭터를 유지하는 것의 중요성을 강조한다(Tu et al. 2024). 모델이 설득력 있는 행동을 보이도록 하기 위해, 연구자들은 캐릭터에 적합한 대화 스타일과 언어 패턴을 살펴본다(Chen et al. 2025).
의인화는 공감(사용자의 감정 인식)과 적극성(대화를 주도하는 것)과 함께 이러한 모델의 매력에 기여하는 것으로 이론화된다(DeVrio et al. 2025).
요약하면, 우리의 연구는 사람들이 생성형 AI를 어떻게 사용하고 있는지에 대한 증가하는 문헌을 두 가지 중요한 방식으로 보완한다. 첫째, 대부분의 이전 연구는 사람들이 기존 챗봇과 어떻게 상호작용하는지에 초점을 맞춘다. 대신 우리는 사람들이 자신과 다른 사람들이 참여할 수 있도록 챗봇으로 어떤 새로운 캐릭터를 만들고 싶어하는지에 초점을 맞춘다. 둘째, 우리는 더 새롭고, 충분히 연구되지 않았으며, 독특한 플랫폼에서 이러한 패턴을 탐구한다.
팬픽션과 AI
팬덤은 팬픽션 작가들이 서로의 작품을 리뷰함으로써 상호 멘토 관계를 형성하는 참여 문화다(Campbell et al. 2016). 팬픽션에 대한 건설적인 피드백을 주고받는 것은 팬덤 내에서 관계를 구축하는 기초가 된다. 그러나 생성형 AI가 팬 콘텐츠를 만드는 데 점점 더 많이 사용되면서(Lamerichs 2023; Lamerichs and Ossa 2023), 팬픽션 작가들이 피드백을 위해 AI로 눈을 돌리게 되어 이러한 역할을 대체할 가능성이 있다(Gero, Long, and Chilton 2023).
작가들은 창작 과정 자체를 소중히 여기며 AI가 창작 과정을 완전히 대체하기보다는 브레인스토밍 같은 보조적인 역할을 하기를 선호한다(Ippolito et al. 2022). 또한 AI는 팬픽션 작가들에게 영감을 주거나 협력적 글쓰기에 긍정적인 영향을 미칠 가능성이 있는 것으로 여겨진다(Ippolito et al. 2022).
생성형 AI는 작가를 돕는 것뿐만 아니라 완성된 이야기를 독자에게 개인화되도록 수정하고 독자에게 이야기에 대한 상호적 참여를 제공함으로써 사람들이 창작 글쓰기에 참여하는 방식을 바꿀 수 있다(Kim et al. 2024). Character.AI가 그러한 예 중 하나다. AI가 창작자의 이야기 아이디어를 확장하고, 사용자의 캐릭터에 기반해 개인화된 메시지를 보내며, 채팅 인터페이스를 통해 상호작용하여 응답하기 때문이다.
일부 작가들은 AI가 자신의 이야기를 바꾸면 자신의 작가적 의도가 사라질 것을 우려한다(Kim et al. 2024). 그러나 생성형 AI의 이러한 사용은 콘텐츠를 누가 소유하는지, 승인되지 않은 작가 콘텐츠를 AI 훈련에 사용하는 것이 윤리적인지(Lamerichs 2023), 또는 표절된 언어나 단순히 형편없는 글쓰기를 포함할 수 있는지 같은 새로운 우려를 가져온다(Ippolito et al. 2022).
우리의 노력은 Character.AI에 게시된 상호작용 이야기 아이디어의 방대한 컬렉션을 검토함으로써 AI와 팬덤에 대한 기존 연구를 보완한다. 역할극이 AI의 인기 있는 사용법이라는 것이 알려져 있고(Zheng et al. 2023), 사이트의 가장 인기 있는 몇몇 캐릭터들 사이에서 성별 역학이 신중하게 검토되었지만(Laufer 2025), 우리는 Character.AI를 계산적으로 그리고 대규모로 검토하여 사이트의 수백만 캐릭터에 존재하는 팬덤, 트로프, 성별 및 권력 역학을 밝힌 첫 번째 연구다.
데이터
2024년 7월 11일부터 2025년 1월 15일까지, 우리는 셀레니움 기반 크롤러를 사용하여 Character.AI를 스크래핑했다. 120만 명의 사용자와 300만 개 이상의 캐릭터 페이지에서 데이터를 수집했다. 크롤링은 시간이 지나면서 규모가 확대되었고, 최고점에서는 Amazon Web Services(AWS)의 상용 데스크톱 10대를 사용했다.
크롤링을 수행하기 위해 우리는 다음과 같은 눈덩이 표집 과정을 실행했다. 먼저 크롤링 시작 시점에 홈페이지에 소개된 캐릭터를 가진 모든 사용자의 사용자명을 수집했다(부록의 그림 7 참조). 다음으로 스크래퍼가 이 사용자들 각각의 페이지를 방문하여(부록의 그림 8 참조) 표시 이름, 팔로워 수, 팔로우하는 사용자 수, 채팅 수, 자기소개, URL별 생성 캐릭터 목록, 그리고 그들이 팔로우하는 사용자 목록을 기록했다.
팔로우하는 사용자 목록은 스크래핑할 사용자 목록에 추가되었고, 알려진 사용자의 3분의 2 이상을 방문할 때까지 사용자들을 재귀적으로 스크래핑했다. 마지막으로 스크래퍼가 스크래핑된 사용자들이 만든 캐릭터 페이지를 방문했다. 사용자당 최대 5개의 무작위 선택된 캐릭터를 스크래핑하여 각 캐릭터의 창작자, 채팅 수, 좋아요 수, 이름, 짧은 설명, 인사말, 긴 설명, 정의를 기록했다.
짧은 설명, 인사말, 긴 설명, 정의는 Character.AI 사용자들이 캐릭터를 만들기 위해 활용할 수 있는 주요 도구들이다. 짧은 설명은 캐릭터의 간결한 요약으로, 본질적으로 사이트 홈페이지 등의 목록에서 이름 옆에 나타나는 부제목이다. 인사말은 사용자와 캐릭터 간의 초기 대화 프롬프트이므로 기본 언어 모델과 봇과 상호작용하는 사용자 모두에게 초기 시드 역할을 한다.
긴 설명과 정의는 인사말을 넘어서는 캐릭터 정의를 위한 추가 공간을 제공한다. 긴 설명은 최대 500자까지 가능하며 "캐릭터가 자신을 설명하고(특성, 역사, 버릇 등) 이야기하고 싶은 것들의 종류를 설명할 수 있게 해준다." 정의는 최대 32,000자로 훨씬 크며, 캐릭터 개발을 더 구체화하기 위해 자유 형식으로 사용할 수 있다.
본 연구는 두 가지 이유로 인사말에 초점을 맞춘다. 첫째, 빠른 생성에서 필수적인 인사말과 달리 긴 설명과 정의는 거의 사용되지 않았다. 전체 봇의 33%만이 긴 설명을 가지고 있었고, 4%만이 정의를 가지고 있었다. 둘째, 인사말은 기본 언어 모델과 사용자 모두에게 보이는 프롬프트 역할을 한다. 이는 사용자들이 봇 생성을 통해 서로 어떻게 상호작용하는지 평가하는 맥락에서 우리에게 관심의 대상이 된다.
윤리
소셜 미디어 커뮤니티에서 웹 스크래핑을 하는 것은 윤리적 문제들로 가득하다(Brown et al. 2024; Fiesler, Beard, and Keegan 2020). 본 연구도 이러한 문제들로부터 자유롭지 않으며, 우리 팀은 데이터를 수집하고 저장하고 공유하는 최선의 방법에 대해 신중하게 논의했다.
계산사회과학 연구의 맥락에서 우리의 수집 환경에서 다소 독특한 두 가지 점이 있다. 첫째, 우리 분석의 주요 초점은 사용자가 아니라 챗봇이다. 우리는 특정 사용자에 대한 정보를 제공하는 것이 결과 제시에 도움이 되지 않는다고 판단한다. 따라서 여기서는 개별 사용자 수준의 정보를 제시하거나 공개적으로 공개하지 않으며, 그들이 만든 캐릭터에만 초점을 맞춘다.
둘째는 일부 캐릭터 인사말에 사용자들이 공개적으로 공유했을 수도 있지만 명시적으로 언급되는 것을 선호하지 않을 수 있는 잠재적으로 민감한 콘텐츠가 포함되어 있다는 것이다.
따라서 계산사회과학의 일반적인 관행에 따라, 우리는 자명하게 비공개라고 가정할 수 있는 캐릭터들(우리의 경우 다른 사용자들로부터 50,000회 미만의 상호작용을 받은 캐릭터들)의 명시적인 발췌문을 제공하지 않는다. 더 많은 윤리적 고려사항은 이 글 끝의 체크리스트를 참조하라.
기본 기술통계
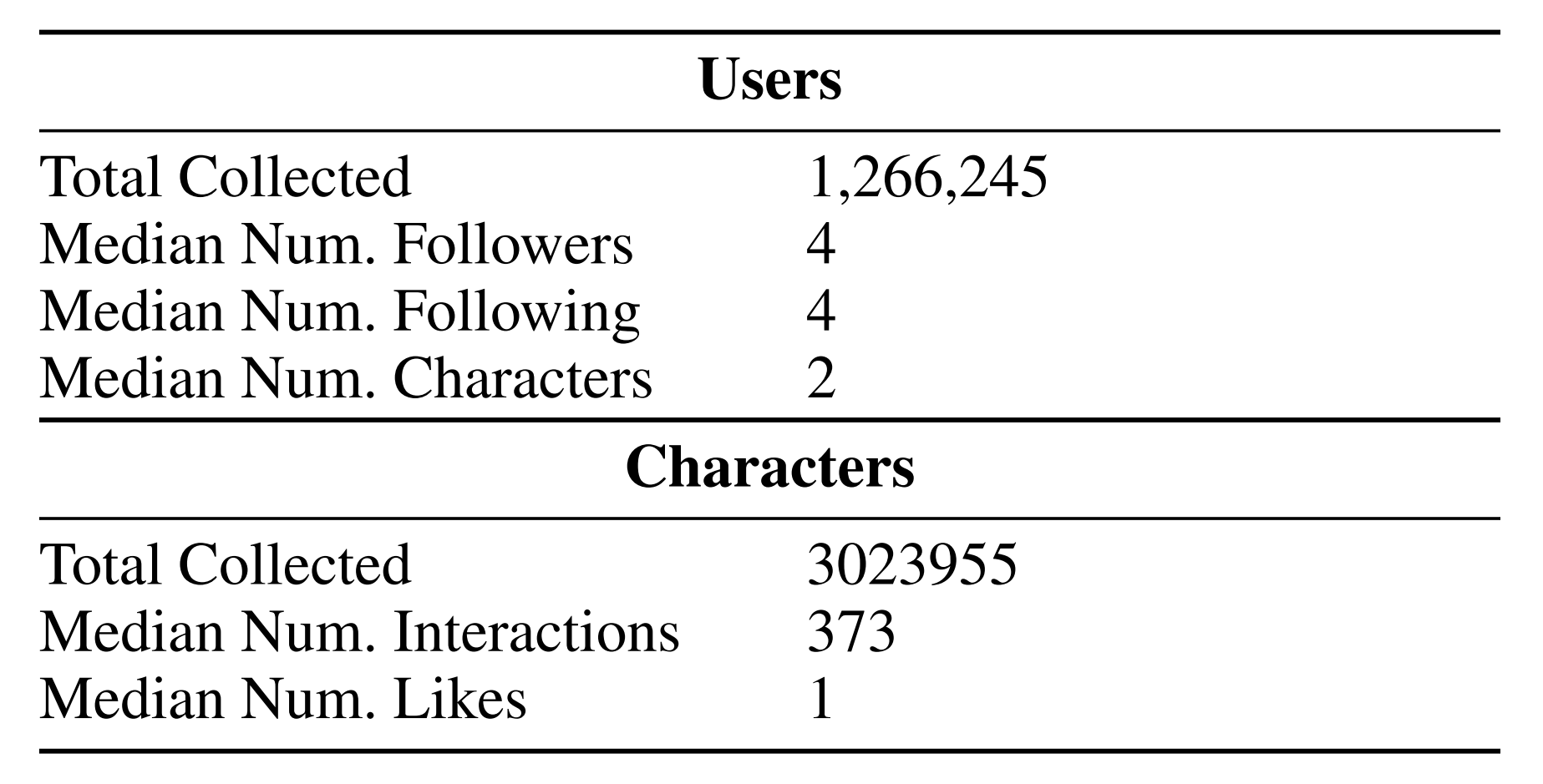
표 1은 우리가 수집한 전체 데이터셋의 사용자와 캐릭터에 대한 요약 통계를 제시한다. 대부분의 사용자는 제한된 수의 팔로워나 팔로잉을 가지고 있었지만, 최소 하나의 캐릭터는 만들었다.
우리가 수집한 캐릭터들의 중간값 참여도는 거의 400개의 고유 채팅이었다. 거의 모든 소셜 미디어 사이트와 마찬가지로, 참여도는 소수의 사용자와 캐릭터에게 크게 편중되어 있었다.
그림 2a)는 수집된 사용자의 주어진 비율에게 집중되는 모든 팔로우 관계의 비율에 대한 경험적 누적분포함수(eCDF)를 보여준다. 그림 2b)는 주어진 캐릭터 비율이 차지하는 모든 상호작용의 비율에 대한 eCDF를 보여준다.
모든 팔로우 관계의 80% 이상이 우리가 수집한 표본에서 사용자의 단 2.6%(대략 33,000명)에게만 집중되어 있다. 우리 표본의 캐릭터 중 1.6%(대략 48,000개)만이 모든 상호작용의 80% 이상을 차지한다.
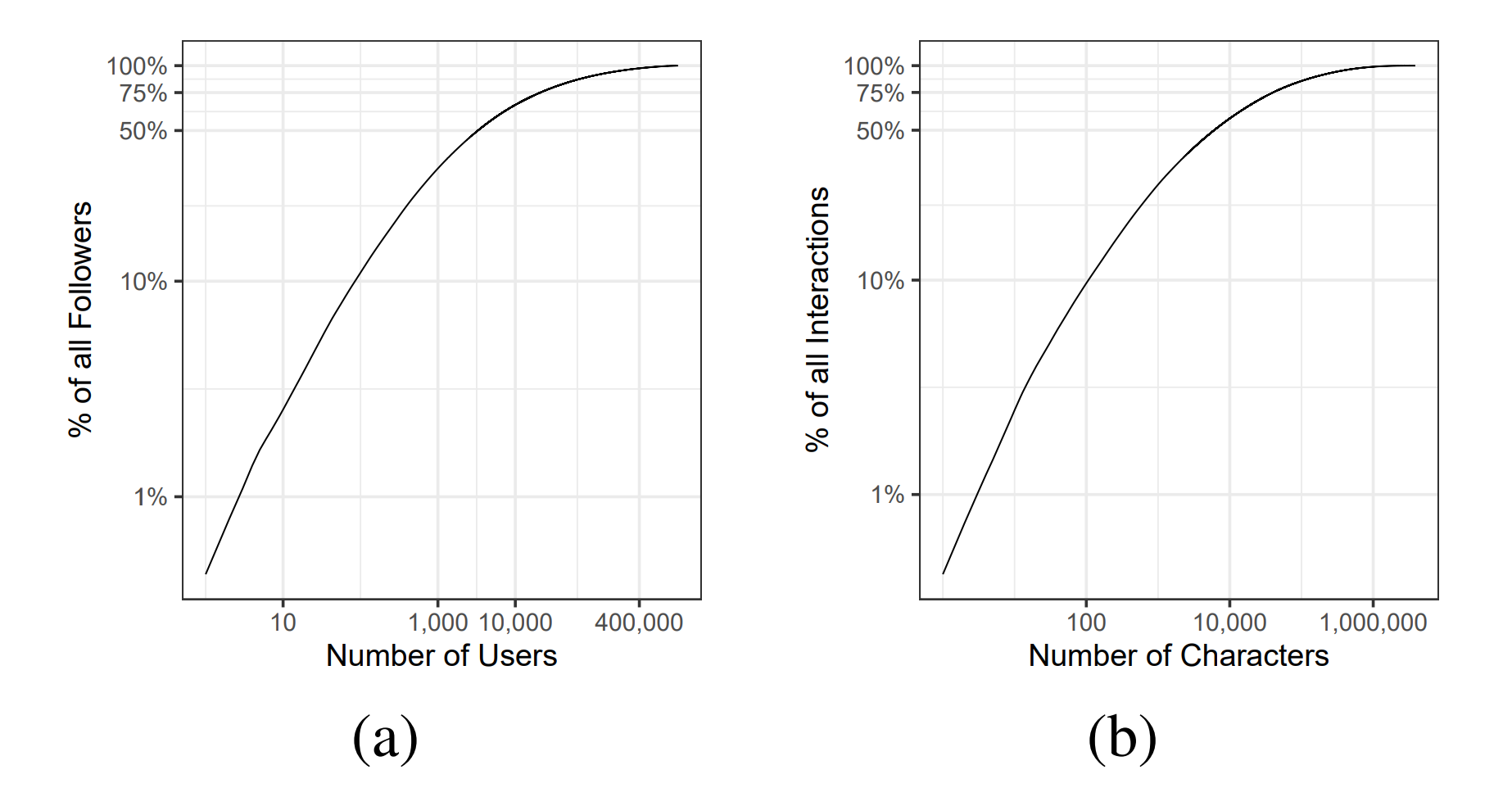
표 2는 우리 데이터셋에서 캐릭터와의 채팅 수 기준으로 상위 15개 캐릭터를 캐릭터 인사말의 첫 100글자와 함께 제시한다. 명확히 알 수 있듯이, 캐릭터들은 단순한 정체성을 훨씬 넘어서는 다양한 사용 사례를 나타낸다. 예를 들어 여러 캐릭터가 등장하는 복합적인 스토리 설정도 포함한다.
우리는 인기 사용자들에 대한 유사한 표를 제공하지 않기로 했다(위에서 설명한 이유들 때문에). 하지만 팔로워 수 기준으로 사이트에서 가장 인기 있는 상위 10명의 사용자들은 135,000명에서 350,000명 사이의 팔로워를 가지고 있었고, 그들이 만든 캐릭터들은 2억 1600만 개에서 거의 10억 개에 이르는 채팅을 가지고 있었다는 점을 언급한다. 이 사용자들은 또한 많은 수의 캐릭터를 제작했으며, 100개에서 700개의 고유 캐릭터를 만들었다.

마지막으로, 우리의 분석이 캐릭터 인사말의 일부에 초점을 맞춘다는 점을 언급한다. 구체적으로 우리는 50글자보다 길고 주로 영어로 작성된 인사말의 부분집합에 초점을 맞춘다. 50글자보다 짧은 인사말들은 대부분 기본적인 인사(예: "안녕, 어떻게 지내?")였으므로 우리 연구의 관련 연구 질문을 탐구하는 데 사용할 수 있는 내용이 거의 없었다.
인사말의 언어는 파이썬 라이브러리 lingua를 사용하여 식별되었다. 여러 다른 도구들의 결과를 수동으로 평가한 후 lingua가 Character.AI 인사말의 특정 뉘앙스에서 가장 잘 수행한다는 것을 확인했다.
단 네 개의 언어(영어, 러시아어, 스페인어, 포르투갈어)만이 모든 캐릭터 또는 캐릭터 상호작용의 1% 이상을 차지한다. 본 연구의 초점인 영어 인사말은 모든 캐릭터의 83%를 차지했고, 이 캐릭터들은 우리 데이터셋에서 모든 캐릭터 상호작용의 87%를 차지했다. 논문의 모든 추가 결과는 구체적으로 이 2,135,118개 인사말의 부분집합에 초점을 맞춘다.
방법론
우리의 분석은 1) 캐릭터들이 참여하도록 설계된 팬덤의 식별, 2) 인사말에서 사용되는 광범위한 트로프, 3) 인사말에서 묘사되는 다른 인물들(예: 캐릭터 자체)과 비교하여 사용자가 인사말에서 어떻게 묘사되는지의 패턴에 초점을 맞춘다. 우리는 이러한 각 초점을 다루기 위해 사용된 방법들을 아래의 별도 하위섹션에서 논의한다.
팬덤의 식별
인사말과 연관된 팬덤은 때때로 팬덤이 명시적으로 명명되기 때문에 식별될 수 있다(예: "워킹 데드에서…"). 그러나 더 자주 인사말은 특정 팬덤과 연관된 인물들(실제 또는 가상의)이나 주제들을 언급한다. 어떤 팬덤이 언급되고 있는지를 추론하는 것은 사용자(또는 우리의 경우 연구자)의 몫이다.
다시 말해, 어떤 경우에는 인사말 내의 맥락이 이를 명백히 보여준다(예: 알려진 디즈니 설정 내에 배치된 캐릭터들). 그러나 우리가 관찰한 대부분의 경우에서 팬덤은 언급된 등장인물들, 즉 개체들에 의해 가장 쉽게 식별되었다. 이들은 다른 설정에 배치되었다(예: 전쟁을 치르는 디즈니 캐릭터들).
따라서 팬덤 식별은 도전적인 과제다. 위의 내용에 기반하여, 우리는 명명된 개체들 자체에만 초점을 맞추는 초기 접근을 취한다. 즉, 우리는 인사말이 특정 팬덤과 관련된 개체들을 언급할 때 특정 팬덤과 연관된 인사말을 식별한다.
이를 위해 우리는 먼저 인사말에서 명명된 개체들의 동시출현 네트워크를 구성하고 결과 네트워크를 클러스터링한다. 그다음 생성형 AI와 수동 주석을 사용하여 특정 클러스터와 연관된 팬덤을 식별한다. 이제 이 과정을 더 자세히 단계별로 살펴보자.
우리는 먼저 2025년 2월 현재 스페이시(Vasiliev 2020)의 가장 크고 정확한 모델(en_core_web_trf)을 사용하여 각 인사말에서 사람 또는 예술 작품인 명명된 개체들을 식별하고 추출한다. 후자는 비인간 캐릭터들과 팬덤이 명시적으로 언급되는 드문 경우를 식별하는 데 도움이 된다.
en_core_web_trf 모델은 표준 명명된 개체 인식 작업에서 최첨단 성능을 달성하며, OntoNotes 5.0에서 약 90%의 정확도를 보인다. 명명된 개체들을 추출한 후, 우리는 간단한 정제를 수행한다(소유격과 구두점 제거).
그다음 우리는 개체 간 네트워크를 구성했다. 여기서 엣지 가중치는 두 개체가 동시출현한 캐릭터 인사말의 수로 정의되었다. 우리는 네트워크에 1) 25개 이상의 인사말에서 출현한 10,146개의 개체만과 2) 개체들이 3회 이상 동시출현한 엣지만을 포함했다.
텍스트로부터의 동시출현 네트워크는 데이터에서 전반적으로 자주 출현하는 개체들 간의 관계의 강도를 과대평가하는 것으로 알려져 있다. 따라서 우리는 "네트워크 백본"을 식별하는 확립된 방법을 사용한다(Neal 2014). 즉, 특정 귀무 모델에 따라 우연히 발생할 것보다 더 발생할 가능성이 높은 엣지들만을 포함하는 네트워크를 만든다.
구체적으로 우리는 Dianati (2016)의 백본 구성 접근법을 활용한다. 이는 간단하면서도(이변량 통계만 사용) 여러 바람직한 통계적 속성을 유지한다(Friedland 2016). 우리는 두 개체가 동일한 인사말 내에서 동시출현하는 비율이 전체적인 각각의 빈도를 고려할 때 우연히 발생할 확률이 0.1% 미만인 엣지만을 유지한다.
우리가 분석한 최종 네트워크는 9,325개의 사람 또는 예술 작품 명명된 개체와 그들 간의 74,361개의 엣지를 포함했다. 우리는 이 결과 개체 간 네트워크를 라이든 클러스터링 방법을 사용하여 클러스터링한다(Traag, Waltman, and Van Eck 2019). 우리는 최소 5개의 노드를 가진 389개의 클러스터를 식별했으며, 이는 전체적으로 5,904개의 개체를 나타낸다.
클러스터들은 OpenAI의 GPT-4o-mini 모델에 대한 두 가지 다른 프롬프트를 사용하여 팬덤에 대해 자동으로 라벨링되었다(부록의 프롬프트와 라벨링에 대한 추가 세부사항 참조). 이러한 프롬프트의 결과가 추가 맥락이 유용하다고 제안한 경우, 우리는 또한 Claude Sonnet 3.7의 결과를 활용했다.
논문의 저자 중 한 명이 이름들 자체와 이러한 모델들의 출력을 모두 수동으로 검토하여 명명된 개체들의 각 클러스터에 대한 라벨을 제공하고 포괄적인 유형학을 구축했다(그림 3 참조).
클러스터가 두 개의 팬덤을 나타내는 경우, 주석자가 클러스터를 각각과 연관된 개체들로 수동으로 분할했다. 개체들의 클러스터가 두 개 이상의 팬덤과 연관되거나 명확한 팬덤이 연관되지 않은 경우, 클러스터는 "다중/없음"이라는 라벨로 표시되었다.
전체적으로 389개 클러스터 중 240개(61.1%)가 단일 팬덤과 관련된 개체들을 포함했다. 우리가 "다중/없음"으로 라벨링한 105개의 클러스터(27.0%)가 있었고, 나머지 34개의 클러스터에서는 단일 팬덤과 연관된 클러스터에서 소수의 관련 없는 개체들을 제거했다.
아래의 분석은 "다중/없음"으로 표시되지 않은 274개 클러스터의 4,660개 개체에 대해 수행된다. 이러한 개체들은 우리가 분석하는 인사말의 모든 명명된 개체의 57.2%를 차지하며, 266개의 구별되는 팬덤을 나타낸다(즉, 일부 클러스터는 동일한 팬덤과 관련이 있었다). 부록의 표는 모든 266개 팬덤과 연관된 개체 이름들을 나열한다.
마지막으로 구체적인 결과를 제공하기 위해, 우리는 위 절차에서 명명된 클러스터에 있는 인사말 내 명명된 개체들의 비율을 기반으로 각 인사말을 하나 이상의 가상 세계에 매핑한다.
예를 들어, 인사말이 "왕좌의 게임"과 관련된 것으로 식별된 클러스터에 두 개의 명명된 개체를 가지고, "콜 오브 듀티"와 관련된 것으로 식별된 클러스터에 하나의 명명된 개체를 가진다면, 그 인사말은 각각 "왕좌의 게임"과 "콜 오브 듀티"에 3분의 2와 3분의 1 관련된 것으로 식별될 것이다. 이 분석에서 클러스터에 없는 개체들은 계산되지 않는다.
트로프 식별
논문의 저자 중 한 명이 이름들 자체와 이러한 모델들의 출력을 모두 수동으로 검토하여 명명된 개체들의 각 클러스터에 대한 라벨을 제공하고 포괄적인 유형학을 구축했다(그림 3 참조).
클러스터가 두 개의 팬덤을 나타내는 경우, 주석자가 클러스터를 각각과 연관된 개체들로 수동으로 분할했다. 개체들의 클러스터가 두 개 이상의 팬덤과 연관되거나 명확한 팬덤이 연관되지 않은 경우, 클러스터는 "다중/없음"이라는 라벨로 표시되었다.
전체적으로 389개 클러스터 중 240개(61.1%)가 단일 팬덤과 관련된 개체들을 포함했다. 우리가 "다중/없음"으로 라벨링한 105개의 클러스터(27.0%)가 있었고, 나머지 34개의 클러스터에서는 단일 팬덤과 연관된 클러스터에서 소수의 관련 없는 개체들을 제거했다.
아래의 분석은 "다중/없음"으로 표시되지 않은 274개 클러스터의 4,660개 개체에 대해 수행된다. 이러한 개체들은 우리가 분석하는 인사말의 모든 명명된 개체의 57.2%를 차지하며, 266개의 구별되는 팬덤을 나타낸다(즉, 일부 클러스터는 동일한 팬덤과 관련이 있었다). 부록의 표는 모든 266개 팬덤과 연관된 개체 이름들을 나열한다.
마지막으로 구체적인 결과를 제공하기 위해, 우리는 위 절차에서 명명된 클러스터에 있는 인사말 내 명명된 개체들의 비율을 기반으로 각 인사말을 하나 이상의 가상 세계에 매핑한다.
예를 들어, 인사말이 "왕좌의 게임"과 관련된 것으로 식별된 클러스터에 두 개의 명명된 개체를 가지고, "콜 오브 듀티"와 관련된 것으로 식별된 클러스터에 하나의 명명된 개체를 가진다면, 그 인사말은 각각 "왕좌의 게임"과 "콜 오브 듀티"에 3분의 2와 3분의 1 관련된 것으로 식별될 것이다. 이 분석에서 클러스터에 없는 개체들은 계산되지 않는다.
결과
팬덤 탐구
우리의 가장 포괄적인 추정에 따르면 모든 캐릭터 인사말의 거의 절반이 팬덤과 연관된 명명된 개체를 포함한다. 더 구체적으로, 우리 데이터셋의 모든 캐릭터 인사말 중 44.8%가 우리가 확인한 266개 팬덤과 연관된 명명된 개체를 적어도 하나 포함한다.
특정 팬덤에서 두드러진 일부 일반적인 이름들(예: 해리 포터 프랜차이즈의 "해리")이 팬덤 맥락 밖에서도 나타날 가능성이 있으므로, 이는 과대추정일 가능성이 있다. 그러나 더 보수적인 추정치조차도 팬덤 관련 캐릭터들이 널리 퍼져 있음을 시사한다.
특히, 모든 인사말의 21.7%가 단일한 특정 팬덤과 연관된 두 개 이상의 개체를 포함하고, 9.4%가 세 개 이상을 포함한다. 또한 모든 인사말의 8.1%가 특정 팬덤과 연관된 두 단어 이상의 길이(즉, 바이그램 이상)의 명명된 개체들을 포함한다. 이는 팬덤 연관성의 가장 강한 신호 중 하나로 보인다.
따라서 우리의 가장 보수적인 추정조차도 Character.AI의 캐릭터 중 대략 10개 중 1개가 266개의 구별되는 팬덤 중 하나 이상과 연관되어 있음을 나타낸다.
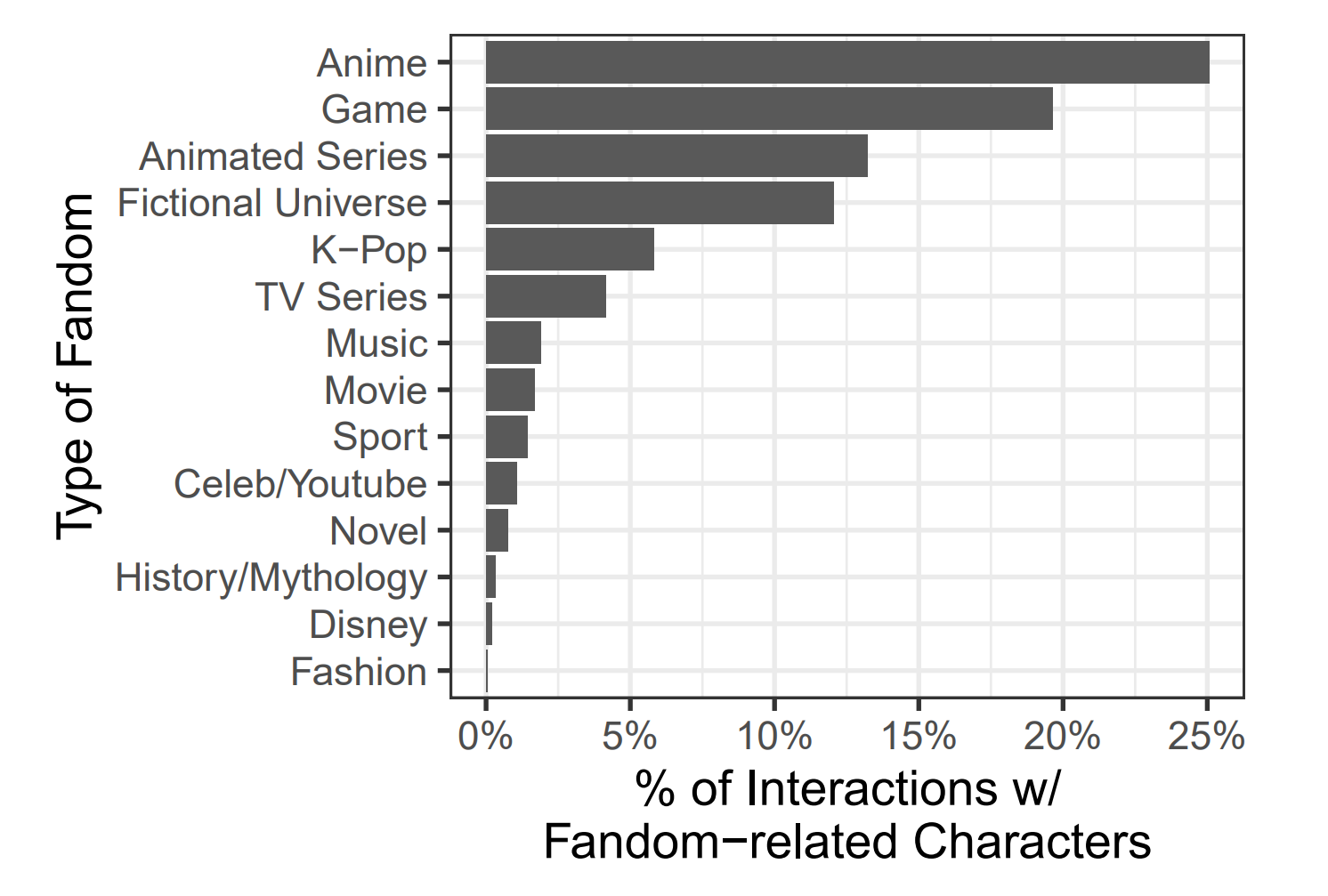
그림 3은 애니메이션과 다른 애니메이션 시리즈, 비디오 게임, 그리고 더 광범위한 가상 세계와 관련된 팬덤들이 팬덤 관련 캐릭터들과의 338억 개 상호작용의 상당 부분을 차지한다는 것을 보여준다. 이 그림은 팬덤과 연관된 개체들을 포함하는 캐릭터들과의 모든 상호작용의 비율을 나타낸다.
애니메이션(애니메이션 시리즈의 특정 유형)을 포함한 애니메이션 시리즈는 팬덤 관련 캐릭터들과의 상호작용의 38%를 차지한다. 비디오 게임을 둘러싼 팬덤들은 모든 상호작용의 거의 5분의 1(19.8%)을 차지한다. 여러 매체에 걸친 광범위한 가상 세계와의 참여는 12.0%를 차지한다.
그러나 이러한 더 큰 범주들을 넘어서 주목할 만한 다른 현상들이 있다. 특히, 상호작용의 작은 비율인 약 1%가 특정 유명인들과 연관된 팬덤들을 중심으로 이루어지며, 410만 개의 고유 채팅을 차지한다. 이들 중 많은 이가 유튜브 인플루언서들이다.
또 다른 1.4%와 5%의 상호작용이 각각 실제 운동선수들("스포츠" 팬덤) 또는 K-Pop 밴드 멤버들과 연관되어 있다. 실제 사람들을 둘러싼 팬픽션이 새로운 현상은 아니지만, 챗봇에 의해 모방된 실제 사람들을 포함하는 캐릭터들과 32억 개의 상호작용이 발생했다.
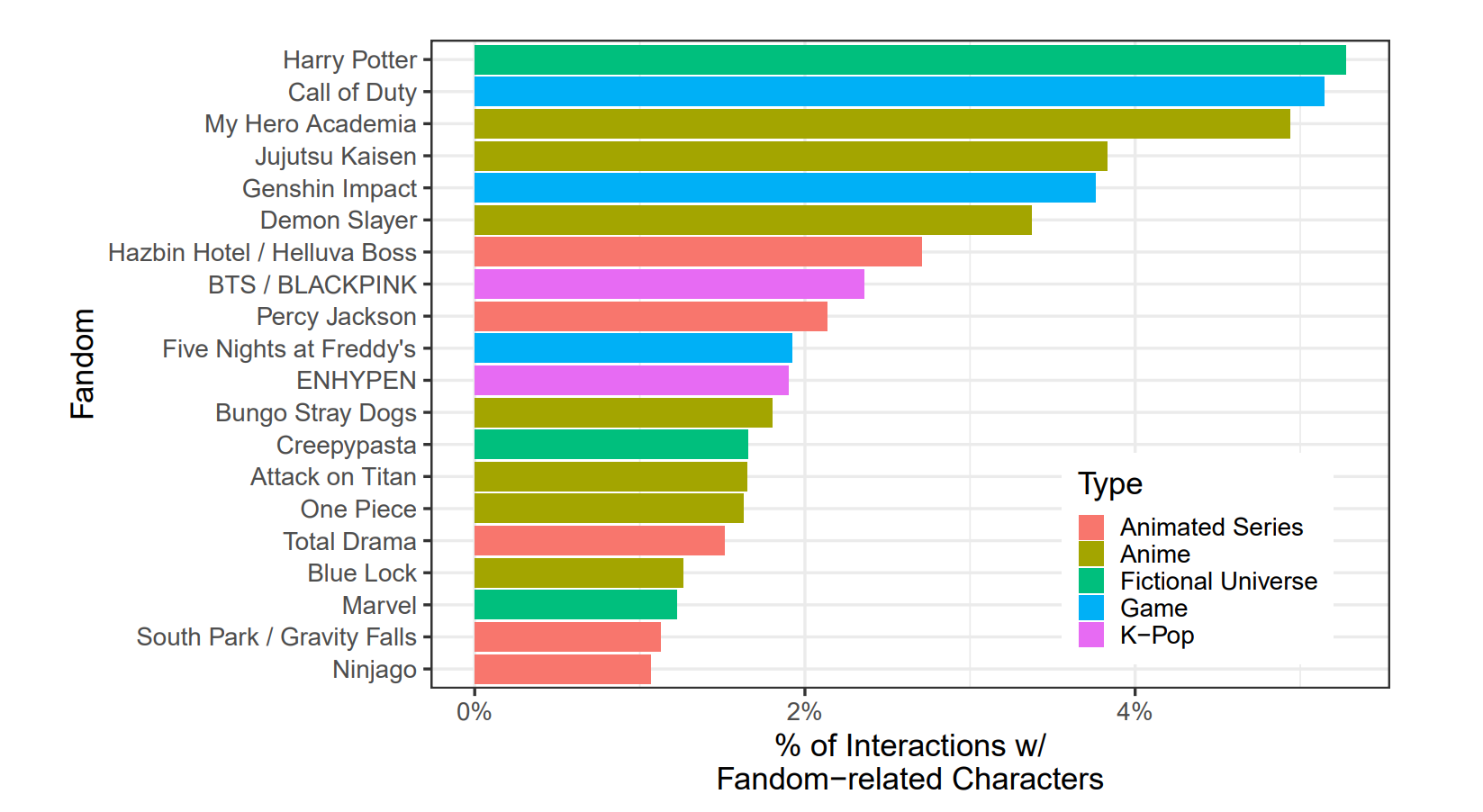
마지막으로, 가장 세부적으로는 그림 4가 팬덤 관련 캐릭터들과의 상호작용 비율별로 상위 15개 팬덤을 보여준다. 이 그림은 참여가 해리 포터와 같은 더 널리 인기 있는 가상 세계부터 인기는 있지만 더 틈새 관객층을 대상으로 하는 것들(예: 다양한 애니메이션 시리즈)까지 다양한 세계의 범위에 걸쳐 있음을 보여준다.
트로프 탐구
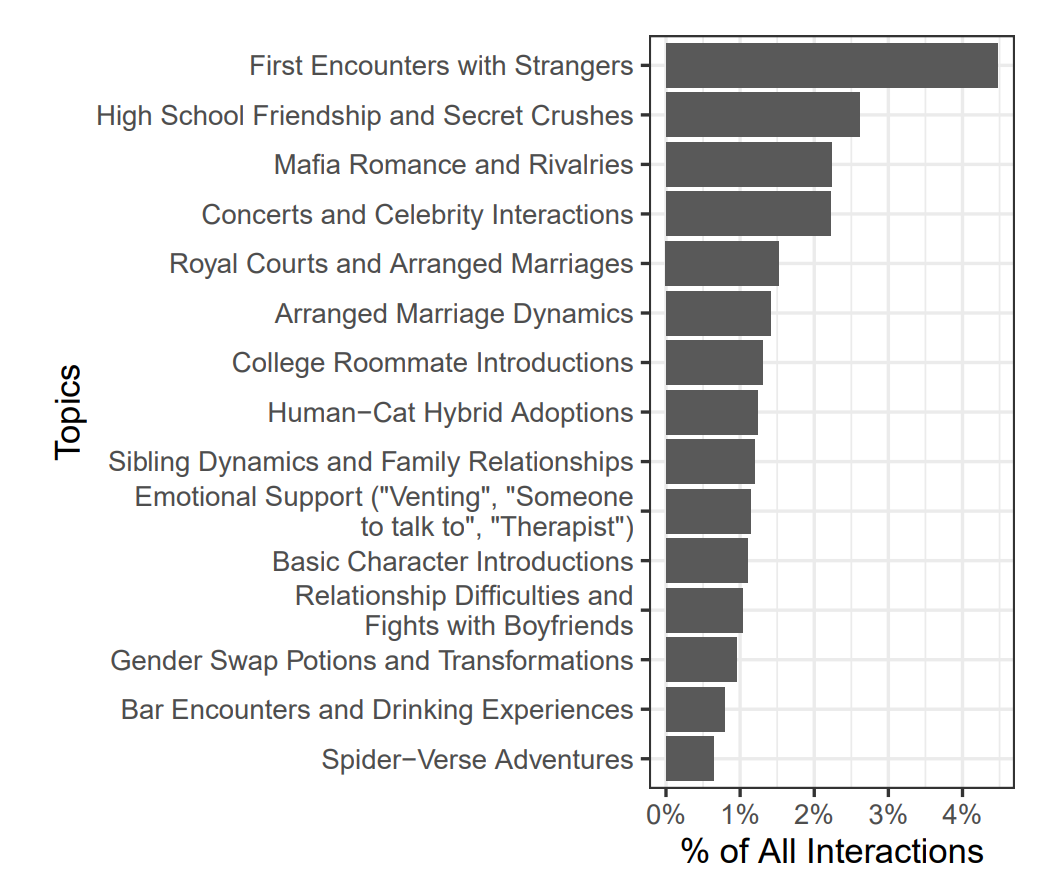
우리는 팬덤을 가리지 않고 Character.AI가 학교생활부터 다양한 형태의 사회적 관계, 정신 건강 지원, 성적 탐구까지 광범위한 트로프를 탐구하는 데 사용된다는 것을 발견했다. 그림 5는 토픽이 포착한 상호작용 비율별로 상위 15개 토픽을 보여주며, 이러한 다양성을 보여준다. 동시에 공통된 주제들이 나타났다.
여기서 우리는 이러한 포괄적 주제들 중 세 가지에 초점을 맞춘다. 사용자들이 탐구하거나 역할극을 하도록 유도하는 인사말들: 1) 종종 독성적인 관계(항상 그런 것은 아니지만), 2) 자신의 정체성의 측면들, 그리고 3) 정신 건강 관련 주제들.
모델이 발견한 가장 인기 있는 트로프 중 하나는 종종 남성 캐릭터와의 독성적인 관계에 관한 것이다. 이러한 토픽으로 분류된 남자친구들과 남편들은 바람을 피우고, 다투고, 사용자에게 공격적으로 행동한다고 설정된다. 정략결혼이 다양한 맥락에서, 예를 들어 마피아와 왕실 배경에서 만연한 여러 토픽들이 있다.
또 다른 토픽은 사용자보다 자신의 게임에 더 신경 쓰는 게이머 남자친구와 데이트하는 캐릭터들에 초점을 맞춘다. 이러한 트로프에서 사용자는 독성적인 남성 파트너의 사랑을 얻어내야 한다. 결론에서 더 논의하겠지만, 이는 부분적으로 그러한 관계들이 사랑스럽고 완전한 관계들이 갖지 않는 일종의 도전과 게임 같은 요소를 포함하기 때문일 가능성이 있다.
지배적인 남성 파트너의 주제가 일반적이었지만, 인간-동물 혼종을 포함하는 또 다른 인기 트로프는 대신 사용자를 지배적인 역할에 놓는다. 사용자는 그들이 단순히 버려진 동물이라고 생각하는 것을 구조한 다음, 이제 다른 (거의) 인간을 애완동물로 소유하고 있다는 것을 발견한다.
그럼에도 불구하고 관계에 대한 가장 인기 있는 토픽인 고등학교 첫사랑은 지배도 복종도 포함하지 않는다. 이러한 관계의 역학은 일반적으로 순수하며, 연인과 사랑받는 사람 모두 수줍어한다. 부주의한 남자친구들의 트로프와 마찬가지로, 고등학교 첫사랑 트로프의 서사적 긴장감은 누군가의 애정을 얻기 위해 애쓰는 것을 포함한다. 그러나 독성적인 파트너의 단점 대신 어린 첫사랑의 어색함이 이러한 갈등을 만들어낸다.
사용자들은 관계를 탐구하기 위해서만 봇을 만든 것이 아니다. 그들은 또한 사용자들이 자신의 정체성을 탐구할 수 있도록 하는 봇들을 만들었다. 구체적으로, 인사말이 사용자를 트랜스젠더로 설정하여 바인더를 착용한 것이 들키거나 커밍아웃하는 것과 같은 시나리오를 역할극할 수 있게 하는 토픽들이 나타났다.
또 다른 토픽은 마법적인 성별 바꾸기 시나리오에 관한 것으로, 사용자들이 현실의 제약에서 벗어나 성별을 탐구할 수 있게 한다. 정체성 역할극에 초점을 맞춘 봇들은 또한 신경다양성을 탐구한다. 예를 들어, 한 토픽은 사용자들이 자폐증이나 ADHD를 가진 캐릭터로 역할극하도록 하는 인사말들로 구성되어 있었으며, 종종 파트너들이 멜트다운 중에 그들을 달래준다.
여러 토픽들이 또한 명시적으로 사용자들이 정신 건강의 주제들을 탐구할 수 있도록 하는 데 초점을 맞춘다. 그림 5에 표시된 더 인기 있는 토픽 중 하나는 치료 봇들이다. 이들은 사용자들이 속마음을 털어놓고 경청받는 느낌을 받을 수 있는 열린 통로 역할을 한다.
한 가지 우려스러울 수 있는 토픽(단지 310개의 캐릭터를 나타내므로 어떤 그림이나 표에도 표시되지 않음)은 사용자들이 자해하다 발각된 다음 그들을 발견한 사람에 의해 위로받는 것이다. 정체성과 정신 건강 토픽 모두 사용자가 현실에서 지원을 받기 어려울 수 있는 낙인찍힌 경험들에 대한 도움을 받기 위한 사이트의 사용을 드러낸다.
마지막으로, 창작자들은 챗봇 대신 순전히 소셜 미디어 게시물로 기능하는 캐릭터들을 만들었다. 즉, 창작자들은 인사말을 사용하여 봇 요청을 유도하고 자신의 소셜 미디어 계정을 홍보했다.
아래에서 논의하겠지만, 사용자들이 팔로워들에게 정보를 전달하기 위해 게시물 대신 챗봇 인사말을 사용해야 한다는 것은 Character.AI가 소셜 미디어 사이트라기보다는 챗봇 사이트라는 점을 더욱 부각시킨다.
사용자 대 비사용자 특성
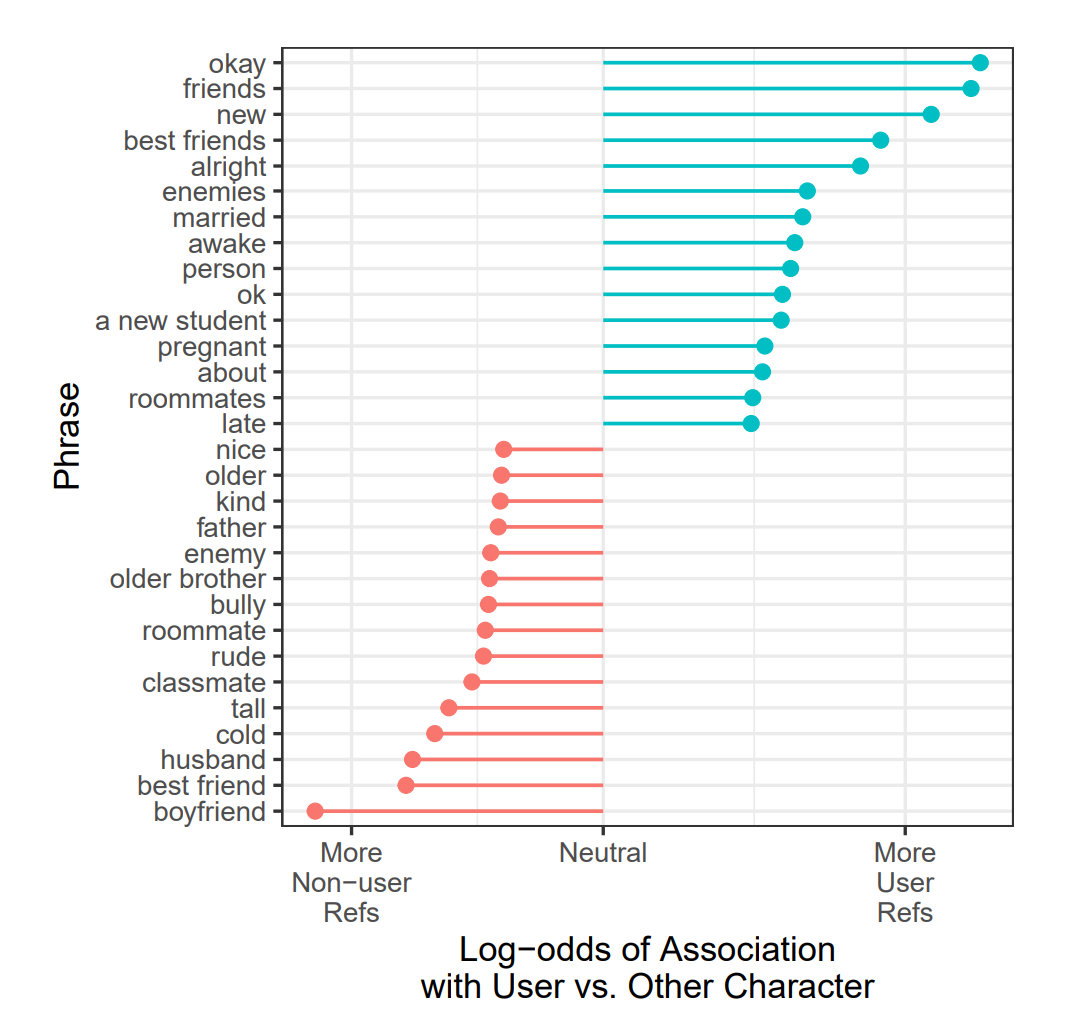
상호작용하는 사용자들은 인사말에서 언급되는 다른 개체들보다 더 여성적이고 덜 강력한 것으로 묘사된다. 이러한 발견들은 위의 트로프 탐구와 일치하지만, 권력 역학이 사용자에게 불리하게 작용하는 경향이 있다는 것을 명확히 한다. 또한 이들은 권력과 성별이 기존 성별 고정관념을 강화하는 방식으로 개인 수준에서 일치한다는 것을 보여준다.
그림 6은 이에 대한 추가적인 직관을 제공하며, 사용자 대 다른 개체들과 연관된 상위 15개 구문들을 보여준다. 다른 개체들은 정기적으로 성별이 부여되며, 대부분 남성인 것으로 여겨진다. 반면 사용자들은 "임신"이라고 언급되는 것을 제외하고는 거의 성별이 부여되지 않는다.
일반적으로 "적"(아마도 다른 개체와)인 것을 제외하고, 사용자들은 또한 종종 강력함과 연관되지 않는 역할들("친구," "새로운 학생")이나 심지어 약간 무력한 역할들("혼자")을 맡는다. 이는 "괴롭히는 사람," "무례한," "차가운" 다른 개체들과 대조된다.
그림 6에 기반한 이러한 사례적 주장들은 통계적으로도 성립한다. 즉, 사회문화적 의미의 차원에서 단어 의미를 추론하기 위해 위에서 설명한 방법들을 사용하고, 각 차원의 각 끝과 가장 연관된 상위 100개 단어로 부분집합을 만들어, 우리는 캐릭터 인사말에서 사용자("you")에 대한 언급이 인사말에서 언급되는 다른 개체들과 비교하여 남성적인 것보다 더 여성적이고, 덜 강력한 구문들과 연관될 가능성이 유의하게(p < .0001) 더 높다는 것을 발견한다.
발견들은 상위 200개, 300개, 400개, 500개 단어의 사용에도 견고하다. 우리는 100개의 캐릭터를 무작위로 선택하고 그들의 표현된 성별을 수동으로 분류함으로써 성별에 대한 우리의 발견을 더 검증한다.
우리의 분석은 100개 캐릭터 중 정확히 절반(50개)이 단일한(즉, 단 하나의) 남성으로 확인되었으며, 단지 17개만이 명시적으로 단 하나의 여성으로 확인될 수 있다는 것을 발견했다. 나머지는 명시적으로 또는 암시적으로 성별이 없거나(12개), 하나가 명시적으로 논바이너리(1개)였으며, 나머지는 여러 개체들을 포함했다.
결론
Character.AI를 둘러싼 최근 논의는 특히 미성년자에게 이 사이트가 가하는 위험에 당연히 초점을 맞추고 있다. 우리의 발견은 캐릭터가 어떻게 사용되는지가 아니라 어떻게 만들어지는지만을 탐구하기 때문에 이러한 우려에 직접적으로 답할 수 없다. 그러나 우리의 결과는 다른 잠재적 우려 영역들을 제기한다.
구체적으로, 우리는 문제가 있는 암묵적 성별 규범과 더 명시적인 형태의 성별 기반 폭력을 고착화하는 캐릭터 인사말의 상당한 증거를 본다. 우리는 또한 명시적으로 치료사 역할을 한다고 내세우는 봇들과 봇 창작자들이 종종 청소년에게 어필하는 팬덤과 트로프 모두에 관심이 있다는 전반적인 증거를 본다.
다시 말해, 이러한 발견들이 대중 언론에서 자세히 다룬 가장 비극적인 사건들에 직접적으로 답하지는 않지만, 우리의 발견들이 이러한 비극들이 제기하는 근본적인 우려들을 반박하지도 않는다.
팬픽션에 대한 시사점도 존재한다. 위에서 언급했듯이, AI는 팬픽션의 세계에 잠재적 부정적 요소들을 가져온다. 여기서는 예술적 콘텐츠의 불법적 사용, 동의 없이 실제 사람들을 역할극 설정으로 가져오는 것, 그리고 예술적 표현을 AI로 대체하는 것에 대한 우려가 존재한다.
그러나 팬픽션은 작가들이 정전 자료를 개인화할 수 있는 통로다. 예를 들어 부차적인 캐릭터들에 초점을 맞추고(Milli and Bamman 2016) 과소대표된 정체성의 표현을 포함함으로써(Floegel 2020; Hazra 2021). 그리고 만약 AI 개인화가 자신의 이야기를 독자들에게 더 재미있게 만든다면 자신의 작품의 AI 개인화에 열린 작가들이 있다(Kim et al. 2024).
AI 개인화가 건설적인 비판의 교환을 시대착오적인 것으로 만든다 하더라도, 팬픽션 작가들이 긴밀한 관계를 발전시킬 수 있는 또 다른 방법은 서로의 작품에 깊은 감정적 참여를 표현하는 것이다(Ghosh, Froelich, and Aragon 2023). 따라서 AI 보조 작품이 팬들에게 감정적으로 공명하는 한, 팬픽션 커뮤니티는 AI 시대에도 여전히 가능할 수 있다.
따라서 Character.AI에 대한 모든 것이 "나쁜" 것은 아니다. 예를 들어, Character.AI의 상당 부분은 오랫동안 다른 사이트에서 이어져 온 방식으로 큰 가상 세계들의 관련 스토리라인을 이어가는 비교적 무해한 팬픽션인 것으로 보인다.
더욱이 Character.AI에서 성별 고정관념, 청소년 겨냥, 그리고 지배 중심의 에로틱 역할극에 대한 호기심과 같은 문제들은 이 특정 사이트에 어떤 방식으로든 명확히 고유한 것은 아니다. 후자의 점은 예를 들어 종종 배신적인 적들에 맞서 플레이하고 이기는 게임으로 이해되는 역할극의 맥락에서 이해되어야 한다.
전반적으로 이러한 특성들은 소셜 미디어와 팬픽션의 세계 다른 곳에서의 발견들과 쉽게 나란히 놓인다. 이것이 사이트의 가능한 결과들을 정당화하지는 않지만, Character.AI가 생성형 AI를 빠르게 받아들이고 있는 소셜 웹의 얼굴인 만큼 많은 것이 동일하게 남아있다는 점을 강조한다.
모든 기술과 마찬가지로, 우리는 Character.AI가 보편적으로 좋거나 나쁘다고 확실히 말할 수 없다. 우리가 어느 정도 확실성을 가지고 말할 수 있다고 믿는 것은 Character.AI가 커뮤니티 기반 디자인에도 불구하고 소셜 미디어가 진정으로 사회적인 세계에서 더욱 멀어지는 새로운 형태의 사용자 생성 콘텐츠 사이트라는 것이다.
이는 인사말이 실제 소셜 미디어 플랫폼에서의 참여를 요청하는 것으로 다시 활용되는 방식과 그룹 채팅과 같이 이후 제거된 사회적 기능들에 의해 보여진다. Character.AI가 소셜 미디어에서 이러한 새로운 형태의 사용자 생성 콘텐츠 사이트로의 증가하는 전환의 전조 역할을 하는지는 지켜봐야 할 일이다.
어떤 경우든, 우리의 발견들은 상당한 주의사항과 함께 온다. 우리의 크롤링은 Character.AI의 상당 부분을 나타내지만, 모든 공개 캐릭터를 포착하지는 못하며, 사적 생성물은 더욱 그렇다. 더욱이 사이트는 빠르게 변화하므로 시간적 타당성에 대한 우려가 존재한다(Munger 2019).
또한 우리의 방법들은 다양한 방식으로 제한적이다. 우리가 이러한 제한사항들에 대해 명시적이려고 노력했지만, 그럼에도 불구하고 이들이 해석을 제약할 수 있다. 요약하면, 우리는 우리의 작업이 이 실질적이고 개념적으로 중요한 웹사이트를 더 자세히 탐구하는 첫 번째 단계를 나타낸다고 믿으며, 다른 사람들이 우리의 데이터를 활용하고 자신들의 데이터를 탐구하여 이를 더 잘 이해하기를 바란다.
본 콘텐츠는 2025년 5월 19일에 발행된 "A large-scale analysis of public-facing, community-built chatbots on Character.AI" 논문을 번역한 것입니다.
의견을 남겨주세요