
Introduction
클라우드 컴퓨팅과 모바일 앱의 시대, 서버에 몰리는 트래픽은 기하급수적으로 늘어나고 있습니다. 이런 상황에서 단일 서버로는 모든 요청을 감당하기 어려운데요. 바로 이때 등장하는 것이 로드 밸런서(Load Balancer)입니다. 들어오는 트래픽을 여러 서버에 분산시켜 과부하를 방지하고 응답 속도를 높이는 역할을 하죠.
하지만 로드 밸런싱이라는 말 자체는 조금 추상적으로 들립니다. 구체적으로 어떤 알고리즘으로 동작하며, 상황에 따라 어떤 전략을 취하는 것이 좋을까요? 이에 대한 해답을 얻기 위해 현업에서 가장 많이 사용되는 5가지 로드 밸런싱 알고리즘을 코드와 함께 파헤쳐 보기로 했습니다. 바로 AlgoMaster Newsletter의 <Load Balancing Algorithms Explained with Code>을 번역해서 가져왔는데요.
라운드 로빈부터 IP 해시까지, 각 알고리즘의 작동 원리와 장단점을 살펴보고 실제 구현 코드까지 함께 살펴보겠습니다. 여러분이 개발하려는 서비스에 어떤 로드 밸런싱 전략이 가장 적합할지, 이 글을 통해 실마리를 얻어가시길 바랍니다.
코드와 함께하는 로드 밸런싱 알고리즘 이해하기
로드 밸런싱이란 들어오는 네트워크 트래픽을 여러 서버에 분산시켜 단일 서버에 과부하가 걸리지 않도록 하는 과정입니다.
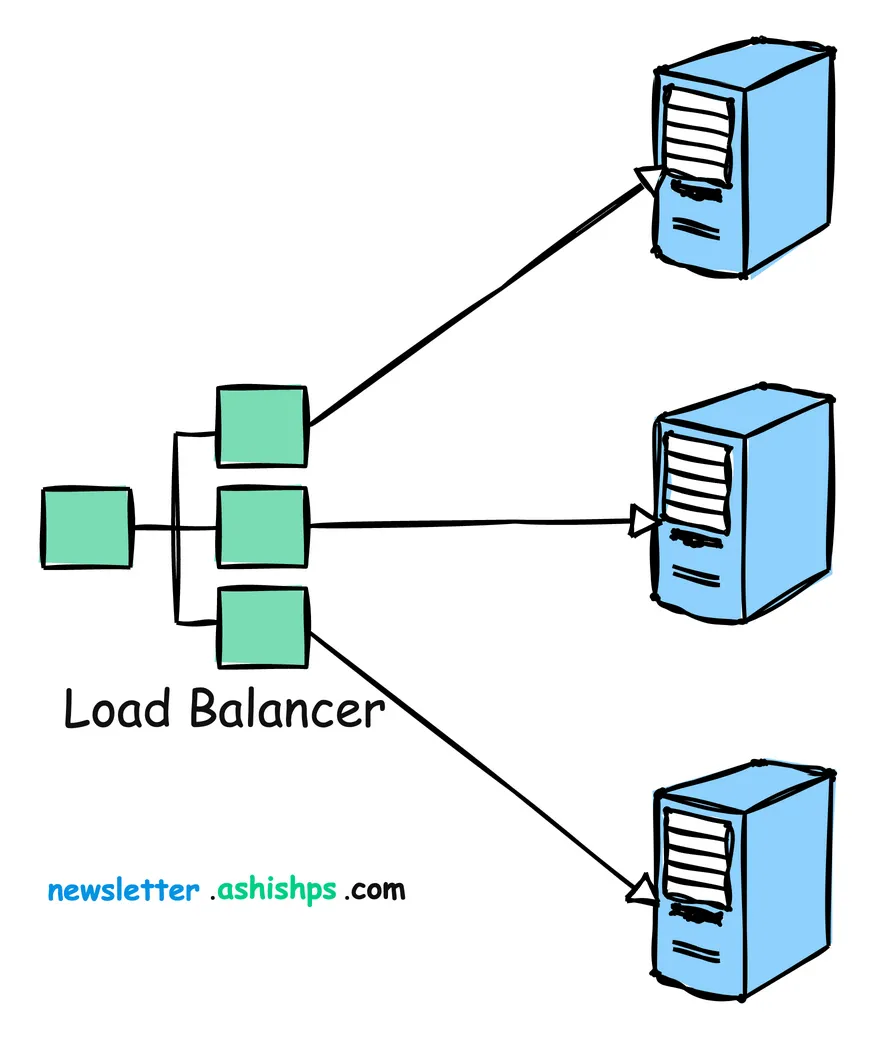
워크로드를 고르게 분산함으로써 로드 밸런싱은 단일 서버의 과부하를 방지하고, 응답 시간을 줄여 성능을 향상시키며, 서버 장애 시 트래픽을 우회시켜 가용성을 높이는 것을 목표로 합니다.
로드 밸런싱을 달성하기 위해서는 여러 알고리즘이 있는데요. 각각마다 장단점이 있습니다.
이 글에서는 가장 널리 사용되는 로드 밸런싱 알고리즘, 작동 원리, 사용 시기, 장단점, 코드 구현 방법에 대해 살펴보겠습니다.
알고리즘 1: 라운드 로빈(Round Robin)
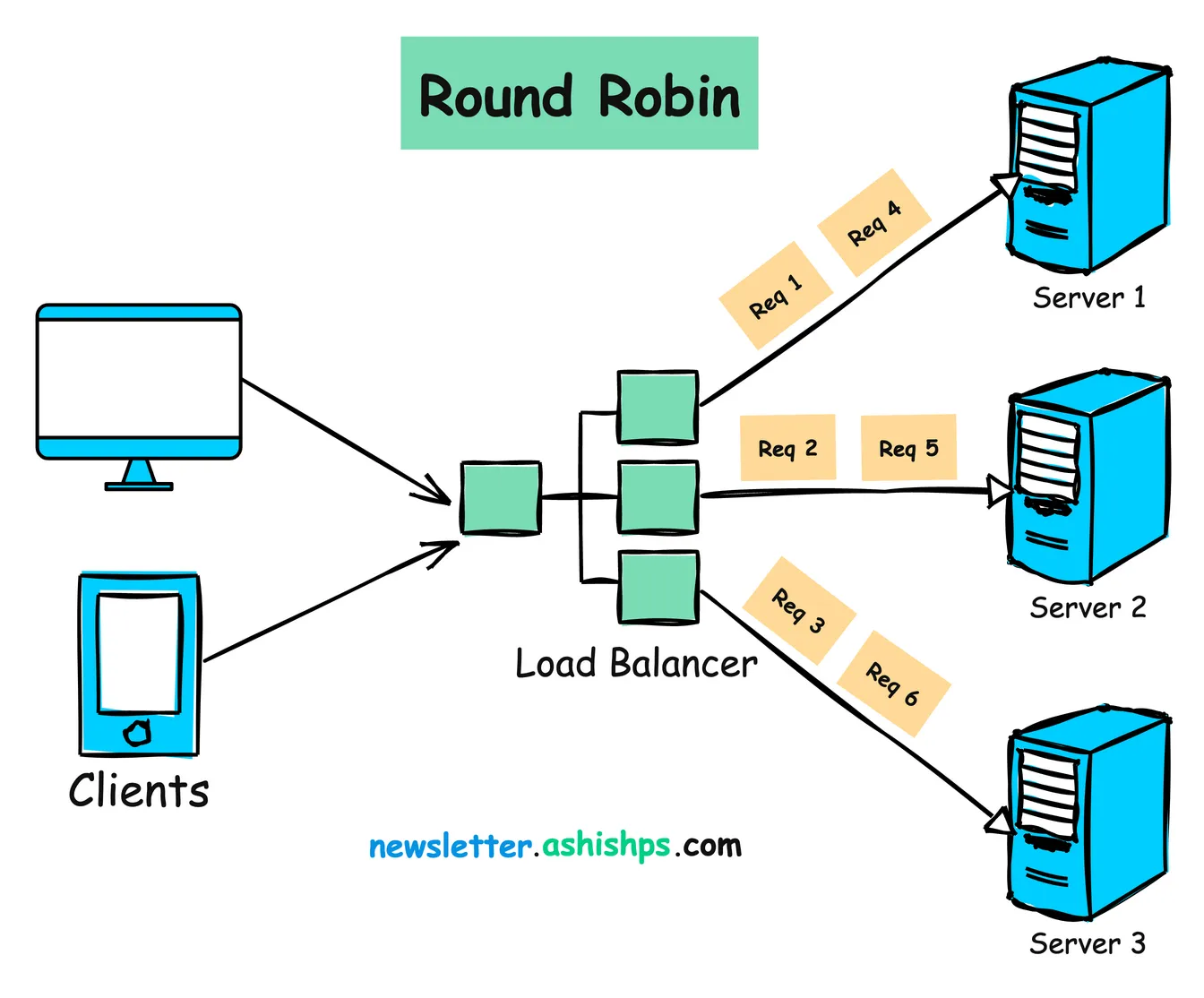
작동 원리:
- 요청이 목록의 첫 번째 서버로 전송됩니다.
- 다음 요청은 두 번째 서버로 전송되는 식입니다.
- 목록의 마지막 서버 다음에는 알고리즘이 첫 번째 서버로 돌아갑니다.
사용 시기:
- 모든 서버의 처리 능력이 비슷하고 요청 처리에 동등한 능력을 가진 경우.
- 단순성과 부하의 고른 분산이 더 중요한 경우.
장점:
- 구현과 이해가 쉽습니다.
- 트래픽의 고른 분산을 보장합니다.
단점:
- 서버 부하나 응답 시간을 고려하지 않습니다.
- 서버의 처리 능력이 다를 경우 비효율성을 초래할 수 있습니다.
구현:
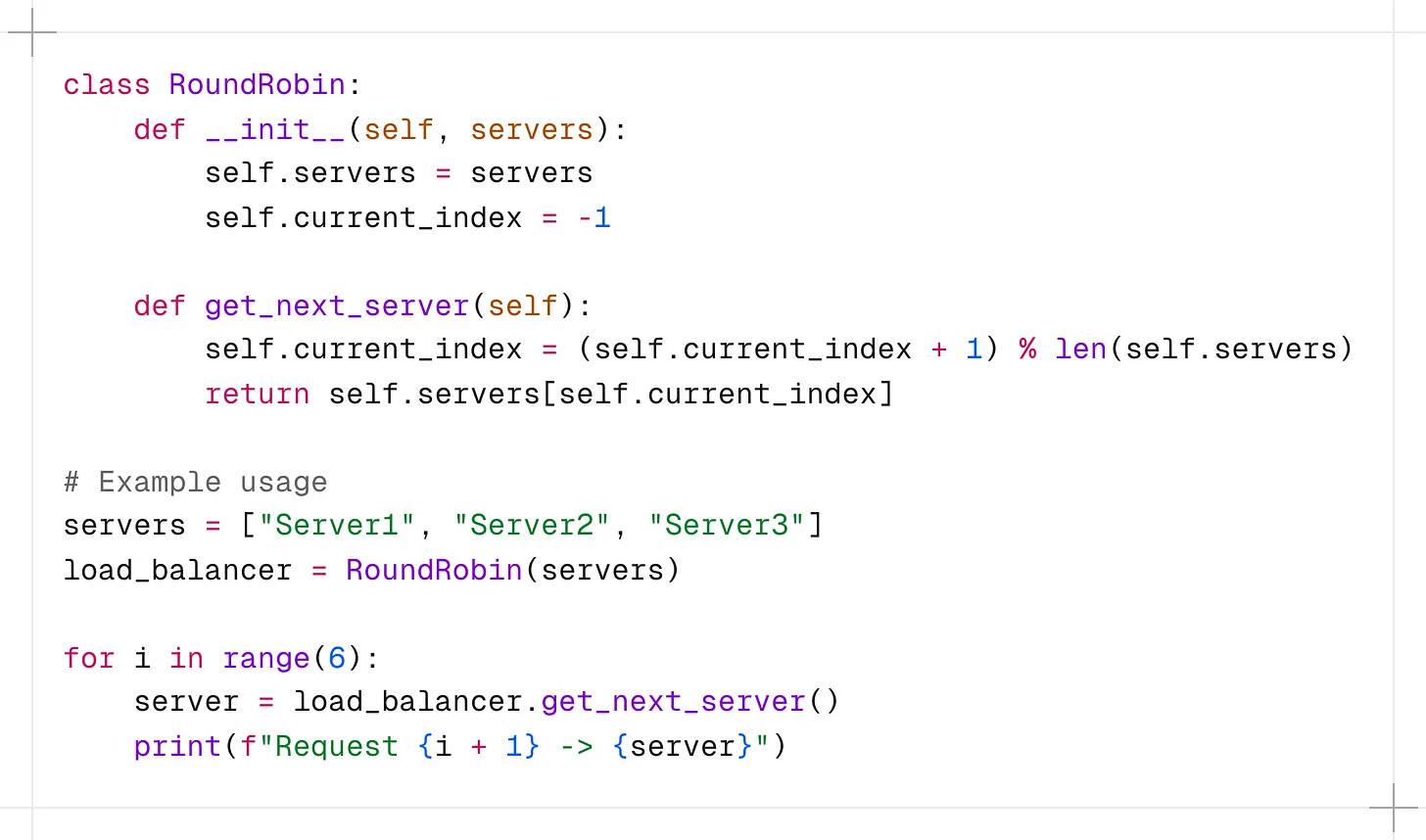
이 구현에서 RoundRobin 클래스는 서버 목록을 유지하고 현재 인덱스를 추적합니다.
get_next_server() 메서드는 인덱스를 업데이트하고 사이클에서 다음 서버를 반환합니다.
알고리즘 2: 가중 라운드 로빈(Weighted Round Robin)
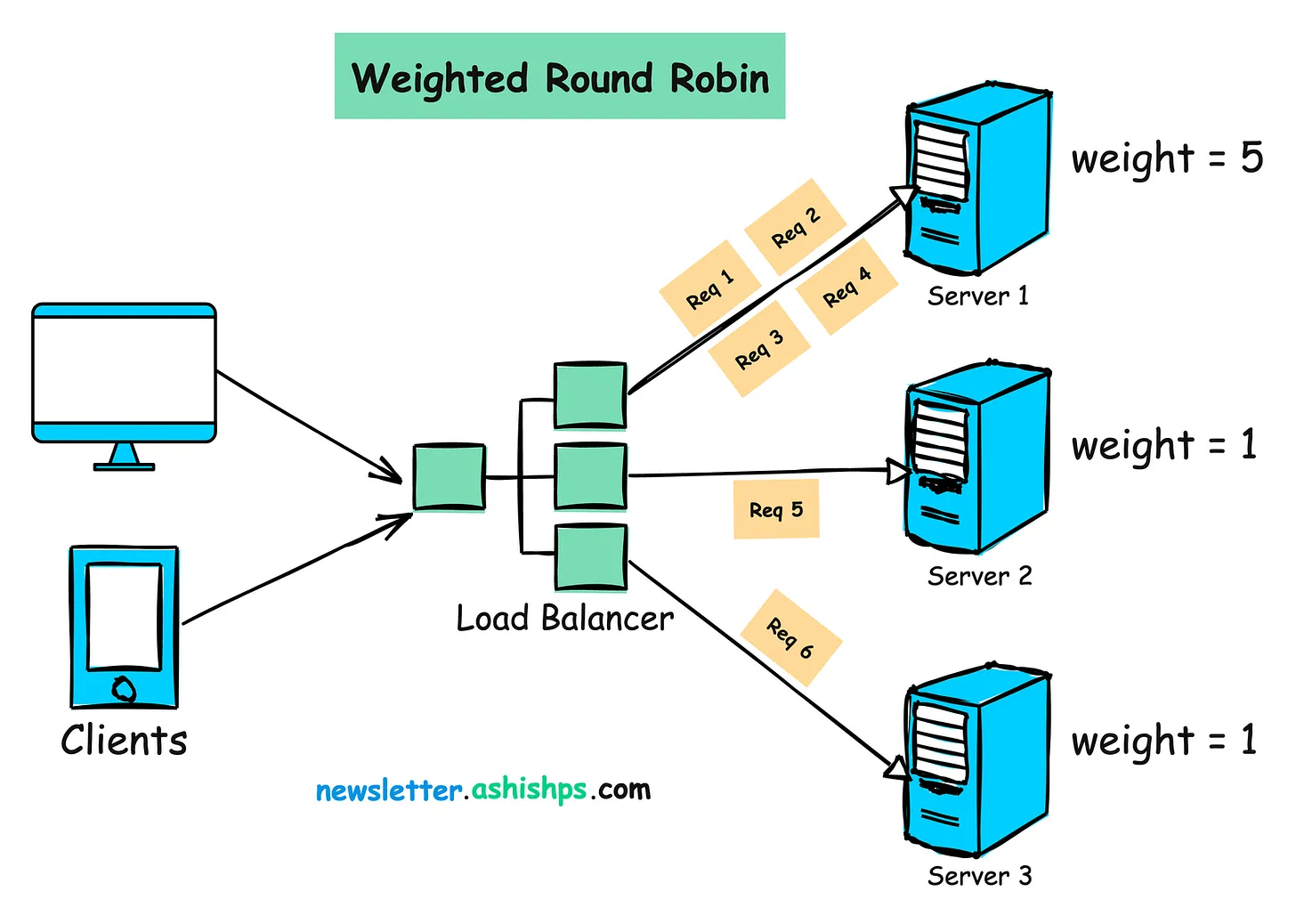
작동 원리:
- 각 서버에는 처리 능력이나 가용 자원에 따라 가중치가 할당됩니다.
- 높은 가중치의 서버는 들어오는 요청 중 비례적으로 더 큰 부분을 받습니다.
사용 시기:
- 서버의 처리 능력이나 가용 자원이 다를 때.
- 각 서버의 용량에 따라 부하를 분산시키고 싶을 때.
장점:
- 서버 용량에 따라 부하를 균형 있게 조정합니다.
- 서버 자원을 더 효율적으로 사용합니다.
단점:
- 단순 라운드 로빈보다 구현이 약간 더 복잡합니다.
- 현재 서버 부하나 응답 시간을 고려하지 않습니다.
구현:
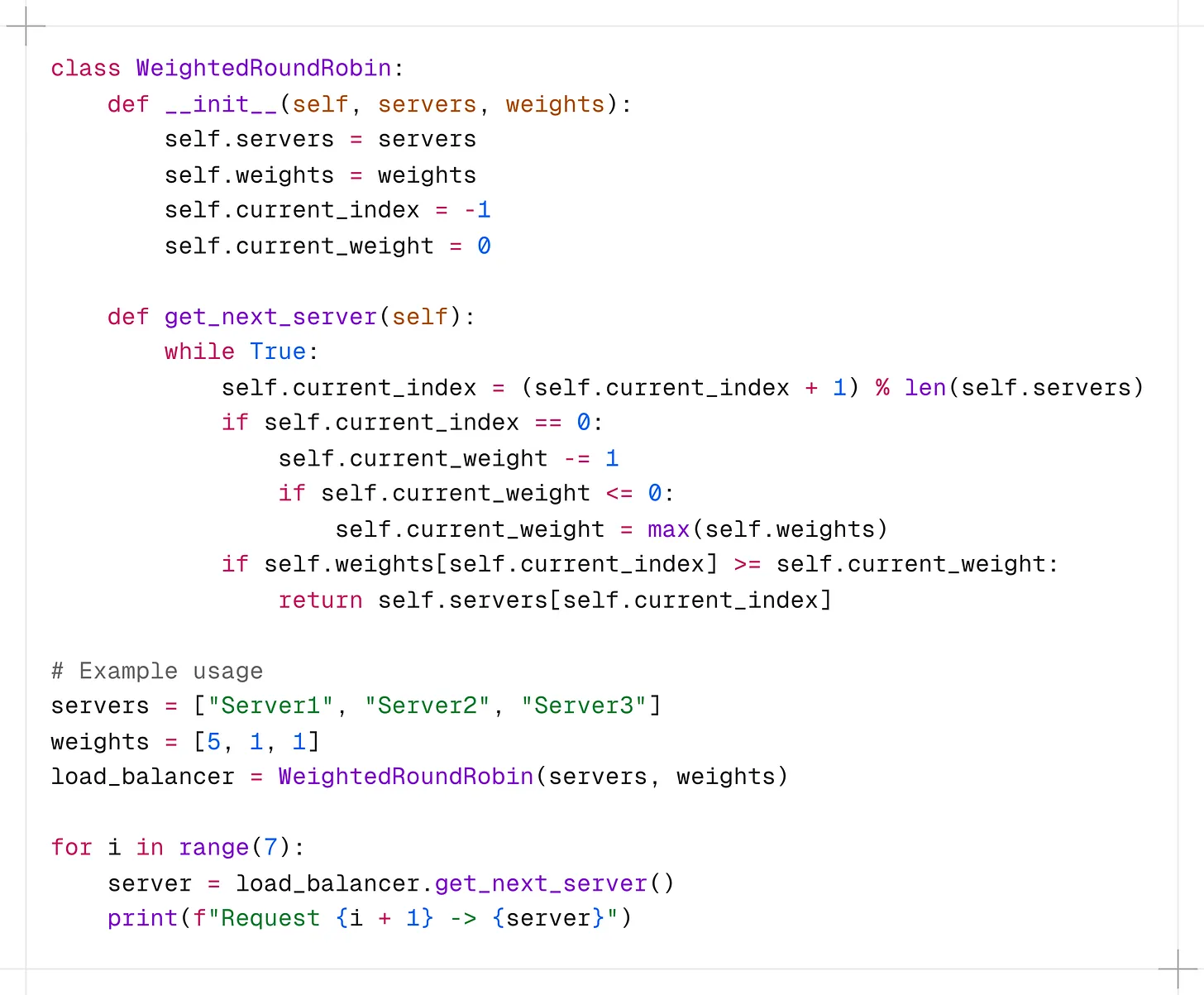
이 구현에서 WeightedRoundRobin 클래스는 서버 목록과 해당 가중치를 받습니다.
get_next_server() 메서드는 무한 루프를 실행하여 가중치에 따라 적합한 서버를 찾으며, 높은 가중치의 서버가 더 많은 요청을 받도록 합니다.
알고리즘은 현재 가중치를 추적하고 각 반복에서 이를 조정하여 원하는 분배 비율을 유지합니다.
ex) 가중치가 [5, 1, 1]이면 Server 1은 Server 2나 Server 3보다 5배 더 자주 선택됩니다.
알고리즘 3: 최소 연결(Least Connections)
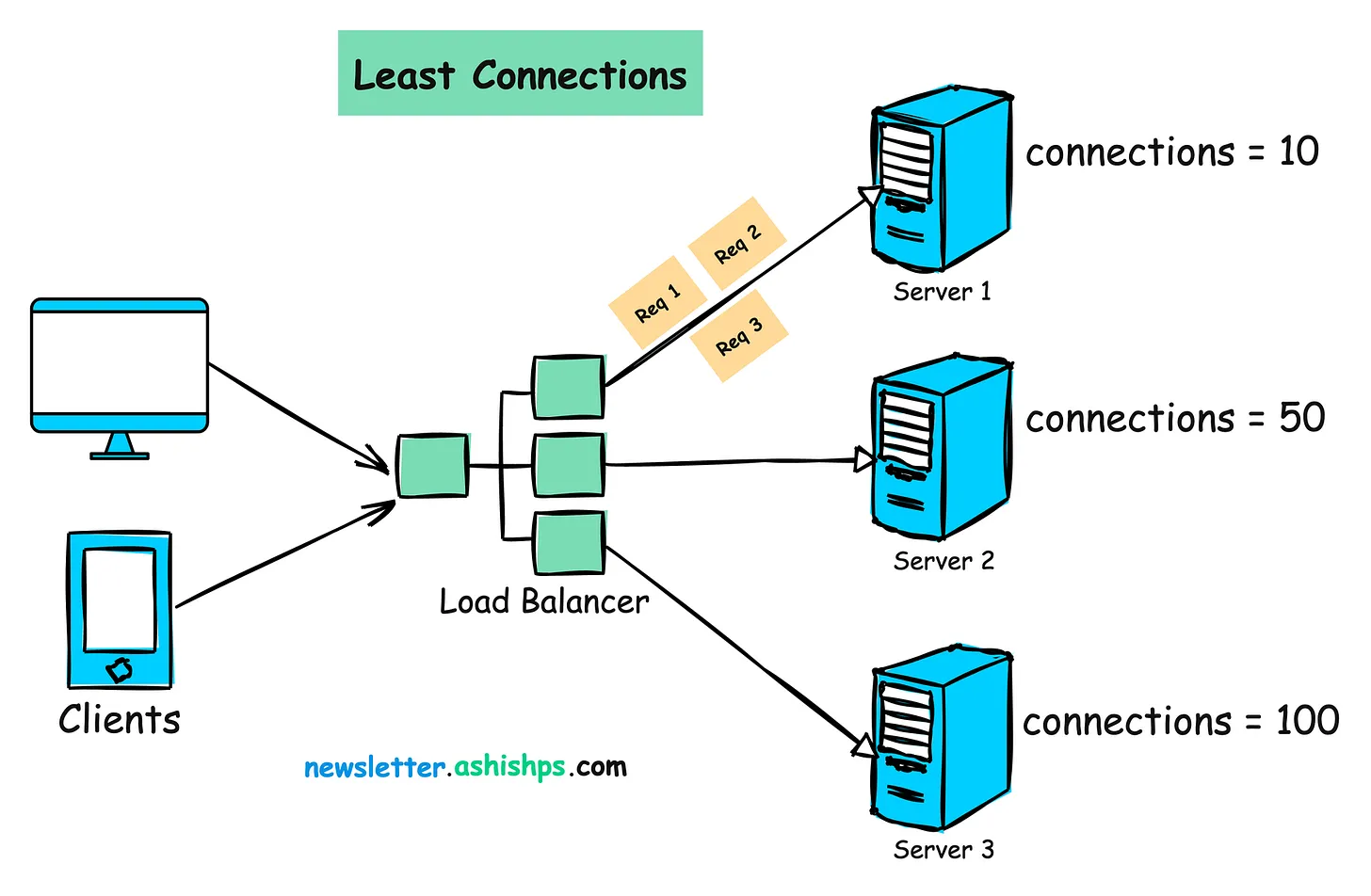
작동 원리:
- 각 서버의 활성 연결 수를 모니터링합니다.
- 활성 연결 수가 가장 적은 서버에 들어오는 요청을 할당합니다.
사용 시기:
- 현재 활성 연결 수에 따라 부하를 분산시키고 싶을 때.
- 서버의 처리 능력은 비슷하지만 동시 연결 수준이 다를 수 있을 때.
장점:
- 현재 서버 부하에 따라 더 역동적으로 부하를 균형 조정합니다.
- 어떤 서버도 많은 수의 활성 연결로 과부하되는 것을 방지하는 데 도움이 됩니다.
단점:
- 서버의 처리 능력이 다를 경우 최적이 아닐 수 있습니다.
- 각 서버의 활성 연결을 추적해야 합니다.
구현:

이 예제에서 LeastConnections 클래스는 서버의 맵과 각 서버의 활성 연결 수를 유지합니다.
get_next_server() 메서드는 연결 수가 가장 적은 무작위 서버를 선택하고 해당 서버의 연결 수를 증가시킵니다.
release_connection() 메서드는 연결이 닫힐 때 호출되며, 해당 서버의 연결 수를 감소시킵니다.
알고리즘 4: 최소 응답 시간(Least Response Time)
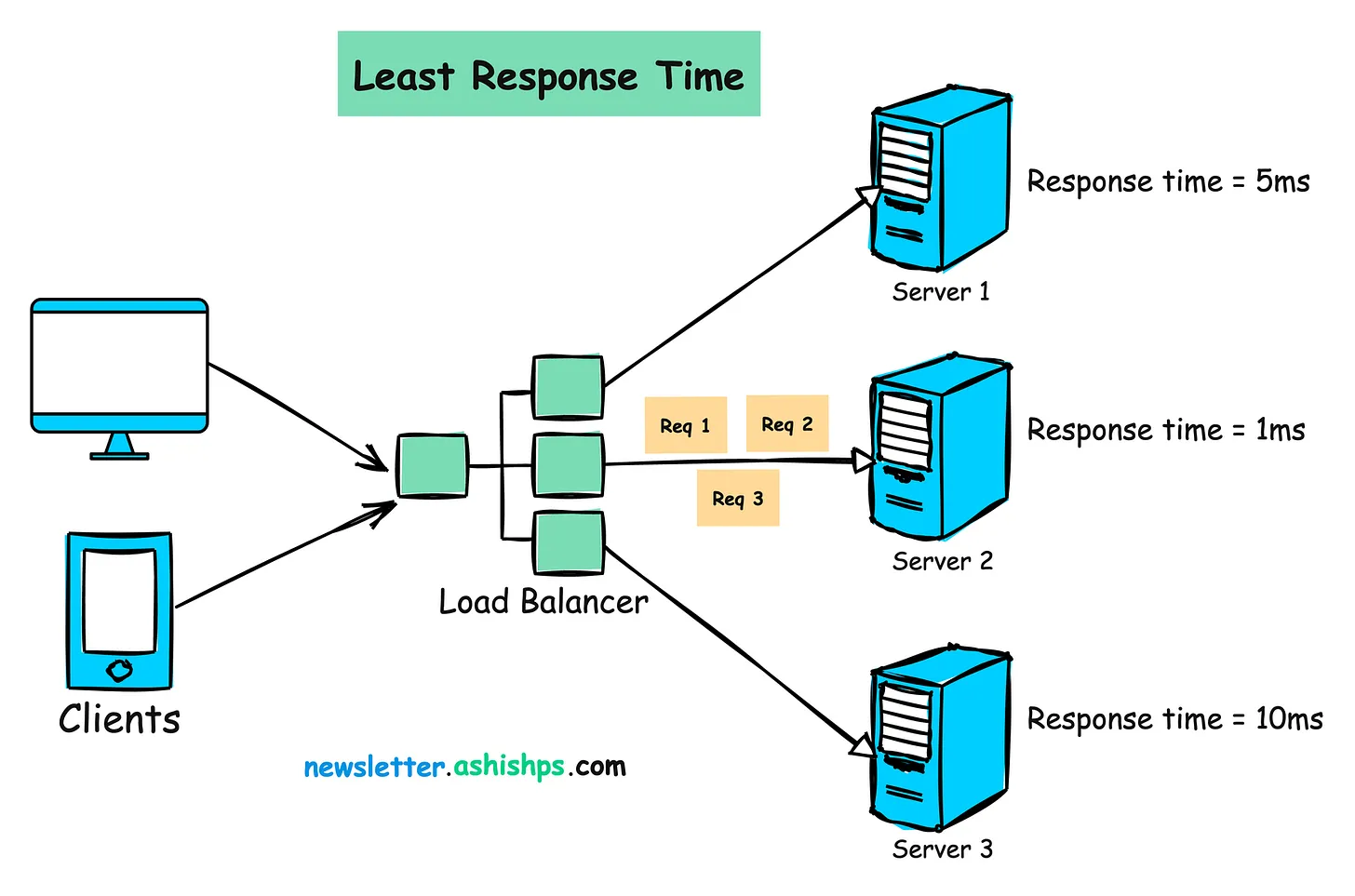
작동 원리:
- 각 서버의 응답 시간을 모니터링합니다.
- 응답 시간이 가장 빠른 서버에 들어오는 요청을 할당합니다.
사용 시기:
- 응답 시간이 다양한 서버가 있고 요청을 가장 빠른 서버로 라우팅하고 싶을 때.
장점:
- 응답 시간이 가장 빠른 서버를 선택하여 전체 지연 시간을 최소화합니다.
- 서버 응답 시간의 변화에 역동적으로 적응할 수 있습니다.
- 빠른 응답을 제공하여 사용자 경험 개선에 도움이 됩니다.
단점:
- 분산 시스템에서 도전적일 수 있는 서버 응답 시간의 정확한 측정이 필요합니다.
- 서버 부하나 연결 수와 같은 다른 요인을 고려하지 않을 수 있습니다.
구현:

이 예제에서 LeastResponseTime 클래스는 서버 목록을 유지하고 각 서버의 응답 시간을 추적합니다.
get_next_server() 메서드는 응답 시간이 가장 적은 서버를 선택합니다. update_response_time() 메서드는 각 요청 후에 호출되어 해당 서버의 응답 시간을 업데이트합니다.
응답 시간을 시뮬레이션하기 위해 simulate_response_time() 함수를 사용하여 서버의 응답 시간을 흉내 내는 무작위 지연을 도입합니다.
실제 시나리오에서는 각 서버의 실제 응답 시간을 측정해야 합니다.
알고리즘 5: IP 해시(IP Hash)
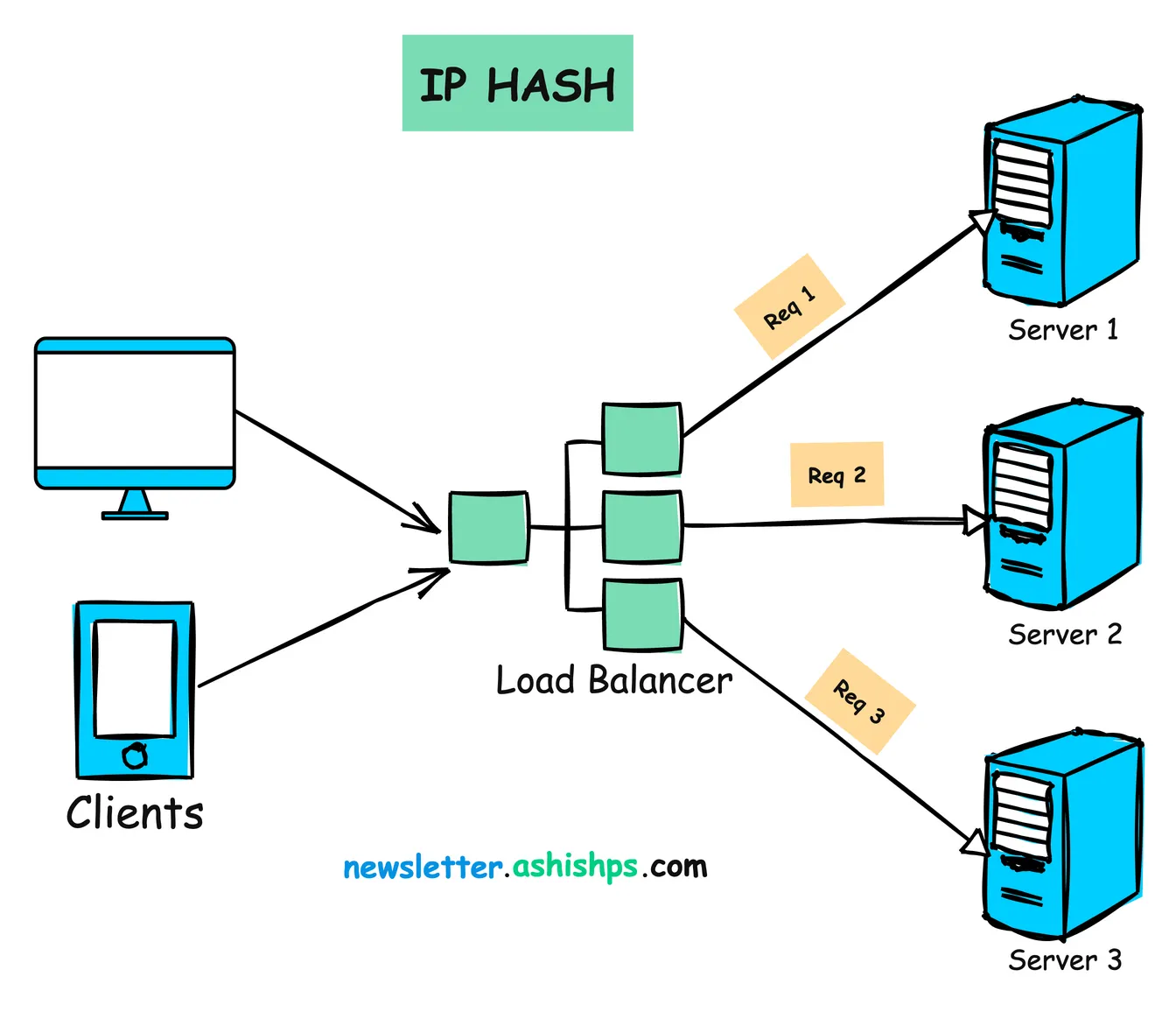
작동 원리:
- 클라이언트의 IP 주소에서 해시 값을 계산하고 이를 사용하여 요청을 라우팅할 서버를 결정합니다.
사용 시기:
- 같은 클라이언트의 요청이 항상 같은 서버로 전달되어야 하는 세션 지속성(Session Persistence)이 필요할 때.
장점:
- 구현이 간단합니다.
- Sticky Session이 필요한 애플리케이션에 유용합니다.
단점:
- 특정 IP 주소가 다른 주소보다 더 많은 트래픽을 생성할 경우 불균등한 부하 분산으로 이어질 수 있습니다.
- 서버가 다운되면 해시 매핑을 재구성해야 하므로 유연성이 부족합니다.
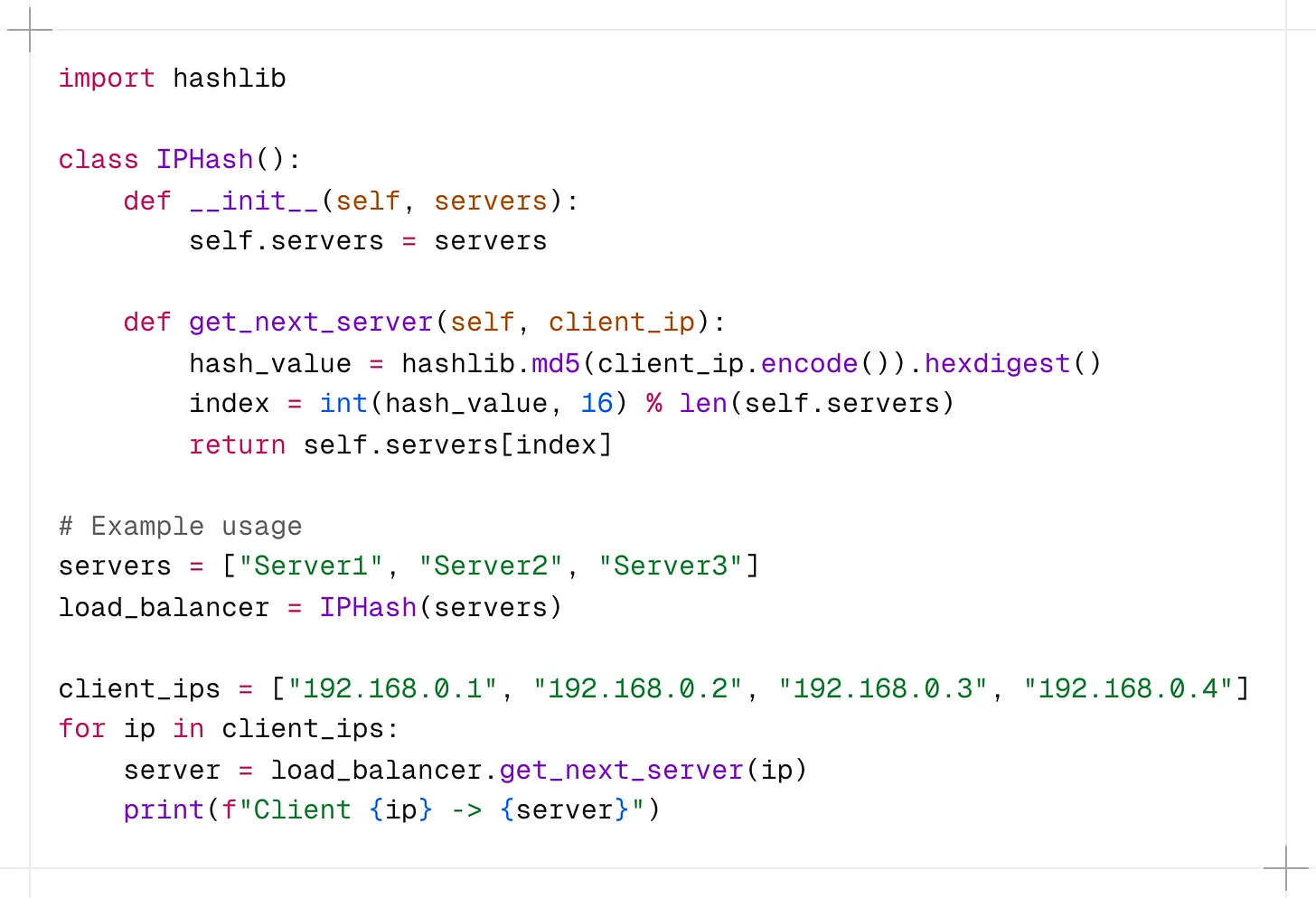
구현:
코드 링크
이 구현에서 IPHash 클래스는 서버 목록을 받습니다.
get_next_server() 메서드는 클라이언트 IP 주소의 MD5 해시를 계산하고 모듈로 연산자를 사용하여 요청을 라우팅해야 할 서버의 인덱스를 결정합니다.
이렇게 하면 동일한 IP 주소의 요청이 항상 동일한 서버로 전달됩니다.
결론
- 라운드 로빈: 간단하고 균일하게 분산시키기에 동일한 서버가 여러 대 떠있는 환경에 가장 적합합니다.
- 가중 라운드 로빈: 서버 용량에 따라 분산시키며, 서로 다른 종류의 서버가 혼합된 환경에 적합합니다.
- 최소 연결: 부하에 따라 동적으로 균형을 조정하여 다양한 워크로드에 이상적입니다.
- 최소 응답 시간: 가장 빠른 응답을 위해 최적화하며, 다양한 서버 성능을 가진 환경에 가장 적합합니다.
- IP 해시: 세션 지속성을 보장하며, 상태를 유지해야 하는(stateful) 애플리케이션에 유용합니다.
적절한 로드 밸런싱 알고리즘을 선택하는 것은 서버 성능, 워크로드 분산, 성능 요구 사항 등 시스템의 특정 요구 사항과 특성에 따라 달라진다는 걸 명심하세요.
Top 1% 개발자로 거듭나는 확실한 처방전, 데브필입니다.

의견을 남겨주세요