
[요약]
1. AI 모델의 크기는 빠른 속도로 거대화되고 있으나, 반도체 칩은 성능 개선 한계에 다다르며 이를 제대로 뒷받침하지 못하고 있습니다.
2. 이러한 칩 성능 한계에 대한 대안으로, AI 엔지니어들은 GPU 여러 개를 병렬로 이어붙여 연산 속도를 높이는 스케일 아웃(Scale-out)을 통해 거대 모델을 학습시키고 있습니다.
3. 하지만, 이러한 병렬 컴퓨팅 방식에서는 메모리와 연산 장치 간의, 연산 장치와 연산 장치 간의 대역폭 한계가 연산 속도 개선의 장애물로 작용하고 있습니다.
4. 테슬라는 이를 해결하기 위해, 칩을 구성하는 가장 작은 단위부터 스케일 아웃에 용이한 형태로 다시 설계한 D1 칩을 개발합니다.
5. 이렇게 개발한 D1 칩으로 구성된 Dojo 컴퓨터는 현존하는 여타 AI 학습용 연산 장치를 압도하는 성능을 보여줄 것으로 기대받고 있습니다.
6. Dojo 컴퓨터가 이러한 뛰어난 성능을 낼 수 있던 배경에는, 서비스부터 인프라, 하드웨어, 소프트웨어까지 모든 구성 요소를 직접 개발해 상호 최적화하는 테슬라의 풀 스택 엔지니어링 역량이 자리하고 있습니다.
7. 이러한 개발 역량은 기존 자동차 기업은 물론이고, 여타 IT 공룡들조차 모방하기 힘든 것으로, Dojo 컴퓨터가 목표한 성능을 구현할 시 테슬라의 압도적인 기술적 해자로 작용할 것입니다.
자동차 회사가 반도체까지 만들어야 할까?
테슬라봇과 FSD에 가려서 제대로 주목받지 못했지만, 두 차례의 AI Day에서 진행된 또 하나의 중대 발표는 Dojo 컴퓨터의 개발입니다.
FSD 모델 학습에 쓰이는 반도체 칩과 이를 활용한 슈퍼 컴퓨터를 테슬라가 직접 만들겠다고 발표한 겁니다.
사실 테슬라는 일찍이 배터리부터 모터, 차량용 소프트웨어와 사내 ERP까지 온갖 부품과 소프트웨어를 자체 개발하고 생산해왔습니다. 이렇게 내재화를 진행하는 배경과 이유에 대해서는 아래 글에서 이미 몇 차례 다루기도 했었는데요.
이런 넓은 범위의 수직계열화에 테슬라 나름의 합리적인 이유가 있었다지만, 그럼에도 불구하고 “그렇게까지 할 필요가 있냐”, “너무 과한 것 아니냐”는 외부 시선이 줄곧 존재해왔던 것도 사실입니다.
그런데 이제 심지어는 반도체와 슈퍼 컴퓨터까지 직접 만든다고 하니, 전통 자동차 업체들은 더더욱 눈이 휘둥그레해질 수밖에 없었을 겁니다. 물론 직접 제조가 아닌 설계 후 위탁 생산이라고는 하지만, 자동차 파는 회사가 꼭 복잡한 반도체까지 직접 설계해서 써야 하냐는 거죠.
그래서 이번에는 테슬라가 왜 굳이 반도체를 직접 개발했으며, 테슬라가 만든 반도체와 슈퍼컴퓨터는 다른 제품과 무엇이 다른지 이야기해보려 합니다.
테슬라는 왜 직접 반도체를 개발했나?
테슬라는 왜 굳이 반도체를 직접 개발했을까요?
결론부터 말하면, AI 모델의 대형화로 컴퓨팅 수요는 폭증하고 있으나, 시중에 나와있는 연산 장치로는 이를 제대로 충족시키지 못하고 있기 때문입니다.
수요 측면의 이야기부터 먼저 해보겠습니다.
ChatGPT의 등장으로, 그 어느 때보다도 많은 사람들이 AI의 상용화와 광역 보급에 기대감을 품고 있습니다. 물론 영화 속에 나오는 범용 인공지능, AGI(Artificial General Intelligence)까지 구현되려면 아직도 많은 시간이 필요할 겁니다. 하지만 그럼에도 AGI까지 나아가기 위한 AI 개발의 방향성 자체는 어느 정도 확정됐다는 게 중론인 것 같은데요.
그 방향성이라 함은, 흔히들 말하는 “초거대 인공지능”을 만드는 겁니다. 모델의 크기를 최대한 키우고 대량의 데이터를 학습시키면, 이에 비례해 AI의 성능도 향상된다는 것이 업계에서는 진리처럼 받아들여지고 있는 것으로 보입니다.
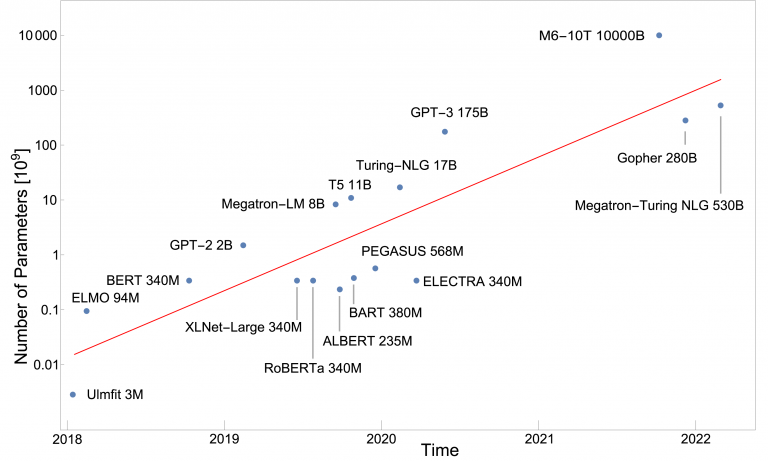
사실 10여년 전까지만 해도 수천 만 혹은 수억 개 파라미터 수준의 중소형 모델이 대다수였습니다. 개 중에서 나름 큰 모델이라고 해봤자 15억개 파라미터의 GPT-2 정도가 전부였죠.
그런데 2020년, 무려 1,750억개의 파라미터를 갖춘 GPT-3가 등장합니다. 여기서 중요한건, 모델 사이즈를 어마무시하게 한번 키워봤더니 성능도 이에 비례해 눈에 띄게 비약적으로 발전하는 모습이 포착된 겁니다.
이 때부터 업계에선 “더 큰 모델 = 더 나은 성능”이 공식처럼 자리잡으면서 너도나도 초거대 모델을 만드는 데 뛰어들기 시작합니다. 글로벌 IT 공룡들인 구글, 메타, 바이두 등의 기업은 물론이고, 국내 기업인 네이버나 카카오, LG도 저마다의 초거대 모델을 만들겠다고 선언하며 거대화 경쟁에 참전을 선언합니다.
이렇게 너도나도 거대화에 열을 올리면서 모델의 사이즈는 점점 커져가고 있는데요. 실제로 얼마 전 2023년 출시된 GPT-4의 경우, 공식적으로 파라미터 개수를 공개하지는 않았으나, 무려 조 단위의 파라미터를 갖췄을 것으로 추정되고 있습니다.
그럼, AI 모델은 앞으로 얼마나 더 커져야 하는 걸까요?
딥러닝이 인간의 뇌 작동방식을 본따 만들어졌다고들 말하는 만큼 인간 신체를 구조를 통해 추측해볼 수 있지 않을까 싶은데요.
인간의 뇌에는 파라미터와 유사한 역할을 하는 시냅스라는 부위가 있습니다. 한 사람의 뇌에 약 100조 개의 시냅스가 있다고 하는데요. 그렇다면 인공지능의 파라미터 개수를 이와 근접한 수준으로 늘리기만 하면 인간과 유사한 지능을 갖춘 기계를 만들 수 있는 게 아니냐는 말도 나오고 있습니다. 물론 매우 단순화된 방식의 추정이지만, 이런 식이면 AI 모델은 앞으로 수 십에서 수 백배는 더 커질거란 결론이 나옵니다.
이제 공급 측면의 이야기입니다.
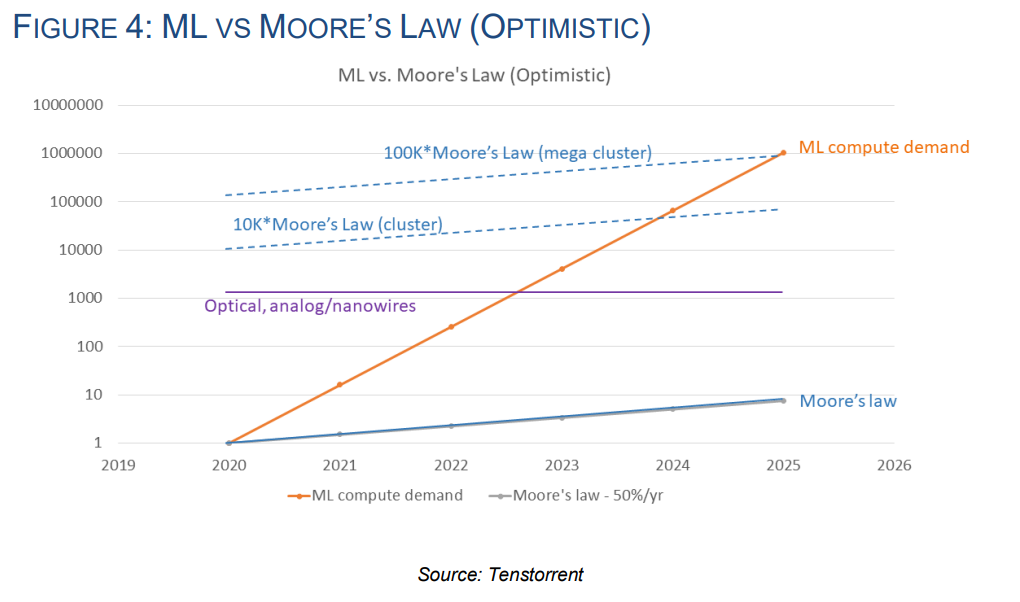
이렇게 모델의 "초거대화"라는 방향성이 정해졌다면, 이제 실행만 하면 될텐데요. 바로 여기서 문제가 발생합니다. 컴퓨팅 수요는 폭증하는데, 공급이 따라주지를 못하는 겁니다.
아무리 멋진 건물 설계도를 그려도 설계대로 시공할 수 없다면 의미가 없겠죠. 수 천 명의 엔지니어가 공들여 10조, 100조 개의 파라미터를 갖춘 초거대 모델을 설계하더라도, 이런 모델을 학습시킬 수 있는 컴퓨팅 자원이 부족하다면 아무 쓸모가 없을 겁니다.
앞서 언급한 GPT-3의 경우, 모델을 한 번 학습시키는 데 무려 수 개월의 시간이 걸린 것으로 알려져 있습니다. 테슬라 역시, FSD 뉴럴넷을 한번 학습시키는 데 한 달이라는 긴 시간이 걸렸다고 하는데요. 일반적인 소프트웨어가 응당 그러하듯, AI의 성능을 정교화하고 업그레이드하기 위해서는 학습 → 테스트 → 배포 → 수정 → 학습의 과정을 무수히 많이 반복해야 합니다. 그런데 학습 한번 시키는 데 몇 달이 걸린다면, 우리가 기대하는 인간 수준의 AI가 출시되는 날은 정말 머나먼 미래가 돼버릴 지도 모릅니다.
특히나 테슬라에게는 시간이 없습니다.
일론 머스크가 도로를 달리는 로보택시를 내놓겠다고 공언한게 벌써 2020년이니, 약속한 기한에서 3년이나 지나버렸습니다. 그런데도 완전 자율주행은 커녕 레벨 3, 4 수준의 자율주행도 좀처럼 완성될 기미를 보이지 않고 있죠.
이런 상황에서 학습 실행 버튼 한번 누르고 1달을 기다려야 하는 상황을 과연 용인할 수 있을까요? 뿐만 아니라 이 1달이란 시간도 앞으로는 점점 길어질 겁니다. 앞서 이야기 했듯 AI 성능 향상을 위해선 모델 크기가 점점 커져야 할 테니까요. 지금 당장 뭔가 중차대한 변화를 만들지 못한다면, 학습 한 번에 1달이 아니라 3달, 6달, 1년이 걸리는 날이 올지도 모릅니다. 바꿔 말하면, 테슬라가 약속한 완전자율주행은 앞으로 수십 년 뒤에나 찾아올 머나먼 미래가 돼버릴 거란 말이죠.
그럼 이렇게 컴퓨팅 파워가 수요를 따라가지 못하고 있는 이유는 무엇일까요?
여기서도 결론부터 말하면, 반도체 성능의 발전 속도가 모델 크기의 성장 속도를 따라가지 못하고 있기 때문입니다.
이제껏 반도체는, “무어의 법칙”이란 이름으로 알려져 있듯 2년에 2배씩 집적도가 향상되며 빠르게 발전해왔는데요. 그런데 최근 그 미세화 수준이 한계에 다다르며, 더 이상 집적도를 향상시키기 어려운 단계에 접어들었습니다.
반면 2017년 구글에서 트랜스포머라는 혁신적인 알고리즘을 발표한 이래, 인공지능 모델의 파라미터 수는 2년간 240배라는 기하급수적인 속도로 커졌다고 합니다. 반도체는 2년에 2배도 버거운 상황인데 말이죠.
이렇게 칩 하나하나의 성능을 발전시키기 어렵다면, 자연히 칩 여러 개를 사용해 성능을 키우는 방향으로 가야겠죠. 모델 크기가 커지면서 폭발적으로 늘어나는 연산 수요에, 엔지니어들은 더 많은 연산 장치를 이어붙여 사용하는 병렬 컴퓨팅 방식으로 대응하고 있습니다. 이를 스케일 아웃(Scale out)이라고 합니다.
비유를 하자면, 풀어야 할 수학 문제의 개수는 점점 늘어나는데 학생의 풀이 실력이 좀처럼 늘지 않으니, 1명한테만 풀게 하던 걸 2명, 3명이 같이 풀게 하는 식으로 해결하는 겁니다.
테슬라 역시 AI 모델이 커져감에 따라 이를 뒷받침하기 위해 GPU 수를 늘리고 있고, 그 수가 21년 기준으로만 무려 1만 대에 달한다고 발표한 바 있었는데요.
그런데 문제는 연산 장치 개수를 늘린다고 해서, 연산 속도가 꼭 이에 정비례하게 향상되지는 않는다는 겁니다.
앞선 이야기한 비유를 다시 사용해 이야기해보겠습니다.
10개 남짓의 몇 안되는 단순한 수학 문제를 2명, 3명, 혹은 5명에게 나눠주고 풀게 하는 일은 어렵지 않습니다. 그런데 풀어야할 수학 문제가 500만개, 학생 수는 10만 명으로 늘어난다면 어떨까요?
문제 수가 500만개 쯤 되면, 문제지를 나르는 것부터 큰 일이 됩니다. 학생들이 끊기지 않고 문제를 계속 풀 수 있도록 산더미 같은 문제지를 열심히 창고에서 각 교실로 운반해야 합니다. 뿐만 아니라 학생들이 문제를 풀고 나면, 각 반의 선생님들이 답안지를 회수해서 다시 채점실로 부지런히 나르는 작업도 만만치 않게 힘들겠죠.
그리고 또, 어떤 문제들은 학생 여러 명이 합심해서 풀고 답안을 맞춰보는 작업까지 거쳐야 한다면 어떨까요?
문제 하나를 학생 A, B, C, D, E 다섯 명이 함께 풉니다. 그리고 E가 풀이 결과를 취합해 가장 많이 나온 답이 무엇인지 파악합니다. 가장 많이 나온 답을 모두에게 전파하고, 해당 값으로 모두의 답안지를 교체하게 합니다. 단순히 문제를 받아 푸는 게 아닌 이런 복잡한 과정들을 진행하게 된다면, 학생들 간에 결과물을 전달하고 의사소통을 진행하는 데 적잖은 시간이 들어갈 겁니다.
문제는, 이렇게 문제지를 운반하고 답안을 취합/전파하는 시간이 문제 풀이의 병목이 되어버리는 겁니다. 문제지가 교실에 도착하지 않는다면, 혹은 학생들 간에 결과물을 공유하는 시간이 지나치게 오래 걸린다면, 학생 숫자를 아무리 늘려도 풀이 소요 시간에는 별 변화가 없을 수도 있습니다.
GPU 장치가 늘어나도 연산 성능은 GPU 개수에 정비례하게 향상되지 않는 이유도 위와 동일합니다.
아무리 연산 장치 개수가 늘어나 연산 속도를 빠르게 만든다 할지라도, 연산 장치와 메모리간의, 연산 장치와 연산 장치 간의 데이터 전송 속도가 이를 받쳐주지 못하기 때문입니다.
시간당 가져올 수 있는 데이터의 양을 대역폭(Bandwidth)라고 하는데요. 모델 크기가 커지고 학습할 데이터가 많아지면, 메모리와 연산장치, 연산 장치와 연산 장치 간에 주고 받아야 할 데이터가 많아지고, 이를 위해 요구되는 대역폭의 수준 역시 높아질 수밖에 없습니다.
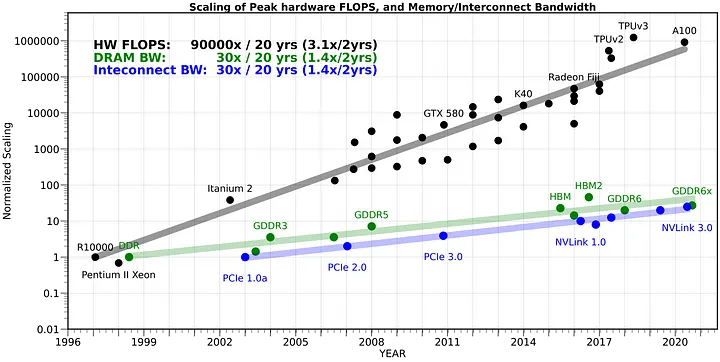
그런데, 이 대역폭의 발전 속도가 생각보다 많이 느리게 발전하면서 연산 속도의 발목을 잡고 있습니다.
실제로 지난 20여년간, 연산 장치의 처리 속도는 약 90,000배 높아진 반면, 메모리와 연산 장치 간의 대역폭은 고작 30배 남짓 높아졌다고 하는데요. 이대로라면 아무리 연산 장치를 이어 붙여서 연산 속도를 높여도 GPU는 학습할 데이터가 없어서 손놓고 놀게 되는 꼴이 되는 겁니다.
D1, 근본부터 스케일아웃을 고려해 만든 칩
그럼 이런 문제를 어떻게 해결해야 할까요?
SK하이닉스 같은 반도체 칩 제조사들이 어서 빨리 더 높은 대역폭의 메모리를 내놓도록 독촉해야 할까요? 아니면, 현재 GPU 시장을 독점하다시피 하고 있는 NVIDIA와 전략적 제휴라도 맺어 연산장치 병렬화 기술에 투자해야 할까요?
언제나 그렇듯, 테슬라의 해결 방식은 직접 필요에 맞게 처음부터 다시 만드는 것입니다.
점점 더 커져가는 모델을 더 빠르게 학습시키기 위해, 테슬라는 태생부터 스케일아웃(Scale out)에 초점을 맞춘 AI 반도체를 직접 설계합니다.
AI 학습용 반도체 칩 하나를 구성하는 가장 작은 연산 단위를 트레이닝 노드(Training Node)라고 하는데요. 테슬라는 이 가장 작은 단위인 노드부터 스케일아웃을 염두에 두고 다시 설계합니다.
노드의 크기가 너무 크면 데이터 전송 속도가 느려지고, 너무 작으면 동기화에 오랜 시간이 걸린다고 하는데요. 테슬라는 대역폭을 극대화하기 위한 최적점을 찾기 위해 단 한번의 클럭 신호로 이동할 수 있는 거리를 측정해, 이 거리만큼의 폭을 가진 노드를 만듭니다. 또 이렇게 설계한 노드는, 노드 간 연결 거리를 최소화해 대역폭을 극대화할 수 있는 그물망 형태의 2D 메쉬 (Mesh) 구조로 배열합니다.

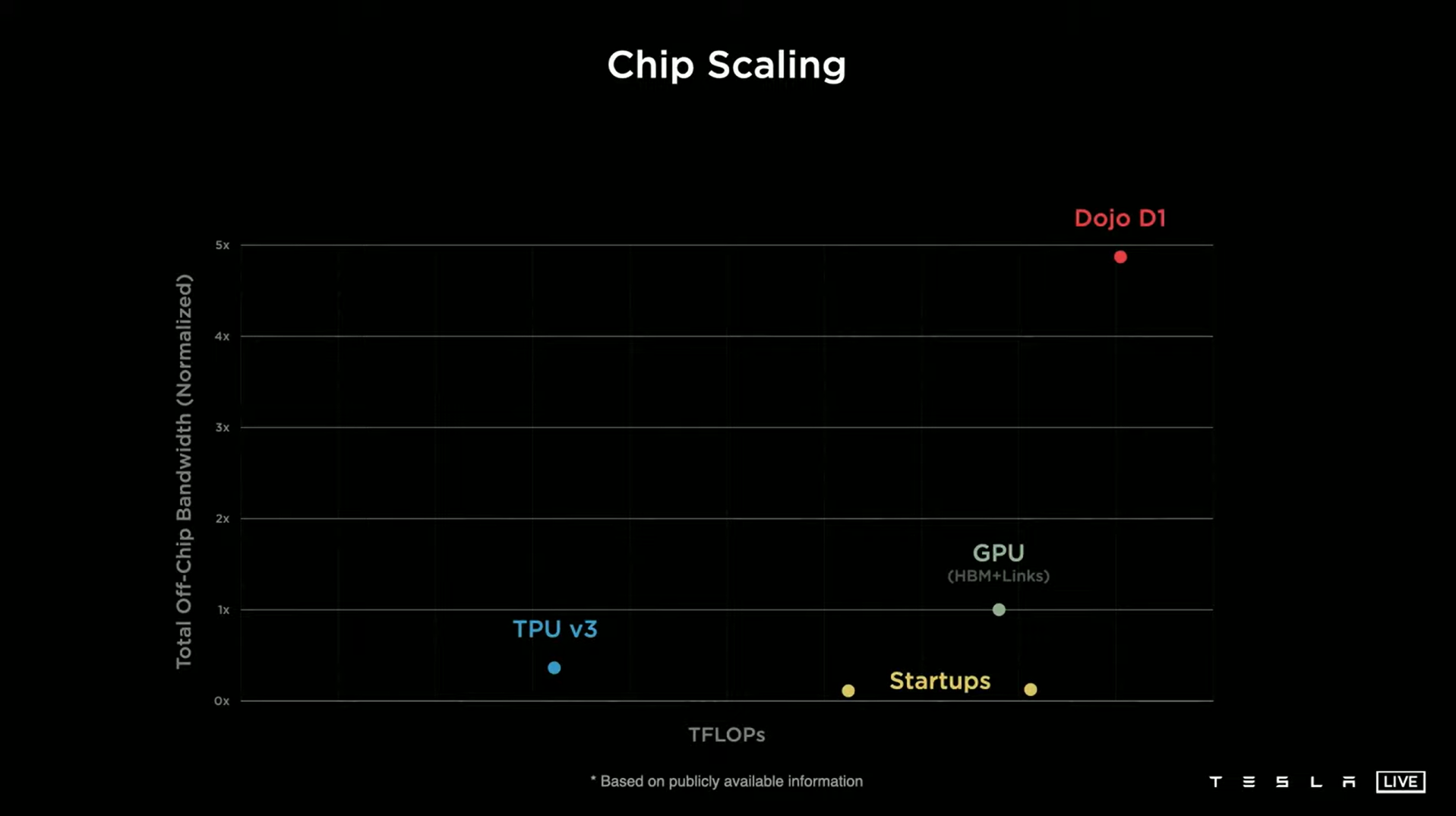
이렇게 만들어진 354개의 노드를 모아 구성한 D1 칩은 상하좌우 어느 방향으로든 동일하게 높은 대역폭을 제공할 수 있다고 하는데요. 시중에 나와있는 NVIDIA나 구글의 연산 장치와 비교하더라도 최소 4배 이상 높은 대역폭을 구현할 수 있다고 합니다.
D1 칩은 25개가 모여 다시 1개의 트레이닝 타일 (Training Tile)이 되는데요. 이 트레이닝 타일 단위에서도 테슬라는 대역폭 손실을 최소화하기 위해 팬아웃 웨이퍼 레벨 패키징 (FOWLP)라는 차세대 패키징 방식을 시도합니다. FOWLP는, 쉽게 설명하면 기존의 PCB 기판을 사용하지 않고 웨이퍼 위에 반도체 칩을 실장해, 대역폭을 높이고 원가를 낮추는 새로운 패키징 방식이라 할 수 있습니다.
이런 트레이닝 타일이 다시 모여 시스템 트레이를, 시스템 트레이가 모여 캐비닛을, 캐비닛이 모여 ExaPOD이라는 테슬라 Dojo 컴퓨터의 최종 구성 단위를 만들어냅니다. 여기서 놀라운 것은 이렇게 만들어진 Dojo의 성능인데요. 현존하는 여타 AI 학습용 슈퍼 컴퓨터 대비 성능은 4배, 전력 사용 효율은 30%나 뛰어나고, 공간은 5배나 덜 차지한다고 합니다.
이렇게 테슬라는 가장 작은 단위인 트레이닝 노드부터 칩, 트레이닝 타일까지 모두 스케일 아웃 하나만 바라보고 다시 만들어 냈습니다. 연산 장치의 개수가 늘어나더라도 손실 없이 높은 대역폭을 유지할 수 있도록 말이죠.
테슬라의 진정한 기술적 해자는 풀 스택 개발 역량에 있다
그렇다면, 이렇게 물을 수 있을 것 같습니다.
“테슬라의 다른 경쟁자들도 테슬라를 따라 스케일 아웃에 적합한 반도체 칩을 설계하면 되는 것 아니냐?” 라고 말입니다. 실제로 포드나 GM 같은 미국 자동차 제조사들도 코로나 기간 차량용 반도체 수급 부족을 계기로 직접 반도체 설계에 관여하기 시작했다고 하니, 아예 불가능한 일은 아닐 것 같기도 합니다.
하지만, 테슬라 D1 칩의 놀라운 퍼포먼스가 단순히 칩을 자체 설계했기 때문이라고만 보기는 어렵습니다.
D1 칩이 NVIDIA A100이나 구글 TPU 등 여타 연산 장치들을 제치고 극대화된 효율을 낼 수 있는 배경에는, 테슬라의 AI 풀 스택 (Full Stack) 개발 역량이 자리하고 있습니다.
여기서 풀 스택 개발 역량이란, AI를 구현하기 위한 백엔드 인프라부터 실제 소비자가 이용하는 AI 서비스까지 모든 레이어를 테슬라가 직접 개발하는 것을 말합니다.
실제로 테슬라는 소비자들이 사용하는 FSD 서비스부터 이를 구현하기 위한 FSD 뉴럴넷, 뉴럴넷을 학습시키기 위한 Dojo 컴퓨터 인프라, 이를 구성하는 D1 칩과 컴파일러까지 모든 영역을 직접 개발, 서비스하고 있습니다.

이렇게 되면, 쉽게 말해 "무엇이 중요한지" 알 수 있다는 게 가장 큰 장점입니다. 상하위 레이어에서 무엇을 필요로 하는지 정확하게 알고 있기에, 이에 맞춰 불필요한 요소는 제거하고 각 레이어의 구성 요소를 최적화할 수 있게 됩니다.
예를 들면, 테슬라의 반도체 설계 엔지니어들은 D1 칩이 구동해야 할 뉴럴넷의 구조와 용량에 대해 상세히 알고 있을 겁니다. 뿐만 아니라 앞으로 뉴럴넷을 어떤 방향으로 개선하고 발전시켜나갈 지 수정사항이나 로드맵에 대해서까지 실시간으로 공유받고 있겠죠. 때문에 반도체 설계에 있어서도 어떤 요소들이 불필요하고, 어떤 방향의 성능 개선이 필요한지 정확히 인지하고 설계에 반영할 수 있을 겁니다.
또 다른 예로, FSD 뉴럴넷의 알고리즘을 짜는 테슬라 소프트웨어 엔지니어들은 실제 FSD 유저들이 전송하는 오류 데이터를 받아 분석하고 반복 테스트할 수 있습니다. 이를 바탕으로 모델에서 어떤 부분의 개선이 필요한지 정확히 파악하고 집중 학습을 통해 오류를 개선할 수 있을 겁니다.
어떻게 보면 너무나 당연한 이야기입니다. 이렇게 서비스, 인프라, 하드웨어, 소프트웨어가 하나의 단일 주체에 의해 개발되면 필요에 맞게 최적화돼 최고의 효율을 낼 수 있다는 것 말이죠.
하지만, 현재 AI 업계에서 이렇게 가장 윗단의 서비스부터 가장 아랫단의 반도체 칩까지 풀 스택을 갖춘 IT 기업은 지구 상에서 테슬라와 구글 단 2개 기업 정도입니다.
앞서 말한 GM이나 포드 같은 제조사들은 이 중 하나라도 제대로 할 수 있는지 의문인 수준입니다. 국내에선 KT가 가장 적극적으로 풀 스택 확보에 노력하고 있는 것으로 보이는데요. 테슬라와 같은 자체 풀 스택 역량 확보가 아닌, 리벨리온, 모레 등 다수 기업들과의 제휴를 통한 방식이라고 합니다.
그만큼 풀 스택 개발 역량을 모두 확보한다는 것은 어려우면서도 모든 엔지니어가 꿈에 그리는 목표인데요. 테슬라는 AI Day 행사 시점을 기준으로 이미 풀 스택 역량을 확보한 것은 물론이고, 세계 각지의 최고 수준의 AI 인재 풀을 흡수하며 그 역량을 더욱 더 강화해왔을 것으로 보입니다.
Dojo는 AI 시대를 앞당길 수 있을까?

23년 7월, D1 칩이 드디어 본격적인 양산에 들어간다고 합니다. 과연 두 차례의 AI Day에서 약속한만큼의 성능을 낼 수 있을지 결과가 궁금해지는데요. 성공한다면, 테슬라가 여타 자동차 제조사나 IT 기업이 감히 모방하기 힘든 강력한 기술적 해자를 구축하고 있음을 공개적으로 입증할 수 있을 겁니다.
또 하나의 주목할 만한 포인트는, 향후 출시될 두번째 버전의 Dojo 컴퓨터인데요. 현재 양산 예정인 첫번째 버전이 영상 학습에 최적화된 컴퓨팅 인프라라면, 두번째는 범용 인공지능, AGI 학습에 쓰일 예정이라고 합니다. AI 데이에서 공개된 테슬라봇의 본격적인 학습에 쓰인다는 말인데요.
과연 테슬라의 자체 설계 반도체가 완전 자율주행은 물론이고 AGI의 보급 속도까지 앞당길 수 있을지 주의 깊게 지켜봐야 할 것 같습니다.
※ 이 글은 전기차 전문 매체 EV POST 에 동시 게재됩니다.

Reference
- Tesla AI Day 2021, 2022
- OpenAI Presents GPT-3, a 175 Billion Parameters Language Model (20/07/07, NVIDIA)
- 2천억개 넘어 100조개까지…초거대 AI, 인간 뇌를 따라잡아라 (21/05/23, 경향신문)
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM (21/08/23, Deepak Narayanan, Mohammad Shoeybi)
- AI and Memory Wall (21/03/30, Amir Gholami)
- 포드·GM도 직접 반도체 생산...미 자동차 공급망 '화룡정점' 찍나? (21/11/19, 아주경제)
의견을 남겨주세요