
안녕하세요 구독자님, 텀타입니다.
여러분들은 요즘 쇼핑하는 방식이 조금씩 달라지고 있다는 걸 느끼시나요? 얼마 전까지만 해도 상상 속 이야기 같던 일이 이제는 현실이 되고 있습니다.
🧒🏻 "내일 부모님 선물로 홍삼 하나 주문해줘. 예산은 5만 원, 내일까지 도착하는 걸로."
이 문장 하나면 AI 에이전트가 여러 쇼핑몰을 탐색하고 조건에 맞는 상품을 골라 주문까지 끝냅니다. 소비자는 결과만 확인하면 되죠.
소비자가 직접 검색하고, 비교하고, 클릭해서 구매하던 여정. 지금까지의 마케팅은 이 과정을 전제로 설계되어 왔습니다. 그런데 구매 여정의 첫 단계에 사람이 아니라 AI가 들어오기 시작하면서 그 전제가 흔들리고 있습니다.
오늘은 AI 에이전트가 무엇을 기준으로 브랜드를 고르는지, 그리고 그 선택을 받기 위해 지금 점검해야 할 데이터가 무엇인지를 짚어보려 합니다. 광고 예산을 늘리지 않고도 지금 당장 손볼 수 있는 영역이라, 끝까지 읽어두시면 분명 도움이 되실 거예요.
📊 체류 32% ↑, 이탈 27% ↓ AI가 데려온 고객은 다릅니다
앞서 언급한 홍삼 주문 장면이 아직은 낯설게 느껴질 수도 있습니다. 하지만 변화의 흐름은 이미 숫자로 나타나고 있습니다.
OpenAI는 2025년 1월 온라인 쇼핑·예약·폼 작성 같은 작업을 수행하는 Operator를 출시했고, 이후 ChatGPT 에이전트로 통합해 제공 범위를 넓혀왔습니다. Google도 2025년 8월 AI Mode를 180개 국가·지역으로 확장하며 에이전틱 기능을 강화했고요.
트래픽도 이를 뒷받침합니다. Adobe와 BCG 데이터에 따르면 2025년 7월 기준 미국 소매 사이트로 유입된 생성형 AI 트래픽은 전년 대비 4,700% 증가했습니다. 더 눈여겨볼 건 유입의 질입니다. AI 경로로 들어온 방문자는 기존 방문자보다 체류 시간이 32% 길고, 이탈률은 27% 낮았습니다. 단순히 방문자가 늘어난 게 아니라, AI를 거쳐 들어온 고객이 훨씬 더 목적 지향적으로 움직인다는 뜻입니다.
물론 아직 모든 소비자가 이렇게 쇼핑하는 건 아닙니다. 실제로 탐색과 비교까지는 AI 에이전트가 매끄럽게 해내지만, 결제와 주문을 끝까지 자동으로 완결하는 단계는 아직 완성형이라기보다는 빠르게 인프라가 깔리고 있는 과정에 가깝습니다. 그럼에도 구매 여정의 첫 단계가 바뀌고 있다는 방향만큼은 지금 숫자로도 분명하게 확인되는 흐름입니다.
🤖 AI 에이전트는 상세 페이지를 읽지 않는다
그렇다면 AI 에이전트는 무엇을 기준으로 브랜드를 고를까요? AI 에이전트가 상품을 고르는 방식은 사람과 꽤 다릅니다.
사람은 상세 페이지 디자인, 브랜드 감성, 카피 문구에 영향을 받습니다. 반면 AI 에이전트는 이런 요소를 거의 참고하지 않아요. 에이전트가 실제로 읽는 건 가격, 재고 상태, 배송 조건, 상품 스펙처럼 명확하게 수치나 값으로 정리된 정보입니다. 아무리 잘 만든 상세 페이지라도 그 정보가 에이전트가 읽을 수 있는 형태로 정리되어 있지 않으면 에이전트 입장에서는 사실상 비어 있는 페이지나 다름없습니다.
이렇게 일정한 형식으로 정리된 상품 정보를 '구조화된 데이터'라고 부릅니다. AI 에이전트는 이걸 1차 판단 기준으로 삼습니다. 구조화된 속성 정보가 부족한 상품일수록 AI 추천 과정에서 노출이 줄어드는 경향이 업계 전반에서 관찰되고 있고요.
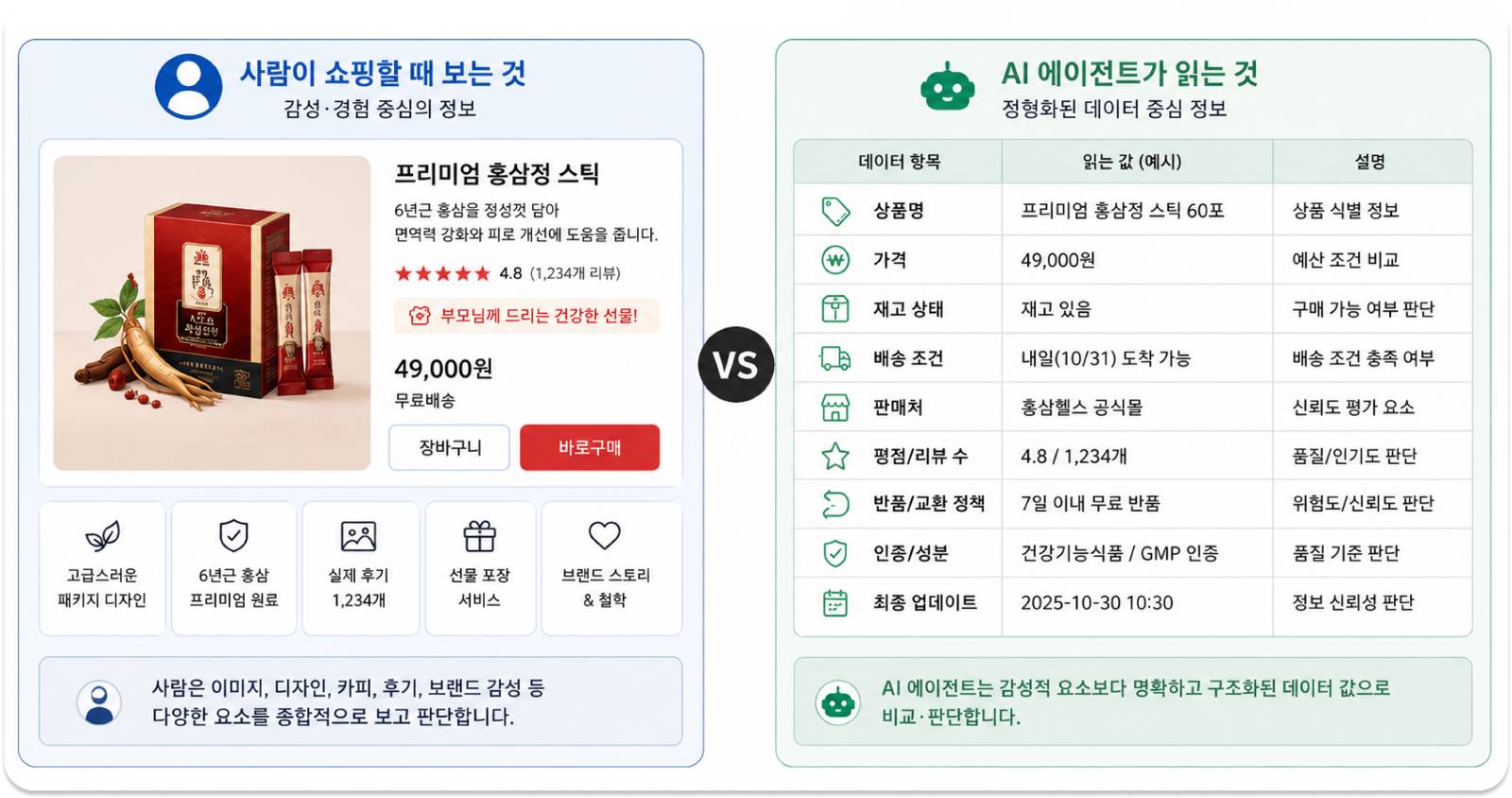
여기에 하나 더, 그 데이터가 채널 간에 일관적인지도 중요합니다. 같은 상품인데 자사몰에는 49,000원, 가격 비교 피드에는 50,000원으로 올라와 있다면 에이전트는 어느 쪽을 믿어야 할까요? 에이전트는 같은 정보가 여러 채널에서 얼마나 일관되게 확인되는지를 신뢰도 판단의 근거로 삼습니다. 채널마다 정보가 어긋나면 그 브랜드의 데이터 전체를 불확실하게 보게 되는 거죠.
결국 AI 에이전트가 브랜드를 선택하는 첫 번째 기준은 '데이터가 얼마나 명확하고 일관되게 정리되어 있는가'입니다. 잘 쓴 카피 한 줄보다 잘 정리된 데이터 한 줄이 먼저 읽히는 구조가 된 셈입니다.
🔍 그럼 우리 데이터는 준비되어 있을까
문제는 정작 브랜드들의 데이터 환경이 이 변화를 따라가지 못하고 있다는 점입니다.
한 글로벌 비즈니스 매체가 2025년 10월 AI 데이터 의사결정 임원 230명을 대상으로 진행한 조사에 따르면, "AI를 위한 데이터가 완전히 준비되어 있다"고 답한 기업은 7%에 불과했습니다. 73%는 자사가 현재 AI 데이터 품질을 충분히 관리하지 못하고 있다고 답했고요. AI 투자는 빠르게 느는데 데이터 기반이 그 속도를 못 따라가고 있다는 게 조사의 핵심이었습니다.
가장 큰 장애물로 꼽힌 건 사일로화된 데이터, 즉 팀이나 시스템 간 데이터 통합의 어려움(56%)이었습니다. 데이터가 없어서가 아니라, 각 팀과 채널에 흩어진 데이터를 하나로 연결하지 못하는 구조가 발목을 잡고 있다는 겁니다.
⚠️ 돈을 써도 노출되지 않는 데이터의 3가지 결함
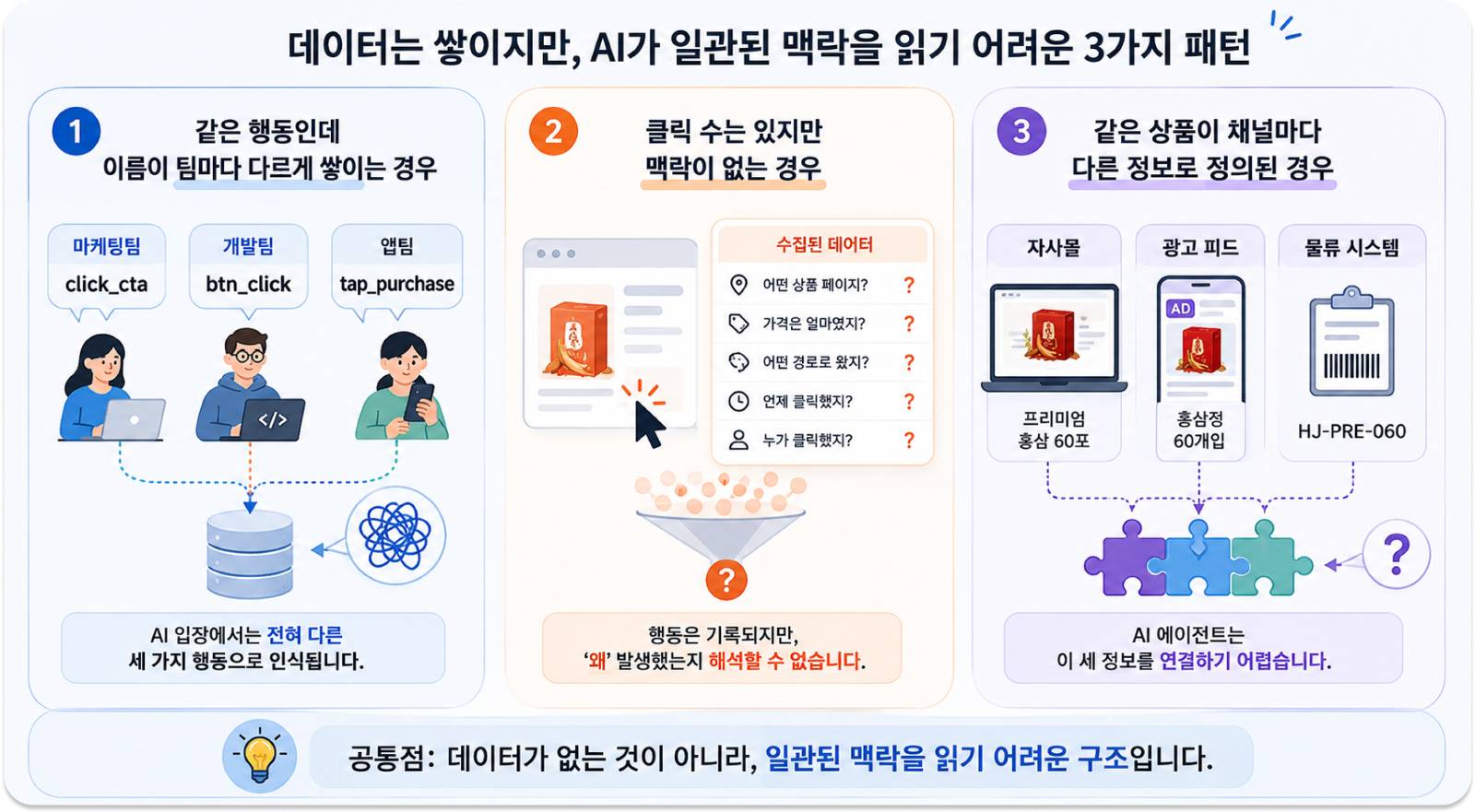
이 문제는 실무에서 보통 세 가지 형태로 나타납니다.
첫째, 같은 행동인데 이름이 팀마다 다르게 쌓이는 경우입니다.
사용자가 앱에서 버튼을 눌렀을 때 마케팅팀은 click_cta로, 개발팀은 btn_click으로, 앱팀은 tap_purchase로 기록하는 상황이 있는데요. 사람 눈엔 다 비슷해 보여도 데이터 입장에서는 전혀 다른 세 가지 행동으로 인식됩니다. 에이전트가 이 데이터를 읽으면 같은 행동의 패턴을 묶어내기 어렵습니다.
둘째, 클릭 수는 있지만 맥락이 없는 경우입니다.
클릭 기록은 있는데 그 클릭이 어떤 상품 페이지에서 발생했는지, 가격이 얼마였는지, 어떤 경로로 들어온 사용자인지 같은 세부 정보가 빠져 있는 경우예요. 클릭 수가 아무리 많아도 "왜 그 행동이 일어났는지"를 읽어낼 수 없으니, 고객 행동 패턴을 신뢰 있게 해석하기 어렵습니다.
셋째, 같은 상품이 채널마다 다른 정보로 정의된 경우입니다.
자사몰에서는 '프리미엄 홍삼 60포', 광고 피드에서는 '홍삼정 60개입', 물류 시스템에서는 'HJ-PRE-060'이라는 코드로만 존재한다면, 에이전트는 이 셋이 같은 상품이라는 걸 연결하기 어렵습니다.
세 패턴의 공통점이 보이시나요? 데이터가 없는 게 아니라, 쌓이긴 하는데 AI가 거기서 일관된 맥락을 읽어내기 어려운 구조라는 점입니다. AI 에이전트는 일관성이 부족한 데이터에 대해 신뢰도를 낮게 평가하는 경향이 있고, 이는 결국 해당 브랜드가 에이전트의 추천 대상에서 멀어지는 결과로 이어질 수 있어요.
🛠️ 그래서 어디서부터 손봐야 할까
해결 방향은 크게 두 가지입니다.
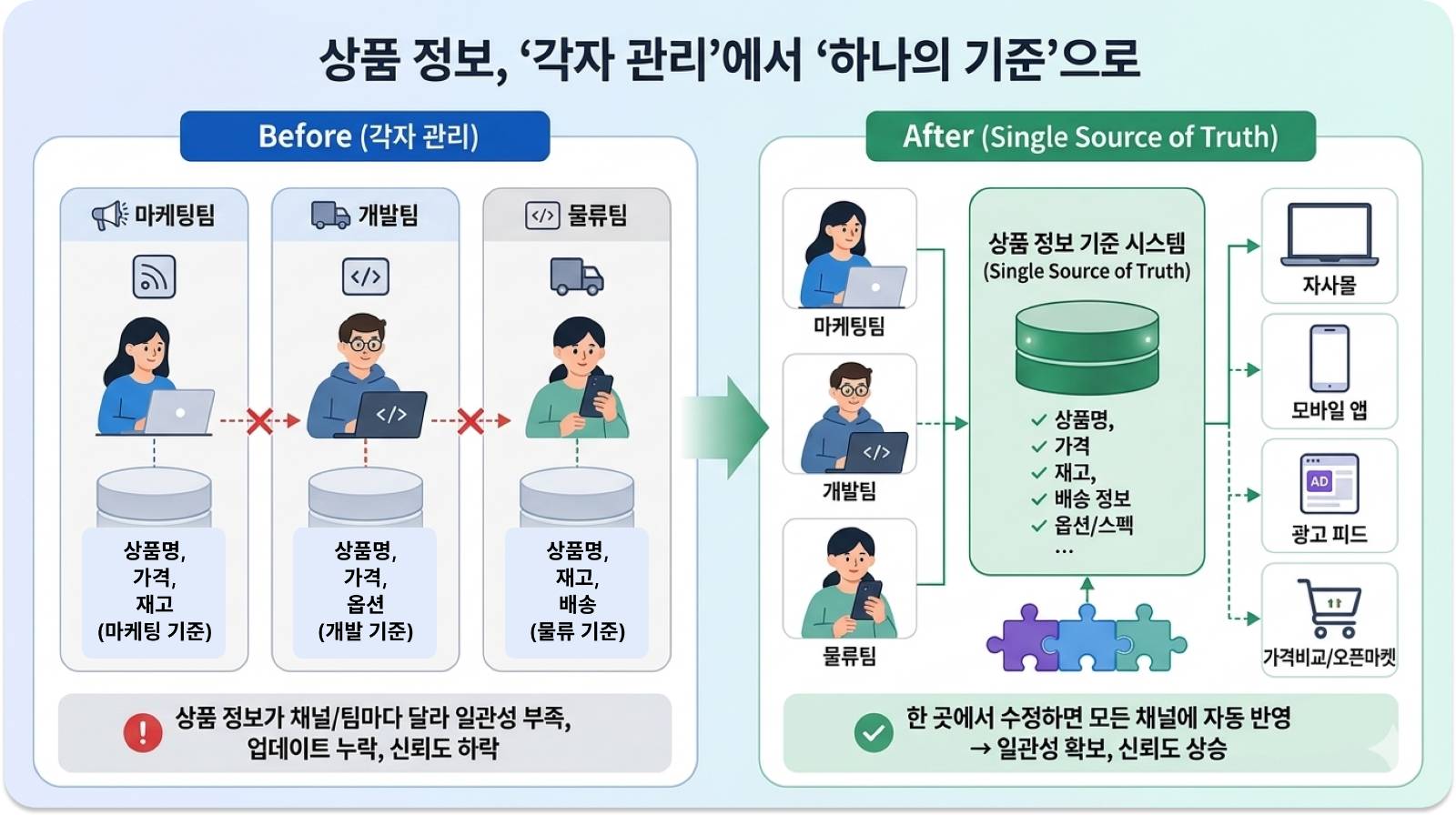
하나는 상품 정보를 하나의 기준으로 통일하는 것입니다.
마케팅팀·물류팀·개발팀이 각자의 시스템에서 같은 상품을 다르게 정의해두는 경우가 생각보다 많습니다. 상품명이 다르거나, 가격이 세금 포함/제외로 갈리거나, 재고 업데이트 시점이 채널마다 다른 식이죠.
이걸 개선하는 개념이 'Single Source of Truth(단일 데이터 기준점)'입니다. 상품 정보는 한 시스템에서만 관리하고, 다른 모든 채널은 거기서 가져가는 원칙이에요. 가격이 바뀌면 마케팅 피드, 자사몰, 물류 시스템이 따로 업데이트되는 게 아니라 한 곳을 고치면 연결된 채널이 함께 반영되는 구조입니다. 에이전트가 여러 채널에서 일관된 정보를 확인할 수 있게 되면, 그 브랜드 데이터의 신뢰도를 더 높게 평가할 가능성이 커집니다.
다른 하나는 행동 데이터에 '왜'라는 맥락을 붙이는 것입니다.
사용자가 상품을 클릭했다는 기록만 있는 경우와, 그 클릭에 {price: 49000, source: "email_campaign", discount_applied: true} 같은 정보가 함께 붙어 있는 경우를 비교해 볼게요. 전자는 "누군가 클릭했다"는 사실만 남지만, 후자는 "이메일 캠페인으로 들어온 사용자가 할인이 적용된 49,000원짜리 상품을 클릭했다"는 맥락까지 읽힙니다. AI는 맥락이 있는 구조에서 "어떤 조건에서 어떤 행동이 발생하는지" 패턴을 훨씬 선명하게 파악합니다.
한 데이터 분석 전문 기업은 "트래킹 구현에 누락이 있으면 AI가 그 누락을 수정하는 게 아니라 증폭시킨다"고 짚었는데요. 맥락이 빠진 데이터는 불완전한 데 그치지 않고, AI를 거치며 오히려 더 잘못된 방향으로 해석될 수 있다는 뜻이기도 해요. 반대로 이야기하면, 맥락이 잘 담긴 이벤트 데이터는 AI가 패턴을 더 정확하게 읽는 데 직접적으로 도움이 된다는 뜻이겠죠.
두 작업의 공통점은, 외부 채널을 늘리거나 광고 예산을 더 태우는 게 아니라 지금 갖고 있는 데이터 파이프라인과 이벤트 구조를 점검하는 데서 출발한다는 점입니다.
💬 마치며: AI를 설득하는 마케팅은 데이터에서 시작됩니다
처음의 장면으로 돌아가볼게요.
"부모님 선물로 홍삼 하나, 예산 5만 원"이라는 요청을 받은 AI 에이전트는 과연 어느 브랜드를 골랐을까요?
정답은 알 수 없습니다. 다만 한 가지는 분명합니다. 에이전트가 가장 먼저 읽은 건 어느 브랜드의 카피가 더 설득력 있었는지가 아니라, '어느 브랜드의 데이터가 더 명확하고 일관되게 정리되어 있었는지'였을 겁니다.
지금까지는 더 좋은 콘텐츠, 더 많은 노출, 더 높은 클릭률이 경쟁력의 기준이었습니다. 하지만 AI 에이전트가 구매 여정에 들어오는 환경에서는 그보다 앞 단계인 데이터 구조가 브랜드 경쟁력을 먼저 가릅니다.
거창한 시스템 개편이 아니어도 괜찮습니다. 우리 상품 정보가 팀·채널마다 같은 기준으로 관리되고 있는지, 이벤트 데이터에 '왜'라는 맥락이 충분히 담겨 있는지 한번 들여다보는 것. 광고 예산을 건드리지 않고도 오늘 당장 시작할 수 있는 점검입니다. AI에게 선택받는 브랜드의 출발점은 의외로 거기에 있을지도 모릅니다.
👉🏻 AI에게 선택받는 브랜드 데이터 전략이 더 궁금하다면?: [AI 에이전트는 상세 페이지를 읽지 않는다: 에이전틱 커머스 시대의 브랜드 데이터 전략]
👩💻 무료 강의로 부담 없이 시작해 보세요!
처음부터 유료 강의를 듣기 망설여진다면, 텀타 아카데미의 무료 강의로 가볍게 시작해 보세요. 실무에 필요한 SQL 문법만 쏙쏙 골라 담았습니다.
📚 GA4, GTM에 대해 더 깊이 배우고 싶다면?
GTM과 GA4를 활용한 실전 분석법을 더 자세히 알고 싶다면 14년차 데이터 분석 전문가 헨리님의 그로스핏 아카데미의 강의도 추천해 드립니다.
📚 보다 자세하게 SQL로 고객 행동을 분석하고 싶다면?
비즈니스 성장에 필요한 데이터 전문 아카데미! GA4, GTM, 데이터 시각화부터 SQL까지 현업에 바로 적용하는 실습형 강의를 제공합니다. 데이터 기반 의사결정을 위한 역량을 갖춰 보세요.

의견을 남겨주세요