

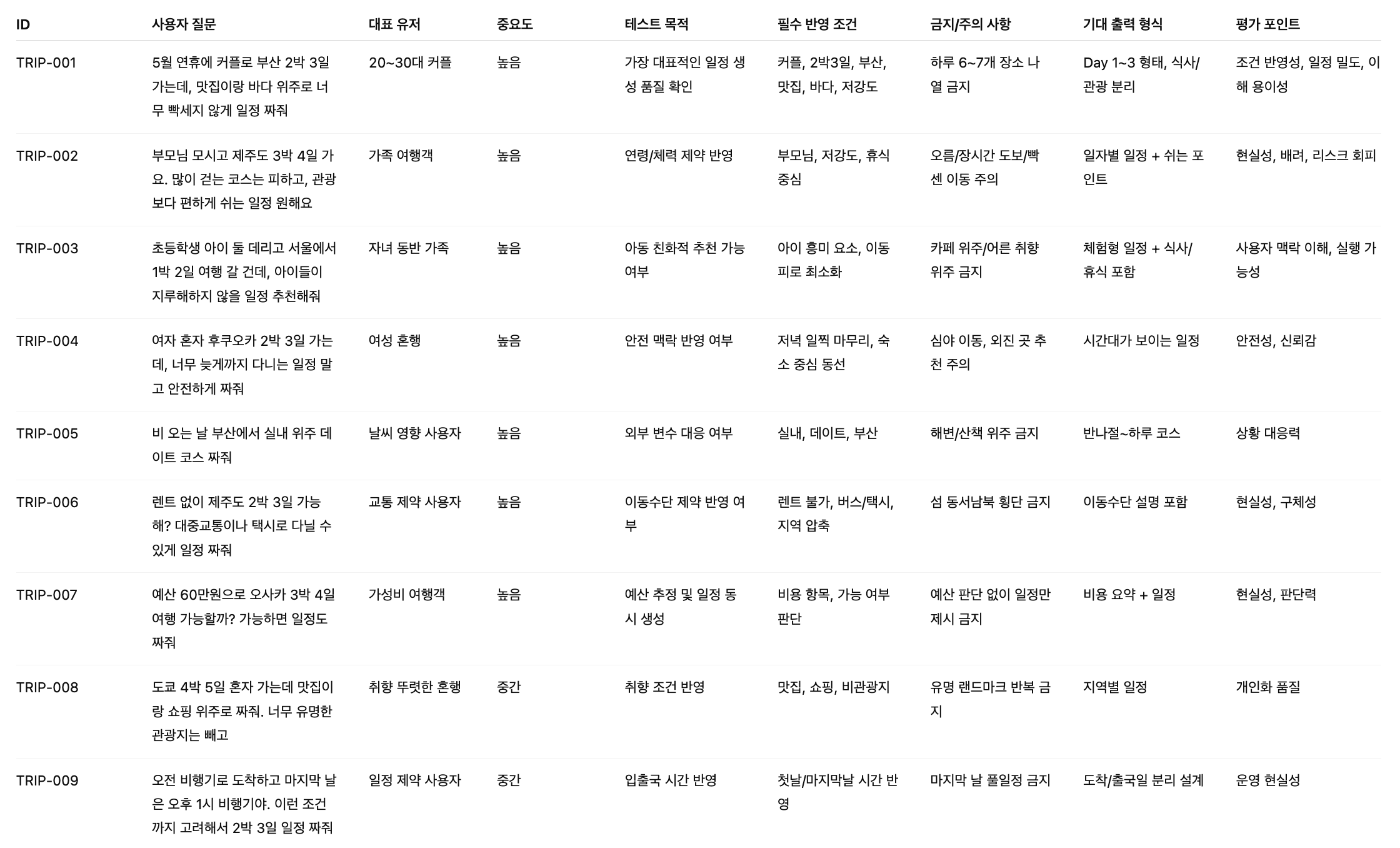
AI 서비스를 처음 맡았을 때, 저는 꽤 당황스러운 경험을 했습니다.
“이걸… 내가 해야 한다고요?”
그동안 PM으로 일하면서 품질과 관련된 일은 어느 정도 익숙한 영역이라고 생각했거든요. 요구사항을 잘 정의하고, QA에서 테스트를 돌리고, 문제가 있으면 수정하면 되는 일이라고요.
그런데 AI 서비스를 맡고 나서부터, 이전에는 한 번도 해보지 않았던 종류의 일이 계속 제 앞으로 떨어지기 시작했습니다.
1. 저는 그 날 8시간 동안 점수만 매겼습니다.
생성형 AI를 이용해 여행 계획을 자동으로 짜주는 AI 서비스를 만들던 시기였습니다. 개발자분이 제 자리로 오시더니 노트북을 보여주셨어요. 엑셀 시트 하나가 열려 있었는데, 스크롤을 내려도 내려도 끝이 안 보이더라고요. 수천 개는 되어 보이는 로우 데이터였습니다.
“사샤, 모델이 뱉은 결과물들인데… 이거 하나하나 점수 좀 매겨주실 수 있을까요?”
순간 멈칫했습니다. 머릿속에 바로 이런 생각이 스쳤어요.
‘아니, 스펙 구체적으로 다 줬는데… 이걸 왜 내가 일일이 보고 있어야 하지? QA팀에서 테스트 케이스 돌리면 되는 거 아닌가?’
솔직히 말하면, 당황했습니다. 이미 기준은 다 정의해놨다고 생각했거든요. 그리고 이런 작업은 제 일이 아니라는 생각도 들었습니다. 그런데 그냥 넘기기도 애매해서, 일단 몇 개만 보자는 마음으로 스크롤을 내리기 시작했습니다. 그리고… 몇 줄 보지도 않았는데 바로 멈췄습니다.
어떤 결과물의 제목은 그냥 “여행”이었습니다. 너무 포괄적이고, 아무 정보도 담겨 있지 않았죠. 또 다른 결과에서는 추천 이유가 “유명”라고 적혀 있었습니다. 심지어 어떤 타임라인은 아침 9시에 남산, 10시에 강남, 11시에 홍대를 찍고 있더라고요. 물리적으로 불가능한 일정이었는데도 아무렇지 않게 그럴듯한 문장으로 포장되어 있었습니다. 그 순간 약간 소름이 돋았습니다.
‘아… 이건 QA로 못 잡겠는데?’
결국 저는 자리에 앉아서 엑셀 시트를 정렬하기 시작했습니다.
제목, 추천 이유, 타임라인 각각에 대해 점수를 매기기 시작했어요. 이건 5점.
이건 2점.
이건 1점. 처음엔 빠르게 끝낼 수 있을 줄 알았는데, 하면 할수록 기준이 흔들리기 시작했습니다.
‘이건 나쁘진 않은데… 3점인가 4점인가? 이건 창의적인데 정확하지는 않네… 그럼 몇 점이지?’
시간이 갈수록 점점 더 느려졌고, 어느 순간부터는 제가 채점을 하고 있는 건지, 기준을 다시 만들고 있는 건지 헷갈리기 시작했습니다.
정신을 차려보니 8시간이 지나 있었습니다. 하루를 거의 다 써버린 셈이었죠.
다른 서비스를 만들 땐 해본 적 없는 업무였습니다. 블로그 서비스를 만들 때에는 글이 잘 올라오는지, 글자 수 제한이 제대로 걸리는지만 확인하면 됐습니다. 한 번도 “이 태그는 5점짜리야” 같은 평가를 기획자가 직접 해본 적은 없었습니다. 앨범 서비스를 만들 때도 마찬가지였어요. 업로드가 되느냐, 깨지지 않느냐, 로딩이 되느냐 같은 것들이 전부였습니다. 한 번도 “이 사진은 1점짜리야” 같은 평가를 해본 적은 없었습니다.
그런데 생성형 AI를 활용한 서비스를 만드는 지금은 완전히 다른 일을 하고 있었습니다.
기능이 “동작하느냐”가 아니라, 결과가 “좋으냐”를 보고 있었으니까요.
그날 처음으로 깨달았습니다.
“아… AI 서비스에서 품질은 테스트가 아니라, 정의의 문제구나.”
2. QA가 품질을 책임질 수 없는 서비스
기존 서비스에서는 품질의 기준이 꽤 명확합니다. 버튼을 누르면 다음 화면으로 넘어가야 하고, 결제가 되면 성공 메시지가 떠야 하고, 오류가 나면 정해진 에러코드가 내려와야 하죠. 다시 말해, 대부분의 상황이 맞다 또는 틀리다로 구분되는 문제였습니다.
그래서 QA가 테스트 케이스를 만들고, 체크리스트 기반으로 검증할 수 있었습니다. PM의 역할도 비교적 분명했습니다. 요구사항대로 잘 만들어졌는지, 빠진 건 없는지를 확인하는 것. 즉 기능의 완성도를 보는 일이었죠.
그런데 생성형 AI 서비스는 이 구조가 그대로 적용되지 않습니다.
같은 질문을 넣어도 매번 다른 답이 나오고, 그 답을 정답이라고 부르기도 애매합니다. 대신 이런 식의 고민이 생깁니다. "이 답변은 자연스러운가? 도움이 되는가? 너무 장황하지는 않은가? 창의적인데, 신뢰할 수 있는가?" 문제의 성격 자체가 완전히 달라진 겁니다. 정답을 맞추는 문제가 아니라, 얼마나 좋은 결과인가를 판단하는 문제가 되어버린 거죠.
이 순간 QA의 역할은 한계에 부딪힙니다. 체크리스트로 검증할 수 없고, Pass 또는 Fail로 나눌 수도 없고, 사람마다 평가가 달라지기 시작하니까요.
그래서 이 공백을 누군가는 채워야 합니다.
그리고 그 역할이 자연스럽게 PM에게 넘어옵니다.
3. "PM은 이제 평가를 설계하는 사람이 됩니다"
이 시기에 흥미로운 인터뷰를 하나 보게 됐습니다. OpenAI의 제품 무결성 책임자(Head of Product Integrity)로 일하고 있는 AI PM 제이크(Jake)의 팟캐스트 인터뷰였습니다.
OpenAI의 PM은 이렇게 말합니다.
“PM들은 제품이 어떻게 작동해야 하는지에 대한 그 누구보다 가장 명확한 비전을 가지고 있기 때문에, 점점 더 평가(evaluation)를 작성하는 역할을 맡게 됩니다.”
제가 엑셀에 앉아서 8시간 동안 했던 그 작업이, 비효율적인 단순 업무였던 것이 아니라 오히려 AI PM의 본질적인 역할이었다는 걸 뒤늦게 이해했던 부분이었습니다.
이 인터뷰에서 제이크는 PM의 변화를 이렇게 정리합니다.
“기존에 PM들은 명세서를 쓰는 사람이었다면, 이제는 평가를 설계하는 사람이 되고 있습니다."
그는 또 이제 제품을 평가하는 방식도 달라지고 있다고 얘기했습니다. 예전에는 클릭 수나 전환율 같은 사용 지표를 중심으로 봤다면, 이제는 “이 기능이 실제로 얼마나 좋은 결과를 만들어내는가”를 직접 측정해야 한다는 것이죠. 결국 같은 이야기였습니다.
AI 서비스에서 품질은 더 이상 ‘테스트해서 잡는 것’이 아니라, ‘처음부터 정의해야 하는 것’이라는 이야기요.
4. 그래서 AI 품질 평가는 어떻게 돌아갈까?
이쯤 되면 이런 질문이 생깁니다. “그래서 실제로는 뭘 어떻게 해야 하는데?”
보통은 이런 흐름으로 돌아갑니다.
먼저, 우리가 중요하게 보고 싶은 대표 쿼리와 데이터셋을 만듭니다. 실제 유저가 많이 할 쿼리, 실패하면 치명적인 케이스, 다양한 난이도를 포함해서요. 이 단계에서 이미 방향이 정해집니다. “우리는 무엇을 잘해야 하는 서비스인가?”를 정의하는 단계이기 때문입니다.
그 다음으로는 평가 기준을 세웁니다.
정확성, 유용성, 자연스러움, 간결성 같은 것들이 보통 등장합니다. 여기서 중요한 건 항목 자체보다 우선순위입니다. 모든 걸 다 잘할 수는 없기 때문에, 우리는 어떤 품질을 더 중요하게 볼지 선택해야 합니다.
그 다음에는 실제로 모델로 결과를 만들어내 봅니다. 그리고 그 결과를 사람이 직접 보거나, 때로는 다른 LLM을 활용해서 점수를 매깁니다. 일부는 수작업으로, 일부는 자동화로 평가가 돌아갑니다.
평가가 됐다면 마지막으로, 어디서 점수가 떨어지는지 분석합니다. 그리고 그 부분을 개선합니다. 프롬프트를 바꾸기도 하고, 로직을 수정하기도 하고, 경우에 따라서는 아예 기준 자체를 다시 정의하기도 합니다.
이 과정을 계속 반복합니다.
5. 일반 서비스 vs AI 서비스, 무엇이 달라졌을까?
이 변화를 한 번에 정리해보면 이렇습니다.
일반 서비스에서는 정답이 존재합니다. 그래서 품질은 Pass 또는 Fail로 나뉘고, QA가 테스트를 통해 검증할 수 있습니다. PM은 요구사항이 잘 구현되었는지를 확인하는 역할을 합니다.
반면 AI 서비스에서는 정답이 없습니다. 대신 결과의 “좋고 나쁨”을 평가해야 합니다. 품질은 스펙트럼 위에 존재하고, 그 기준을 정의하는 사람이 필요합니다.
그래서 PM의 역할도 달라집니다.
기능이 잘 동작하는지를 보는 사람이 아니라,
무엇이 좋은 결과인지 정의하고, 그것을 측정하는 구조를 설계하는 사람이 됩니다.
| 구분 | 💻 일반 서비스 | 🤖 AI 서비스 |
| 품질 기준 | 명확함 (기획서 = 정답) | 애매함 (스펙트럼만 있음, 정답 대신 '모범 답안' 존재) |
| 품질 관리의 초점 | 품질 보증 | 평가 설계 |
| 품질 책임 | QA | PM |
| 핵심 지표 | 기능의 완결성 | 평가 기준 부합 정도 |
| 검증 기준 | 결과값의 일치 여부 판단 (='O/X 퀴즈' 채점 방식) | 결과값의 최적화 여부 판단 (='논술 시험' 채점 방식) |
| 검증 방식 | 정해진 시나리오 기반 Pass/Fail 테스트 | 인간의 정성 평가(Human Eval) → LLM 기반 자동화 평가(LLM judge) |
6. "저 품질관리 해본 적 없는데요…"라는 분들께
글을 읽으면서 이런 생각 드셨을 수도 있을 것 같아요.
“저는 QA도 아니고, 품질관리 해본 적 없는데요…”
저도 그랬습니다. 하지만 AI 품질 평가는 기존 QA와는 완전히 다른 영역이라, 대부분 처음부터 배우게 됩니다. 그리고 사실 이건 ‘품질관리 경험’의 문제가 아니라,
‘기준을 만들어본 적 있느냐’의 문제에 가깝습니다. 이렇게 시작해보시면 좋습니다.
Step 1. 직접 점수 매겨보기
실제 서비스 결과를 20~30개 정도 뽑아서,
아무 기준 없이 그냥 직접 점수를 매겨보는 겁니다. 처음엔 이렇게 시작하시면 됩니다.
이건 좋은 것 같다 → 5점
이건 좀 애매하다 → 3점
이건 별로다 → 1점
이렇게요. 그런데 몇 개만 해보면 금방 막히는 지점이 옵니다.
‘이건 3점인가 4점인가…?’
‘왜 이건 좋다고 느껴지는 거지?’
이때 드는 그 답답함이 굉장히 중요합니다. 바로 그 순간, 깨닫게 됩니다.
“아, 기준이 없으면 평가 자체가 안 되는구나.” 이 단계는 점수를 정확하게 매기는 게 목적이 아니라,
내가 어떤 기준으로 판단하고 있는지 스스로 인식하는 단계입니다.
Step 2. 기준 정의해보기
이제 그 “막연한 느낌”을 말로 꺼내보는 단계입니다. 예를 들어 이런 식입니다.
“좋은 여행 계획은 구체적이어야 한다. 일정을 실제로 따라 할 수 있을 정도면 구체적이다.”
“좋은 여행 계획은 현실적이어야 한다. 이동 시간, 예산, 체력을 고려해 실행 가능한 내용이어야 한다."
"불필요하게 길고 장황하면 감점한다."
처음부터 완벽한 기준을 세울 수는 없을거예요. 대부분은 “뭔가 좋은데… 왜 좋은지 모르겠어. 확실한 건 이건 별로인데… 설명이 안 되네”로 시작합니다.
괜찮습니다. 그걸 억지로라도 문장으로 만들어보는 게 핵심입니다. 이 과정을 거치면서,
머릿속에만 있던 기준이 점점 밖으로 드러나기 시작합니다. 이 단계의 목표는
“감으로 판단하던 걸, 우리 프로젝트 멤버들이 납득할만한 설명 가능한 기준으로 바꾸는 것”입니다.
Step 3. 품질 기준이 되는 질문 세트 만들기
기준을 어느 정도 세웠다면, 그 다음에는 그 기준을 계속 적용해볼 수 있는 문제지를 만들어야 합니다. 그 기준을 반복적으로 검증할 수 있는 “판”을 만들어야 하는데 이게 바로 데이터셋입니다. 데이터셋은 쉽게 말하면 “우리 서비스가 잘해야 하는 질문들을 모아놓은 리스트”입니다.
데이터셋은 보통 실제 유저가 많이 할 법한 쿼리, 실패하면 치명적인 케이스 몇 개와 그에 대한 모범답안을 포함합니다. 그리고 이 질문들에 대해 결과를 뽑고, 같은 기준으로 계속 평가해보는 과정을 거칩니다.
이 데이터셋의 역할은 딱 하나입니다. 우리 서비스 품질을 측정하는 기준점입니다. 이게 없으면 매번 다른 질문, 다른 상황을 보게 되니까
좋아졌는지 나빠졌는지 판단이 안 되니까요.
기준 = “무엇이 좋은가”
데이터셋 = “그 기준을 적용해볼 문제들”
이 둘이 같이 있어야
비로소 품질을 계속 개선할 수 있는 상태가 됩니다.
Step 4. LLM을 평가자로 써보기
이제 조금 익숙해졌다면, 그 다음은 자연스럽게 자동화를 고민하게 됩니다. 사람이 계속 점수를 매기는 건 한계가 있으니까요. 이때 LLM을 평가자(LLM Judge)로 활용해볼 수 있습니다. 예를 들어 이렇게 시킬 수 있습니다.
“이 답변을 1~5점으로 평가해줘, 특히 ‘구체성’과 ‘현실성’을 기준으로 판단해줘”
여기서 중요한 포인트는 앞서 정했던 기준을 반드시 같이 넣어줘야 한다는 것입니다. 기준 없이 점수만 매기라고 하면
LLM도 그냥 “그럴듯하게” 평가해버립니다.
이렇게 하면, 대량 평가 가능해지고 반복 작업이 줄어들고 빠르게 개선 사이클을 돌릴 수 있게 됩니다. 이 단계부터가 본격적인 평가 자동화의 시작입니다.
Step 5. 지표를 믿지 말고 의심하기
여기까지 오면 보통 이런 착각을 하게 됩니다. “이제 점수도 나오고, 계속 올라가니까 잘 되고 있는 거겠지?” 그런데 여기서 한 번 더 넘어야 할 단계가 있습니다. 지표를 의심하는 단계입니다.
AI 서비스에서는 실제로 이런 일이 자주 벌어집니다. 평가 점수는 계속 올라가는데 유저 만족도는 오히려 떨어지는 상황이요. 왜 이런 일이 생길까요?
대부분은 우리가 잘못된 기준을 열심히 최적화하고 있었던 데에서 발생합니다. 예를 들어, “정확성”만 너무 강조해서 결과가 딱딱해진다거나, “창의성”을 높이려다 쓸데없이 장황해진다거나 하는 상황이죠. 지표는 좋아졌지만,
사용자 입장에서는 더 별로가 된 거죠.
그래서 이 단계에서는 반드시 “이 지표가 진짜 유저 경험을 설명하고 있는가?”라는 질문을 계속 던져야 합니다.
만약 아니라면,
모델을 개선하기 전에 기준부터 다시 봐야 합니다.
7. 지금 이 역할을 잡는 AI PM이 앞서갑니다.
품질이라는 새로운 짐을 떠안게 된 건 사실입니다.
예전에는 QA가 나눠 들고 있던 무게를 이제 PM이 직접 체감하게 된 셈이니까요. 그래서 처음에는 꽤 부담스럽게 느껴집니다.
내가 이걸 다 판단해야 한다는 것도, 기준을 스스로 만들어야 한다는 것도요.
그런데 신기하게도 이 과정을 몇 번 겪다 보면 조금 다른 감각이 생깁니다. 단순히 품질을 관리하는 걸 넘어서,
이 서비스가 어떤 방향으로 가야 하는지에 대한 감각이 훨씬 또렷해집니다. 어떤 결과가 좋은지 고민하다 보면 결국 “이 서비스는 무엇을 잘해야 하는가”라는 질문까지 닿게 되거든요. 그래서 저는 요즘 품질을 본다는 건 결국 제품의 방향을 가장 가까이에서 다루는 일이라는 것을 느낍니다.
저는 글로벌 회사에서 먼저 이 역할을 경험했기 때문에,
이 변화가 비교적 빠르게 체감됐던 것 같습니다. 반대로 아직 많은 국내 서비스에서는
이 역할이 PM의 핵심 영역으로 완전히 올라오지는 않은 느낌도 있습니다. 그래서 오히려 지금이 기회라고 생각합니다.
품질의 중요성을 먼저 이해하고, 기준을 스스로 정의할 수 있고, 이 과정을 반복해본 경험이 있다면 AI PM으로서 꽤 큰 격차를 만들 수 있는 시기입니다. 기능을 잘 만드는 PM은 많지만,
좋은 결과를 정의할 수 있는 PM은 아직 많지 않으니까요.
📮 다음 호 예고
[10호] AI와 함께 일하는 환경에서 내 옆의 동료에게 말 거는 법
업무의 절반 이상을 AI와 함께하는 요즘, AI와 함께 사고하는 방식은 우리의 커뮤니케이션을 어떻게 바꾸고 있을까요?
✉️ 다음 호가 궁금하신 분들은 아래 [구독하기] 버튼을 눌러주세요.
의견을 남겨주세요