

Created by 주간SaaS with DALLE
주간SaaS 이번주 소개 글
안녕하세요. SaaS 기업 뿐 아니라 많은 기업들이 앞다투어 LLM을 통해 새로운 비즈니스 가치를 개발하기 위해 노력 중입니다. 그러면서 자연 스럽게 효율적이고 안정적인 "LLM 환경"을 유지하고 개선하는 것이 중요해졌으며 그 결과 LLMOps 라는 개념에 관심을 갖기 시작합니다. 오늘은 LLMOps 의 개념과 각 단계를 구성하는 요소를 핵심만 정리한 글을 소개 합니다.
(*"LLMOps 구성 단계 부분"에는 원문에 덧붙여 추가적인 개념 설명을 추가했습니다)
DevOps
- DevOps(Developer Operations)는 소프트웨어 개발자와 다른 IT 전문가 간의 협업과 소통을 강조하면서 소프트웨어 제공 및 인프라 변경 프로세스를 자동화하는 문화적, 전문적 트렌드입니다[1].
- DevOps는 조직이 빈번한 반복 주기를 통해 소프트웨어 및 IT 서비스를 더 빠르게 생산할 수 있도록 지원하는 것을 목표로 합니다[7][10].
- DevOps는 워크플로우를 자동화하고 애플리케이션 성능을 지속적으로 측정하여 협업과 생산성을 향상시키기 위해 개발자와 운영팀을 통합합니다.
- 이는 전통적으로 사일로화된 팀, 개발 및 운영 간의 장벽을 제거하는 것입니다[4].
MLOps
LLMOps
- LLMOps(Large Language Model Operations)는 MLOps의 특수한 하위 집합으로, GPT-4 또는 Claude와 같은 대규모 언어 모델(LLM)을 배포하고 유지 관리하는데 필요한 특별한 임무에 중점을 둡니다[3].
- LLMOps는 MLOps(Machine Learning Operations)의 하위 집합으로 간주될 수 있지만, 기존 ML 모델과 LLM을 사용하여 AI 제품을 구축하는 방식의 차이로 인해, 두 가지 중요한 차이점이 있습니다.
- LLMOps에서는 이미 사전 학습된 모델이 사용됩니다. 그러나 MLOps에서는 컴퓨터 비전을 제외한 모든 모델이 처음부터 학습됩니다.
- LLMOps에서는 안정적인 기반 모델(기본 LLM)을 선택하는 것이 중요합니다.
- 다음은 작업을 기반으로 한 두 가지의 자세한 차이점입니다[4].
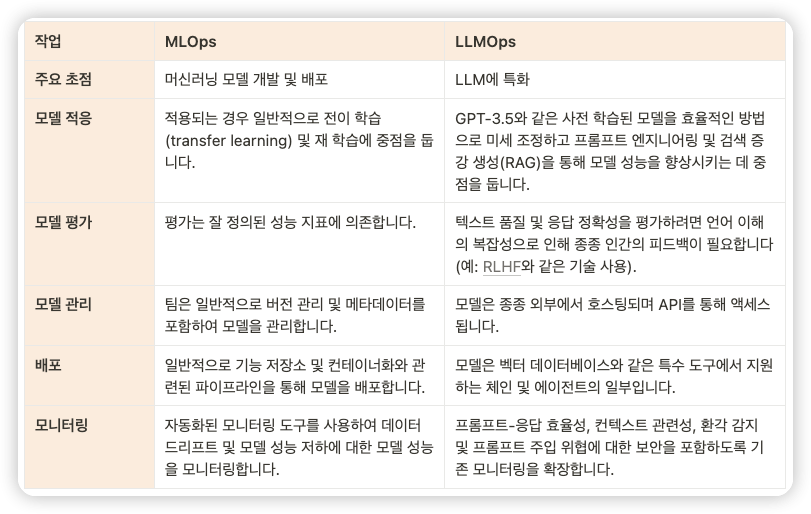
출처: https://blog.soumendrak.com/llmops-introduction
LLMOps의 과제
- LLMOps는 많은 이점을 제공하지만 구현 과정에서 몇 가지 어려움에 직면할 수 있습니다. 이 어려움에는, 데이터 개인 정보 보호 및 보안 문제, 컨텍스트 제한, 인프라 최적화 및 LLM 평가 등이 있습니다.
- LLM이 빠르게 진화함에 따라, 많은 기업들은 버전 관리, 비회귀 테스트, 개념 및 데이터 드리프트 처리에 어려움을 겪고 있습니다. 또한 LLMOps에 필요한 컴퓨팅 리소스는 상당할 수 있으므로 비용 계획 및 최적화가 프로세스의 중요한 측면이 됩니다.
- LLM을 애플리케이션에 통합하는 구조화된 관리 접근 방식이 없으면 미래 비용을 추정하는 것이 복잡해지거나 불 확실해 질겁니다.
LLMOps 구성 단계
1. 모델 선택 단계
- 먼저 LLM을 선택합니다.
- 상용 모델: GPT-3, Claude 등
- 오픈소스 모델: LLaMA2, Falcon, Mistral 등
- 자체 미세 조정 모델: 위 두 가지 유형의 모델을 기반으로 특정 도메인/작업에 맞게 미세 조정
2. 모델 적응(Adpation) 단계(선택한 LLM을 특정 작업 및 데이터셋에 맞게 조정)
- 미세 조정(Fine-tuning): 특정 도메인/주제에 대한 전문성을 갖도록 LLM을 추가로 학습시킵니다.
- 프롬프트 엔지니어링(Prompt Engineering): LLM에서 원하는 출력을 얻기 위해 입력 프롬프트를 설계하고 최적화합니다.
- 재학습(Re-Training): 새로운 데이터를 사용하여 모델을 다시 학습시켜 성능을 향상시키거나 새로운 정보를 반영합니다.
- 인간 피드백 강화 학습(RLHF), 인공지능 피드백 강화 학습(RLAIF), 직접 선호도 최적화(DPO): 인간 피드백이나 AI 평가를 활용하여 모델을 더욱 개선합니다.
- 검색 증강 생성(RAG): 외부 지식 베이스를 활용하여 LLM의 생성 능력을 향상시킵니다.
3. 모델 평가 단계: 객관적인 지표와 인간 평가를 통해 모델 성능을 엄격하게 평가합니다.
4. 모델 배포 단계
- 모델 경량화: 증류(Distillation), 가지치기(Pruning), 양자화(Quantization) 등의 기술을 사용하여 모델 크기를 줄이고 추론 속도를 높입니다.
- 모델 양자화: 모델의 가중치를 더 낮은 비트로 변환하여 메모리 사용량을 줄이고 추론 속도를 향상시킵니다.
- Bitsandbytes: 미세 조정 단계에서 모델 크기를 줄이고 학습 속도를 높이는 데 사용됩니다.
- GPTQ:: 생성 단계에서 모델 크기를 줄이고 추론 속도를 높이는 데 사용됩니다.
- 더 나은 병합 모델을 얻는 과정
- bitsandbytes를 사용하여 기본 모델 양자화: 먼저 bitsandbytes 라이브러리를 사용하여 기본 모델을 양자화합니다. 양자화는 모델의 가중치를 더 낮은 비트로 변환하여 모델 크기를 줄이고 추론 속도를 높이는 기술입니다.
- 어댑터 추가 및 미세 조정: 양자화된 기본 모델에 어댑터 레이어를 추가합니다. 어댑터는 모델의 특정 작업에 대한 성능을 향상시키기 위해 추가되는 작은 신경망입니다. 추가된 어댑터는 미세 조정 과정을 통해 특정 작업에 맞게 학습됩니다.
- 학습된 어댑터를 기본 모델 또는 양자화 해제된 모델 위에 병합: 미세 조정된 어댑터를 원래 기본 모델 또는 양자화를 해제한 기본 모델과 병합합니다. 이 단계에서는 어댑터의 가중치 정보가 기본 모델에 통합됩니다.
- GPTQ를 사용하여 병합된 모델 양자화 및 배포: 병합된 모델을 GPTQ(Generative Pre-Training Quantization) 기술을 사용하여 다시 양자화합니다. GPTQ는 모델의 성능 저하를 최소화하면서 모델 크기를 더욱 줄일 수 있는 양자화 기술입니다. 최종적으로 양자화된 모델을 배포하여 실제 애플리케이션에 사용합니다.
6. 데이터 개인 정보 보호 단계
7. 모델 모니터링 단계:
- Weights & Biases:와 같은 도구를 사용하여 모델 성능을 지속적으로 모니터링하고 성능 저하를 감지합니다.
LLMOps를 위한 모범 사례
이러한 과제를 극복하고 LLMOps를 성공적으로 채택하기 위한 몇 가지 모범 사례가 있습니ㅏㄷ.
- 데이터 관리 및 보안: LLM 학습에서 데이터의 중요한 역할을 고려할 때 강력한 데이터 관리 및 엄격한 보안 관행이 필수적입니다.
- 모델 라이프사이클 관리: 여기에는 모델 및 데이터 세트 버전 관리, 자동화된 테스트, 모델의 지속적인 통합 및 배포, 모델 성능 모니터링이 포함됩니다.
- 효율적인 리소스 할당: LLMOps는 리소스 할당을 모니터링하고 관리하는 동시에 효율적인 미세 조정을 위해 적합한 하드웨어 리소스에 대한 액세스를 보장합니다.
- 평가: LLMOps 도구를 사용하여 LLM 기반 애플리케이션을 평가하여 LLM 애플리케이션의 성능에 대한 간결하고 간단한 평가를 제공하고 배포 가능성을 결정할 수 있습니다.
- 지속적인 개선: 정기적인 평가는 모델의 여러 버전 또는 반복을 비교하는 데 사용할 수 있으므로 시간이 지남에 따라 LLM의 성능을 유지 관리하는 데 필수적입니다.
LLMOps의 미래
- 점점 더 많은 기업이 LLM의 가치와 이를 관리하기 위한 효율적인 방법의 필요성을 인식하고 있기 때문에 LLMOps의 미래는 밝습니다. LLM은 규모와 기능이 향상됨에 따라 생성 AI 시장을 전례 없는 성장으로 이끌고 있으며 이 기술의 시장 규모는 2028년까지 518억 달러에 이를 것으로 예상됩니다[25].
- LLMOps를 마스터하면 조직은 궁극적으로 최첨단 AI 솔루션을 만들고 새로운 혁신의 기회를 열 수 있습니다. 이 분야가 계속 발전함에 따라 AI와 머신러닝의 미래를 어떻게 형성할지 지켜보는 것은 흥미진진할 것입니다.
마지막으로 정리하자면 ,DevOps, MLOps 및 LLMOps는 소프트웨어 및 서비스의 속도, 효율성 및 안정성을 향상시키는 세 가지 접근 방식입니다. DevOps는 전반적인 IT 및 소프트웨어 개발에 중점을 둔 방법론인 반면 MLOps는 머신러닝 모델을 최적화하도록 설계되었습니다. 반면에 LLMOps는 AI 분야 내에서 대규모 언어 모델을 관리하는 데 특화 되어 있습니다.
의견을 남겨주세요