

주간SaaS 이번주 소개글:
SaaS는 완성되는 법이 없다고 생각합니다. MVP 수준의 초기 버전의 릴리스를 통해 시장에 진입한 순간 부터, 시장 제품 적합성을 찾아 성장의 단계를 거쳐 번창의 단계에 이른 순간까지도 끊임 없이 개선하고 성장해 나갈 뿐 입니다. 이를 위한 첫번째는 데이터를 통한 고객 이해 입니다. 오늘 소개하는 글은 Gusto가 7년간 고객 데이터 기반의 Growth platform을 구축하며 배운 교훈과 경험에 관한 글 입니다.
고객을 이해하는 첫걸음: 데이터 분석
폭발적으로 성장하는 모든 기업에게 성장 엔지니어링(Growth Engineering)은 필수적입니다. 하지만 성공적인 성장 엔지니어링을 위해서는 고려해야 할 사항들이 많죠. 지난 7년 동안 저는 성장 엔지니어링 팀 구축, 도구 개발, 그리고 고객 데이터 기반 성장에 필요한 플랫폼 구축에 매진했습니다. 이러한 경험을 바탕으로, SaaS 회사를 위한 강력한 성장 플랫폼 구축에 필요한 요소들을 이 시리즈에서 하나씩 짚어보려고 합니다.
첫 번째 주제는 모든 사용자 분석의 기초이자 모든 성장 플랫폼의 근간이 되는 계측 및 분석입니다. 본격적으로 계측에 대해 알아보기 전에, 개인 정보 보호 및 동의에 대해 잠시 살펴보겠습니다. 이 글에서는 사용자 행동 데이터를 수집하고 분석하는 방법을 다루는데, 데이터를 수집할 때는 회사의 개인정보 보호정책 및 사용자 데이터 & 개인 정보 보호 관련 규정을 준수하는 것이 무엇보다 중요합니다. Gusto는 데이터 소유자가 아닌 데이터 관리자가 되는 것을 중요하게 생각하며, Gusto의 데이터 개인 정보 보호 정책은 여기에서 확인할 수 있습니다.
자, 이제 성장 실험을 계획할 때 스스로에게 던져봐야 할 질문들을 소개합니다.
- 당신은 당신의 고객을 알고 있습니까?
- 고객이 어떤 경로를 통해 유입되는지 알고 있습니까?
- 고객이 당신의 마케팅 웹사이트 혹은 애플리케이션의 어떤 부분과 상호작용하는지 알고 있습니까?
이러한 질문에 대한 답을 찾거나 실험의 기초가 되는 가설을 세우려면 데이터 수집은 필수입니다. 다시 말해, 분석 정보를 수집하기 위한 소프트웨어 계측 작업이 선행되어야 합니다.
분석 정보: 구체적으로 어떤 데이터를 말하는 걸까요?
예를 들어 설명해보겠습니다.
- 방문자 Anon1은 구글 검색 결과를 클릭하여 홈페이지에 방문합니다.
- 방문자 Anon1은 네비게이션 바 왼쪽 상단에 위치한 '가입' 버튼을 클릭합니다.
- 방문자 Anon1이 계정 생성 양식을 제출합니다.
- 방문자 Anon1에게 '사용자 UUID 747374–232332…'가 부여됩니다.
이처럼 처음 웹사이트에 방문하는 모든 사람은 익명의 방문자일 뿐이며, 로그인이나 회원가입을 해야만 비로소 '등록된 사용자'가 됩니다. 그렇다면 이러한 정보는 어떻게 얻을 수 있을까요?
정보 수집의 시작: 분석 이벤트
우리는 측정하고자 하는 모든 접점에 대한 분석 이벤트를 전송하여 정보를 얻습니다. 이벤트 이름은 보통 명사(무엇) + 동사(행동)의 형태로 구성됩니다. 접점은 UI에서 발생하는 상호작용일 수도 있고, 백엔드에서 처리되는 작업일 수도 있습니다.
UI 상호작용 예시
- 페이지 뷰
- 버튼 클릭
- 양식 제출
백엔드 작업 예시
- 사용자 계정 생성
- 구독 결제 성공
- 이메일 전송
아래 이미지는 분석 데이터 추적을 유발하는 일반적인 상호작용들을 보여줍니다.
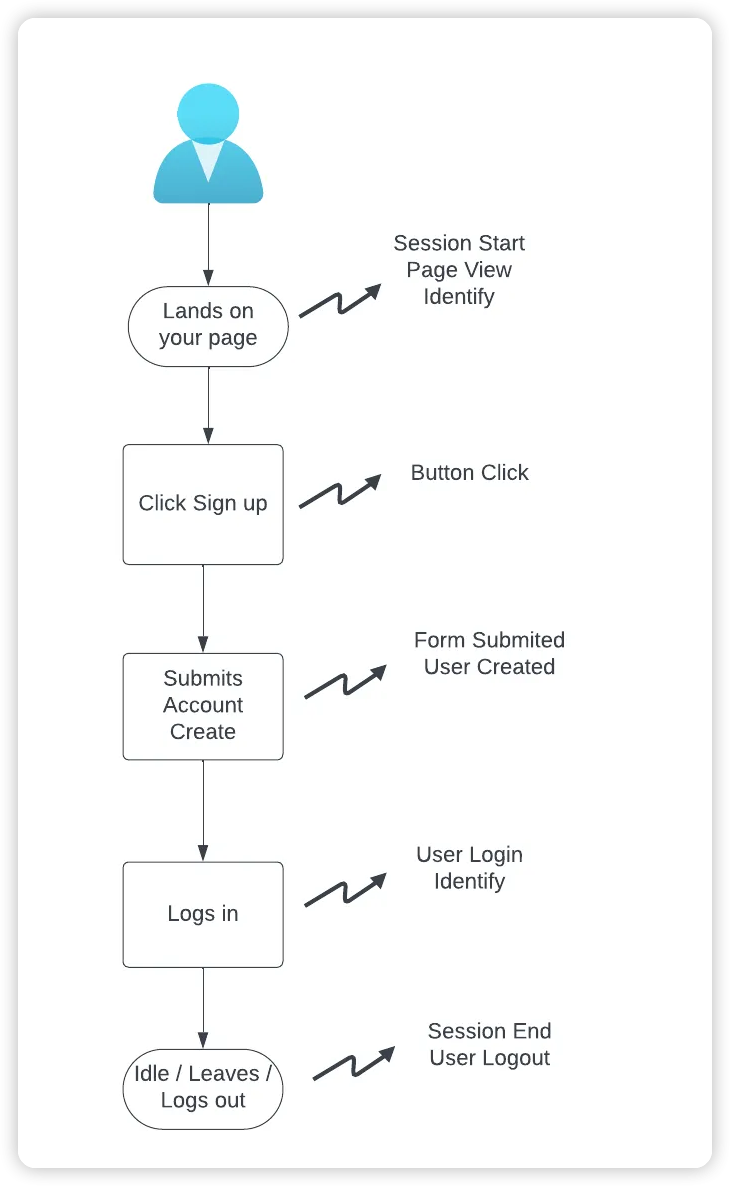
수집된 정보들은 추후 고객의 웹페이지 이용 방식에 대한 인사이트를 도출하기 위해 쉽게 쿼리 가능한 형태로 저장됩니다. 일반적으로 분석 이벤트는 특정 스키마를 따르는데, 최소한 eventName 필드는 필수적으로 포함되어야 합니다. 스키마는 다른 이벤트 속성과 더불어 익명 ID 혹은 알려진 사용자의 경우 사용자 ID가 될 수 있는 사용자 식별자를 포함합니다.
다음은 일반적인 분석 이벤트 스키마의 예시입니다.
지금까지 이벤트의 구조를 살펴봤으니, 이제 이벤트 정보를 얻는 방법에 대해 자세히 알아보겠습니다. 분석 데이터를 얻는 간단한 방법부터 시작해서, 성숙한 이벤트 파이프라인을 구축하는 단계까지 차근차근 살펴보도록 하죠.
계측 및 분석 플랫폼: 진화의 단계
대부분의 기업들은 어떤 요인이 웹사이트 트래픽을 증가시키는지 파악하기 위해 마케팅 웹사이트 분석부터 시작합니다. 이때 손쉽게 시작할 수 있는 도구 중 하나가 바로 Google Analytics입니다. 웹사이트에 추가하여 사용하는 Javascript 태그 형태인 Google Analytics는 방문자의 웹사이트 이용 행태를 수집하고, 트래픽 소스를 분석할 수 있는 기능을 제공합니다.
Google Analytics는 방문자 수, 세션 수, 추천 유입 출처, 방문자 위치 등을 파악하는 데 유용하며, 페이지뷰, UTM 매개변수 등을 측정하여 마케팅 캠페인 효과를 분석하는 데도 유용하게 활용됩니다.
하지만 Google Analytics가 만능은 아닙니다. 개인정보 보호에 민감한 브라우저들의 경우 Google Analytics를 차단하기도 합니다. 예를 들어, Firefox는 기본적으로 Google Analytics를 차단하기 때문에 해당 브라우저를 사용하는 방문자에 대한 분석 데이터는 수집할 수 없습니다. 사용자 개인 정보 보호는 매우 중요한 문제이기 때문에, 계측 작업은 반드시 사용자 개인 정보를 침해하지 않는 선에서 이루어져야 합니다.
기본적인 마케팅 데이터를 확보했다면, 이제 애플리케이션 사용 현황을 추적하기 위한 커스텀 이벤트를 구축할 차례입니다. Amplitude나 Mixpanel과 같은 써드파티 분석 도구를 활용하면 이 과정을 손쉽게 진행할 수 있습니다. 이러한 SaaS 서비스는 커스텀 분석 이벤트를 전송하는 SDK를 제공하며, 프론트엔드 개발을 위한 Javascript SDK, 백엔드 개발을 위한 다양한 언어 기반 SDK가 준비되어 있습니다.
써드파티 분석 도구는 서버에서 렌더링된 페이지의 경우 페이지 뷰를 자동으로 수집하고, SPA(Single Page Application)의 경우 필요에 따라 수집합니다. 또한, 워크플로우 상 중요한 순간을 포착하기 위해 애플리케이션 어디에서나 사용할 수 있는 커스텀 이벤트 전송 API를 제공하기도 합니다.
커스텀 이벤트 설정을 마쳤다면 각 이벤트를 사용자와 연결해야 합니다. 사용자는 공개 웹사이트 상의 익명의 방문자이거나 로그인한 '알려진 사용자'일 수 있습니다. 방문자는 익명 ID, 알려진 사용자는 고객 ID와 연결하여 백엔드 시스템에서 사용자의 모든 행동을 하나의 스토리로 연결할 수 있도록 합니다. (ID는 UUID를 사용하는 것이 좋습니다.)
하지만 기업의 규모가 커지고 데이터가 방대해질수록 이벤트 데이터 저장 및 분석 시스템을 여러 개 운영해야 할 필요성이 생깁니다. 자체 데이터 분석 팀이나 비즈니스 인텔리전스(BI) 팀을 보유한 기업의 경우, 내부적으로 데이터를 조회할 수 있도록 자체 엔터프라이즈 데이터 웨어하우스(EDW)를 구축하는 경우도 있습니다. 마케팅 팀에서 캠페인 전환율 및 유입 경로 기여도를 측정하기 위해 마테크 툴에 분석 데이터 연동이 필요할 수도 있습니다.
이 단계까지 왔다면 이벤트 라우터 도입을 고려해 보는 것이 좋습니다. 이벤트 라우터를 활용하면 이벤트를 필요한 곳으로 손쉽게 전달할 수 있습니다. Segment나 Tealium과 같은 유명 이벤트 라우팅 솔루션은 데이터를 수집하고 관리자가 라우팅 규칙을 직접 설정하거나 데이터 싱크로 전달하기 전 데이터를 보강할 수 있는 기능을 제공합니다. 데이터 싱크는 써드파티 API, 시각화 도구, 데이터 저장소, 광고 네트워크 등이 될 수 있습니다. 이러한 솔루션은 오늘날 고객 데이터 플랫폼(CDP)이라는 형태로 진화했습니다.
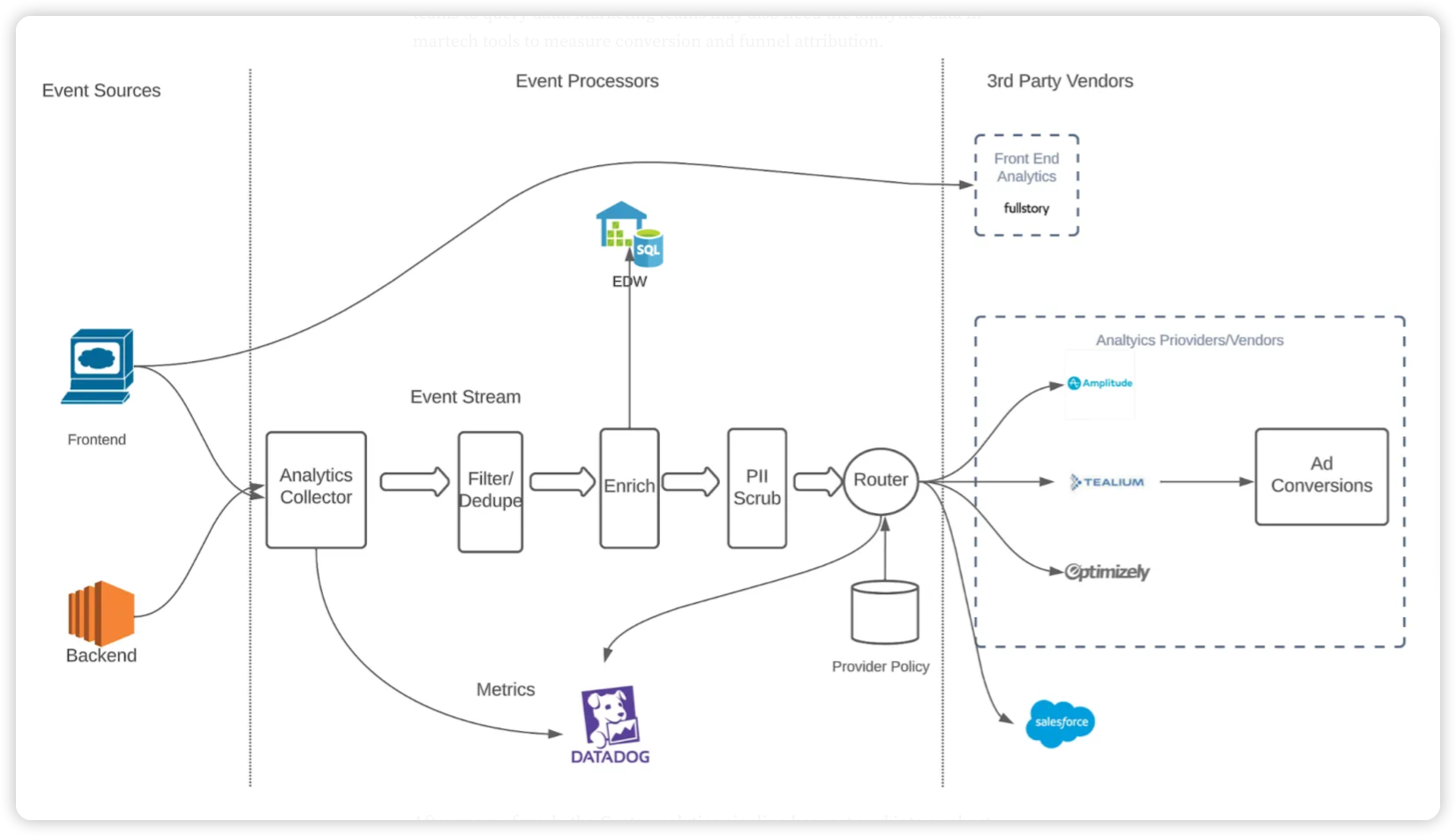
만약 써드파티 솔루션이 적합하지 않다면 자체 분석 파이프라인을 구축하는 방법도 있습니다. 오픈소스 기술을 활용하여 모든 시스템을 사내 서버에 구축하는 것이죠. 분석 파이프라인은 이벤트 스트림으로 구성되며, 각 이벤트는 특정 동작을 수행하거나, 수정되거나, 필터링된 후 최종적으로 이벤트를 전달받는 곳으로 전송됩니다. 분석을 위한 이벤트 스트림을 생성하고 필요에 따라 스트림을 처리한 후, 다운스트림 소비자에게 전달하는 구조입니다. AWS Kinesis나 Kafka와 같은 이벤트 스트리밍 기술이 이러한 시스템 구축에 유용하게 활용됩니다. 이때 이벤트를 수신하고 스트리밍 파이프라인으로 전송하기 위해서는 가용성이 높은 분석 서버가 필수적입니다.
스트림 프로세서는 스트리밍 데이터를 처리하는 함수입니다. 스트림 프로세서는 이벤트 데이터를 보강하고 여러 데이터 싱크로 이벤트를 전송하는 역할을 합니다. AWS Firehose를 이용하면 모든 이벤트를 S3에 저장하고, 사내 EDW 시스템에서 S3 데이터를 쿼리하여 분석에 활용할 수 있습니다. 데이터를 효율적으로 쿼리하기 위해 Parquet 형식으로 데이터를 저장하는 것이 좋습니다.
수년간의 노력 끝에 Gusto 분석 파이프라인은 안정적이고 강력한 시스템으로 성장했습니다. 초기에는 단순히 인사이트 도출을 위한 시스템이었지만, 지속적인 개선을 통해 분석 모범 사례를 따르는 고도화된 시스템으로 발전했습니다.
분석 모범 사례: 서버 측 이벤트 vs. 클라이언트 측 이벤트
클라이언트 측 이벤트보다는 서버 측 이벤트를 사용하는 것이 좋습니다. 클라이언트 측 이벤트를 사용해야 하는 경우, 동일한 도메인의 엔드포인트로 이벤트를 전송해야 광고 차단 프로그램에 의해 차단되는 것을 방지할 수 있습니다. 서버 측 이벤트를 사용할 때는 봇, 자동화 테스트, 크롤러 등에서 발생하는 이벤트는 제외해야 합니다. 실제 사용자 이벤트가 아니기 때문에 데이터를 왜곡할 수 있기 때문입니다.
분석과 모니터링은 다릅니다
분석과 모니터링, 비슷해 보이지만 엄연히 다른 개념입니다. 모니터링은 애플리케이션의 정상 작동 여부를 확인하는 데 사용됩니다. 모니터링 시스템은 오류를 감지하고 성능 및 가용성 지표를 측정합니다. 반면, 분석은 사용자의 소프트웨어 이용 행태를 파악하는 데 도움이 됩니다. 분석과 모니터링을 하나의 시스템으로 관리하는 실수를 범해서는 안 됩니다. 사용자 데이터를 모니터링 시스템에 저장할 경우 메트릭 카디널리티(고유 시계열 데이터 수)가 높아져 비효율적일 뿐만 아니라 시스템 부하를 높여 비용 부담으로 이어질 수 있습니다. 성능 지표 데이터 때문에 분석 파이프라인에 과부하가 걸리면 사용자 행동과는 무관한 시스템 정보로 인해 사용자 분석 데이터가 오염될 수 있습니다. 이는 이벤트 볼륨 증가로 이어져 분석 솔루션 이용료가 증가하는 원인이 됩니다.
쿠키와 사용자 동의
데이터 분석을 위해서는 사용자 데이터가 필수적이지만, 그렇다고 해서 함부로 데이터를 수집해서는 안 됩니다. 사용자 동의를 항상 존중해야 하며, 사용자가 추적을 원하지 않는다면 절대로 추적해서는 안 됩니다. 분석 데이터는 사용자 이용 패턴을 파악하고 사용자 상호작용을 측정하기 위해 활용되어야 하며, 데이터 활용 전 반드시 사용자 동의를 구해야 합니다.
PII / PHI: 민감한 정보는 더욱 신중하게
분석 시스템을 통해 특정 사용자를 식별할 수 있어서는 안 됩니다. PII / PHI 데이터는 분석 시스템을 통해 전송되어서는 안 되며, 이벤트 데이터에는 UUID를 사용하고, GDPR이나 CPRA와 같은 개인 정보 보호법을 준수하는 데이터 삭제 정책을 수립해야 합니다.
써드파티 솔루션 vs. 자체 구축: 상황에 맞는 전략 선택
써드파티 솔루션을 이용하면 분석 시스템을 빠르게 구축하여 데이터 분석을 시작할 수 있다는 장점이 있습니다. 하지만 데이터 양이 증가함에 따라 솔루션 이용료 또한 증가하기 때문에, 데이터 양이 많아질수록 자체 솔루션을 구축하는 것이 비용 절감에 더 효과적일 수 있습니다.
만약 중소기업이라면 처음부터 분석 파이프라인을 직접 구축하는 것이 더 효율적일 수 있습니다. 자체 서버를 구축하면 데이터 유실 가능성을 최소화할 수 있으며, 데이터 레이크를 직접 구축하여 데이터를 분석하면 비용을 절감할 수 있고, 데이터를 내부적으로 안전하게 관리할 수 있다는 장점도 있습니다.
이벤트 유실 / Latency: 언제나 고려해야 할 요소
분석 이벤트는 유실될 가능성이 있으며 대기 시간에 민감하지 않습니다. 웹 애플리케이션과 비동기적으로 동작해야 하지만, 데이터 유실 가능성을 최소화하기 위한 노력은 필요합니다. 데이터 지연 시간은 비즈니스 요구사항을 만족하는 수준이어야 하며, 데이터 지연 시간을 최소화해야 중요한 분석 데이터를 실시간에 가깝게 분석할 수 있습니다.
데이터 품질 및 스키마: 정확한 분석의 시작
데이터 분석 결과의 정확성을 위해서는 높은 수준의 데이터 품질 관리가 필수적입니다. 부정확한 데이터는 잘못된 의사 결정으로 이어질 수 있습니다. 스키마, 시행, 이벤트 정의 부재로 인해 시간이 지남에 따라 데이터 품질이 저하되는 경우를 자주 볼 수 있습니다.
분석 이벤트에 대한 명확한 스키마를 사전에 정의해야 모든 이벤트와 속성이 동일한 형태와 구조를 유지할 수 있습니다. 빌드 파이프라인이나 분석 파이프라인에 스키마 유효성 검사 단계를 추가하면 잘못된 데이터 유입을 방지하고 이벤트 스트림의 품질을 유지할 수 있습니다.
스키마 유효성 검사 외에도 추적 계획을 수립하는 것도 중요합니다. 추적 계획은 이벤트의 목적과 측정하려는 지표를 명확하게 정의하는 문서입니다. 스프레드시트는 추적 계획을 간편하게 관리할 수 있는 도구입니다. 추적 계획에는 측정하려는 지표/워크플로우, 지표/워크플로우를 측정하기 위해 데이터를 수집할 시점, 각 시점을 기록하기 위한 이벤트 정의 등이 포함됩니다. 새로운 이벤트를 정의하거나 기존 이벤트에 문맥 정보를 추가할 수 있습니다.
추적 계획은 제품 관리자와 데이터 분석가가 애플리케이션 워크플로우와 지표를 측정하고 계측하는 방법을 이해하는 데 도움이 됩니다. 스프레드시트 외에도 avo나 tracking plan과 같이 추적 계획 관리를 위한 써드파티 솔루션도 있습니다.
결론: 데이터 기반 의사 결정을 위한 첫걸음
Gusto는 데이터 팀에서 관리하는 정교한 분석 파이프라인, 사내 EDW, 그리고 써드파티 시각화 도구를 활용하고 있습니다. 성장 팀과 제품 팀은 이러한 데이터 분석 시스템을 기반으로 데이터에 기반한 의사 결정을 내리고, 신규 기능 출시 및 실험 결과를 측정합니다. 이 글이 성장을 위한 핵심 도구와 분석 시스템을 활용하여 사용자 이용 행태를 분석하는 방법을 이해하는 데 도움이 되었기를 바랍니다.





의견을 남겨주세요