
주간SaaS 오늘의 소개 글
안녕하세요, 주간 SaaS입니다.
새로운 서비스에 가입할 때, 내가 쓰려던 아이디가 이미 존재한다는 메시지를 종종 만나게 됩니다. 으레 '데이터베이스에서 중복 값을 확인하나 보다' 하고 넘겼지만, 사용자 수가 폭발적으로 늘어난다면 이 간단한 기능조차 지연 시간 없이 제공하기란 쉽지 않은 과제입니다.
오늘 소개할 글은 바로 이 단순한 기능을 어떻게 저지연(low-latency), 그리고 확장성 있는 소프트웨어 아키텍처로 구현하는지 그 방법을 쉽고 명쾌하게 소개합니다.
Instagram 같은 플랫폼에서 회원가입을 할 때, 사용하고 싶은 유저명을 입력하면 시스템은 거의 즉시 사용 가능 여부를 알려줍니다. 만약 이미 사용 중인 이름이라면, 그 자리에서 바로 대안 유저명을 추천해주기까지 하죠.
수천 명 규모의 작은 스타트업이라면 간단한 database query 한 번으로 충분할 겁니다. 하지만 Instagram, Google, 혹은 X(구 Twitter)처럼 수십억 명의 사용자를 보유한 플랫폼에게는 훨씬 더 어려운 문제입니다. 누군가 가입을 시도할 때마다 수십억 개의 데이터를 전부 스캔할 수는 없는 노릇이니까요.
그렇다면 이들은 어떻게 눈 깜짝할 사이에 이 작업을 해내는 걸까요?
이 글에서는 가장 기본적인 접근법부터 빅테크 기업에서 사용하는 정교한 아키텍처까지, 이러한 시스템이 어떻게 만들어지는지 그 여정을 단계별로 살펴보겠습니다.
## Level 1: 데이터베이스에 직접 쿼리하기
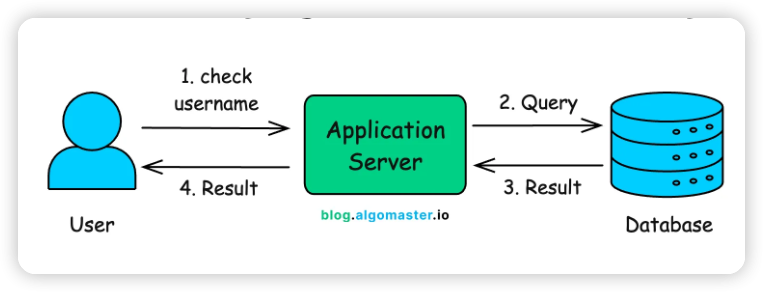
유저명 중복을 확인하는 가장 간단한 방법은 데이터베이스에 직접 물어보는 것입니다.
SELECT COUNT(1)
FROM users
WHERE username = ‘new_user’;만약 count가 0보다 크면 이미 사용 중인 유저명이고, 0이라면 사용 가능한 이름입니다. 간단하죠?
수천, 수백만 명 규모의 시스템에서는 이 방법으로도 충분합니다. 인덱싱이 잘 된 관계형 데이터베이스는 수 밀리초(milliseconds) 안에 결과를 반환할 수 있으니까요.
하지만 수억, 수십억 명의 사용자가 여러 서버와 데이터 센터에 분산된 환경으로 확장되면 상황은 완전히 달라집니다.
- 인덱스가 거대해집니다: B-trees나 hash indexes 같은 효율적인 자료구조를 사용하더라도, 이를 스캔하고 유지하는 데 더 오랜 시간이 걸립니다.
- 데이터베이스에 과부하가 걸립니다: 모든 가입 시도가 새로운 쿼리를 의미하며, 이미 바쁜 시스템에 엄청난 읽기 트래픽(read traffic)을 유발합니다.
요컨대, 직접 쿼리는 정확하고 구현하기 쉽지만 빅테크 규모의 트래픽을 감당할 만큼 확장성이 좋지는 않습니다. 수십억 개의 데이터 앞에서는 이 방식은 금방 멈춰버릴 것입니다.
## Level 2: Cache 추가하기
그다음으로 자연스러운 최적화 단계는 Caching입니다.
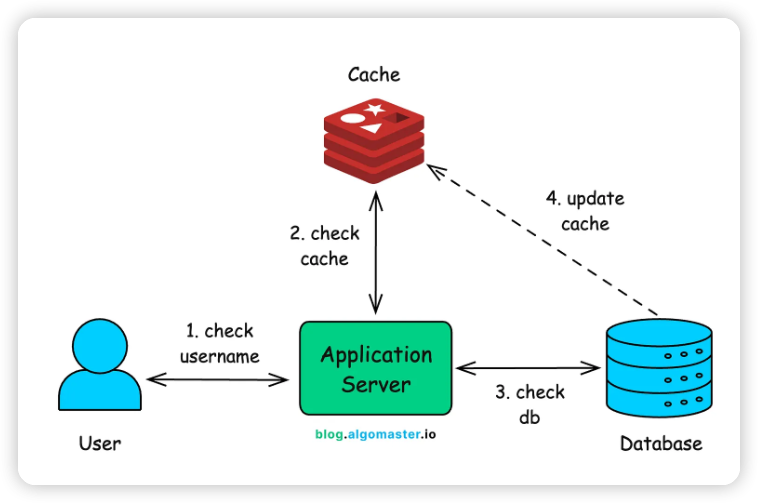
사용자가 새로운 유저명을 시도할 때마다 데이터베이스를 호출하는 대신, 자주 확인되는 유저명의 임시 복사본을 메모리(Redis나 Memcached 같은 도구 사용)에 보관하는 것입니다.
흐름은 다음과 같습니다.
- 유저가 유저명 입력: 요청이 애플리케이션 서버로 들어옵니다.
- Cache 확인 (1차): 시스템은 먼저 이 유저명이 최근에 조회된 적이 있는지 Cache에서 확인합니다.
- 데이터베이스 확인 (최종): Cache에 없는 경우, 애플리케이션은 데이터베이스에 최종 결과를 쿼리합니다.
- Cache 업데이트 (미래를 위한 최적화): 데이터베이스가 응답을 반환하면, 시스템은 그 결과를 Cache에 업데이트합니다. 다음에 같은 유저명을 조회할 때는 메모리에서 즉시 결과를 얻을 수 있도록 말이죠.
이 방식은 자주 조회되는 유저명에 대해 아주 효과적입니다. 예를 들어 수천 명의 사용자가 john, alex, princess 같은 이름을 계속 시도한다면, Cache는 데이터베이스를 전혀 거치지 않고도 해당 요청들을 즉시 처리할 수 있습니다.
하지만 Caching은 새로운 고민거리를 안겨줍니다.
- 제한된 메모리: 수십억 개의 유저명을 영원히 메모리에 저장하는 것은 불가능합니다. 너무 비싸죠. 그래서 시스템은 보통 Least Recently Used (LRU) 같은 정책을 통해 "인기 있는" 데이터만 남깁니다.
- 오래된 데이터 (Stale data): 만약 사용자가 계정을 삭제해서 유저명이 사용 가능해졌는데 Cache가 제때 업데이트되지 않으면, 시스템은 여전히 사용 중이라고 착각할 수 있습니다. 이는 보통 time-to-live (TTL) 값을 설정해 캐시된 데이터가 결국 만료되도록 하여 해결합니다.
- Cache misses: 처음 조회되는 고유한 유저명은 여전히 데이터베이스까지 도달해야만 합니다.
## Level 3: Bloom Filters 사용하기
이제부터 정말 흥미로워집니다.
모든 유저명을 메모리에 직접 저장하거나 매번 데이터베이스에 쿼리하는 대신, 어떤 유저명이 존재할 수도 있다는 사실을 알려주는 아주 작은 "지문(fingerprint)"을 저장하면 어떨까요?
이것이 바로 Bloom Filters가 설계된 목적입니다.
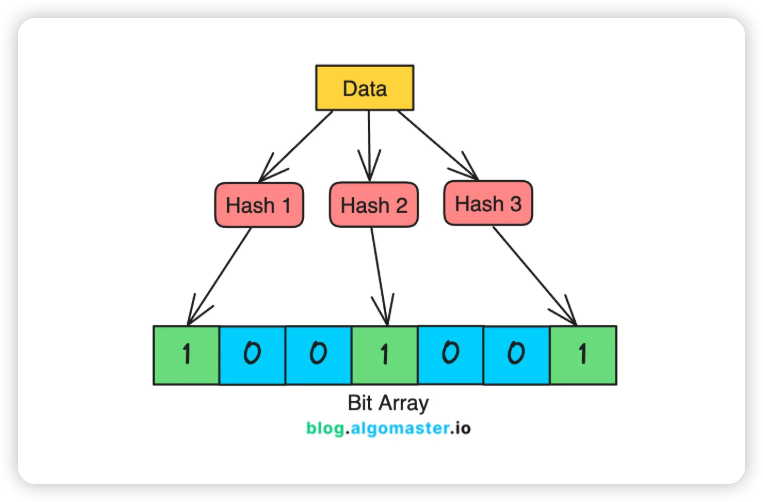
Bloom Filter란?
Bloom filter는 "이 유저명이 시스템에 존재할 가능성이 있는가?"라는 질문에 아주 빠르게 답할 수 있는 확률적 자료구조입니다.
- 만약 필터가 NO라고 답하면, 그 유저명은 100% 존재하지 않습니다.
- 만약 필터가 YES라고 답하면, 그 유저명은 존재할 수도 있으니, Cache나 데이터베이스에서 다시 한번 확인해봐야 합니다.
Bloom filter는 아주 약간의 false positives(오탐) 확률을 감수하는 대신, 극단적인 속도와 메모리 효율성을 얻는 전략입니다.
Bloom Filter가 강력한 이유
- 공간 효율성: 약 1.2GB의 메모리만으로 10억 개의 유저명을 1%의 false positive 확률로 표현할 수 있습니다.
- 속도: 메모리에서 몇 개의 비트를 확인하는 것은 Cache나 데이터베이스에 접근하는 것보다 훨씬 빠릅니다.
Bloom Filter의 동작 방식
- 초기화: Bloom filter는 모든 비트가 0으로 설정된 거대한 비트 배열로 시작합니다.
- 유저명 추가: 사용자가 new_user로 가입했다고 가정해 봅시다.
- 이 유저명은 여러 개의 다른 hash functions(보통 3~10개)를 통과합니다.
- 각 hash function은 비트 배열의 특정 위치를 가리키는 값을 생성하고, 해당 위치의 비트들을 1로 바꿉니다.
- 유저명 확인: 나중에 다른 사람이 new_user를 시도하면, 똑같은 hash functions이 적용됩니다.
- 시스템은 해당 비트들을 확인합니다.
- 만약 하나라도 0인 비트가 있다면, 이 유저명은 절대 등록된 적이 없는 것이므로 → 사용 가능합니다.
- 만약 모든 비트가 1이라면, 이 유저명은 아마도 사용 중일 것입니다.
- 주의할 점: False Positives
- 가끔, 어떤 새로운 유저명의 해시 위치들이 다른 유저명들이 설정해 둔 위치와 우연히 겹칠 수 있습니다. 이는 필터가 실제로는 사용 가능한 유저명임에도 불구하고 "아마도 사용 중"이라고 말할 수 있음을 의미합니다.
- 이것이 바로 Bloom filter가 YES라고 답했을 때 항상 Cache나 데이터베이스에서 최종 확인을 거쳐야 하는 이유입니다. (전체 요청의 약 1% 정도)
모든 것을 종합하면
여러분이 my_cool_username을 입력하고 엔터를 누를 때, 대규모 시스템의 뒷단에서는 다음과 같은 일이 일어납니다.
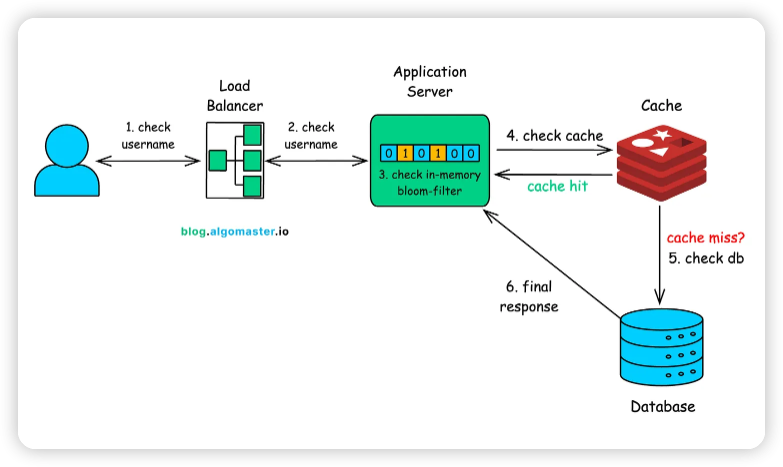
- Load Balancer: 당신의 요청은 먼저 Load Balancer에 도달하고, 가장 가깝거나 가장 한가한 서버로 라우팅됩니다.
- Bloom Filter (1차 확인): 서버는 먼저 메모리에 있는 Bloom filter를 확인합니다.
- 만약 Bloom filter가 "절대 사용 중 아님"이라고 답하면, 서버는 즉시 "사용 가능!"이라는 응답을 반환합니다.
- 대부분의 유저명은 고유하기 때문에, 압도적인 대다수의 요청은 여기서 끝납니다. Cache나 데이터베이스를 전혀 건드리지 않고요.
- Cache 확인 (2차 확인): 만약 Bloom filter가 "아마도 사용 중"이라고 답하면, 시스템은 분산 Cache(Redis/Memcached)를 확인합니다.
- 만약 유저명이 최근에 조회된 적이 있다면, Cache가 즉시 확정적인 답변을 반환합니다.
- 데이터베이스 확인 (최종 확인): Cache에도 없는 경우에만 요청은 메인 데이터베이스로 향합니
- 이것은 단일 머신이 아니라 Cassandra, DynamoDB, Spanner 등 수천 대의 서버에 분산된 시스템입니다.
- 내부적으로는 B+ Trees와 같은 인덱싱 구조가 거대한 규모에서도 O(log n)의 효율적인 조회를 보장합니다.
- 응답 및 업데이트: 데이터베이스가 최종적인 yes/no를 반환합니다.
- 응답이 돌아오는 길에, 그 결과는 다음 조회를 위해 Cache에 기록됩니다.
이러한 계층적 접근 방식은 각 단계가 수많은 요청을 걸러내는 깔때기처럼 작동하여, 오직 극소수의 요청만이 "비싼" 작업인 메인 데이터베이스까지 도달하도록 보장합니다.
## Level 4: 단순한 조회를 넘어서
지금까지 우리는 단순히 "이 유저명이 존재하는가?"라는 yes/no 확인에 대해서만 이야기했습니다.
하지만 Instagram과 같은 실제 플랫폼은 한 걸음 더 나아갑니다. 만약 당신이 선택한 이름이 이미 사용 중이라면 대신해 사용할만 한 유저명을 제안해주죠.
예를 들어 daniel이라는 유저명이 이미 사용 중이라면, Instagram은 다음과 같은 이름을 제안할 수 있습니다.
- daniel_123
- daniel_dev
- daniel2025
이런 기능은 Cache나 Bloom filter보다 더 똑똑한 무언가를 필요로 합니다. 바로 접두사 기반 조회(prefix-based lookups)를 위해 특별히 제작된 자료구조, Trie (Prefix Tree)입니다.
Trie란?
Trie는 문자열을 그들의 공통된 접두사를 기준으로 정리하는 트리 형태의 구조입니다. 유저명을 통째로 저장하는 대신, 한 글자씩 분해하여 공통된 경로를 재사용합니다.
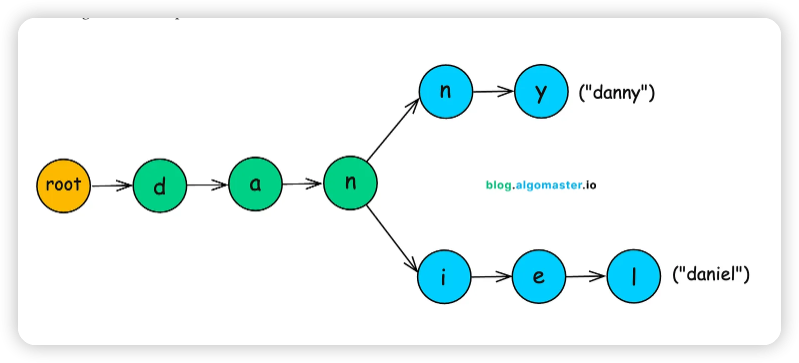
예를 들어:
- daniel은 d → a → n → i → e → l 경로가 됩니다.
- danny는 d → a → n 경로를 공유하다가 n → y로 갈라집니다.
Trie는 데이터베이스나 Cache가 힘들어하는 다음과 같은 기능들을 가능하게 합니다.
- 빠른 조회: 유저명이 존재하는지 확인하는 데 걸리는 시간은 전체 유저명의 수가 아니라 오직 문자열의 길이(O(M))에 비례합니다. 시스템에 수십억 개의 유저명이 있더라도 daniel을 찾는 데는 6단계면 충분합니다.
- 자동 완성: 부분적인 경로를 따라가면, 주어진 접두사로 시작하는 모든 유저명(예: dan)을 즉시 나열할 수 있습니다.
- 추천 기능: 비슷한 유저명들이 공통 경로를 공유하기 때문에, daniel_dev나 daniel2025 같은 대안을 생성하는 것이 쉽고 효율적입니다.
물론 Trie에도 단점은 있습니다.
- 메모리 사용량: 만약 유저명들이 공통된 접두사를 많이 공유하지 않는다면, 트리의 가지가 폭발적으로 늘어나 많은 메모리를 소모할 수 있습니다.
- 업데이트 오버헤드: 분산 환경에서 실시간으로 유저명을 삽입하거나 삭제하려면 신중한 동기화 작업이 필요합니다.
메모리 사용량을 줄이기 위해, 종종 compressed tries (radix trees)가 사용됩니다. 자식 노드가 하나뿐인 체인을 하나의 엣지(edge)로 압축하여 공간과 조회 단계를 모두 절약함으로써, 이 구조를 대규모 환경에서 더 실용적으로 만들어줍니다.
의견을 남겨주세요