
OpenAI 연구원인 정형원박사가 모교인 MIT에서 진행하여 2024년 9월 20일 공개된 강연 내용을 리뷰해봤습니다.
위대한 문제를 찾아봅시다:
- 위대한 연구자들의 공통점은 가장 임팩트가 큰 문제를 찾는 능력이 있다는 점
- 눈앞의 문제를 푸는데 급급해서는 위대한 문제를 찾을 수 없음
- 위대한 문제를 찾기 위해서는 관점의 변화가 필요함
- 다양한 관점이 서로 존중되고 더 활발히 공유되길 바람
AI 연구의 핵심 동향:
- 컴퓨팅 비용이 기하급수적으로 감소하고 있음
- 이 트렌드는 거역할 수 없고, 이 트렌드를 어떻게 잘 활용할지 고민해야 함
- 현재의 거대 언어 모델은 다음 토큰 예측에 기반한 약한 인센티브 구조를 사용함
- 이를 통해 모델은 수조 개의 작업 유형을 처리하기 위한 일반적인 기술을 학습함
- 이렇게 많은 데이터를 가지고 많은 작업 유형 (패턴)을 익히는 방식은 비효율적임
- 많은 연구자들이 자신들의 이름을 건 알고리즘으로 세상을 바꾸고자 하지만, 알고리즘보다 데이터와 컴퓨팅이 훨씬 중요했다는 것이 역사로 증명
- 중요한 것은 모델이 가치를 창출하느냐는 것이고 이를 달성하기 위해서는 연구자들도 새로운 인센티브 구조를 연구할 필요가 있음
인센티브 기반 학습의 중요성
- 직접적인 교육보다 인센티브 구조를 통한 학습이 더 효과적
- 모델 규모가 커짐에 따라 인센티브 기반 학습의 효과가 증대됨
- 모델 규모에 따라 다른 능력이 출현함
- 현재 작동하지 않는 아이디어도 미래에는 작동할 수 있다는 "아직"의 관점 필요
- 연구자들은 이러한 현상을 예측하고 준비해야 함
- 물론 원숭이에게 바나나를 아무리 가져다줘도 수학 논문을 쓸 수는 없듯이 인센티브 기반 학습이 가능하려면 최소한의 지적 능력을 갖춰야 함
- GPT4 모델부터 이 능력을 갖춘 것으로 봄
- "물고기 맛을 보여준 뒤, 계속 배고프게 하자." 그러면 인내심과 물고기가 좋아하는 미끼 등 여러가지 필수 능력을 인공지능이 스스로 학습할 것
AI 연구에 대한 새로운 관점
- 기본 가정(가장 유능한 모델)이 빠르게 변화함
- 바뀔때마다 기존 방식을 버리고 (unlearning) 새로운 방식을 익혀야 함
- 실제로 기존 방식에 대한 지식이 전무한 학부생이 쓴 논문으로 전체 업계의 연구방향이 바뀌기도 함
- 기존 직관을 버리고 새로운 패러다임에 적응하는 능력이 중요
- 다음 토큰 예측 (Next Token Prediction) 방식이 그동안 아주 잘 동작해왔지만, 이것도 정답이 아닐 수 있음
- 더 나은 인센티브 구조에 대해 주목해야 함
리뷰
정형원 박사의 강의에는 정말 훌륭한 인사이트가 가득한데요, 하나하나 인용해가면서 리뷰해보겠습니다.
인간 지능과 기계 지능은 다릅니다. 인간의 기준으로 기계를 가르치는 것보다 모델이 스스로 데이터를 보고 패턴을 학습하게 하는 것이 훨씬 낫습니다.
OpenAI 정형원
사실 이건 새로운 인사이트가 아닐 수 있는데, 사람의 도움없이 스스로 바둑을 학습한 모델이 사람이 바둑을 두는 것을 보고 배운 모델보다 우수하다는 것은 이미 지난 2017년 Alphago Zero를 통해 입증된 적이 있죠.
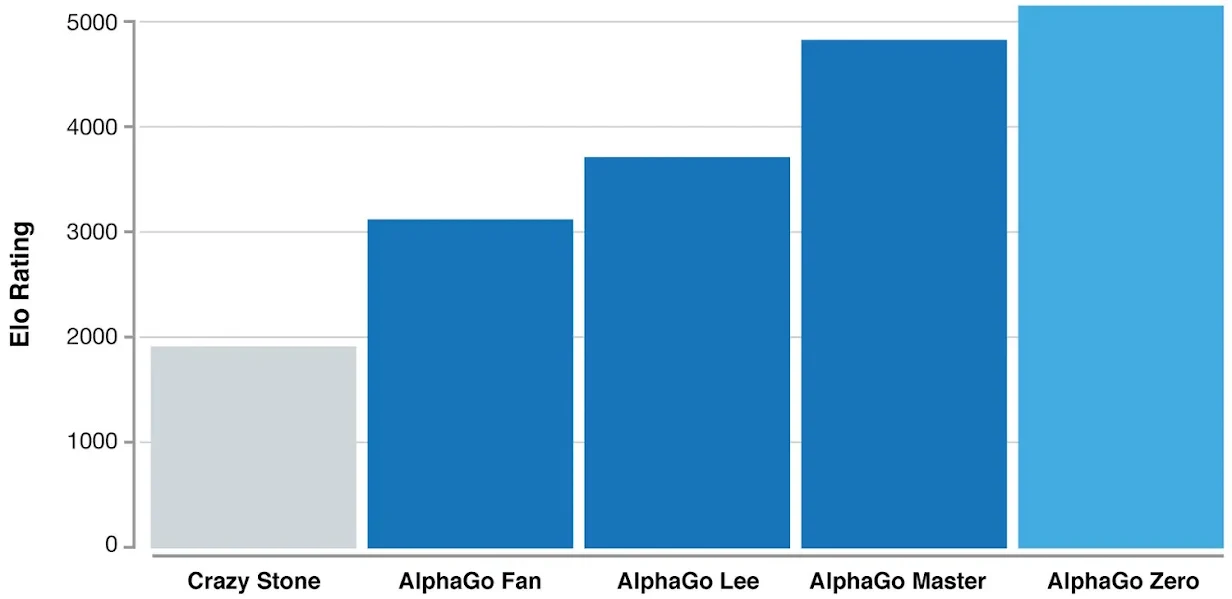
그럼에도 우리는 계속 인공지능에게 우리가 생각하는 방식을 가르치려고 시도합니다. 정형원 박사는 그 이유에 대해서 단기적으로 좋은 결과가 나오기 때문이라고 설명합니다. 그래서 그동안 연구자들이 우선 여기에 집중을 하는 경향이 있었는데, 장기적으로 봤을 때는 이 방식은 어느 지점 이후로는 성능이 정체된다는 단점이 있었습니다. 사람이 하나하나 가르치게 되면, 사람의 방식이 일종의 한계로 작용할 수 있다는 것입니다.
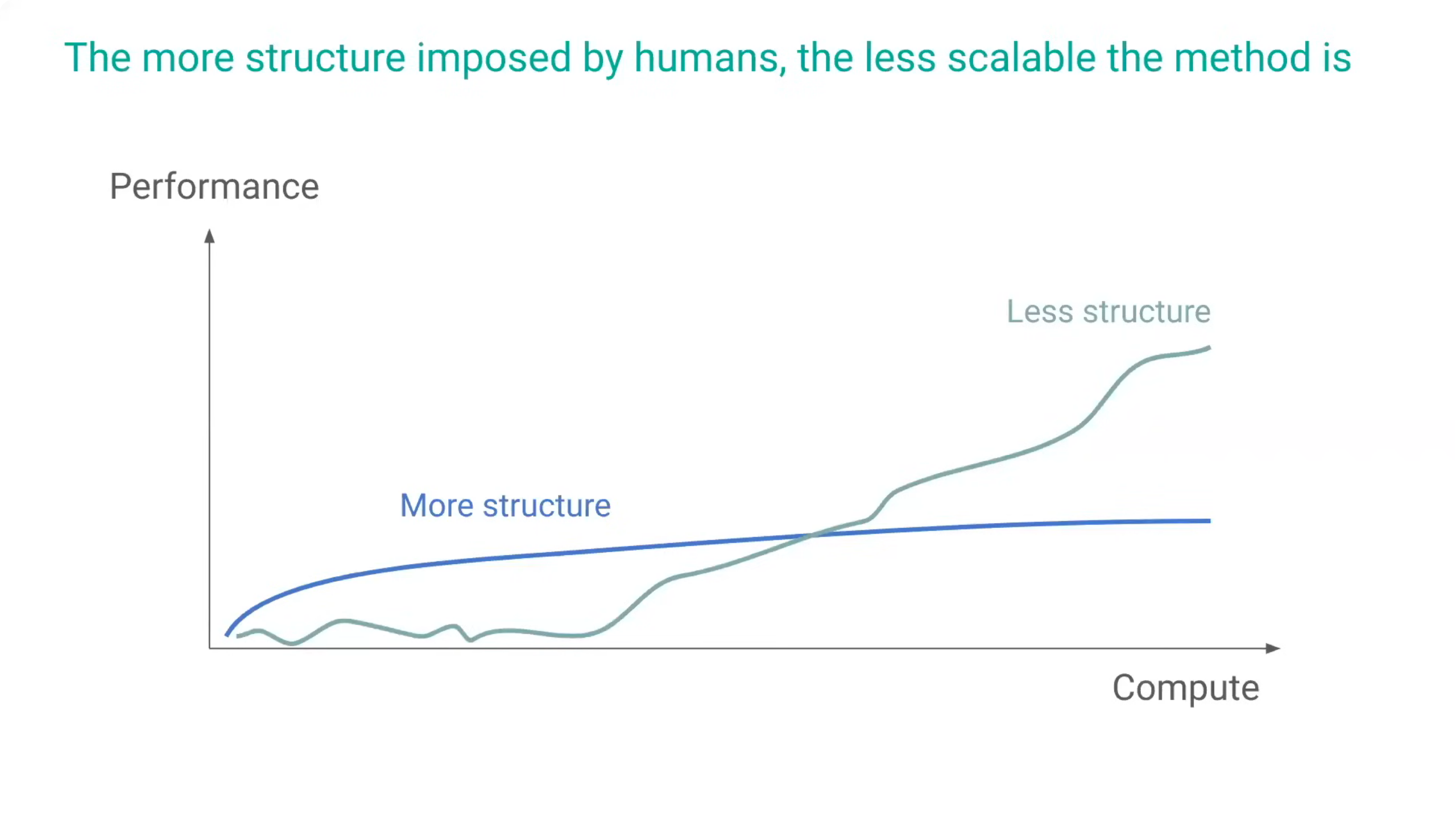
모델에게 알아서 학습하도록 하면 처음엔 부족하더라도 충분한 컴퓨팅과 데이터가 제공되면 스스로 사람이 가르칠 수 있는 패턴보다 훨씬 많은 개수의 패턴을 스스로 학습할 수 있다는 것입니다. GPT4의 경우에는 그 패턴의 개수가 수조개가 넘는다고 하니, 앞으로도 컴퓨팅과 데이터는 더 많이 제공될 거라는 것을 전제로 했을 때 더 이상 사람이 가르치려는 방식을 붙잡고있을 필요가 없다는 것입니다.
이 분명한 트렌드를 인식하고, 기계가 스스로 학습할 수 있도록 하되, 기계에게 어떻게 인센티브를 줘야 더 학습이 잘 될 것이냐에 집중해야된다는 이야기를 하고 있습니다. 잘 생각해보면 이런 맥락은 일전에 리뷰했던 구글의 프랑소와 숄레의 이야기와도 맞닿아 있습니다.
학습량을 늘리면 꺼내쓸 수 있는 공식이 많아지니 더 많은 상황에 대처가 가능해지는 거고, 꺼내쓸 수 있는 공식을 못찾거나 잘못 찾으면 환각을 일으키는 것
Google 프랑소와 숄레
정형원 박사와 프랑소와 숄레 모두 LLM의 작동방식과 한계점에 대해서는 공감을 하고 있다는 거죠. 다만, 프랑소와 숄레는 해결책을 다 같이 찾아보자는 취지에서 Arc Prize 대화를 연 것이고, 정형원 박사는 모델에게 어떻게 인센티브를 주느냐, 즉 새로운 인센티브 구조를 통해 이 한계를 뛰어넘을 수 있을 것 같다는 이야기를 하고 있습니다.
이 인센티브 구조에 대해 아주 기가막힌 비유를 하나 제시하였는데요, 어릴 때부터 들어왔던 "물고기를 잡아주기 보다 물고기 잡는 법을 가르쳐주어라"는 말을 살짝 비틀어 "물고기 맛을 보여준 다음 모델이 계속 배고픔을 느끼게 하라"는 말로 인센티브 구조를 설명하였습니다.
"물고기 맛을 보여준 다음 모델이 계속 배고픔을 느끼게 하라"
OpenAI 정형원
모델이 계속 물고기를 먹고 싶게하면, 우리가 물고기 잡는 법, 좋은 타이밍을 위해 기다리는 법, 물고기가 좋아하는 미끼를 고르는 법을 직접 가르쳐주지 않아도 직접 시행착오를 거듭하며 학습할 것이라는 이야기입니다. 심지어 컴퓨팅 능력이 높아지면서 예전 드래곤 볼에 나오는 "정신과 시간의 방"처럼 현실세계의 시간보다 훨씬 빠르게 모델이 학습을 할 수도 있을 것입니다.
정형원 박사는 또, 패러다임이 바뀔때마다 기존 방식을 버리고 (unlearning) 새로운 방식을 익혀야 하는 시대가 왔다고 합니다. 다음 토큰 예측 (Next Token Prediction) 방식이 그동안 아주 잘 동작해왔지만, 이것도 정답이 아닐 수 있고, 더 나은 방법이 있을 수 있다고 말이죠.
제프리 힌튼 교수도 비슷한 이야기를 한 적이 있지요. 자신의 역전파 알고리즘보다 더 나은 방법이 있을 수 있으므로 자신도 그 방법에 대해 고민하고 있고, 다른 사람들도 고정관념에 사로잡히지 말고 새로운 시각으로 문제를 봐달라고요.
대가들의 인터뷰들을 정리하다보니 이렇게 대가들 이야기에서 공통된 부분이 찾아질때가 종종 생깁니다. 뭔가 어떤 분야에서 일가를 이룬 사람들은 공통된 것들이 보이나 봅니다. 현 방법론의 한계를 정확히 알면서 새로운 방법을 끊임없이 탐구하는 모습에서 오늘도 많은 동기부여를 받습니다.
참고자료
의견을 남겨주세요