
🐧 : 안녕하세요, 최근 SaaS 서비스를 개발하시면서 SaaS 의 컨트롤 플레인과 데이터 플레인에 대해서 질문하시고, 이를 직접 개발하시는 분들이 늘어난 것을 느낍니다. 그와 동시에 컨트롤 플레인과 데이터 플레인에 대한 개념이 처음이어서 어려워 하시는 분들도 많은데요, 이번주와 다음주에는 B2B SaaS 를 설계 할 때 필수적인 컨트롤 플레인과 데이터 플레인에 대해서 다루어 보고자 합니다.
먼저 이번 주에는 다음 원문 을 통해 컨트롤 플레인과 데이터 플레인 의 일반적인 개념을 소개하고, 이어서 다음 주에는 SaaS 에서의 컨트롤 플레인과 데이터 플레인을 다뤄볼 예정입니다.
원문에 포함된 다양한 참고 자료 링크를 꼭 한번씩 읽어 보시면 컨트롤 플레인과 데이터 플레인 아키텍처 설계 고려 사항에 대해 이해하실 수 있을 겁니다.
최근 직장에서 만난 한 아키텍트는 사용 중인 리소스에 따라 시스템을 고가용성 및 독립적으로 확장할 수 있도록 설계하는 아키텍처적 접근 방식에 대해 언급했습니다. 이 개념을 컨트롤 플레인과 데이터 플레인이라고 합니다.
고가용성을 최우선으로 고려해야 하는 트래픽이 많은 경우 컨트롤 플레인과 데이터 플레인 개념을 고려할 가치가 있습니다.
컨트롤 플레인과 데이터 플레인에 대한 정보를 검색하면 의심할 여지없이 네트워크 기술과 관련된 글 들을 다수 찾을 수 있습니다. 네트워킹이 이를 어떻게 적용하는지에 대한 많은 예시와 설명이 있습니다. 예를 들어, Cloud Flare의 다음 글은 컨트롤 플레인과 데이터 플레인의 차이점을 설명합니다. "컨트롤 플레인은 데이터가 전달되는 방식을 제어하는 네트워크의 일부이며, 데이터 플레인은 실제 전달 프로세스입니다."
컨트롤 플레인과 데이터 플레인은 네트워킹의 전문 용어지만, 우리는 AWS 내에서 모든 곳에서 이 용어를 사용합니다.
Becky Weiss & Mike Furr
AWS는 실제로 이 용어를 엔지니어링에 적용하고 네트워킹에 의해 설정된 원칙을 적용하여 시스템의 논리적 부분을 분리 했습니다. 분리의 주요 초점은 데이터 제어(컨트롤 플레인)와 데이터 검색(데이터 플레인)을 기반으로 기능을 분리하는 것입니다. 목표는 시스템의 일부가 다운되더라도 고객에게 계속 서비스를 제공할 수 있는 고가용성 시스템을 만드는 것입니다.
컨트롤 플레인과 데이터 플레인
컨트롤 플레인과 데이터 플레인은 로직을 서로 다른 영역으로 분할하는 방법을 설명하는 데 사용되는 네트워킹 용어입니다.
AWS는 이러한 용어를 사용하여 아키텍처를 분할하여 더 많은 처리량을 처리하는 아키텍처 영역에 따라 고가용성 및 목표 확장을 허용하는 방법을 설명했습니다.
컨트롤 플레인과 데이터 플레인의 AWS 용어에 초점을 맞추면 다음과 같습니다.
컨트롤 플레인 - 시스템 변경 사항을 처리합니다. 리소스 생성, 저장, 삭제, 업데이트와 같은 변경 사항을 처리합니다. 컨트롤 플레인은 변경 사항을 전파하는 작업도 처리합니다.
데이터 플레인 - 시스템의 런타임 활동을 처리합니다.
컨트롤 플레인과 데이터 플레인의 예를 들면, 사용자가 다단계 인증(MFA)을 설정하면 컨트롤 플레인이 TOTP 또는 백업 MFA 방법을 데이터베이스에 저장하는 등의 설정을 처리하는 것입니다. 이벤트 스타일 아키텍처를 사용하는 경우 컨트롤 플레인은 새 이벤트나 업데이트된 이벤트를 처리하여 데이터베이스에 전파합니다.
데이터 플레인은 데이터베이스에서 이 정보를 검색하는 작업을 처리합니다.
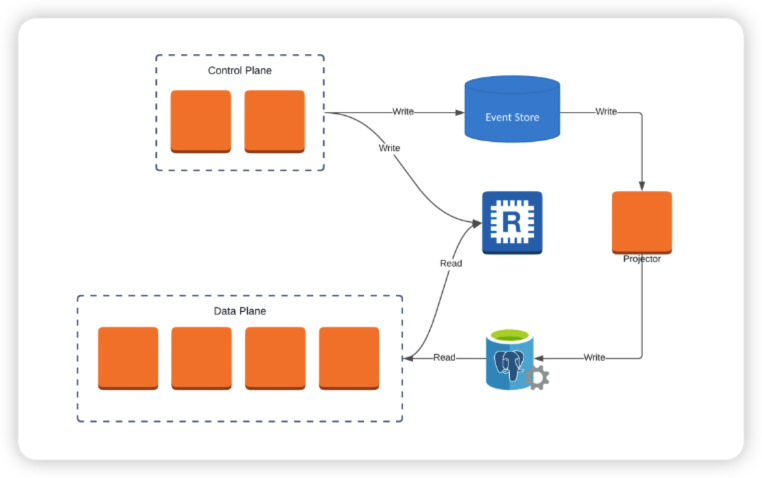
데이터 플레인과 컨트롤 플레인 분리의 장점
고가용성
대부분의 시스템은 고가용성이 필요합니다. 하지만 문제가 발생하면 시스템 성능 저하를 예상하고 계획한 방식으로 시스템을 구축해야 합니다.
"Amazon이 얻은 한 가지 교훈은 장애가 발생하기 전에 예상해야 한다는 것입니다." - Becky Weiss & Mike Furr
애플리케이션 로직을 컨트롤 플레인과 데이터 플레인으로 분리하면 가장 중요한 시스템을 가동하고 실행하는 데 주의를 집중할 수 있습니다. 여기서 가장 중요한 시스템은 데이터 플레인입니다.
컨트롤 플레인은 여전히 안정적이고 가능한 한 가용성을 유지해야 하지만, 서비스가 중단되더라도 데이터 플레인이 컨트롤 플레인이 되어 고객에게 계속 서비스를 제공할 수 있어야 합니다.
컨트롤 플레인은 데이터 플레인보다 움직이는 부분이 더 많은 경우가 많습니다. 컨트롤 플레인은 리소스의 생성, 저장, 삭제, 업데이트를 처리하기 때문입니다. 따라서 컨트롤 플레인은 데이터 플레인이 사용자의 데이터를 검색하는 곳에서 문제가 발생할 위험이 더 높습니다.
AWS는 이 개념을 사용하여 고가용성 시스템을 제공합니다. 종속성이 다운되면 새 리소스나 업데이트된 리소스를 얻지 못할 수 있지만, 시스템은 계속 가동되어 오래된 데이터로도 고객에게 서비스를 제공할 수 있습니다. 참조: https://aws.amazon.com/builders-library/static-stability-using-availability-zones/
스케일링
로직을 데이터 플레인과 컨트롤 플레인으로 분할하면 데이터 플레인이 컨트롤 플레인보다 더 많은 양의 요청을 수신하는 것을 볼 수 있습니다.
이를 바탕으로 이러한 서비스를 독립적으로 확장하여 어떤 엔드포인트와 요청을 기반으로 작업을 확장할 수 있도록 하는 것이 합리적입니다.
컨트롤 플레인 및 데이터 플레인의 단점
컨트롤 플레인과 데이터 플레인은 필요한 상황에서는 훌륭한 아키텍처 입니다.하지만, 저도 직접 경험해 보았지만 필요한 상황이 아니라면 솔루션이 더 복잡해지기 쉽습니다. 이로 인해 솔루션을 개발하기 전에 솔루션을 이해하는 데 걸리는 시간이 늘어날 수 있습니다.
디자인이나 코드가 실제로 일을 단순화하는 대신 더 복잡하게 만들면 과도하게 엔지니어링하는 것입니다.
맥스 카나트-알렉산더
시스템 아키텍처를 결정할 때는 탄탄한 계획을 세워야 합니다. 따라서 컨트롤 플레인과 데이터 플레인 아키텍처 설계 시 다음과 같은 사항이 포함되어야 합니다.
- 기능적 요구 사항과 비기능적 요구 사항 모두에 대한 명확한 이해
- 설계의 각 구성 요소가 수행할 작업 이해
Lucidchart의 게시물 "소프트웨어 아키텍처를 설계하는 방법: 주요 팁과 모범 사례"에서 이 부분에 대해 자세히 알아보세요"
요약
컨트롤 플레인과 데이터 플레인 아키텍처는 가용성이 높고 독립적으로 확장 가능한 서비스를 개발할 때 따라야 할 좋은 방법입니다. 하지만 이 아키텍처를 따르기 전에 반드시 조사하여 구축하려는 솔루션에 적합한 아키텍처 패턴인지 확인해야 합니다.
이 글에 대해 의견이 있으시거나 이전에 비슷한 스타일을 사용해 보신 적이 있으시다면 아래 댓글로 의견을 남겨 주시면 감사하겠습니다.
의견을 남겨주세요