

안녕하세요 주간SaaS 입니다. 2023년 마지막 주간SaaS가 소개하는 아티클은 Emerging Architectures for LLM Applications 입니다. LLM(Large Language Model)을 활용한 애플리케이션을 만들때 필요한 기술 스택, 패턴 그리고 선택지를 다이어그램과 함께 체계적으로 정리한 글 입니다.
개인적으로 저는 LLM이 SaaS의 마진과 이익률을 증가시키는 중요한 요소가 될 것이라고 생각합니다. 반대로 SaaS는 LLM이 비즈니스 모델로서 효과적으로 작동할 수 있게 하는 역할을 할 것입니다. 이 두 요소가 결합된 새로운 서비스와 기능들이 계속해서 등장하는 가운데, LLM을 효과적으로 활용하기 위한 아키텍처 스택, 패턴, 그리고 선택지에 대한 이해는 필수적입니다. 제가 개인적으로 이 주제에 대해 공부할 필요성을 느끼고 있던 찰나에 잘 정리된 글을 발견했습니다. 이 글이 여러분에게도 도움이 되면 좋겠습니다!
마지막으로 지난 6월, 8월에 발행한 Generative AI와 SaaS에 관한 아래 주간SaaS 레터도 함께 보시면 좋을 것 같습니다!
거대 언어 모델(LLM)은 소프트웨어 개발에 강력한 새로운 도구입니다. 하지만 아직은 개발 초기이고 기존 컴퓨팅 자원과는 정말 다르게 작동하기 때문에 어떻게 써야 할지 막막하기도 합니다.
이번 글에서는 떠오르는 LLM 앱 스택을 위한 참조 아키텍처를 공유드립니다. 인공지능 스타트업과 선두 기술 기업들이 사용하는 가장 일반적인 시스템, 도구, 설계 패턴을 담고 있습니다. 이 스택은 아직 초창이며 기반 기술이 발전함에 따라 크게 바뀔 수도 있지만 현재 LLM과 함께 작업하는 개발자들에게 유용한 참조가 될 거라고 기대합니다.
이 작업은 인공지능 스타트업 설립자 및 엔지니어와의 대화를 토대로 진행되었습니다. 특히 Ted Benson, Harrison Chase, Ben Firshman, Ali Ghodsi, Raza Habib, Andrej Karpathy, Greg Kogan, Jerry Liu, Moin Nadeem, Diego Oppenheimer, Shreya Rajpal, Ion Stoica, Dennis Xu, Matei Zaharia, and Jared Zoneraich 도움에 감사드립니다!
스택
현재 버전의 LLM 앱 스택에 대한 오버뷰 입니다.
Emerging LLM App Stack
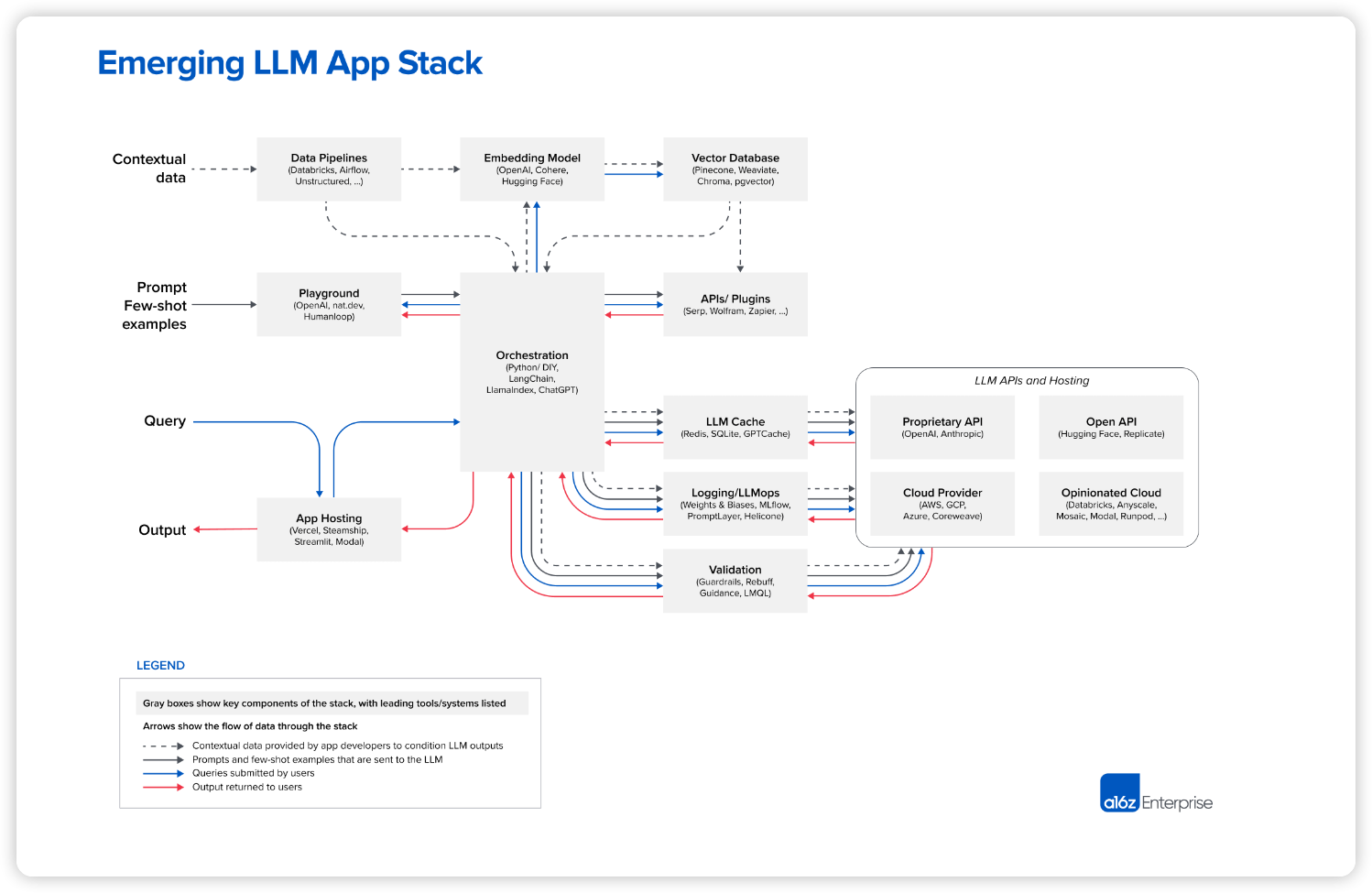
*🐶원문에 가시면 빠르게 참고 할 수 있도록 각 프로젝트의 링크를 확인할 수 있습니다.
거대 언어 모델(LLM)을 활용하는 방법은 여러 가지가 있습니다. 완전히 새로운 모델을 훈련하거나, 공개된 소스 코드 모델을 미세 조정하거나, 호스팅된 API를 사용하는 것도 포함됩니다. 이 글에서 제시하는 스택은 "상황 학습"(in-context learning)이라는 디자인 패턴을 기반으로 합니다. 이 패턴은 대부분의 개발자들이 가장 많이 사용하는 사용하는 방법이고, 최근 파운데이션 모델이 발전하면서 가능해진 기술이기도 합니다.
다음 섹션에서는 이 패턴에 대한 간략한 설명을 제공합니다. 이미 LLM 개발 경험이 있는 분들은 건너뛰셔도 좋습니다.
디자인 패턴: 상황 학습(In-context learning)
상황 학습의 핵심 아이디어는 LLM을 그대로 사용(미세 조정 없이)하면서, 꼼꼼하게 프롬프트를 만들고 비공개 "상황적" 데이터에 대한 조건을 더하여 원하는 결과를 이끌어내는 겁니다.
예를 들어, 법률 문서 세트에 대한 질문에 답변하는 챗봇을 만든다고 가정해보세요. 단순한 방법으로는 모든 문서를 ChatGPT나 GPT-4 프롬프트에 붙여 넣고 질문을 한 후 응답을 받을 수 있습니다. 이 방법은 아주 작은 데이터 세트에는 잘 작동할 수도 있지만 확장성이 없습니다. 가장 큰 GPT-4 모델도 약 50페이지의 입력 텍스트만 처리할 수 있으며, 이 한계에 접근하면 성능(추론 시간 및 정확도)이 크게 저하됩니다.
상황 학습은 이 문제를 똑똑한 방법으로 해결합니다. 모든 문서를 각 LLM 프롬프트와 함께 보내는 대신, 가장 관련성이 높은 몇 개의 문서만 보냅니다. 그리고 가장 관련성이 높은 문서는... 맞습니다... LLM을 사용하여 결정됩니다.
대략적으로 작업 과정은 세 가지 단계로 나눌 수 있습니다.
1. 데이터 전처리/임베딩
이 단계에서는 나중에 검색할 개인 데이터(예시: 법률 문서)를 저장하는 작업이 포함됩니다. 일반적으로 문서는 조각으로 나누어지고 임베딩 모델을 통과한 다음 벡터 데이터베이스라는 특수 데이터베이스에 저장됩니다.
2. 프롬프트 작성/검색
사용자가 질문(이 경우 법률 질문)을 제출하면, 애플리케이션은 LLM에 보낼 일련의 프롬프트를 만듭니다. 완성된 프롬프트는 일반적으로 개발자가 미리 코딩한 프롬프트 템플릿, 유효한 출력 예시(few shot 학습), 필요한 외부 API 정보, 벡터 데이터베이스에서 검색한 관련 문서 세트로 구성됩니다.
3. 프롬프트 실행/추론
프롬프트가 완성되면, 유료 모델 API와 오픈소스/자체 훈련 모델 모두 포함하여 사전 훈련된 LLM에 제출됩니다. 일부 개발자는 이 단계에서 로깅, 캐싱, 검증과 같은 운영 시스템도 추가합니다.
이 작업은 처음에는 많은 작업처럼 보이지만, 실제로 LLM 자체를 훈련하거나 미세 조정하는 것보다 더 쉬운 경우가 많습니다. 상황 학습을 위해 전문 ML 엔지니어 팀이 필요하지 않고, 자체 인프라를 호스트하거나 OpenAI에서 값비싼 전용 인스턴스를 구매할 필요도 없습니다. 이 패턴은 실제로 AI 문제를 데이터 공학 문제로 축소시켜 대부분의 스타트업과 대기업이 이미 해결할 수 있는 방법으로 만듭니다. 또한 비교적 작은 데이터 세트에 대해서도 미세 조정보다 우수한 성능을 발휘하며(LLM이 미세 조정을 통해 정보를 기억하려면 학습 세트에서 특정 정보가 적어도 10회 이상 나타나야 함), 거의 실시간으로 새로운 데이터를 통합할 수 있습니다.
상황 학습에 대한 가장 큰 질문 중 하나는 바로 이거죠. "’컨텍스트 창’ 이란 LLM이 한 번에 처리할 수 있는 정보 양을 말하는데, 그럼 이 창을 늘리면 어떻게 될까?”입니다.
이론적으로 가능하긴 하지만, 쉽지 않은 문제입니다. 현재 연구가 활발히 진행되고 있고 (예시로 Hyena 논문이나 최근 게시물 참고), 기술 발전이 이루어지고 있지만 여전히 어려운 과제 입니다.
가장 큰 문제는 뭘까요? 바로 비용과 속도입니다. 컨텍스트 창을 늘리면 프롬프트 길이가 길어지고, 이에 따라 추론 비용과 시간이 제곱 급으로 늘어나기 때문 입니다. 이론적으로 최적화된 선형 증가라도 현재 API 요금으로는 엄청난 비용이 들게 됩니다. 10,000 페이지짜리 문서에 대한 GPT-4 질문 하나만 해도 수백 달러가 날아가는 거죠. 따라서 컨텍스트 창 확장만으로는 획기적인 변화를 기대하기 어렵습니다. 하지만 이 부분에 대한 더 자세한 내용은 앞으로 계속 다루겠습니다.
궁금한 점이 더 있으신가요? 상황 학습에 대해 더 깊이 알고 싶으신다면 AI 연구 분야의 훌륭한 자료들이 많습니다. 특히 "LLM 활용 실용 가이드" 부분을 참고해보세요. 이 글의 나머지 부분에서는 앞서 소개한 워크플로우를 따라 참조 스택을 살펴보겠습니다.
Data Preprocession/Embedding
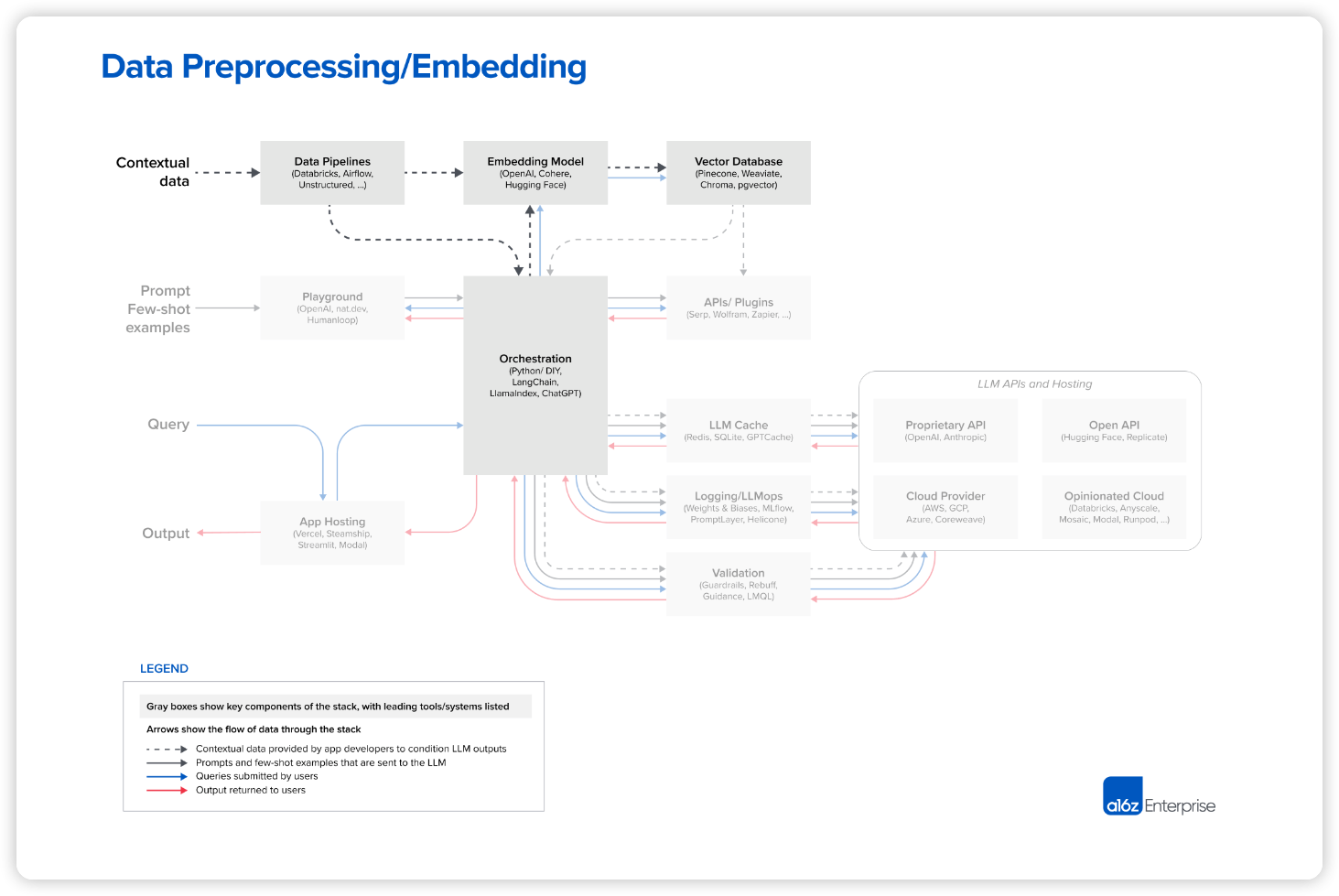
LLM 앱은 텍스트 문서, PDF, 심지어 CSV나 SQL 테이블 같은 구조화된 형식의 데이터로부터 상황적데이터(Contextual data)정보를 얻어 작업합니다. 개발자들 사이에서 이 데이터를 불러오고 변환하는 방법은 매우 다양합니다. 대부분은 Databricks나 Airflow 같은 기존 ETL 도구를 사용하지만, LangChain(Unstructured) 및 LlamaIndex(Llama Hub) 같은 오케스트레이션 프레임워크에 내장된 문서 로더를 사용하는 사람도 있습니다. 하지만 LLM 앱에 맞춤 제작된 데이터 복제 솔루션이 필요하기도 합니다.
임베딩의 경우, 대부분의 개발자들은 OpenAI API를 사용하며 특히 text-embedding-ada-002 모델을 선호합니다. 사용하기 쉽고, 성능도 괜찮으며 점점 가격이 내려가고 있습니다. 일부 대기업은 임베딩에 더 집중하며 특정 시나리오에서 더 뛰어난 성능을 내는 Cohere를 시험하기도 합니다. 오픈소스를 선호하는 개발자라면 Hugging Face의 Sentence Transformers 라이브러리가 표준입니다. 특정 용도에 맞게 다양한 유형의 임베딩을 만드는 것도 가능하지만 현재까지 그렇게 하는 것은 소수에 불과 합니다. 물론 연구가 활발한 분야이기도 합니다.
시스템 관점에서, 전처리 파이프라인의 가장 중요한 부분은 벡터 데이터베이스(vector database)입니다. 수십억 개의 임베딩(벡터)을 효율적으로 저장, 비교, 검색하는 역할을 합니다. 시장에서 가장 일반적인 선택은 Pinecone입니다. 완전히 클라우드 호스팅으로 쉽게 시작할 수 있으며, 성능, 단일 사용자 인증(SSO), 업타임 서비스 수준 계약(SLA) 등 대기업이 필요한 많은 기능을 갖추고 있기 때문입니다.
물론 다양한 벡터 데이터베이스가 존재합니다.
- 오픈소스 시스템 Weaviate, Vespa, Qdrant: 일반적으로 뛰어난 단일 노드 성능을 제공하며 특정 애플리케이션에 맞게 조정할 수 있으므로 맞춤형 플랫폼을 선호하는 경험 많은 AI 팀들이 선호합니다.
- 로컬 벡터 관리 라이브러리 Chroma, Faiss: 개발자의 경험이 충분하고 작은 앱 및 개발 실험을 할 때 쉽게 사용할 수 있습니다. 대규모 서비스를 한다면 완전한 데이터베이스를 대체하기는 어렵습니다.
- OLTP 확장 프로그램 pgvector: 모든 데이터베이스 문제에 Postgres를 적용하는 개발자나 단일 클라우드 공급업체에서 대부분의 데이터 인프라를 구매하는 기업에게 적합합니다. 하지만 장기적으로 벡터 작업과 스칼라 작업을 밀접하게 결합하는 것이 좋을지 여부는 논란이 있습니다.
앞으로 대부분의 오픈소스 벡터 데이터베이스 회사들은 클라우드 서비스를 개발할 것으로 예상됩니다. 하지만 다양한 사용 사례에서 클라우드에서 강력한 성능을 달성하는 것은 어려운 문제입니다. 따라서 단기적으로는 옵션 세트가 크게 바뀌지 않을 수 있지만, 장기적으로는 변화할 가능성이 높습니다. 벡터 데이터베이스가 OLTP 및 OLAP와 유사하게 몇 개의 인기 시스템으로 통합될지 여부가 관심사입니다.
또 다른 관심사는 대부분의 모델에 사용 가능한 컨텍스트 창이 커짐에 따라 벡터화와 벡터 데이터베이스가 어떻게 발전할지 입니다. 컨텍스트 데이터를 프롬프트에 직접 넣을 수 있으므로 벡터화가 덜 중요해질 수도 있습니다. 하지만 전문가들의 의견은 반대입니다. 컨텍스트 창이 커짐은 강력한 도구이지만 많은 계산 비용이 필요합니다. 따라서 효율적으로 활용하는 것이 중요해집니다. 모델 관련성을 위해 직접 훈련된 다양한 유형의 벡터화 모델과 이를 활용하도록 설계된 벡터 데이터베이스가 등장할 수 있습니다.
Prompt Construction/Retrieval
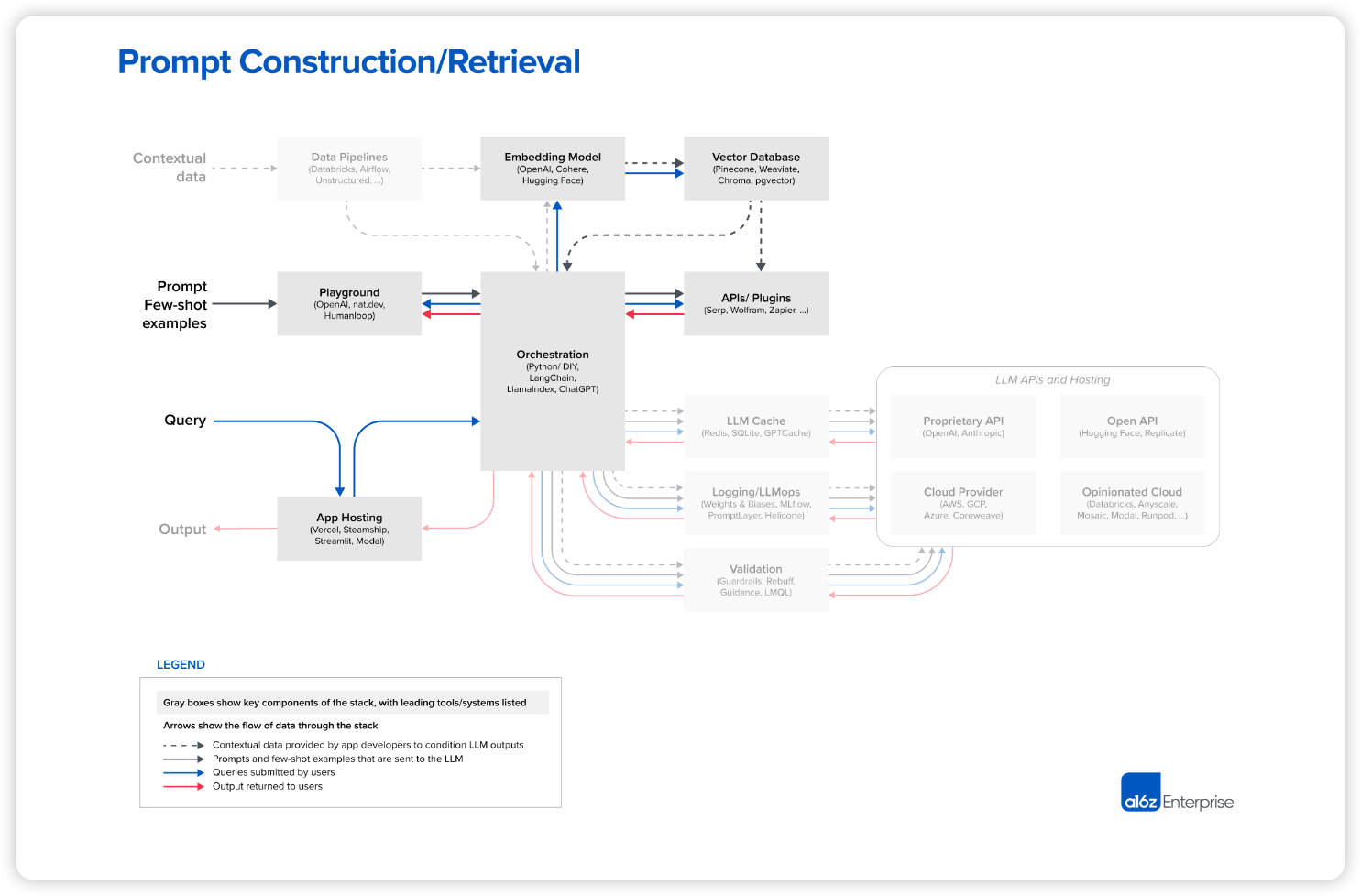
LLM을 활용한 앱 개발에서 프롬프트 작성과 컨텍스트 데이터 활용 기술은 점점 복잡해지고 중요한 차별화 요소로 자리 잡고 있습니다. 대부분의 개발자들은 직접적인 지시문만 담은 간단한 프롬프트(제로샷 프롬프팅) 또는 예시 출력을 추가한 조금 더 복잡한 프롬프트(퓨샷 프롬프팅)로 시작합니다. 이러한 프롬프트는 좋은 결과를 내지만, 실제 서비스에 요구되는 정확성 수준에는 미치지 못할 때가 많습니다.
다음 단계는 LLM의 응답을 "진실의 근원"에 연결하고 모델 훈련 데이터에 포함되지 않은 외부 컨텍스트를 제공하는 것입니다. '프롬프트 엔지니어링 가이드'는 chain-of-thought, self-consistency, generated knowledge, tree of thoughts, directional stimulus 등 무려 12가지의 고급 프롬프트 전략을 소개합니다. 이러한 전략은 문서 질문 응답, 챗봇 등 다양한 LLM 사용 사례에 맞게 결합하여 사용할 수도 있습니다.
바로 이 지점이 LangChain과 LlamaIndex 같은 '오케스트레이션 프레임워크'가 빛을 발하는 지점 입니다. 이들은 프롬프트 연결, 외부 API와의 연동(API 호출 필요 시점 결정 포함), 벡터 데이터베이스에서 컨텍스트 데이터 검색, 여러 LLM 호출 간 메모리 유지 등 복잡한 작업을 간소화합니다. 또한 위에서 언급한 일반적인 응용 프로그램에 대한 템플릿도 제공합니다. 이 프레임워크의 출력은 언어 모델에 제출할 프롬프트 또는 일련의 프롬프트입니다. 이들은 취미 개발자와 앱 개발을 막 시작한 스타트업 사이에서 널리 사용되며 LangChain이 선두를 달리고 있습니다.
LangChain은 아직 비교적 새로운 프로젝트(현재 버전 0.0.201)지만, 이를 사용하여 구축된 앱들이 실제 서비스로 사용되기 시작했습니다. 일부 개발자, 특히 LLM 초기 사용자들은 추가적인 의존성을 없애기 위해 서비스 운영 시 raw Python으로 전환하는 것을 선호합니다. 하지만 웹 앱 스택의 변화와 유사하게, 대부분의 경우 시간이 지남에 따라 이러한 DIY 접근 방식은 줄어들 것으로 예상됩니다.
눈이 예리한 독자라면 위 그림의 오케스트레이션 목록에서 좀 이상하게 보이는 항목을 발견할 수 있습니다: ChatGPT가 포함되어 있습니다. 일반적인 사용에서 ChatGPT는 앱이며 개발자 도구가 아닙니다. 하지만 API로도 접근할 수 있으며, 맞춤형 프롬프트 작성, 상태 유지, 플러그인, API 또는 다른 소스를 통한 컨텍스트 데이터 검색 등 다른 오케스트레이션 프레임워크와 유사한 기능을 수행하기도 합니다. 여기 나열된 다른 도구와 직접적인 경쟁 관계는 아니지만, ChatGPT는 대체 솔루션으로 사용될 수 있고, 결국 프롬프트 작성을 위한 간편하고 실용적인 대안으로 자리 잡을 수도 있습니다.
Prompt Execution/Inference
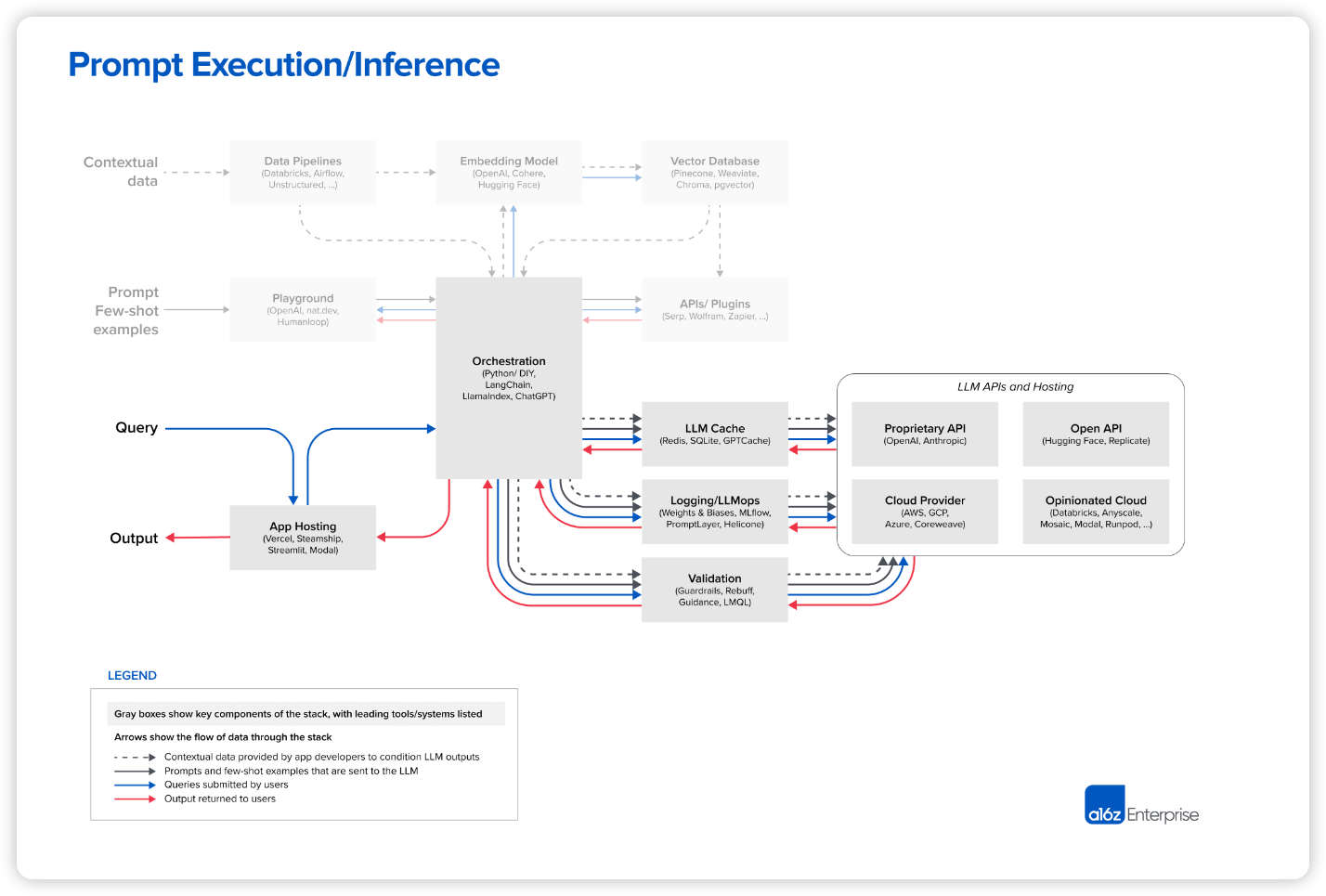
현재 대형 언어 모델(LLM) 분야에서 OpenAI는 선두 주자입니다. 대부분의 개발자들은 새로운 LLM 앱을 시작할 때 OpenAI API를 사용하며, 주로 gpt-4 또는 gpt-4-32k 모델을 선택합니다. 이는 앱 성능을 최적화하는 옵션이며 다양한 입력 영역에서 작동하기 때문에 사용하기 쉽습니다. 대부분 미세 조정이나 자체 호스팅 필요 없이 바로 사용할 수 있습니다.
하지만 프로젝트가 실제 서비스로 들어가서 규모가 커지면 더 다양한 옵션을 고려해야 합니다. 개발자들이 주로 언급한 몇 가지 예시는 다음과 같습니다.
- gpt-3.5-turbo로 전환: GPT-4보다 약 50배 더 저렴하고 훨씬 빠릅니다. 대부분의 앱은 GPT-4 수준의 정확성을 필요로 하지 않지만 낮은 지연 추론과 무료 사용자를 위한 비용 효율적인 지원이 필요합니다.
- 다른 독점 모델을 활용한 실험: Anthropic의 Claude 모델은 빠른 추론, GPT-3.5 수준의 정확성, 대규모 고객을 위한 더 많은 맞춤화 옵션, 최대 10만 개의 컨텍스트 창(하지만 입력 길이가 길어질수록 정확성이 저하됨)을 제공합니다.
- 일부 요청을 오픈소스 모델로 전환: 이는 검색이나 채팅과 같은 높은 처리량을 요구하는 B2C 사용 사례에서 특히 효과적입니다. 쿼리 복잡성이 다양하고 무료 사용자에게 저렴하게 서비스해야 하는 경우 적합합니다.
- Databricks, Anyscale, Mosaic, Modal, RunPod 등의 플랫폼은 오픈소스 모델 미세 조정에 점점 더 많이 사용되고 있습니다. 이 글에서는 이러한 툴 스택에 대해 자세히 다루지는 않지만, 미세 조정이 필요한 경우 참고할 수 있습니다.
- Hugging Face와 Replicate의 간단한 API 인터페이스, 주요 클라우드 공급업체의 컴퓨팅 리소스, 위에서 언급한 것과 같은 클라우드 서비스에서 제공하는 다양한 추론 옵션이 오픈소스 모델에 활용될 수 있습니다.
현재 오픈소스 모델과 상용/독점 모델과의 격차는 좁혀지고 있습니다. Meta의 LLaMa 모델은 오픈소스 정확성의 새로운 기준을 제시하고 다양한 변형 모델을 탄생시켰습니다. LLaMa는 연구용으로만 라이센스되었기 때문에 많은 새로운 공급업체들이 대안 기본 모델 (예: Together, Mosaic, Falcon, Mistral)을 훈련하기 위해 참여했습니다. Meta는 또한 LLaMa 2의 진정한 오픈소스 출시를 검토하고 있습니다.
오픈소스 LLM이 gpt-3.5 수준의 정확성에 도달하면 (필연적으로 도달할 것이라 생각합니다) 텍스트 분야에서 Stable Diffusion과 같은 급격한 발전이 예상됩니다. 이는 미세 조정된 모델의 대규모 실험, 공유, 생산화를 포함합니다. Replicate 같은 호스팅 회사는 이미 이러한 모델을 소프트웨어 개발자가 더 쉽게 사용할 수 있도록 도구를 추가하고 있습니다. 점점 더 많은 개발자들은 특정 사용 사례에서 더 작고 미세 조정된 모델이 최고 수준의 정확성에 도달할 수 있다고 믿고 있습니다.
대부분의 개발자들은 아직 LLM 운영 도구를 깊이 사용하지 않고 있습니다. 캐싱은 보통 Redis를 기반으로 비교적 널리 사용됩니다. 응답 시간과 비용을 개선하는 효과가 크기 때문이죠. Weights & Biases, MLflow (기존 머신 러닝에서 이식)와 같은 도구나 PromptLayer, Helicone (LLM 전용으로 제작)도 꽤 흔하게 사용됩니다. 이들은 LLM 출력을 기록하고 추적하며 평가할 수 있게 해줍니다. 또한 보통 프롬프트 작성 개선, 파이프라인 조정, 모델 선택 같은 목적으로도 사용됩니다. 최근에는 LLM 출력 검증(Guardrails)이나 prompt injection 공격 감지(Rebuff) 같은 새로운 도구들도 개발되고 있습니다. 이런 운영 도구 대부분은 자체 Python 클라이언트 사용을 권장해 LLM 호출을 진행합니다. 앞으로 이런 다양한 솔루션들이 어떻게 공존해 나갈지 흥미롭습니다.
마지막으로, LLM 앱의 웹 자원을(모델을 제외한 모든 부분) 어딘가에 호스팅 해야 합니다. 현재 가장 일반적인 솔루션은 Vercel이나 주요 클라우드 공급업체가 표준 옵션입니다. 하지만 흥미로운 두 가지 새로운 카테고리가 등장하고 있습니다. Steamship 같은 신생 기업은 LangChain 오케스트레이션, 다중 테넌트 데이터 컨텍스트, 비동기 작업, 벡터 저장, 키 관리 등을 포함하여 LLM 앱을 위한 종단 간 호스팅을 제공합니다. Anyscale, Modal 같은 회사들은 개발자들이 모델과 Python 코드를 한 곳에 호스팅할 수 있도록 허용합니다.
What about agents?
이상의 참조 스택에서 빠진 가장 중요한 구성 요소는 AI 에이전트 프레임워크입니다. GPT-4를 완전히 자율적으로 만들기 위한 실험적인 오픈 소스 시도인 AutoGPT는 이번 봄에 역사상 가장 빠르게 성장하는 Github 저장소였으며 현재 현존하는 거의 모든 AI 프로젝트 또는 스타트업은 어떤 형태로든 에이전트를 포함하고 있습니다.
우리와 대화를 나눈 대부분의 개발자들은 에이전트의 잠재력에 대해 매우 흥분하고 있습니다. 이 글에서 설명하는 상황 학습 패턴은 콘텐츠 생성 작업을 더 잘 지원하기 위해 환각 및 데이터 신선도 문제를 해결하는 데 효과적인 반면에, 에이전트는 AI 앱에 복잡한 문제를 해결하고, 외부 세계에 작용하고, 배포 후 경험을 통해 학습하는 등 근본적으로 새로운 기능을 제공합니다. 이들은 고급 추론/계획, 도구 사용, 메모리/재귀/자기 성찰의 조합을 통해 이를 수행합니다.
따라서 에이전트는 LLM 앱 아키텍처의 핵심 부분이 될 가능성이 있습니다(recursive self-improvement까지 가능해진다면 전체 스택을 차지할 수도 있습니다). 그리고 LangChain과 같은 기존 프레임워크는 이미 일부 에이전트 개념을 통합했습니다. 문제는 단 하나입니다. 에이전트는 아직 실제로 작동하지 않습니다. 오늘날 대부분의 에이전트 프레임워크는 개념 증명 단계에 있으며 놀라운 데모가 가능하지만 아직 안정적이고 재현 가능한 작업 완료가 불가능합니다. 그래서 저희는 그들이 가까운 장래에 어떻게 발전하는지 주시하고 있습니다.
앞으로
사전 훈련된 AI 모델은 인터넷 이후 소프트웨어에서 가장 중요한 아키텍처 변화를 대표합니다. 이를 통해 개별 개발자가 수개월이 걸리는 대규모 팀의 지도 학습 프로젝트를 능가하는 놀라운 AI 앱을 며칠 만에 구축할 수 있습니다.
여기에 제시된 도구와 패턴은 LLM을 통합하기 위한 시작점이지 최종 상태가 아닐 것입니다. 주요 변경 사항이 발생하면 업데이트하고 필요할 경우 새로운 참조 아키텍처를 배포 하겠습니다. 혹시 의견이나 제안 사항이 있으시면 언제든지 편하게 연락주세요!
의견을 남겨주세요