
OpenAI 연구원인 노암 브라운박사가 워싱턴 주립대 폴 알렌 공과대학에서 진행하여 2024년 9월 18일 공개된 강연 내용을 리뷰해봤습니다.
노암 브라운 (Noam Brown):
- 현 OpenAI Research Scientist
- OpenAI o1 모델 개발에 참여
- Facebook에 재직하며 Diplomacy 게임을 플레이하는 AI, Cicero를 공동 개발
- 카네기 멜론 대학 컴퓨터 과학 박사
- 카네기 멜론 대학에서 포커를 플레이하는 AI, Libratus와 Pluibus를 공동 개발
계획/탐색의 압도적 성능
- 인공신경망을 더 많은 데이터를 더 많은 컴퓨팅으로 학습시키면 성능은 계속 향상되어 왔음. 업계에서는 이 현상을 확장의 법칙, Scaling Law라고 부름
- 하지만, 인공신경망이 추론을 할 때 생각할 시간을 주면 갑자기 성능이 급격하게 향상되는 현상을 발견
- 여기서 생각할 시간을 준다는 것은 고를 수 있는 선택의 가짓수를 충분히 뽑아보고 각 선택에 대해 평가할 시간을 준다는 의미
- 이 과정을 계획 (Planning) 또는 탐색 (Search)라고 부르는데, 기존 모델이 답을 내기 전에 탐색을 먼저 하게 하면, 모델 크기를 10만배 키웠을 때와 같은 효과를 보게 됨
- AlphaGo Zero 역시 추론 시에 몬테카를로 트리 탐색을 하지 않으면, 프로 바둑 기사들에게 이기지 못함
- 확장의 법칙이 동작하는 것은 맞지만 가성비를 고려해보면, 비싼 장비를 사서 학습시키는 것에 비해 탐색을 시키는 게 훨씬 낫다는 걸 알게 됨
도장깨기


LLM에도 탐색을 적용
- LLM이 수학을 잘 못한다는 사실은 잘 알려져 있음
- 2022년 구글에서 만든 모델 미네르바가 MATH benchmark에서 50% 점수를 얻음
- 구글에서 사용한 기법은 "컨센서스"라는 기법으로, 모델에 같은 질문을 여러번 던져서 돌아오는 대답 중에 자주 반복되는 것을 고르는 방식
- 그 다음으로 제시된 방식은 "Best of N"이라는 방식으로 보상 모델이라는 것을 둬서 먼저 "컨센서스"의 방식으로 N개의 답변을 구한 뒤, 그 중에서 보상 모델이 고르는 최고의 답변 1개를 사용하는 방식
- 여기서 조금 더 나아가서 2023년 OpenAI에서 새로운 방식을 제시했는데 이 방식은 Best-of-N 방식이 최고의 답변 하나를 고르는 방식이었던 것에 반해, 모델이 수행하는 각 작업을 단계별로 평가해서 모든 단계를 정확하게 수행한 답변을 사용하는 방식
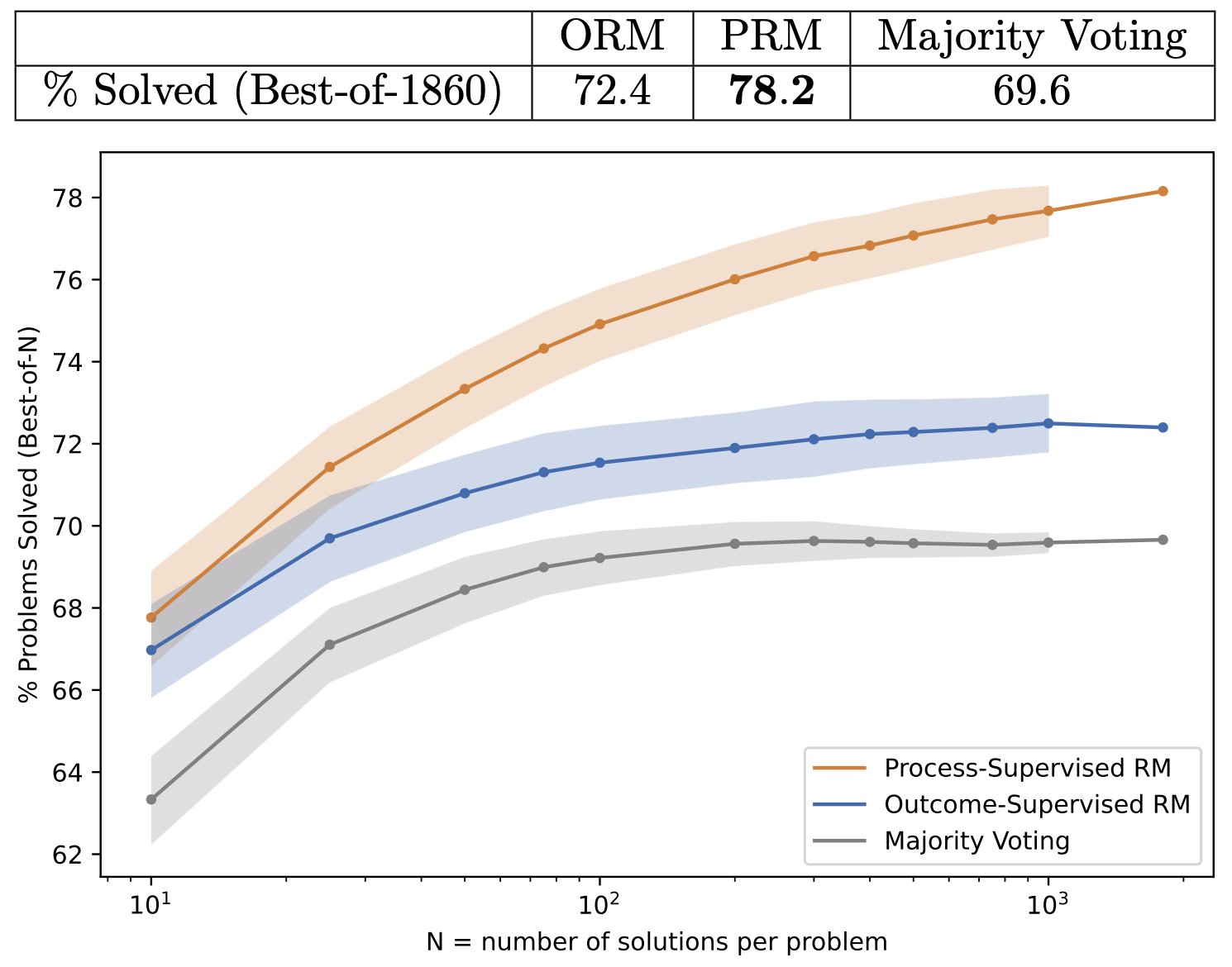
- 2022년 구글 미네르바(컨센서스)가 50% 달성한 벤치마크에서 2023년 OpenAI에서 프로세스 검증 보상 모델을 적용한 모델로 78.2% 달성
- 탐색을 적용하면 LLM에서도 결과가 좋아지는 것을 확인
- 탐색을 적용하면 추론시 시간과 토큰을 많이 소모하는 단점이 있으나, 순수하게 인공신경망과 확장의 법칙에만 기대는 것보다 훨씬 자원을 덜 소모하면서도 높은 결과를 얻을 수 있음
리뷰
최근 다루었던 인터뷰에서 대부분 확장의 법칙에 대한 이야기만 다뤘던 것에 비해 이번 강연은 "탐색"을 다룬 점이 상당히 흥미로웠습니다. 그리고 왜 탐색이 잘 동작하는지에 대한 노암 브라운 박사의 해석도 인상적이었는데요.
인간의 사고과정을 모사하는 것은 인공신경망에게는 쉽지 않은 일입니다. 체스 고수들의 데이터를 가지고 신경망을 학습해도, 신경망은 항상 어느정도 부족한 부분을 보였습니다. 가령 Elo 스코어 2000점 이상의 플레이어들의 플레이를 가지고 학습을 한 모델은 잘해봐야 1700점이 나오는 정도입니다. 이런 패턴을 보이지 않는 경우는 플레이어들이 깊게 사고하지 않고 즉흥적으로 체스를 두는 "총알 체스 (Bullet Chess)" 형식일때 뿐이었습니다. 이때는 사람과 신경망 사이에 큰 차이가 없었습니다. 이를 통해 추측해볼 수 있는 것은 사람의 사고 방식은 매우 복잡해서 신경망이 학습하기 어려운 부분이 있다는 것입니다.
OpenAI 노암 브라운
이것은 다시 2002년 노벨 경제학상 수상자인 대니얼 카너먼 박사의 시스템 1, 시스템 2 분류법과도 일맥상통하는 면이 있습니다. 인간의 생각은 빠르고 얕은 시스템 1과 느리지만 심사숙고하는 시스템 2로 구별할 수 있다는 주장인데요, 그래서 최근 나오는 논문들에는 인공지능에게 시스템 2 생각을 하도록 만들겠다는 주제가 많이 보입니다.
일전에 리뷰했던 안드레이 카파시의 인터뷰에서는 이 부분을 생각의 과정에 대한 데이터가 부족하다는 이야기로 언급이 되었었고요, 프랑소와 숄레의 인터뷰에서는 학습된 패턴들을 얕게 검색해서 답을 준다는 이야기로 언급이 되었었죠. 그리고 2024년 9월, 최초로 시스템 2 생각을 하는 모델 o1이 출시되었죠.
이전까지의 모델은 확장의 법칙에만 기대왔다면, 좀 더 인간의 생각과 가깝게, 그리고 더욱 비용 효율적으로 "탐색"을 추가한 모델이 등장한 것입니다. 추론에 드는 토큰은 훨씬 더 많아졌지만 그 대가로 훨씬 유의미한 답변을 얻는 것이 가능해졌습니다.
학습에 10배 더 많은 컴퓨팅을 할당하면, 추론에는 15배 더 적은 컴퓨팅이 필요합니다. 반대로 추론에 15배 더 많은 컴퓨팅을 할당하면, 10배 더 큰 모델을 학습한 것과 같은 효과를 만들 수 있습니다.
Anthropic 앤디 존스
그리고 그 안에서도 컨센서스 방식, Best-of-N 방식 그리고 프로세스 검증 방식 등으로 점차 탐색을 개선하는 노력이 이루어지듯이 앞으로 나올 모델들은 확장의 법칙을 통한 기본적인 성능 향상에 탐색 방식의 개선을 더한 모델이 될 걸로 예상이 됩니다.
참고자료
- System 2 thinking in OpenAI's o1-preview model: Near-perfect performance on a mathematics exam by OpenAI, 2024
- Let's Verify Step by Step by OpenAI, 2023
- Solving Quantitative Reasoning Problems with Language Models by Google, 2022
- Scaling Scaling Laws with Board Games by Andy L. Jones, 2021
의견을 남겨주세요