
똑똑한 한스라고 혹시 들어보셨나요? 한스는 20세기 초에 독일에서 활동하던 천재적인 말이었는데요, 놀랍게도 독일어를 알아듣고 문제를 풀 줄 알았습니다. 주인이 한스에게 "12 더하기 10이 뭐지?" 하고 물어보면 발굽을 스물두 번 굴러서 대답하는 거예요. 똑똑하지요? 말 주제에 주인이 하는 질문을 알아들은 데다가 덧셈까지 할 줄 알았으니까요.
한스의 주인인 빌헬름 폰 오스텐은 수학 교사였습니다. 이 사람은 자기가 말한테도 수학을 가르칠 수 있다는 사실에 엄청나게 놀라서, 한스를 데리고 독일을 여행하면서 돈을 벌었어요. 한스는 자기 주인이 아닌 사람이 낸 문제에도 대답할 수 있었고, 나중에는 사칙연산보다 어려운 질문에도 대답을 할 수 있었습니다. "25의 제곱근이 뭐지?" 발굽 다섯 번. "3월 1일이 월요일이면, 그다음 주 수요일은 며칠이지?" 발굽 열 번.

당연하지만, 한스는 절대 사람의 말을 알아듣고 문제를 풀어서 대답한 게 아닙니다. 한스는 그냥 눈치가 엄청나게 빠른 거였어요. "16의 제곱근이 뭐지?" 하고 사람이 질문을 하면, 한스는 일단 발굽을 두드리기 시작합니다. 한스가 발굽을 세 번쯤 두드리면 답 근처까지 왔으니까 관중들이 술렁거리겠지요. 그러면 쓱 눈치를 보고서 조금 더 천천히, 한 번 더 발굽질을 합니다. 관중 몇 명이 환호합니다. 아, 여기가 정답이구나! 발굽질을 멈춥니다. 관중이 일제히 환호하고, 주인은 한스에게 맛있는 간식을 상으로 주겠지요.
한스가 똑똑한 건 맞는 것 같죠? 이만큼 눈치가 빠른 사람도 그렇게 많을 것 같지는 않은데 말이에요. 하지만 주인이 원하는 상황은 절대 아니었습니다. 주인은 한스를 훈련해서 독일어를 알아듣고 문제를 풀게 하고 싶었지만 한스가 배운 건 그냥 주변의 눈치를 빠르게 캐치해서 간식을 얻어먹는 법이었으니까요.
이처럼 실험 설계가 잘못되어서 정답의 힌트를 흘려주는 상황을 '똑똑한 한스 효과'라고 부릅니다. 그런데 인공지능 프로그램을 만들 때에도 똑똑한 한스 효과를 조심해야 한다는 연구가 조금씩 나오고 있어요. 오늘은 기계학습 인공지능의 원리를 간단하게 소개하고 '똑똑한 한스 인공지능'이 어떻게 생기는지 설명해 보겠습니다.
1. 기계학습 이해하기
요즘 잘 나가는 인공지능 모델은 거의 100% 기계학습이라는 방법을 통해서 만들어집니다. 기계학습이란 경험이나 데이터를 통해 '개선'될 수 있는 형태의 모든 알고리즘을 말해요. 말 그대로, 어떤 '기계'한테 자료를 잔뜩 보여주면서 '학습'을 시켜서 그럴듯한 일을 하는 성능 좋은 기계를 만들겠다는 이야기입니다.
기계학습 모델을 만들기 위해서는 그래서 두 가지가 필요해요. 첫 번째는 업데이트할 수 있는 부속품을 갖고 있는 프로그램입니다. 보통 '모델'이라고 부르고, 상황에 따라 바꿀 수 있는 숫자인 '학습 가능한 변수'를 잔뜩 갖고 있습니다. 그리고 두 번째는 바로 모델을 학습시킬 수 있는 대량의 데이터예요.
기계학습은 이런 순서로 진행됩니다. 우선, 모델 프로그램과 고양이 사진 100만 장, 강아지 사진 100만 장을 준비합니다. 고양이 사진 50장과 강아지 사진 50장을 뽑아내고 섞어서 100장짜리 묶음을 만듭니다. 이 묶음을 프로그램에게 보여준 다음, 어느 사진이 고양이이고 어느 사진이 강아지인지 맞춰 보라고 시키는 거죠.
처음에 프로그램은 전혀 감을 못 잡고 있을 테니 그냥 덮어놓고 찍을 거예요. 정답률이 50% 근처에서 왔다 갔다 하겠지요? 이제 '얘는 사실 고양이고, 쟤는 사실 강아지'라고 알려주면서 정답률을 높일 수 있는 방향으로 프로그램을 업데이트합니다. 이런 과정을 몇만 번 반복하면 강아지와 고양이를 구분하는 기계학습 프로그램이 만들어지는 거고요.
이렇게 학습된 프로그램은 사실 고양이와 강아지가 어떤 생물인지 전혀 이해할 필요도 없고 그럴 능력도 없습니다. 다만 데이터 내부에 어떤 패턴이 있다면 그걸 인식해서 대답할 뿐이에요. 물론 데이터가 충분히 많이 있다면, 그리고 모델이 충분히 복잡하고 강력하다면 성능 좋은 인공지능 모델이 나오겠지만 까딱 잘못하면 똑똑한 한스처럼 이상한 패턴만 인식하는 프로그램을 만들 수도 있습니다.
2. "똑똑한 한스 인공지능"과 수상쩍은 패턴 인식

아주 극단적인 예시를 하나 들어 보겠습니다. 강아지와 고양이를 구분하는 인공지능을 만들고 싶어서 강아지와 고양이 사진을 잔뜩 준비했는데, 어쩌다 보니 검은 고양이와 흰 강아지 사진밖에 못 구했어요. 사진을 더 구할 시간도 비용도 부족해서 에라 모르겠다 하고 기계학습을 돌립니다. 그러면 어떻게 될까요?

이렇게 훈련한 기계학습 모델은 위의 사진 두 장을 보고 "첫 번째는 고양이, 두 번째는 강아지"라고 대답할 겁니다. 컴퓨터는 사진 자료를 RGB값의 배열로 받아들일 텐데, 강아지와 고양이의 모습이나 자세를 구분하는 것보다 색깔을 구분하는 게 훨씬 쉬우니까요. 귀 모양이나 눈 모양, 취하고 있는 자세의 패턴을 찾는 것보다는 검은색과 흰색을 패턴으로 인식하는 겁니다.
왜 "똑똑한 한스 인공지능"인지 아시겠지요? 훈련용 데이터를 잘 구성해 주지 않으면 기계학습 모델은 쉬운 쪽으로만 찾아갑니다. 검은 고양이와 흰 강아지만 있을 때는 강아지와 고양이를 구분하는 어려운 문제를 풀기보다는 색깔 구분 문제를 푸는 쪽을 선택하는 거죠. 패턴만 찾을 수 있다면 뭐든 신경 쓰지 않는 겁니다.
저는 기계학습 인공지능이 똑똑하지만 게으른 학생이라고 비유하는 걸 좋아해요. 수학 문제를 풀어오라고 숙제를 내 주면 공부해서 문제를 풀려고 하는 게 아니라 혹시 교과서 뒤에 답안지가 붙어있지는 않은지, 검색해서 해답을 찾을 수 있는지부터 찾아보는 학생인 거죠. 문제를 아주 잘 내고 이상한 힌트를 하나도 흘리지 않는다면 결국은 공부를 해서 실력을 쌓겠지만 교사가 조금만 허점을 보이면 바로 꼼수를 쓰는 똑똑한 학생인 겁니다.
3. 이게 정말 문제가 될까?
"검은 고양이, 흰 강아지" 예시는 너무 극단적이라고 생각하실 수도 있어요. 실제로 데이터를 구할 때 저렇게까지 치우친 자료가 모이는 일은 흔치 않을 테니까요. 하지만 기계학습에 사용되는 대규모 데이터에 이런 오류는 생각보다 많이 있습니다. '똑똑한 한스' 인공지능을 분석한 연구논문 한 편을 볼까요?
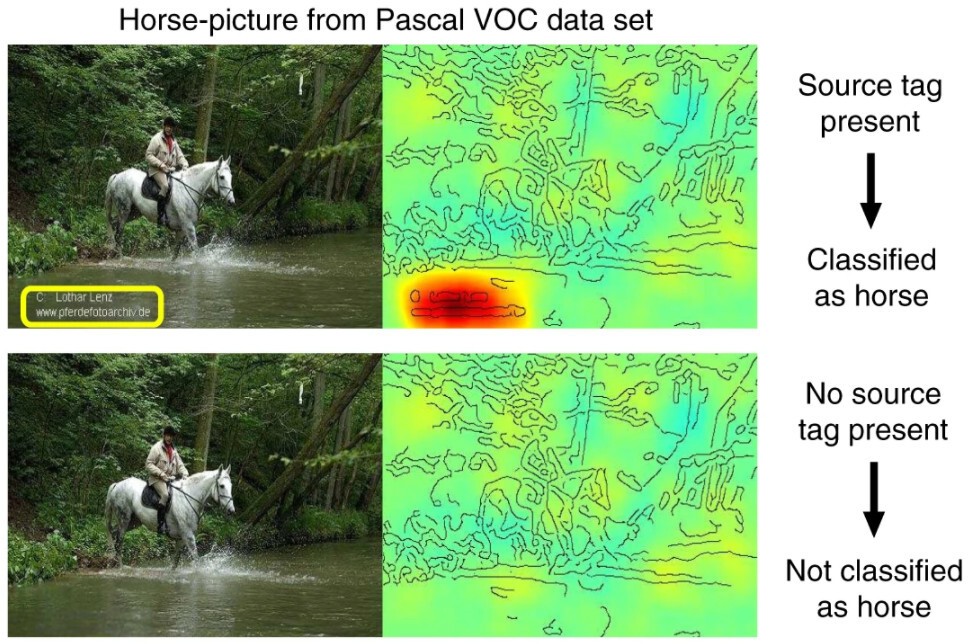
이 논문에서 분석한 그림 자료는 모두 파스칼 시각객체 구분 문제(Pascal VOC)라는 데이터베이스에 등록된 사진입니다. 파스칼 VOC 데이터베이스로 훈련된 프로그램은 위쪽 사진을 보고 '말'이라고 정상적으로 대답을 할 수 있어요. 뭐, 문제 없는 것 같습니다.
그런데 말 사진을 자세히 보면, 사진 구석에 게시자의 이름이 적힌 태그가 붙어 있습니다. 그리고 프로그램이 사진의 어느 부분을 집중적으로 관찰하는지 분석한 그림을 함께 보시면, 태그가 있는 자리에만 빨갛게 집중을 하고 있네요. 이 프로그램은 그러니까 사진에서 말을 보고 '말'이라고 대답한 게 아니고, 사진 구석의 태그를 보고 '말'이라고 대답한 겁니다. 사진에서 태그를 지워버리면 말이 아니라고 대답하기까지 합니다.
왜 이런 일이 생겼을까요? 파스칼 VOC 데이터베이스에 있는 말 사진 중 대략 5분의 1쯤은 구석에 저런 태그를 갖고 있었기 때문이에요. 아마 인터넷에서 사진을 긁어오는 과정에서 특정 사이트의 양식이 섞여들어온 것 같은데, 덕분에 기계학습 프로그램은 똑똑하면서도 게으르게 '구석에 태그가 있는 사진은 말 사진이야'라고 학습을 한 거죠. 얄밉도록 영리하네요.
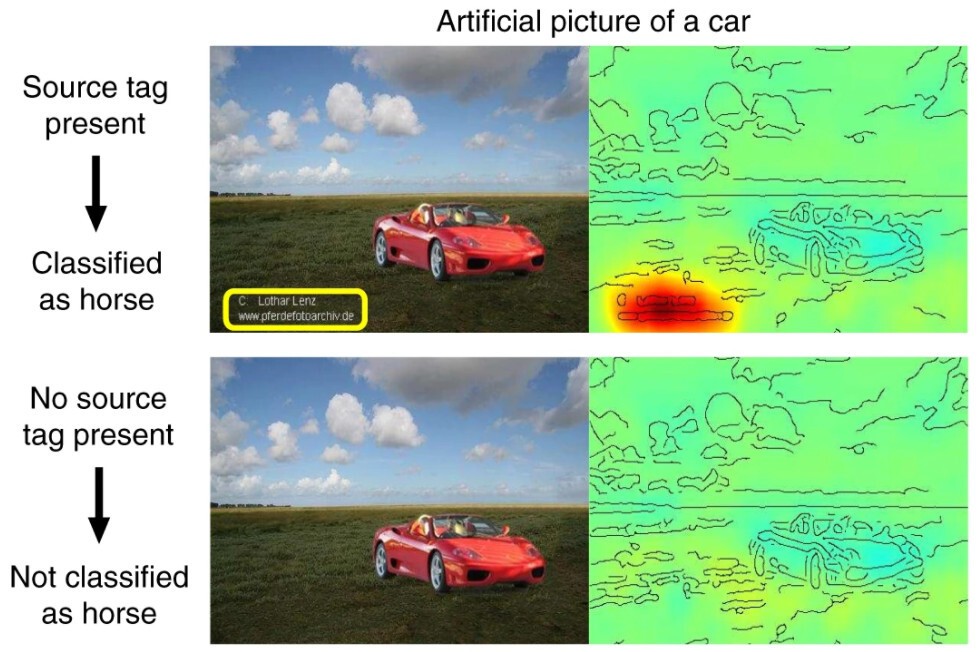
연구진은 아예 태그를 넣은 가짜 사진을 만들어서 프로그램이 어떻게 반응하는지도 확인해 봤는데요, 멀쩡한 자동차 사진 한 구석에 태그를 집어넣으면 이 프로그램은 당당하게도 '말'이라고 대답합니다. 똑똑한 한스랑 하나도 다를 게 없지요?
사실 말을 말이 아니라고 분류하는, 혹은 자동차를 말이라고 분류하는 알고리즘이 있다고 해서 우리에게 큰 문제가 생기지는 않습니다. 하지만 인공지능의 어떤 분야는 까딱 잘못하면 큰 피해를 일으킬 수도 있기 때문에 조심해야 합니다. 자율주행 인공지능이 제때 브레이크를 밟지 못하면 큰 사고가 나겠지요? 하지만 인공지능 알고리즘을 무작정 믿기만 하고 감시하지 않으면 사람이 죽기 전까지 문제를 인식하지 못할 수도 있습니다.
이 논문처럼 딥러닝 인공지능의 작동 원리를 설명하고 이해하려고 하는 연구 흐름을 설명 가능한 인공지능(Explainable AI, XAI)이라고 부릅니다. 최근 몇 년 사이 부쩍 주목받고 있는 연구 방향으로, 인공지능의 성능이 좋더라도 내부 구조를 전혀 이해하지 못한다면 신뢰할 수 없다는 비판이지요. 2021년 4월에는 기계학습에 널리 사용되는 데이터베이스에 상당히 오류가 많다는 연구도 발표되었는데요, AI 기술이 점점 널리 쓰이는 상황을 생각해 볼 때 이처럼 적극적으로 AI의 오류 가능성과 신뢰성을 검증하는 건 아주 중요한 작업이 될 겁니다.
의견을 남겨주세요