

안녕하세요 구독자님. 오늘의 레터는 ChatGPT를 개발한 OpenAI에서 만든 영상 제작 인공지능인 Sora에 대해 전해드리려고 합니다. 인공지능 소라에 대해 이미 알고 계신 분들도 있으실테고 또는 이 레터를 통해 처음 접하시는 분들도 계실 텐데요. 한번 알아볼까요?
What is the Sora?
ChatGPT에게 위 제목과 같이 물었습니다.
"대체 소라(Sora)가 뭐야?"
ChatGPT의 답은 다음과 같았어요.

ChatGPT가 대답한 내용을 토대로, Sora에 대해 자세히 알아볼게요.🔽
🔠Text to Video📺, AI Sora
🔍Sora : 텍스트를 동영상으로 변환해 주는 인공지능 모델
지난 2월 15일, ChatGPT를 만든 OpenAI는 동영상 생성 인공지능을 공개했다. '하늘(Sky)'을 뜻하는 일본어 '소라'(空そら)를 착안하여 네이밍 하였으며, 무한하고 잠재력 있는 의미를 담고 있다. 움직이는 물리적 세계를 이해하고 시뮬레이션하는 인공지능을 지향한다.
Sora는 몇 문장으로 구성된 프롬프트를 입력하면, 최대 1분 분량의 동영상을 생성하여 제공한다.
*프롬프트 : 생성형 인공지능에 질문 또는 지시하는 입력 값
실제로 OpenAI에서 Sora와 함께 공개했던 영상의 프롬프트는 다음과 같다.
Prompt : A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.
프롬프트 : 스타일리시 한 여성이 따뜻하게 빛나는 네온사인과 애니메이션 도시 간판으로 가득한 도쿄 거리를 걷고 있다. 그녀는 검은색 가죽 재킷, 빨간색 긴 드레스, 검은색 부츠를 신고 검은색 지갑을 들고 있다. 그녀는 빨간 립스틱을 바르고, 선글라스를 쓰고 있다. 그녀는 자신감 있고 자연스럽게 걷는다. 거리는 축축하고, 반사되어 화려한 조명의 거울 효과를 만든다. 많은 보행자가 걸어 다닌다.
위 다섯 문장을 입력하자 이를 반영한 영상이 수 초 내에 만들어졌다.
Sora가 만든 영상은 기존 인공지능이 만들었던 제작 영상에 비해 현실과 구분하기 어려울 정도로 더욱 정교하게 제작되어 많은 주목을 받았다.
현재(2024년 4월) 기준, Sora 서비스는 제한된 소수의 전문가 및 창작자에게만 제공되어 안전성 여부를 평가받고 있다.
OpenAI 최고기술책임자는 월스트리트저널(WSJ)과의 인터뷰에서 "올해(2024년 기준) 일반 대중들이 Sora를 이용할 수 있을 것" 이라고 전했다. Sora 서비스가 일반인들에게도 제공되면, 영상 관련 업계에 많은 변화가 예상된다.
전문가들이 경험한 Sora는?
*지난 3월 25일, OpenAI 공식 블로그를 통해 일부 전문가들이 Sora를 이용해 생성한 작품들을 공개했다.
다음은 Sora를 통해 영상을 제작한 전문가들이 Sora에 대해 평가 및 설명한 부분이다.
1. 복수의 캐릭터, 특정한 종류의 움직임, 그리고 대상과 배경의 정확한 세부사항을 포함한 복잡한 장면을 생성할 수 있다.
2. 언어에 대한 깊은 이해를 가지고 있어, 지시를 정확하게 해석하고 생동감 넘치는 감정을 표현하는 매력적인 캐릭터를 생성할 수 있다.
3. 약점이라면, 복잡한 장면의 물리학을 정확하게 모방하는 데 어려움을 겪을 수 있으며, 원인과 결과의 특정한 사례를 이해하지 못할 수 있다. 예를 들면, 사람이 쿠키를 한 입 베어 먹을 수 있지만, 그 후 쿠키에 베어진 자국이 없을 수 있다.
4. Sora는 확산 모델로, 정적 노이즈처럼 보이는 비디오로 시작하여 여러 단계를 거쳐 노이즈를 제거하면서 점차 변환하여 비디오를 생성한다.
5. Sora는 한 번에 전체 비디오를 생성하거나 생성된 비디오를 연장하여 길게 만들 수 있다. 모델에게 한 번에 여러 프레임의 미래를 알려줌으로써, 일시적으로 뷰에서 사라져도 대상이 동일하게 유지되는 문제를 해결했다.
Text to Video, 다른 기업들은?
1. 지난해 11월 메타 AI는 블로그를 통해 ‘에뮤 비디오’를 공개했다. 에뮤 비디오는 텍스트를 입력하면 그림을 그려주고, 지시에 맞춰서 그림이 움직인다. 마크 저커버그 메타 최고경영자(CEO)는 이러한 기능을 인스타그램과 페이스북에 적용할 가능성을 내비쳤다. 현재 이미지 편집 기능에 에뮤 에디트를 추가할 경우 훨씬 편리하게 이미지를 생성할 수 있다.
2. 이미지 생성 엔진 ‘스테이블 디퓨전’을 만든 스태빌리티AI가 지난해 11월 비디오 생성 모델을 내놨고, 이미지 생성 AI로 유명한 미드저니도 ‘텍스트 투 비디오’ 모델을 준비하고 있다.
3. AI 영상 편집툴을 만드는 런웨이ML은 ‘젠-2’라는 동영상 생성 서비스를 제공하고 있다. 실리콘밸리 스타트업인 ‘피카랩스’도 영상 생성 AI 서비스를 공개하면서 지난해 5500만달러의 투자를 받았다.
수십 배 이상 커지는 AI 시장 규모
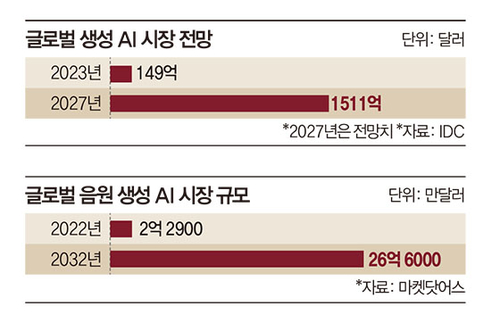
생성형 인공지능은 사용자와 언어로 소통하며 스토리 개요, 보고서 등 텍스트, 이미지, 동영상, 오디오와 같은 멀티 모달 콘텐츠에 이르기까지 완전히 새로운 데이터를 생성할 수 있는 모델이다. 올해 하반기는 AI가 텍스트 기반 채팅을 넘어 음성, 비디오까지 통달하는 멀티 모달 모델로 완전히 대중화될 것으로 예상된다. OpenAI의 최고운영책임자브래드 라이트캡은 “세상을 인식하고 상호작용할 때 우리는 사물을 보고 듣고 말한다”라며 “세상은 멀티모달”이라고 강조했다.
OpenAI가 ‘Sora’를 개발한 이유는 ‘멀티모달’이 AI 대중화를 이끌 것이라는 전망에 기반한 것으로 보인다. 프롬프터에 언어 입력 시, 언어만 생성하는 대규모언어모델(LLM)과 달리 멀티모달 AI는 텍스트, 이미지, 음성, 영상 등을 제한 없이 모두 생성 가능하다.
Generative AI 관련 비케이레터 톺아보기🔍
비케이레터를 운영하면서 종종 인공지능에 관해 전해드렸는데요, 생성형 인공지능의 대표주자 ChatGPT뿐만 아니라 네이버에서 개발한 클로바, 구글의 야심작 Gemini, 그리고 본 레터의 주인공 Sora까지!
혹시 중간에 놓쳤던 콘텐츠가 있다면, 이번 기회에 둘러보시는 것도 좋겠습니다. :)
📍마지막 주(4/29)와 대체공휴일(5/6)은 쉬어 갑니다.
🌸모두 즐겁고 건강한 봄 날 되세요!
의견을 남겨주세요
수은
비공개 댓글 입니다. (메일러와 댓글을 남긴이만 볼 수 있어요)
비케이레터
비공개 댓글 입니다. (메일러와 댓글을 남긴이만 볼 수 있어요)
의견을 남겨주세요