
주간SaaS 오늘의 소개글
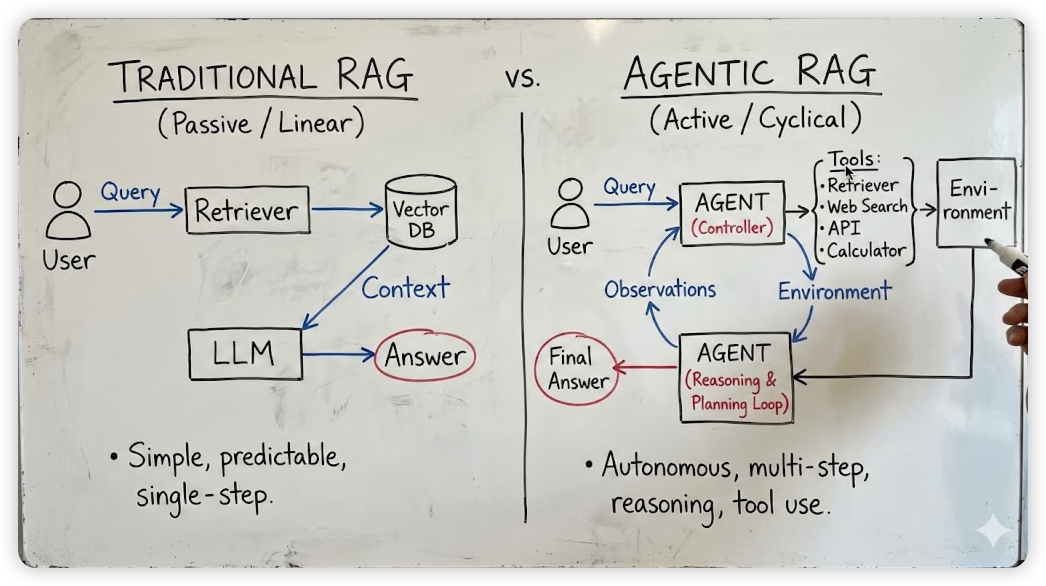
Agentic RAG의 성패는 결국 기존 RAG가 가진 정교한 검색 아키텍처 토대 위에, 이를 LLM이 능동적으로 활용할 수 있는 에이전트 루프를 얼마나 잘 설계하느냐에 달려 있는것 같습니다. 그런 측면에서 프로덕션 수준의 대량 문서 기반 RAG 구축 경험을 다룬 이 글은, RAG를 구성할 때 놓치지 말아야 할 핵심적인 사항들을 짚어내고 있어 많은 공부가 되었습니다.
시간이 되신다면 HN에 달린 다양한 RAG 경험 후기들을 함께 읽어 보셔도 좋을 것 같습니다.
지난 8개월간 RAG(검색 증강 생성) 현장에서 직접 부딪히며, 시간 낭비였던 일과 실제로 효과가 있었던 핵심 노하우를 공유하고자 합니다. 저희는 Usul AI(900만 페이지)와 익명의 법률 AI 기업(400만 페이지)을 위한 RAG 시스템을 구축했습니다.
Langchain과 Llamaindex의 한계
처음에는 유튜브 튜토리얼을 보며 Langchain으로 시작해 Llamaindex로 넘어갔습니다. 며칠 만에 작동하는 프로토타입을 만들었고, 100여 개의 문서로 테스트했을 때는 결과가 훌륭해 보여 낙관적이었습니다. 일주일 만에 전체 데이터를 파이프라인에 돌려 배포까지 마쳤죠.
하지만 실제 결과는 기대 이하였습니다. 오직 최종 사용자만이 그 차이를 느낄 수 있을 정도로 성능이 낮았습니다. 결국 저희는 원하는 성능 수준에 도달할 때까지 몇 달에 걸쳐 시스템을 하나씩 다시 작성했습니다. 다음은 그 과정에서 투자 대비 효율(ROI)이 높았던 순서대로 정리한 내용입니다.
성능 개선을 위해 실제로 유효했던 전략들
1.쿼리 생성 (Query Generation)
사용자의 마지막 질문만으로는 전체 맥락을 다 담기 어렵습니다. 저희는 LLM이 전체 대화 흐름을 검토한 후, 여러 개의 의미론적(Semantic) 쿼리와 키워드 쿼리를 생성하도록 했습니다. 이를 병렬로 처리하고 리랭커(Reranker)에 전달함으로써, 하이브리드 검색 점수에만 의존하지 않고도 훨씬 넓은 범위의 정보를 포착할 수 있었습니다.
2.리랭킹 (Reranking)
단 5줄의 코드로 가장 큰 가치를 만들어낼 수 있는 단계입니다. 리랭킹을 적용하면 청크(Chunk)의 순위가 생각보다 크게 바뀝니다. 설정이 다소 미흡하더라도 충분한 양의 청크를 리랭커에 넘겨주면 성능을 보완할 수 있습니다. 저희는 '50개 입력 -> 15개 출력' 조합이 가장 이상적임을 확인했습니다.
3.청크 분할 전략 (Chunking Strategy)
가장 많은 노력이 들고 시간도 오래 걸리는 작업입니다. 각 기업의 데이터 특성에 맞춰 커스텀 흐름을 구축했습니다. 데이터를 깊이 이해하고 분할된 결과물을 직접 검토하며 다음 두 가지를 반드시 확인해야 합니다.
- 단어나 문장 중간에 어색하게 끊기지 않는가?
- 각 청크가 그 자체로 논리적인 단위이며 독립적인 정보를 담고 있는가?
4.LLM에 메타데이터 전달
처음에는 청크 텍스트만 LLM에 전달했지만, 실험 결과 문서 제목, 저자 등 관련 메타데이터를 함께 주입했을 때 문맥 이해도와 답변 품질이 크게 향상되었습니다.
5.쿼리 라우팅 (Query Routing)
"이 기사를 요약해줘"나 "작가가 누구야?" 같이 RAG 시스템이 굳이 필요 없는 질문들도 많습니다. 저희는 작은 라우터를 만들어, 이런 질문은 복잡한 RAG 과정을 거치지 않고 직접 LLM과 API 호출로 즉시 답변하도록 구성했습니다.
사용된 기술 스택 (Our Stack)
벡터 데이터베이스
벡터 데이터베이스: Azure → Pinecone → Turbopuffer(저렴하며 네이티브 키워드 검색 지원)
문서 추출
자체 제작 (Custom)
청크 분할
기본적으로 Unstructured.io 사용, 기업용은 커스텀 (Chonkie도 추천받음)
임베딩
text-embedding-3-large (다른 모델은 아직 테스트 전)
리랭커
초기 미사용 → Cohere 3.5 → Zerank (덜 알려졌지만 성능이 우수함)
LLM
GPT 4.1 → GPT 5 → GPT 4.1 (Azure 크레딧 활용)
오픈소스 프로젝트
저희의 모든 학습 결과는 MIT 라이선스 하에 오픈소스 프로젝트인 agentset-ai/agentset에 공개해 두었습니다. 궁금한 점이 있다면 언제든 문의해 주세요.
의견을 남겨주세요