
🐧 : 안녕하세요, SaaS 라는 상품을 판매하면서 SLI 와 SLO 를 많이 고민하실텐데요. 이번 시간에는 SLI 와 SLO 를 기반으로 어떻게 배포 체계를 구성할 수 있는 지에 대해 오픈소스인 Keptn 을 바탕으로 설명드려보고자 합니다. Keptn 에서 나온 글이다 보니, Keptn 위주로 설명이 되어 있지만, 이렇게 배포 방식을 가져갈 수 있구나 정도로 이해하시면 좋을 것 같습니다. 원본은 여기서 보실 수 있습니다. ( 품질 게이트 라는 어색한 단어가 많이 나오는데, quality gates 를 의미하며 높은 품질의 배포만 통과시킨다고 생각하면 됩니다. )
Google’s Book on Site Reliability Engineering 라는 책이 있습니다. 이 책을 보면 아래와 같은 개념이 나옵니다.
서비스 수준 지표(SLI) - 예: 서비스 응답 시간의 95번째 백분위수
서비스 수준 목표(SLO) - 예: 최대 부하 시 응답 시간이 200ms를 초과하지 않아야 함
이러한 개념은 조직이 서비스 수준 계약(SLA)을 충족하는지 확인하기 위한 모니터링에 유용합니다. 동일한 개념은 지속적인 배포 파이프라인에서도 사용할 수 있습니다. 좀 더 구체적으로 설명하자면, 조직은 모든 빌드를 SLO에 따라 평가하기 시작하고 빌드를 적용하기 전에, 평과 결과가 품질 게이트 역할을 하도록 합니다.
아래 그림은 4개의 SLI, 해당 SLO 및 각 빌드가 개별 SLO 결과를 기반으로 총점을 받아 품질 게이트를 통과할 수 있을 만큼 충분한지 여부를 결정하는 방법을 보여주고 있습니다.
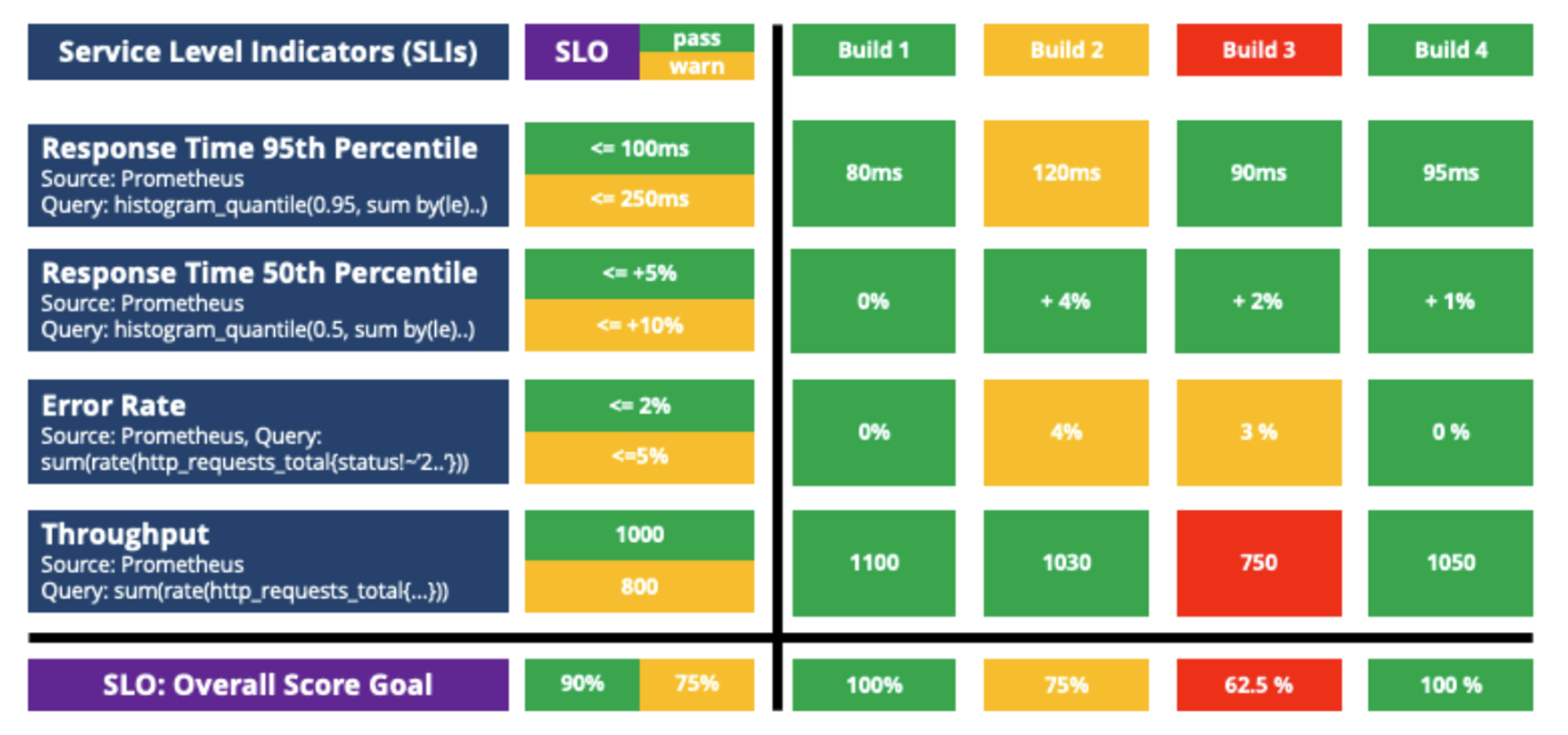
Kubernetes에 워크로드를 배포할 때, SLI에 정의된 값을 캡처하기 위해 Prometheus를 떠올리실 겁니다. 이 구조에는 Prometheus와 같은 데이터 소스에서 모든 SLI를 자동으로 검색하고, SLO에 대해 유효성을 검사하고, 품질 게이트에 사용할 수 있는 전체 점수를 계산하는 구현이 빠져 있습니다.
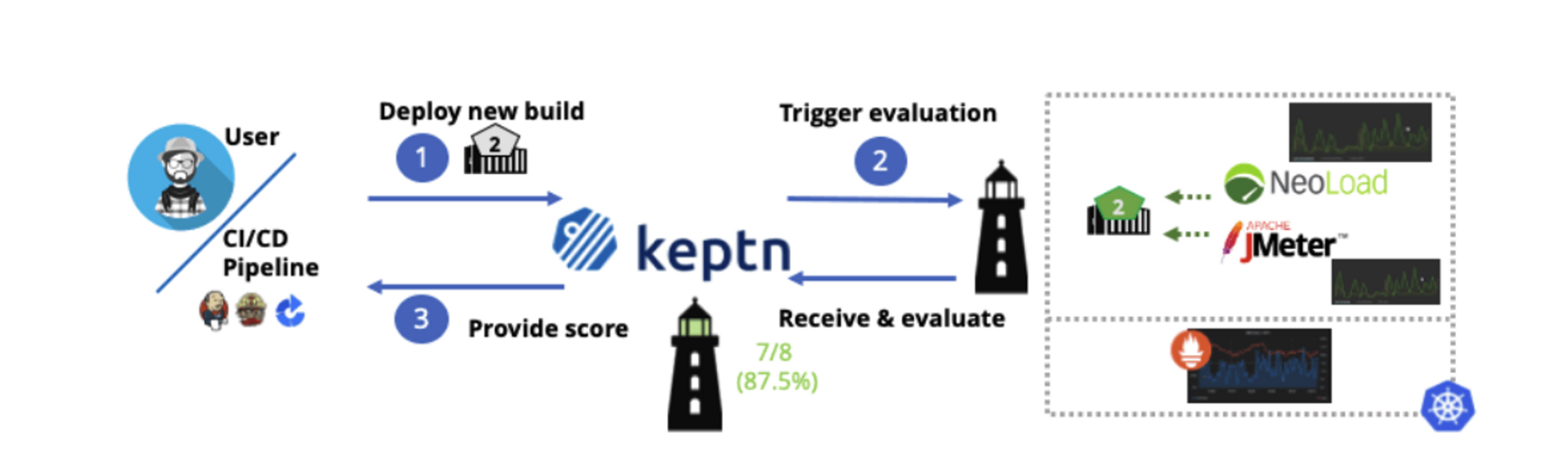
이 구조를 완성하기 위해 이벤트 기반 컨트롤 플레인인 오픈 소스 프로젝트 Keptn을 사용할 수 있습니다. 이 프로젝트의 핵심은 SLI와 SLO를 사용하여 배포 단계 간에 품질 게이트를 적용하고, 블루/그린 배포와 카나리아 배포를 검증하고, 프로덕션 환경의 문제를 자동으로 수정하는 것입니다.
이 글에서는 품질 게이트를 평가하기 위해 Prometheus 기반 SLI와 함께 지속적 배포를 위한 Keptn을 사용하는 방법에 대해 중점적으로 설명합니다. 기존 배포 파이프라인이 있고 품질 게이트만 통합하려는 경우 여기에 있는 예제를 살펴보시기 바랍니다. 자동화 작업과 복구에 관심이 있으시다면 Keptn 웹사이트의 튜토리얼을 살펴보세요.
이제 Keptn으로 Prometheus 기반의 품질 게이트 구축을 시작해 보겠습니다!
Keptn으로 Prometheus 설정 및 구성하기
아직 클러스터에서 실행 중이 아니라면 Keptn을 사용하여 Prometheus를 설정 및 구성할 수 있습니다. 설정 프로세스는 Keptn 웹사이트에 자세히 설명되어 있으며, 기본적으로 다음 단계로 구성되어 있습니다:
Github에서 Keptn CLI를 다운로드하거나 다음 명령어를 통해 다운로드를 시작합니다.
curl -sL <https://get.keptn.sh>; | sudo -E bash
Keptn CLI를 통해 Kubernetes 클러스터에 Keptn을 설치합니다.
keptn install --platform=[gke|aks|eks|openshift|...]
품질 게이트를 설정하려는 애플리케이션에 대한 프로젝트를 생성합니다.
keptn create project sockshop --shipyard=./sockshop.yaml
Keptn으로 관리하려는 서비스를 온보딩하세요.
keptn onboard service shoppingcart --project=sockshop --chart=./shoppingcart
서비스에 대한 Prometheus 구성을 합니다.
keptn configure monitoring prometheus --project=sockshop --service=shoppingcart
이제 Keptn을 설치하고 Prometheus를 구성했으므로 품질 게이트에 대한 SLI와 SLO를 정의할 차례입니다.
품질 게이트 설정
Keptn에서 품질 게이트란 Prometheus와 같은 데이터 제공자로부터 쿼리할 수 있는 임의의 메트릭을 여러 서비스 수준 지표(SLI)로 구성된 서비스 수준 목표(SLO)를 갖는다는 것입니다. Keptn은 실제 API 호출에서 SLI의 값을 검색하는 방법을 추상화하고 SLO가 무엇을 평가해야 하는지에 대한 정의에 중점을 둡니다. 예를 들어 설명해드리겠습니다.
아래의 코드를 보면, Keptn에서 자동으로 평가할 수 있고 다른 단계와 다른 마이크로서비스에 재사용할 수 있는 품질 게이트에 대해서 이해하실 수 있습니다.
품질 게이트 자체는 두 가지 목적을 가지고 있습니다: 1) 서비스 응답 시간의 95번째 백분위 reponse_time_p95와 2) 서비스의 오류율입니다.
응답 시간의 경우 이전 실행 대비 최대 25% 증가와 300ms의 절대 임계값만 허용합니다. 두 기준이 모두 충족되면 이 목표를 달성하게 되어 만점을 받습니다. 경고 기준도 지정할 수 있는데, 이 경우 600ms 범위 내에 있는 경우 경고가 발령되고 목표가 절반의 점수로 평가됩니다.
두 번째 목표는 오류율이 5보다 낮거나 같은 것입니다. 아래 코드에서는 이 기준을 충족하지 못하면 품질 게이트 전체가 실패한다는 의미에서 이를 핵심 SLI로 정의했습니다. 핵심 SLI 를 통해서 비즈니스에 절대적으로 중요한 지표를 관리하고 있으며, 해당 품질 기준이 충족되지 않으면 서비스 출시를 중단해야 합니다.
spec_version: '0.1.1'
comparison:
compare_with: "several_results"
number_of_comparison_results: 3
include_result_with_score: "pass"
aggregate_function: avg
objectives:
- sli: response_time_p95
pass:
- criteria:
- "<=+25%" # relative values
- "<300" # absolute values
warning:
- criteria:
- "<=600"
- sli: error_rate
pass:
- criteria:
- "<=5"
key_sli: true # if not met, evaluation fails
- sli: throughput
- sli: response_time_p50
total_score:
pass: "90%"
warning: "75%"
그렇다면 이 품질 게이트를 어떻게 평가할 수 있을까요? 그 해답은 GitOps 접근 방식과 Keptn에 내장된 기능의 조합에 있습니다.
GitOps 접근 방식에 따라 모든 구성 파일은 Git 리포지토리에서 버전이 제어되고 관리됩니다. 여러 마이크로서비스로 구성된 각 애플리케이션에는 자체 리포지토리가 있으며, 폴더와 브랜치는 서로 다른 환경(개발,운영) 에서 서로 다른 마이크로서비스를 구분하는 데 사용됩니다.
Keptn에는 응답 시간, 장애율, 처리량과 같은 가장 일반적인 서비스 수준 지표(SLI)를 위한 라이브러리가 내장되어 있으며, 이 라이브러리는 쉽게 확장할 수 있습니다. 이 라이브러리를 사용하면 Prometheus 쿼리에 대한 전문가가 아니더라도 SLO를 기반으로 품질 게이트를 작성할 수 있습니다. 또한, 기본 모니터링 도구를 전환하고 다른 소스에서 데이터를 수집하면서도 동일한 품질 게이트를 유지할 수 있습니다.
아래에서 Prometheus 쿼리의 예시를 살펴볼 수 있습니다.
response_time_p95:
histogram_quantile(0.95, sum(rate(http_response_time_milliseconds_bucket{job='<service>-<project>-<stage>-canary'}[<test_duration_in_seconds>s])) by (le))
response_time_p50:
histogram_quantile(0.50, sum(rate(http_response_time_milliseconds_bucket{job='<service>-<project>-<stage>-canary'}[<test_duration_in_seconds>s])) by (le))
error_rate:
sum(rate(http_requests_total{job="<service>-<project>-<stage>-canary",status!~'2..'}[<test_duration_in_seconds>s]))/sum(rate(http_requests_total{job="<service>-<project>-<stage>-canary"}[<test_duration_in_seconds>s]))
throughput:
sum(rate(http_requests_total{job="<service>-<project>-<stage>-canary"}[<test_duration_in_seconds>s]))
품질 게이트 평가
이제 Keptn이 품질 게이트를 평가하는 방법을 살펴보겠습니다: 사용자 또는 CI/CD 도구에 의해 Keptn이 트리거되면 SLI 제공자(이 경우 Prometheus)에 도달하고 품질 게이트에 정의된 모든 SLI가 정해진 시간 동안 쿼리됩니다. 이 시간은 사용자가 정의할 수도 있고, Keptn이 테스트 실행을 트리거하는 경우 테스트 실행 시간 범위가 사용될 수도 있습니다.
다음 Keptn은 절대 임계값 또는 이전 실행과 비교하여 메트릭을 평가합니다. 점수가 생성되면 Keptn은 결과를 클라우드 이벤트(CNCF의 일부인 이벤트 데이터를 공통된 방식으로 설명하기 위한 오픈 소스 사양) 형식으로 반환합니다. 따라서 외부 도구에서도 결과를 처리할 수 있습니다. 배포 유효성 검사에 대한 알림을 받기 위해 Slack, MS Teams 등과도 통합할 수 있습니다.
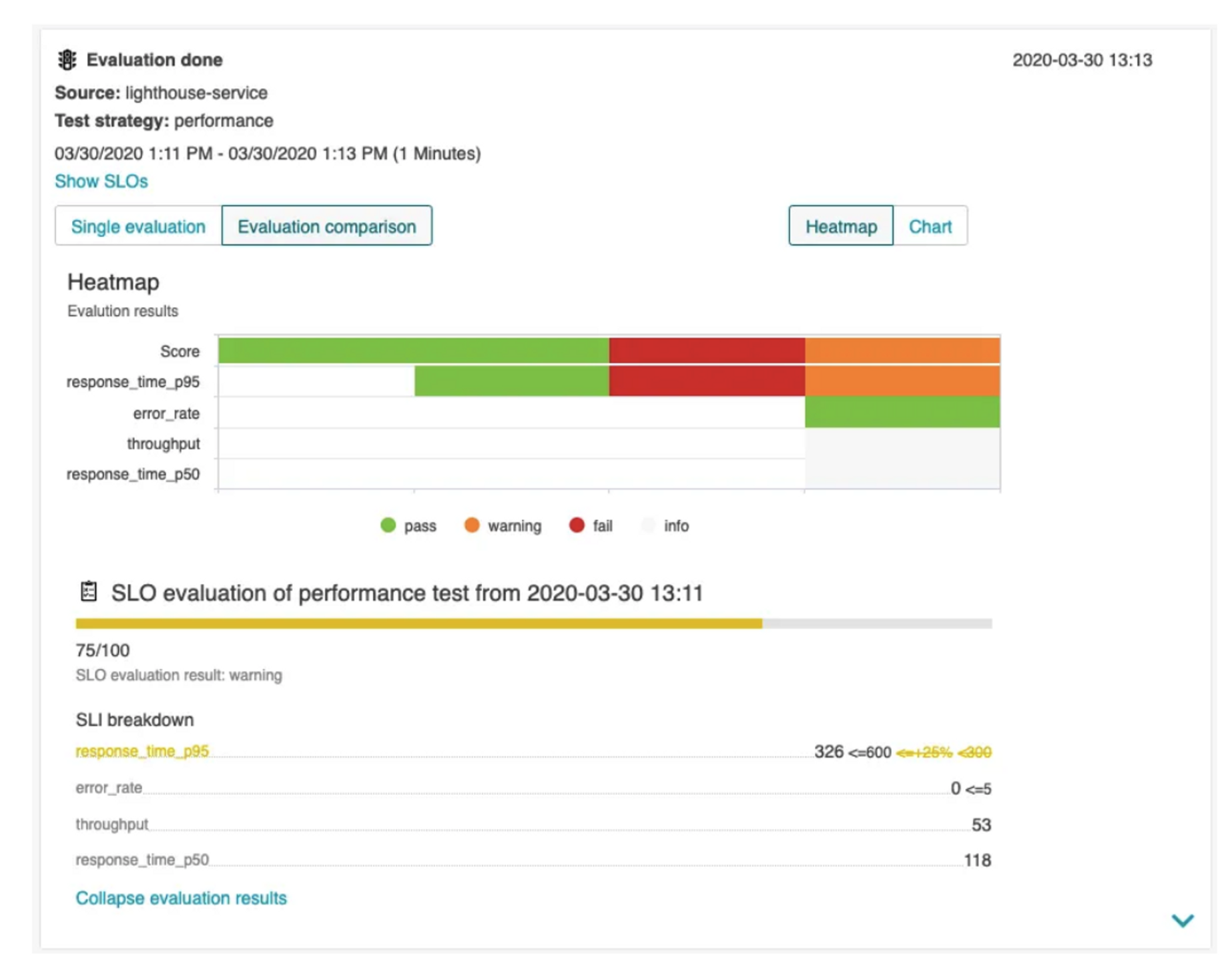
다음 그림에서 볼 수 있듯이 모든 평가 실행 및 결과도 Keptn's Bridge에 시각화됩니다. 아래의 간단한 예시에서는 총 4번의 실행을 트리거하여 1번과 2번은 품질 게이트를 통과했지만 3번은 품질 게이트를 통과하지 못했고(빨간색으로 표시), 4번 빌드는 허용 가능했지만 응답 시간이 품질 검사를 완전히 충족하지 못해 경고가 발생했습니다.
이번 내용, 잘 보셨나요? 실제로 해보고 싶으신 분은 여기 에서 해보실 수도 있고, 관련된 동영상 도 보실 수 있습니다. SLO / SLI 를 배포시점에서부터 파악해서 관리한다는 점에서 SaaS 의 품질을 높히는 데에 큰 도움이 될 것으로 보입니다.





의견을 남겨주세요