
안녕하세요 주간 SaaS 입니다. 주간 SaaS가 소개한 다른 글들도 많지만 오늘 소개 하는 글은 SaaS를 개발하고 계시는 팀들이 꼭꼭꼭 보면 좋겠다는 생각이드는 글 입니다. OLAP 오픈소스 DB로 인기있던 ClickHouse를 1년 내에 as a Service 형태로 개발하고 출시하는 과정에서 선택한 기술 전략과 설계 고민이 모두 담겨 있는 글(Building ClickHouse Cloud From Scratch in a Year) 입니다. 컨트롤플레인 아키텍처, 고가용성에 대한 내용 부터 미터링, 빌링 아키텍처 설계 방향, 마켓플레이스와의 통합까지 모두 담겨 있습니다.내용이 길어서 나누어 소개 할까 하다 뒷 내용이 궁금해 하실것 같아서 한번에 담았습니다.
소개
서버리스 서비스형 소프트웨어(SaaS) 제품을 1년 이내에 구축하는 데 무엇이 필요한지 궁금한 적이 있었나요? 이 블로그 게시물에서는 세계에서 가장 인기 있는 온라인 분석 처리(OLAP) 데이터베이스 기반의 관리형 서비스인 ClickHouse Cloud를 처음부터 어떻게 구축 했는지 설명합니다. 계획, 설계 및 아키텍처 결정, 보안 및 규정 준수 고려 사항, 클라우드에서 글로벌 확장성과 안정성을 달성한 방법, 그 과정에서 얻은 몇 가지 교훈에 대해 자세히 살펴봅니다.
업데이트 및 인터뷰
이 게시물의 인기 덕분에 그동안 받은 몇 가지 질문에 대해 동영상으로 답변할 기회를 만들었습니다.
타임라인 및 마일스톤
저희의 타임라인과 계획 프로세스는 다소 파격적으로 보일 수 있습니다. ClickHouse는 2016년부터 매우 인기 있는 오픈 소스 프로젝트였기 때문에 2021년에 회사를 설립할 당시에는 우리가 구축하는 제품에 대한 수요가 상당히 많았습니다. 그래서 1년 동안 일련의 공격적인 스프린트를 통해 이 클라우드 제품을 구축한다는 공격적인 목표를 세웠습니다.
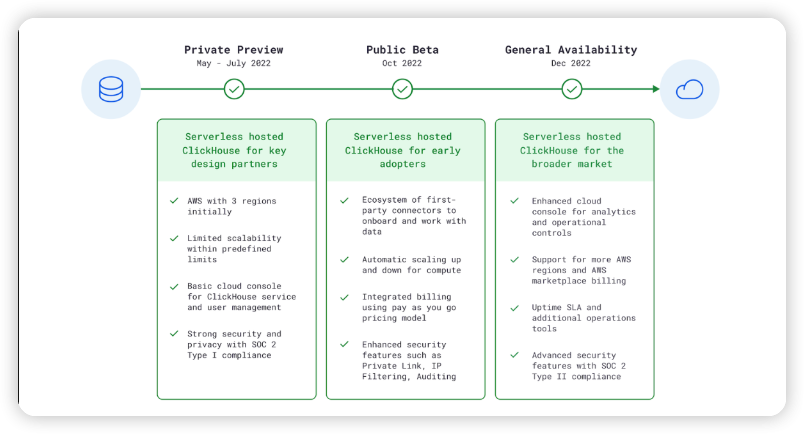
5월에 비공개 프리뷰, 10월에 공개 베타, 12월에 일반 공개 등 마일스톤을 미리 결정한 다음, 각 날짜까지 실현 가능한 것이 무엇인지, 그리고 이를 달성하기 위해 필요한 리소스는 무엇인지 스스로에게 질문했습니다. 각 마일스톤의 우선순위를 정하고 어떤 유형의 프로젝트를 동시에 시작할지 매우 신중하게 결정해야 했습니다. 우선순위를 정할 때는 클라우드 제품 구축 경험, 시장 분석, 초기 클라우드 잠재 고객과의 대화에서 도출된 문제점에 대한 의견을 종합적으로 고려했습니다.
우리는 항상 각 마일스톤에서 너무 많은 일을 하려고 계획한 다음, 도달한 지점을 반복적으로 재평가하고 필요에 따라 목표와 범위를 조정했습니다. 때로는 얼마나 빨리 진전을 이룰 수 있는지 놀랄 때도 있었고(예: 모든 기능을 갖춘 컨트롤 플레인 MVP를 단 몇 주 만에 구축), 때로는 서류상으로는 간단해 보였던 일이 훨씬 더 오래 걸리기도 했습니다(예: 백업은 방대한 데이터 볼륨에서 까다롭습니다). 각 릴리스 마다 기능의 스택 순위를 엄격하게 정하고, 차단해야 할 기능과 꼭 필요한 기능을 명확하게 표시했습니다. 기능을 줄여야 할 때 후회 없이 최 하위에 있는 기능을 삭제할 수 있었습니다.
우리는 현실과 동떨어진 개발을 원하지 않았기 때문에 우리 제품에 관심이 있는 ClickHouse 사용자를 초기에 초대하여 플랫폼을 사용해 보도록 했습니다. 5월부터 7월까지 50명 이상의 잠재 고객과 파트너를 초대하여 서비스를 사용해 볼 수 있는 광범위한 비공개 프리뷰 프로그램을 운영했습니다. 실제 워크로드를 보면서 배우고, 피드백을 받고, 사용자와 함께 성장하는 것이 목표였기 때문에 사용료를 받지 않았습니다.
하지만 처음부터 사용 편의성을 최 우선으로 고려했습니다. 시스템에서 생성된 초대, 셀프 서비스 온보딩, 자동화된 지원 워크플로 등 온보딩 프로세스를 최대한 원활하게 만드는 데 중점을 두었습니다. 동시에 각 비공개 미리 보기 사용자가 직접 Slack 채널을 이용할 수 있도록 하여 고객의 목소리를 직접 듣고 모든 문제를 효율적으로 해결할 수 있도록 했습니다.
ClickHouse Cloud의 아키텍처
우리의 목표는 모든 개발자나 엔지니어가 분석 데이터베이스에 대한 깊은 지식 없이도, 그리고 인프라를 명시적으로 크기 조정하면서 관리 필요 없이 곧바로 사용할 수 있는 클라우드 제품을 구축하는 것이었습니다.
그래서 '분리된 스토리지와 컴퓨팅'을 갖춘 '모든 것을 공유하는' 아키텍처를 채택했습니다. 이는 기본적으로 스토리지와 컴퓨팅이 분리되어 있으며 별도로 확장할 수 있다는 것을 의미합니다. 분석 데이터의 기본 저장소로 Amazon S3와 같은 객체 스토리지를 사용하고 캐싱, 메타데이터, 임시 저장소로만 로컬 디스크를 사용합니다.
아래 다이어그램은 ClickHouse Cloud의 논리적 "모든 것을 공유하는" 아키텍처를 나타냅니다.
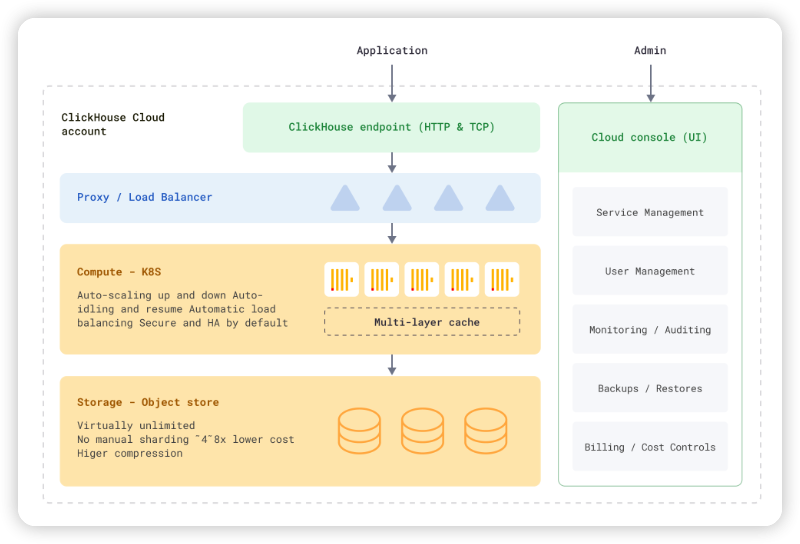
이 아키텍처를 선택한 이유는 다음과 같습니다:
- 클러스터/스토리지의 크기를 미리 정할 필요가 없고, 물리적으로 데이터를 샤딩할 필요가 없으며, 배포를 확장하거나 축소할 때 노드 간에 데이터를 재조정할 필요가 없고, '아무것도 공유하지 않는' 아키텍처의 고정된 컴퓨팅/스토리지 비율로 인해 컴퓨팅 리소스가 유휴 상태로 남아 있지 않기 때문에 데이터 관리가 크게 단순 해졌습니다.
- 또한 벤치마킹과 실제 워크로드 실행 경험을 바탕으로 이 아키텍처가 분석 워크로드 유형에 대해 가장 경쟁력 있는 가격 대비 성능을 제공한다는 사실을 알게 되었습니다.
이런 방향을 선택함으로써 발생하는 추가 작업도 있었습니다:
- 개체 저장소 지연 시간은 로컬 디스크보다 느리기 때문에 분석 쿼리를 빠르게 유지하기 위해 개체 저장소 위에 스마트 캐싱, 병렬 액세스 및 프리페칭에 투자해야 했습니다.
- 개체 저장소 액세스(특히 쓰기)는 비용이 많이 들기 때문에, 얼마나 많은 파일을 얼마나 자주 쓰는지, 그리고 그 비용을 최적화하는 방법을 면밀히 검토해야 했습니다. 이러한 노력이 전반적인 안정성과 성능 개선에도 도움이 된 것으로 나타났습니다.
ClickHouse 클라우드 구성 요소
ClickHouse Cloud는 두 개의 서로 다른 독립적인 논리 단위로 볼 수 있습니다:
- 컨트롤 플레인 - "사용자 대면" 레이어입니다: 사용자가 클라우드에서 작업을 실행하고, ClickHouse 서비스에 대한 액세스 권한을 부여하며, 데이터와 상호 작용할 수 있도록 하는 UI 및 API 입니다.
- 데이터 플레인 - "인프라 대면" 부분: 리소스 할당, 프로비저닝, 업데이트, 확장, 로드 밸런싱, 다른 테넌트로부터 서비스 격리, 백업 및 복구, 가시성, 미터링(사용 데이터 수집) 등 물리적 ClickHouse 클러스터를 관리 및 오케스트레이션하는 기능입니다.
다음 다이어그램은 ClickHouse 클라우드 구성 요소와 그 상호 작용을 보여줍니다.
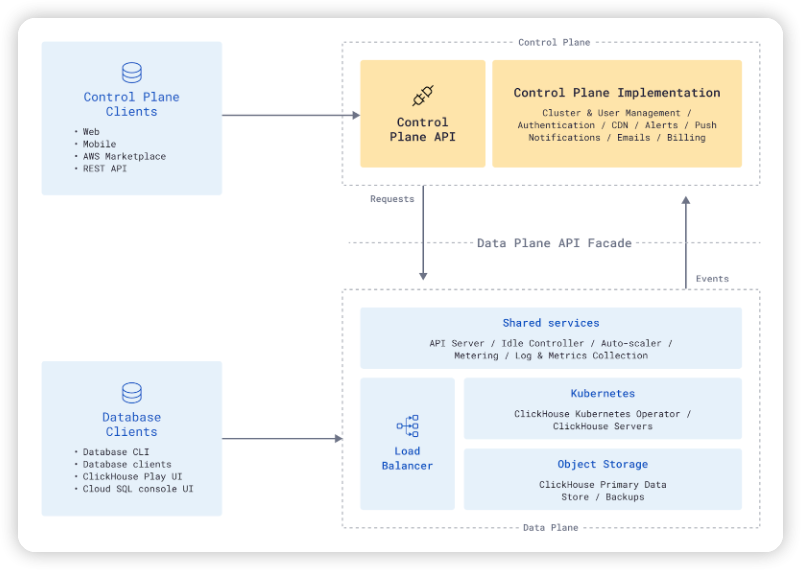
컨트롤 플레인과 데이터 플레인 사이의 양방향 API 계층은 두 플레인 간의 유일한 통합 지점을 정의합니다. 다음과 같은 이유로 REST API를 사용하기로 결정했습니다:
- REST API는 사용되는 기술에 독립적이므로 컨트롤 플레인과 데이터 플레인 간의 종속성을 피하는 데 도움이 됩니다. 데이터 플레인의 언어를 파이썬에서 골랑으로 변경해도 컨트롤 플레인에는 아무런 변경이나 영향이 없었습니다.
- 다양한 서버 구성 요소를 독립적으로 발전시킬 수 있는 뛰어난 유연성을 제공합니다.
- 서버가 이전 요청과 독립적으로 모든 클라이언트 요청을 완료하는 요청의 상태 비저장 특성으로 인해 효율적으로 확장할 수 있습니다.
클라이언트가 데이터 플레인과의 상호 작용이 필요한 작업(예: 새 클러스터 생성 또는 현재 클러스터 상태 가져오기)을 수행하면 컨트롤 플레인에서 데이터 플레인 API로 호출이 이루어집니다. 데이터 플레인에서 컨트롤 플레인으로 전달해야 하는 이벤트(예: 클러스터 프로비저닝, 데이터 이벤트 모니터링, 시스템 알림)는 메시지 브로커(예: AWS의 SQS 큐 및 GCP의 Google Pub/Sub)를 사용하여 전송됩니다.
이 API의 구체적인 구현은 데이터 플레인 내부의 여러 구성 요소에 있습니다. 이는 소비자에게 투명하게 공개되므로 "데이터 플레인 API 파사드"가 있습니다. 데이터 플레인 API가 수행하는 작업 중 일부는 다음과 같습니다:
- ClickHouse 서비스 시작/중지/일시 중지
- ClickHouse 서비스 구성 변경 노출된 엔드포인트(예: HTTP, GRPC)엔드포인트 구성(예: FQDN)
- 노출된 엔드포인트(예: HTTP, GRPC)
- 엔드포인트 구성(예: FQDN)
- 엔드포인트 보안(예: 비공개 엔드포인트, IP 필터링)
- 기본 고객 데이터베이스 계정 설정 및 비밀번호 재설정 ClickHouse 서비스에 대한 정보 얻기엔드포인트에 대한 정보(예: FQDN, 포트)
- ClickHouse 서비스에 대한 정보 얻기
- 엔드포인트에 대한 정보(예: FQDN, 포트)
- VPC 페어링에 대한 정보 ClickHouse 서비스에 대한 상태 정보 얻기
- ClickHouse 서비스에 대한 상태 정보 얻기
- 프로비저닝, 준비됨, 실행 중, 일시 중지됨, 성능 저하됨
- 상태 업데이트를 위한 이벤트 구독
- 백업 및 복원
멀티 클라우드
컨트롤 플레인은 AWS에서 실행되지만, 데이터 플레인을 Google Cloud와 Microsoft Azure를 비롯한 모든 주요 클라우드 제공업체에 배포하는 것이 목표입니다. 데이터 플레인은 클라우드 서비스 공급자(CSP)의 특정 로직을 캡슐화하고 추상화하므로 컨트롤 플레인은 이러한 세부 사항에 대해 걱정할 필요가 없습니다.
처음에는 AWS에서 프로덕션 빌드아웃을 시작하고 GA로 전환했지만, 주요 CSP별 문제를 조기에 파악하기 위해 Google Cloud Platform(GCP)에서 PoC 작업을 동시에 시작했습니다. 예상대로 AWS 특정 구성 요소에 대한 대안을 찾아야 했지만, 일반적으로 그 작업은 점진적으로 잘 진행되었습니다. 저희의 주요 관심사는 다른 클라우드 공급업체로 이전할 때 S3 기반에서 컴퓨팅과 스토리지를 분리하는 데 얼마나 많은 작업이 필요한지였습니다. 다행히도 GCP에서는 Google Cloud Storage(GCS)를 기반으로 S3 API 호환성을 통해 큰 이점을 얻을 수 있었습니다. S3에서의 개체 저장소 지원은 인증과 관련된 몇 가지 차이점을 제외하고는 대부분 "그냥 작동"했습니다.
디자인 결정 사항
이 섹션에서는 몇 가지 디자인 결정 사항과 선택 이유를 살펴보겠습니다.
Kubernetes vs VM
확장, 재스케줄링(예: 충돌 발생 시), 모니터링(활성도/준비도 프로브), 기본 제공 서비스 검색, 로드 밸런서와의 손쉬운 통합을 위한 기본 제공 기능으로 인해 초기에 컴퓨팅 인프라로 Kubernetes를 선택하기로 결정했습니다. Kubernetes의 Operator 패턴을 사용하면 클러스터에서 발생하는 모든 이벤트에 대한 자동화를 구축할 수 있습니다. 업그레이드가 더 쉬워지고(애플리케이션 및 노드/OS 업그레이드 모두) 100% 클라우드에 구애받지 않습니다.
kOps vs 관리형 Kubernetes
우리는 클러스터 자체에 대한 관리 부담을 덜어주기 때문에 AWS의 EKS(및 다른 클라우드 제공업체의 유사한 서비스)와 같은 관리형 Kubernetes 서비스를 사용합니다. 저희는 프로덕션 준비가 완료된 Kubernetes 클러스터를 위한 인기 있는 오픈 소스 대안인 kOps를 고려했지만, 소규모 팀에서는 완전 관리형 Kubernetes 서비스가 시장 출시 속도를 높이는 데 도움이 될 것이라고 판단했습니다.
네트워크 격리
Cilium을 사용하는 이유는 특히 서비스 수가 많을 때 높은 처리량, 낮은 지연 시간, 적은 리소스 소비를 제공하는 eBPF를 사용하기 때문입니다. 또한 Google GKE 및 Azure AKS를 포함한 3대 클라우드 제공업체 모두에서 잘 작동한다는 점도 선택에 중요한 요소였습니다. Calico도 고려했지만, eBPF가 아닌 iptables를 기반으로 하고 있어 성능 요구 사항을 충족하지 못했습니다. 미묘한 차이와 장단점을 이해하는 데 도움이 된 몇 가지 기술적 세부 사항과 벤치마크에 대해 자세히 설명하는 Cilium의 블로그 게시물이 있습니다.
데이터 플레인 API 서버를 위한 Lambda vs Kubernetes
ClickHouse Cloud를 시작할 때 빠른 개발 시간을 제공하는 AWS Lambda를 사용하여 데이터 플레인 API 계층을 구축했습니다. 이러한 구성 요소에는 serverless.com 프레임워크를 사용했습니다. 베타 및 GA 출시를 준비하면서 Kubernetes에서 실행되는 Golang 앱으로 마이그레이션하면 코드 배포 시간을 단축하고 ArgoCD와 Kubernetes를 사용하여 배포 인프라를 간소화할 수 있다는 것이 분명해졌습니다.
로드 밸런서 - AWS NLB와 Istio 비교
비공개 프리뷰에서는 서비스당 하나의 AWS 네트워크 로드 밸런서(NLB)를 사용했습니다. AWS 계정당 NLB 수가 제한되어 있기 때문에, 공유 인그레스 프록시에 Istio와 Envoy를 사용하기로 결정했습니다. Envoy는 범용 L4/L7 프록시이며 쉽게 확장하여 MySQL 및 Postgres와 같은 특수 프로토콜을 위한 다양한 기능을 제공할 수 있습니다. Istio는 가장 널리 사용되는 Envoy 컨트롤 플레인 구현입니다. 두 프로젝트 모두 오픈소스로 공개된 지 5년이 넘었습니다. 시간이 지남에 따라 상당히 성숙해졌고 업계에서 잘 채택되고 있습니다.
Istio 프록시는 서버 이름 표시기(SNI)를 사용하여 트래픽을 다른 서비스로 라우팅합니다. 공인 인증서는 cert-manager와 Let's Encrypt를 통해 프로비저닝되며, 별도의 Kubernetes 클러스터를 사용하여 프록시를 실행하면 클러스터를 확장하여 트래픽 증가를 수용하고 보안 문제를 줄일 수 있습니다.
비동기 통신을 위한 메시지 브로커
우리는 데이터 플레인 내부의 통신과 컨트롤 플레인과 데이터 플레인 간의 통신 모두에 SQS를 사용합니다. 클라우드에 구애받지 않지만 설정이 간단하고 구성이 간편하며 비용도 저렴합니다. SQS를 사용하면서 출시 기간이 단축되고 아키텍처의 이 부분에 대한 관리 오버헤드가 감소했습니다. 대체 클라우드 구축을 위해 Google Pub/Sub와 같은 다른 대안으로 마이그레이션하는 데 드는 노력도 최소화할 수 있습니다.
기본 저장소로 Object Store
앞서 언급한 바와 같이, 저희는 기본 데이터 저장소로 오브젝트 스토어(예: AWS의 S3 또는 GCP의 GCS)를 사용하고 캐싱 및 메타데이터에는 로컬 SSD를 사용하고 있습니다. 오브젝트 스토리지는 무한대로 확장 가능하고 내구성이 뛰어나며 대량의 데이터를 저장할 때 훨씬 더 비용 효율적입니다. 오브젝트 스토어에 데이터를 정리할 때 처음에는 논리적 ClickHouse 서비스별로 별도의 S3 버킷을 사용했지만 곧 AWS limits 에 부딪히기 시작했습니다. 그래서 버킷의 하위 경로를 기반으로 서비스를 분리하고 별도의 역할/서비스 계정을 유지하여 데이터 보안을 보장하는 공유 버킷으로 전환했습니다.
인증 및 자격 증명
저희는 초기에 컨트롤 플레인이나 데이터베이스 자격 증명을 서비스에 저장하지 않기로 결정했습니다. 저희는 고객 신원 및 액세스 관리(CIAM)를 위해 Amazon Cognito를 사용하며, 컨트롤 플레인 계정을 설정할 때 자격 증명이 유지되는 곳입니다. 새 ClickHouse 서비스를 시작할 때 온보딩 중에 자격 증명을 다운로드하도록 요청하며 세션 이후에는 저장하지 않습니다.
확장성 및 안정성
확장성
서비스 성능에 영향을 주지 않으면서 사용자 트래픽 증가를 처리할 수 있도록 제품을 원활하게 확장할 수 있기를 원했습니다. Kubernetes를 사용하면 컴퓨팅 리소스를 쉽게 확장할 수 있고, 자동 장애 조치 및 자가 복구 기능을 통해 애플리케이션의 고가용성을 보장하며, 이식성이 가능하고, 스토리지 및 네트워크와 같은 다른 클라우드 서비스와 쉽게 통합할 수 있습니다.
자동 확장(Auto-scaling)
자동 확장을 통해 다양한 워크로드 패턴을 지원하는 것이 중요한 목표였습니다. 스토리지와 컴퓨팅이 분리되어 있기 때문에 각 워크로드의 사용률에 따라 CPU와 메모리 리소스를 추가 및 제거할 수 있습니다.
자동 확장은 idler와 scaler라는 두 가지 구성 요소를 사용하여 구축됩니다. idler는 현재 쿼리를 처리하지 않는 서비스에 대해 파드를 일시 중단하는 역할을 합니다. scaler는 서비스가 현재 쿼리 믹스 및 속도에 대응하여 효율적으로 작동할 수 있는 충분한 리소스를 확보(범위 내)하도록 하는 역할을 담당합니다.
ClickHouse idling의 설계는 Knative의 activator 패턴을 밀접하게 따르는 사용자 정의 구현 형태 입니다. 프록시(Envoy)가 Kubernetes 운영자와 긴밀하게 통합되어 있기 때문에 Knative에 필요한 일부 구성 요소를 제거할 수 있습니다.
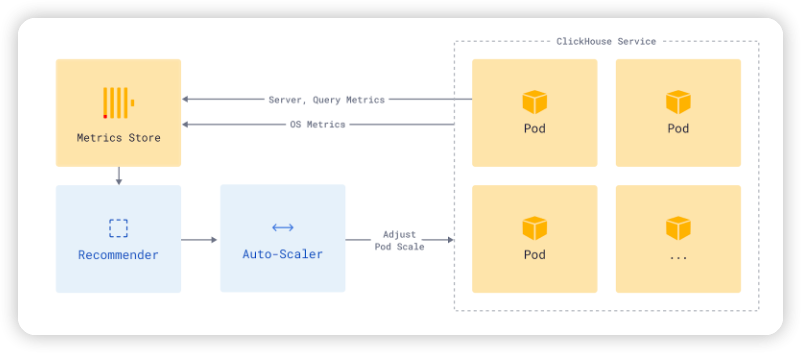
idler는 다양한 서비스 파라미터를 모니터링하여 파드의 대략적인 시작 시간을 결정합니다. 이러한 매개변수를 기반으로 유휴 기간을 계산하고 이 계산된 기간 동안 요청을 받지 않을 때 서비스에 할당된 컴퓨팅 파드의 할당을 해제합니다.
ClickHouse auto scaler는 수직 및 수평 자동 스케일러와 같은 쿠버네티스 에코시스템의 자동 스케일링 구성 요소와 작동 방식이 매우 유사합니다. 하지만 두 가지 주요 측면에서 이러한 상용 시스템과 다릅니다. 첫째, 클라우드 에코시스템에 긴밀하게 통합되어 있습니다. 따라서 운영 체제, ClickHouse 서버의 메트릭과 쿼리 사용량의 일부 신호를 사용하여 서비스에 할당해야 할 컴퓨팅 양을 결정할 수 있습니다. 둘째, stateful 서비스를 실행하는 데 필요한 중단 예산을 보다 강력하게 제어할 수 있습니다.
30분마다 이러한 신호의 과거 및 현재 값을 기반으로 서비스에 할당해야 하는 리소스의 양을 계산합니다. 이 데이터를 사용하여 서비스에 대한 리소스를 추가할지 축소할지 결정합니다. auto scaler는 시작 시간 및 사용 패턴과 같은 요소를 기반으로 최적의 변경 시점을 결정합니다. 더 많은 입력을 통합하고 더 정교한 예측을 수행하여 이러한 권장 사항을 더 빠르고 더 나은 것으로 만들기 위해 계속 반복하고 있습니다.
신뢰성(Reliability)
데이터는 비즈니스에 매우 중요하며, 오늘날과 같은 시대에 인프라 서비스에서 다운타임은 그 누구도 용납할 수 없습니다. ClickHouse Cloud는 내부 구성 요소 장애로부터 신속하게 복구하고 시스템의 전체 가용성에 영향을 미치지 않도록 보장하는 기본 제공 기능을 갖춘 고가용성이 필요하다는 것을 일찍부터 알고 있었습니다. 클러스터 구성 일체는 프로덕션 서비스를 위한 3개의 가용 영역(AZ)과 개발 서비스를 위한 2개의 AZ에 Pod가 분산되어 클러스터가 영역 장애로부터 복구할 수 있도록 구성됩니다. 또한 한 리전에서의 중단이 다른 리전의 서비스에 영향을 미치지 않도록 여러 리전을 지원합니다.
하나의 클라우드 계정에서 리소스 제한에 부딪히지 않도록 데이터 플레인에 cellular architecture를 도입했습니다. "Cell"은 서로 독립적으로 작동하는 독립적이고 자율적인 단위로, 전체 서비스에 대해 높은 수준의 내결함성과 복원력을 제공합니다. 이를 통해 필요에 따라 데이터 플레인 cell을 추가로 가동하여 트래픽과 수요 증가에 대응하고, 필요한 경우 서로 다른 서비스를 분리할 수 있습니다.
성능 벤치마킹
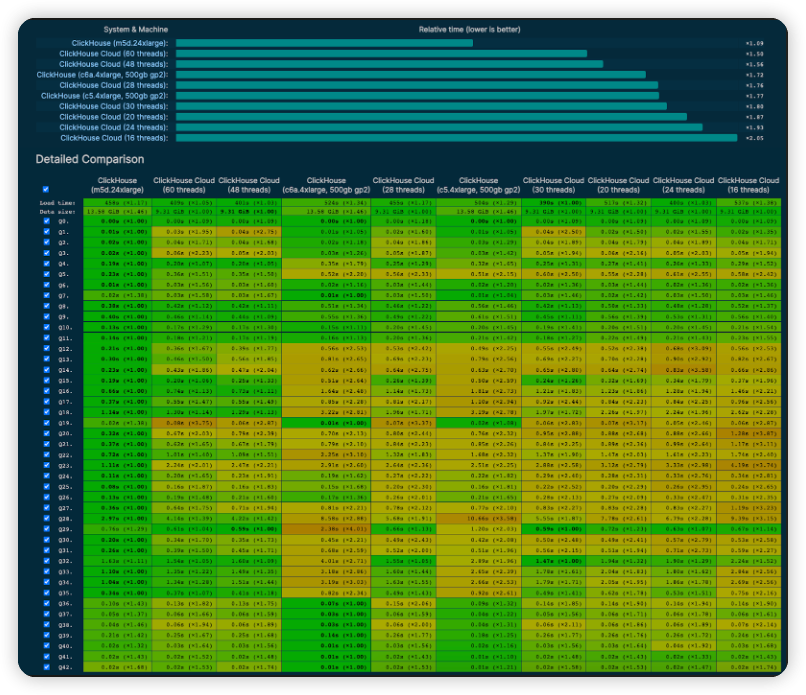
클라우드 서비스를 구축하는 과정에서 핵심 팀은 내부적으로 사용하던 분석 벤치마크를 오픈소스로 공개했습니다. 이 벤치마크를 클라우드 환경과 버전 전반에서 실행하는 주요 성능 테스트 중 하나로 채택함으로싸 다양한 구성, 클라우드 제공업체 환경 및 버전 전반에서 데이터베이스의 성능을 더 잘 이해했습니다. 베어메탈 및 로컬 SSD에 비해 오브젝트 스토리지에 대한 액세스가 느릴 것으로 예상되었지만, 병렬화, 프리페칭 및 기타 최적화를 통해 대화형 성능과 튜닝된 성능을 기대하고 있습니다(밋업 강연에서 ClickHouse로 오브젝트 스토리지에서 100배 빠르게 읽는 방법을 참조하세요).
주요 업데이트가 있을 때마다 결과를 업데이트하고 벤치마크 사이트(benchmarks.clickhouse.com)에 공개적으로 게시합니다. 아래 스크린샷은 아무것도 공유하지 않는 구성에서 다양한 크기의 몇 가지 자체 관리 설정과 ClickHouse 클라우드 서비스 성능을 비교한 것입니다. 여기서 가장 빠른 기준은 쿼리 실행에 48개의 스레드를 사용하는 AWS m5d.24xlarge 인스턴스에서 실행되는 ClickHouse 서버입니다. 보시다시피, 48개의 스레드를 사용하는 동급의 클라우드 서비스는 벤치마크에 표시된 다양한 단순하고 복잡한 쿼리에서 매우 우수한 성능을 발휘합니다.
보안 및 규정 준수
처음부터 제품에 대한 신뢰를 구축하는 것이 매우 중요했습니다. 저희는 고객이 맡긴 데이터를 보호하기 위해 3단계 접근 방식을 취합니다.
보안 구축
GDPR, SOC 2, ISO 27001과 같은 규정 준수 프레임워크와 CIS와 같은 보안 구성 표준을 활용하여 제품의 각 계층을 구축했습니다. 인터넷 연결 서비스는 웹 애플리케이션 방화벽으로 보호됩니다. 컨트롤 플레인과 데이터베이스뿐만 아니라 모든 내부 서비스 및 시스템에도 강력한 인증이 적용됩니다. 새로운 서비스가 생성되면 구성 표준이 일관되게 적용되도록 보장하는 코드형 인프라를 통해 배포됩니다. 여기에는 AWS ID 및 액세스 관리(IAM) 역할, 트래픽 라우팅 규칙, 가상 사설망(VPN) 구성부터 전송 중 및 미사용 시 암호화와 기타 보안 구성에 이르기까지 여러 항목이 포함됩니다. 내부 보안 전문가가 각 구성 요소를 검토하여 서비스가 안전하고 규정을 준수하면서 효율적이고 효과적으로 운영될 수 있도록 보장합니다.
지속적인 모니터링
보안과 규정 준수는 일회성 구현으로 끝나는 것이 아닙니다. 저희는 취약성 스캔, 침투 테스트, 보안 로깅 설정, 경고를 통해 환경을 지속적으로 모니터링하고 있으며, 업계 연구자들이 bug bounty program을 통해 잠재적인 문제를 보고하도록 장려하고 있습니다. 또한 프로덕션 환경, 기업 시스템, 공급업체를 2차 방어선으로 포함하는 200개 이상의 개별 점검을 통해 지속적인 규정 준수 모니터링을 실시하여 기술 및 프로세스 중심 프로그램을 성실히 이행하고 있습니다.
시간이 지남에 따라 개선
업계 동향이나 고객 요청에 따라 새로운 보안 기능을 지속적으로 추가합니다. ClickHouse 데이터베이스에는 강력한 인증 및 암호화, 유연한 사용자 관리 RBAC 정책, 할당량 및 리소스 사용 제한 설정 기능 등 다양한 고급 보안 기능이 이미 내장되어 있습니다. 제어 영역에서 강력한 인증, 기본 데이터베이스 계정에 대한 강력한 암호 자동 생성, 전송 중 및 미사용 데이터 암호화 기능을 갖춘 클라우드 프라이빗 프리뷰를 출시했습니다. 공개 베타에서는 IP 액세스 목록, AWS 프라이빗 링크 지원, Google을 통한 연합 인증, 컨트롤 플레인 활동 로깅을 추가했습니다. GA에서는 컨트롤 플레인을 위한 다단계 인증을 도입했습니다. 보다 전문적인 사용 사례와 산업을 지원하기 위해 더 많은 보안 기능이 추가될 예정입니다.
전반적으로 각 클라우드 제공업체에 대한 표준 보안 모범 사례를 사용하고 있습니다. 저희는 클라우드 환경에서 실행되는 모든 구성 요소에 대해 최소 권한 원칙을 따릅니다. 프로덕션, 스테이징 및 개발 환경은 서로 완전히 격리되어 있습니다. 각 리전 또한 다른 모든 리전과 완전히 격리되어 있습니다. AWS S3, RDS, Route53, SQS와 같은 클라우드 서비스에 대한 액세스는 모두 엄격한 제한이 있는 IAM 역할과 IAM 정책을 사용합니다.
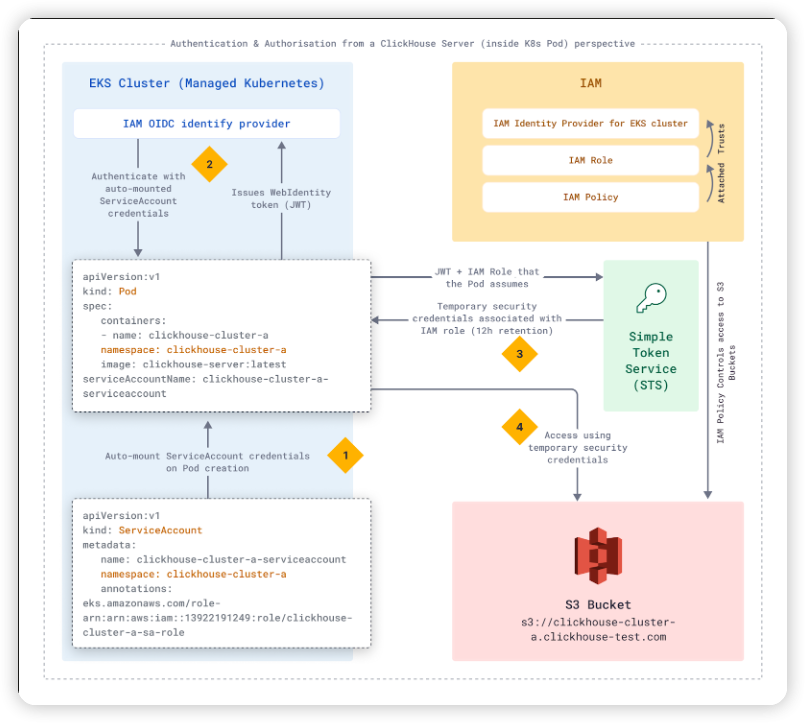
예를 들어, 다음 다이어그램은 고객 데이터를 저장하는 S3 버킷에 액세스하기 위해 EKS IAM OIDC ID 공급자 및 IAM 역할/정책을 사용하는 방법을 보여줍니다. 각 고객에게는 전용 IAM 역할에 매핑되는 service account가 있는 격리된 Kubernetes 네임스페이스가 있습니다.
- EKS는 pod 생성 시 ServiceAccount 자격 증명을 자동으로 마운트합니다.
- pod는 service account 자격 증명을 IAM OIDC 공급자에 대해 사용한다.
- pod는 제공된 JWT와 IAM 역할을 사용하여 STS(Simple Token Service)를 호출한다.
- STS는 pod에 IAM 역할과 연관된 임시 보안 자격 증명을 제공한다.
저희는 다른 서비스에 액세스해야 하는 모든 컴포넌트에 대해 이 패턴을 사용합니다.
고객 데이터를 처리하는 구성 요소는 네트워크 계층에서 서로 완전히 격리되어 있습니다. 저희의 클라우드 관리 구성 요소는 보안 위험을 줄이기 위해 고객 워크로드에서 완전히 격리되어 있습니다.
가격 책정 및 청구
가격 모델을 결정하고 이후 미터링 및 청구 파이프라인을 구현하는 데 약 6개월이 걸렸으며, 이후 고객 피드백을 바탕으로 베타 및 GA를 거치면서 반복적으로 개선했습니다.
사용량 기반 요금 모델
저희는 사용자들이 서버리스 서비스 사용 방식에 맞는 사용량 기반 요금 모델을 원한다는 것을 알고 있었습니다. 여러 가지 모델을 고려한 끝에 최종적으로 소비된 스토리지와 컴퓨팅을 기반으로 하는 간단한 리소스 기반 요금 모델을 결정했습니다.
다른 차원에 따른 가격 책정도 고려했지만, 각 모델에는 사용자에게 적합하지 않은 주의 사항이 있었습니다. 예를 들어, 읽기/쓰기 작업에 대한 가격 책정은 이해하기 쉽지만, 단일 쿼리가 매우 간단하거나(한 열에 대한 단순 집계) 매우 복잡할 수 있는(여러 집계 및 조인을 포함하는 다단계 선택) 분석 시스템에는 실용적이지 않습니다. 스캔한 데이터의 양에 따라 가격을 책정하는 것이 더 적절하지만, 다른 분석 시스템 사용자들로부터, 이러한 유형의 가격 책정은 매우 징벌적이어서 우리가 원하는 것과는 정반대로 시스템 사용을 억제한다는 사실을 알게 되었습니다! 마지막으로, 불투명한 '워크로드 단위'를 기준으로 가격을 책정하는 방안도 고려되었지만, 결국 이해하기 어렵고 신뢰하기 어렵다는 이유로 폐기되었습니다.
미터링 및 청구 엔진
저희는 컴퓨팅 사용량(분당)과 스토리지(15분당)를 기준으로 요금을 부과하기 때문에 실시간 사용량 지표를 표시하고 특정 한도를 초과하지 않도록 모니터링하기 위해 이러한 차원의 실시간 사용량을 추적해야 했습니다.
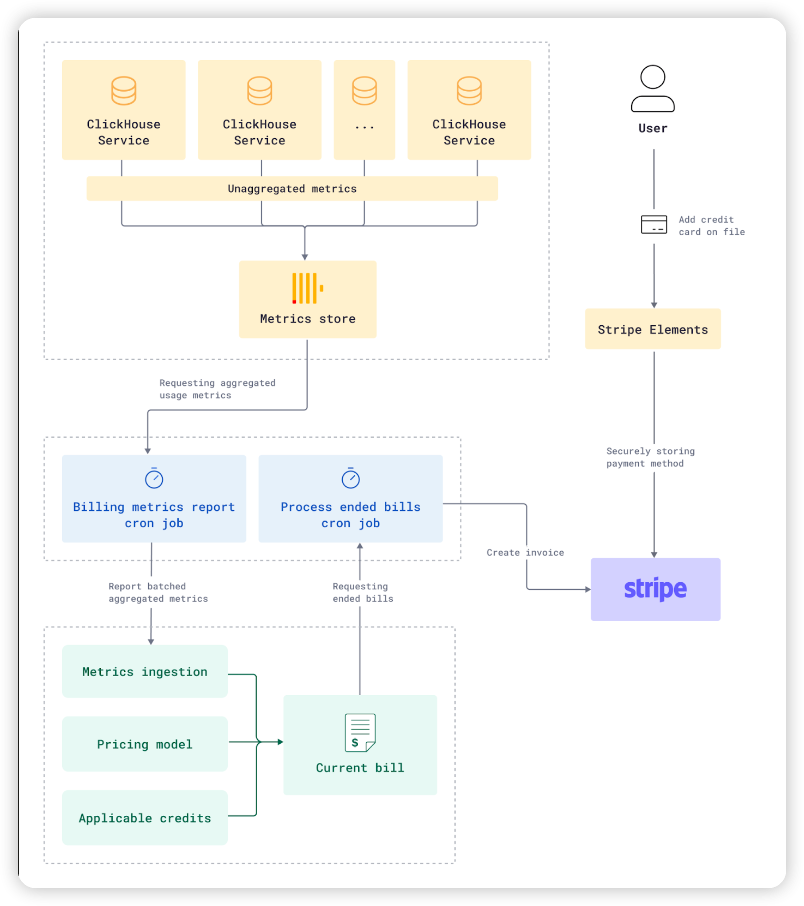
ClickHouse는 이미 시스템 테이블 내에 내부적으로 사용량 지표를 노출하고 있습니다. 이 데이터는 각 고객의 ClickHouse 서비스에서 정기적으로 쿼리되어 내부 및 중앙 ClickHouse 메트릭 클러스터에 게시됩니다. 이 클러스터는 모든 고객 서비스에 대한 세분화된 사용량 데이터를 저장하여 고객이 서비스 사용량 페이지에 표시되는 차트를 강화하고 청구 시스템에 공급하는 역할을 담당합니다.
사용량 데이터는 메트릭 클러스터에서 주기적으로 수집 및 집계되어 계량 및 청구 플랫폼인 m3ter로 전송되며, 여기서 청구 차원으로 변환됩니다. 조직 생성 시부터 시작되는 롤링 월별 청구 기간을 사용합니다. m3ter에는 다양한 사용 사례에 대한 약정 및 선불을 관리할 수 있는 기능도 내장되어 있습니다.
이것이 청구서가 생성되는 방식입니다:
- 집계된 사용량 메트릭이 현재 청구서에 추가되고 가격 모델을 사용하여 비용으로 변환됩니다.
- 조직에서 사용 가능한 모든 크레딧(평가판, 선불 크레딧 등)은 크레딧의 시작/종료 날짜, 잔여 금액 등에 따라 청구 금액에 적용됩니다.
- 청구서 총액은 반복적으로 계산되어 크레딧 고갈과 같은 중요한 변경 사항을 감지하고 알림을 트리거합니다("ClickHouse Cloud 평가판 크레딧이 75%를 초과했습니다").
- 청구 기간이 종료된 후에는 마감일 이후에 전송되었지만 해당 기간과 관련된 나머지 사용량 지표가 모두 포함되도록 다시 한 번 계산합니다.
- 그런 다음 청구서가 마감되고 크레딧이 적용되지 않은 금액은 Stripe의 새 청구서에 추가되어 신용 카드로 청구됩니다.
- 새 청구서가 열리면 새 청구 기간의 사용량과 비용이 합산되기 시작합니다.
관리자는 종량제 청구를 위해 신용 카드를 파일에 등록할 수 있습니다. Stripe의 요소 UI 구성 요소를 사용하여 민감한 카드 정보를 Stripe에 직접 안전하게 전송하고 토큰화합니다.
AWS 마켓플레이스
2022년 12월, ClickHouse는 AWS 마켓플레이스를 통해 통합 결제를 제공하기 시작했습니다. AWS의 가격 모델은 종량제와 동일하지만, 마켓플레이스 사용자는 AWS 계정을 통해 ClickHouse 사용량에 대한 요금이 청구됩니다. AWS와의 통합을 용이하게 하기 위해 모든 주요 클라우드 제공업체와 통합할 수 있는 통합 API 계층을 제공하는 Tackle을 사용하여 멀티 클라우드 인프라 제품을 구축할 때 전반적인 개발 노력과 출시 시간을 크게 단축할 수 있습니다. 신규 가입자가 AWS를 통해 등록하면 Tackle은 핸드셰이크를 완료하고 ClickHouse Cloud로 리디렉션합니다. 또한 태클은 m3ter에서 AWS로 청구서를 보고하기 위한 API를 제공합니다.
UI 및 제품 분석
고객에게 최고의 사용자 인터페이스를 제공하는 것은 ClickHouse에게 매우 중요한 일입니다. 이를 위해서는 고객이 UI를 어떻게 사용하는지 이해하고 무엇이 잘 작동하는지, 무엇이 혼란스러운지, 무엇이 개선되어야 하는지 파악해야 합니다. 고객의 행동을 더 잘 관찰할 수 있는 한 가지 방법은 이벤트 로깅 시스템을 사용하는 것입니다. 다행히도 저희는 최고의 OLAP DB를 사내에 보유하고 있습니다! 모든 웹 UI 클릭 및 기타 제품 사용 이벤트는 ClickHouse 클라우드에서 실행되는 ClickHouse 서비스에 저장되며, 엔지니어링 팀과 제품 팀 모두 이 세분화된 데이터를 사용하여 제품 품질을 평가하고 사용 및 채택을 분석합니다. 이러한 이벤트의 일부 하위 집합을 Segment에 보내 마케팅 팀이 모든 터치포인트에서 사용자 여정과 전환을 관찰하는 데 도움을 줍니다.
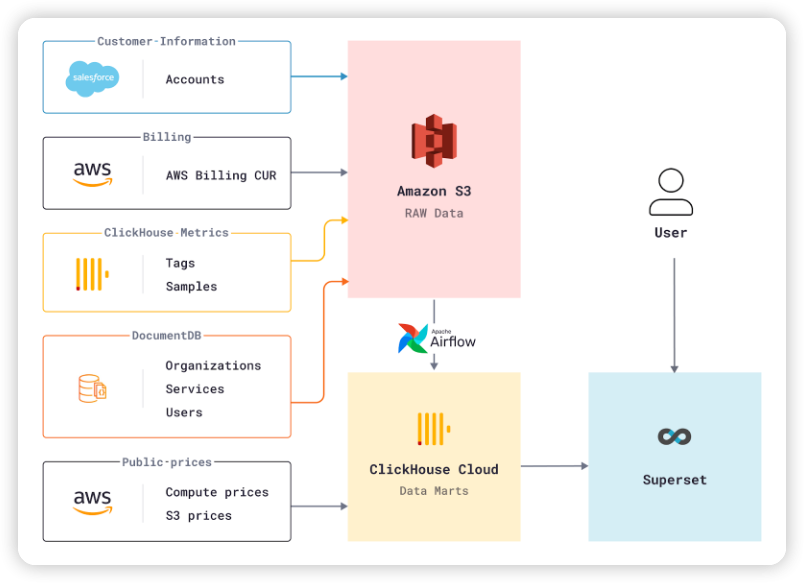
우리는 모든 데이터를 한 곳에서 볼 수 있도록 ClickHouse의 시각화 레이어로 Apache Superset을 사용합니다. 강력하고 사용하기 쉬운 오픈 소스 BI 도구로, 저희의 필요에 딱 맞습니다. 이 설정은 서로 다른 시스템에서 데이터를 집계하는 방식이기 때문에 ClickHouse Cloud를 운영하는 데 매우 중요합니다. 예를 들어, 이 설정을 사용하여 전환율을 추적하고, 자동 확장을 미세 조정하고, AWS 인프라 비용을 관리하고, 주간 내부 회의에서 보고 도구로 사용합니다. ClickHouse로 구동되기 때문에 '너무 많은 데이터'로 인한 시스템 과부하를 걱정할 필요가 없습니다!
교훈
ClickHouse Cloud를 구축하는 과정에서 많은 것을 배웠습니다. 결론부터 말하자면, 가장 중요한 교훈은 다음과 같습니다.
- 클라우드는 진정으로 탄력적이지 않습니다. 퍼블릭 클라우드가 탄력적이고 무한하다고 생각하지만, 대규모로 보면 그렇지 않습니다. 확장성을 염두에 두고 설계하고, 모든 제한 사항에 대한 작은 글씨를 읽고, 인프라의 병목 현상을 파악하기 위해 확장성 테스트를 수행하는 것이 중요합니다. 예를 들어, 저희는 공개 베타를 시작하기 전에 확장성 테스트를 통해 인스턴스 가용성 문제, IAM 역할 제한 및 기타 문제를 발견하여 셀룰러 아키텍처를 채택하게 되었습니다.
- 안정성과 보안도 중요한 기능입니다. 새로운 기능 개발과 그 과정에서 안정성, 보안, 가용성을 타협하지 않는 것 사이에서 균형을 찾는 것이 중요합니다. 특히 제품 개발 초기 단계에서는 새로운 기능을 계속 구축/추가하고 싶은 유혹에 빠지기 쉽지만, 프로세스 초기에 내린 아키텍처 결정은 나중에 큰 영향을 미칩니다.
- 모든 것을 자동화하세요. 테스트(사용자, 기능, 성능 테스트), CI/CD 파이프라인을 구현하여 모든 변경 사항을 빠르고 안전하게 배포하세요. EKS 클러스터와 같은 정적 인프라 프로비저닝에는 Terraform을 사용하고, 동적 인프라에는 인프라에서 무엇이 실행 중인지 한 곳에서 확인할 수 있는 ArgoCD를 사용하세요.
- 공격적인 목표 설정. 저희는 1년 이내에 클라우드를 구축하기로 했습니다. 미리 마일스톤(5월, 10월, 12월)을 결정한 다음 그때까지 실현 가능한 것을 계획했습니다. 각 마일스톤에서 무엇이 가장 중요한지 어렵게 결정하고 필요에 따라 범위를 축소해야 했습니다. 각 릴리스에 대한 기능의 스택 순위를 엄격하게 정했기 때문에 삭감해야 할 때 후회 없이 최하위에 있는 기능을 삭제할 수 있었습니다.
- 출시 기간에 집중. 제품 개발을 빠르게 진행하려면 아키텍처의 어떤 구성 요소를 자체적으로 구축할지, 기존 솔루션을 구매할지 결정하는 것이 중요합니다. 예를 들어, 저희는 자체적으로 미터링 및 마켓플레이스 통합을 구축하는 대신 사용량 기반 가격 책정 및 마켓플레이스 청구를 통해 시장 출시 기간을 단축할 수 있도록 m3ter와 Tackle을 활용했습니다. 가장 핵심적인 혁신에 엔지니어링 노력을 집중하고 나머지는 파트너와 협력하지 않았다면 1년 안에 클라우드 제품을 구축할 수 없었을 것입니다.
- 사용자의 의견을 경청하세요. 저희는 초기에 사용자를 디자인 파트너로 플랫폼에 참여시켰습니다. 비공개 프리뷰에서는 50명의 사용자를 초대하여 무료로 서비스를 사용해보고 피드백을 제공하도록 했습니다. 이 프로그램은 매우 성공적이었으며, 공개 베타로 전환하는 과정에서 무엇이 잘 작동하고 무엇을 조정해야 하는지 매우 빠르게 파악할 수 있었습니다. 공개 베타 기간 동안 저희는 다시 연필을 내려놓고 경청 투어에 나섰습니다. 정식 출시로 가는 길에 가격 모델을 빠르게 조정하고 개발자를 위한 전용 서비스를 도입하여 마찰을 없애고 사용자의 요구 사항에 맞추었습니다.
- 클라우드 비용을 추적하고 분석하세요. 처음부터 클라우드 인프라를 비효율적으로 사용하면 매달 큰 비용을 지불하는 데 익숙해지기 쉽습니다. 비용 효율성은 사후 고려 사항이 아니라 제품을 구축하고 설계할 때 중요한 요소로 고려해야 합니다. EC2, EKS, 네트워크 또는 S3와 같은 블록 스토어 등 클라우드 서비스 사용 모범 사례를 찾아보세요. 멀티파트 업로드 실패로 인해 S3에서 1PB의 정크 데이터를 발견하고 다시는 이런 일이 발생하지 않도록 TTL을 설정했습니다.
결론
1년 안에 클릭하우스 클라우드를 구축하겠다는 목표를 세웠고 실제로 그렇게 했지만, 우여곡절이 많았습니다. 결국에는 항상 그렇듯이 많은 오픈 소스 도구를 활용할 수 있어서 감사했고, 오픈 소스 커뮤니티의 일원이 된 것을 더욱 자랑스럽게 생각합니다. 출시 이후 사용자들의 압도적인 반응을 보았고, 비공개 프리뷰와 베타에 참여해주신 모든 분께 감사드리며, GA 이후에도 저희의 여정에 함께 해주신 모든 분께 감사드립니다.
의견을 남겨주세요